
- 1centos7 环境下使用centos docker中运行flask应用及后台运行实战_怎么让flask程序在centos后台一直运行
- 2docker-compose实践_docker 启动报错vue -web you need to provide a host and
- 3django 使用 可视化包-Pyechart
- 4CVPR 2019 论文汇总(按方向进行论文划分)_hlw094.life
- 5Java 之父:你至少得会两门语言
- 6游戏测试的概念是什么?测试方法和流程有哪些?
- 7如何来判断一个函数是否是凸函数_判断f(x1,x2)=x1^2—2x1x2+x^2+x1+x2凸函数
- 8openlayer加载在线百度瓦片(二)_openlayer引用百度外部瓦片服务
- 9chrome10月新问题反馈——此网站无法提供安全连接 发送的响应无效_chrome 此网站无法提供安全连接
- 10python+emqx实现mqtt协议传输数据_msg.payload.decode()
协方差矩阵、相关矩阵的详细说明
赞
踩
一、协方差矩阵
在做人脸识别的时候经常与协方差矩阵打交道,但一直也只是知道其形式,而对其意义却比较模糊,现在我根据单变量的协方差给出协方差矩阵的详细推导以及在不同应用背景下的不同形式。
变量说明:
设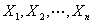 为一组随机变量,这些随机变量构成随机向量
为一组随机变量,这些随机变量构成随机向量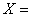
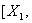
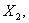
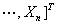 ,每个随机变量有m个样本,则有样本矩阵
,每个随机变量有m个样本,则有样本矩阵
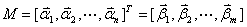 (1)
(1)
其中 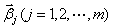 对应着每个随机向量X的样本向量,
对应着每个随机向量X的样本向量,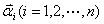 对应着第i个随机单变量的所有样本值构成的向量。
对应着第i个随机单变量的所有样本值构成的向量。
单随机变量间的协方差:
随机变量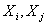 之间的协方差可以表示为
之间的协方差可以表示为
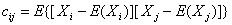 (2)
(2)
根据已知的样本值可以得到协方差的估计值如下:
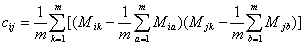 (3)
(3)
可以进一步地简化为:
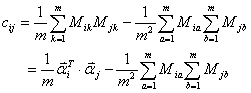 (4)
(4)
协方差矩阵:
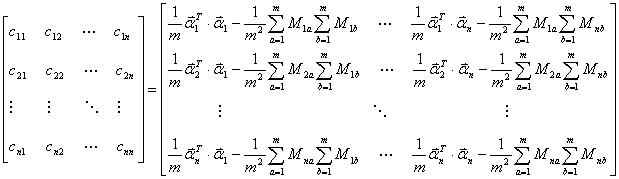
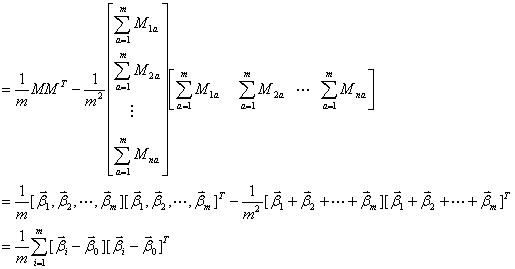 (5)
(5)
其中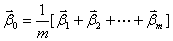 ,从而得到了协方差矩阵表达式。
,从而得到了协方差矩阵表达式。
如果所有样本的均值为一个零向量,则式(5)可以表达成:
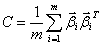 (6)
(6)
补充说明:
1、协方差矩阵中的每一个元素是表示的随机向量X的不同分量之间的协方差,而不是不同样本之间的协方差,如元素Cij就是反映的随机变量Xi, Xj的协方差。
2、协方差是反映的变量之间的二阶统计特性,如果随机向量的不同分量之间的相关性很小,则所得的协方差矩阵几乎是一个对角矩阵。对于一些特殊的应用场合,为了使随机向量的长度较小,可以采用主成分分析的方法,使变换之后的变量的协方差矩阵完全是一个对角矩阵,之后就可以舍弃一些能量较小的分量了(对角线上的元素反映的是方差,也就是交流能量)。特别是在模式识别领域,当模式向量的维数过高时会影响识别系统的泛化性能,经常需要做这样的处理。
3、必须注意的是,这里所得到的式(5)和式(6)给出的只是随机向量协方差矩阵真实值的一个估计(即由所测的样本的值来表示的,随着样本取值的不同会发生变化),故而所得的协方差矩阵是依赖于采样样本的,并且样本的数目越多,样本在总体中的覆盖面越广,则所得的协方差矩阵越可靠。
4、如同协方差和相关系数的关系一样,我们有时为了能够更直观地知道随机向量的不同分量之间的相关性究竟有多大,还会引入相关系数矩阵。
二、相关矩阵
相关系数:
著名统计学家卡尔·皮尔逊设计了统计指标——相关系数。相关系数是用以反映变量之间相关关系密切程度的统计指标。相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。
依据相关现象之间的不同特征,其统计指标的名称有所不同。如将反映两变量间线性相关关系的统计指标称为相关系数(相关系数的平方称为判定系数);将反映两变量间曲线相关关系的统计指标称为非线性相关系数、非线性判定系数;将反映多元线性相关关系的统计指标称为复相关系数、复判定系数等。
相关系数用r表示,它的基本公式(formula)为:
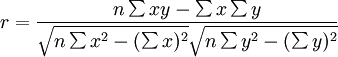
相关系数的值介于–1与+1之间,即–1≤r≤+1。其性质如下:
- 当r>0时,表示两变量正相关,r<0时,两变量为负相关。
- 当|r|=1时,表示两变量为完全线性相关,即为函数关系。
- 当r=0时,表示两变量间无线性相关关系。
- 当0<|r|<1时,表示两变量存在一定程度的线性相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近于0,表示两变量的线性相关越弱。
- 一般可按三级划分:|r|<0.4为低度线性相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关。
相关矩阵也叫相关系数矩阵,是由矩阵各列间的相关系数构成的。也就是说,相关矩阵第i行第j列的
元素是原矩阵第i列和第j列的相关系数。
求取相关矩阵的matlab函数为:correoff
3、协方差矩阵和相关矩阵的关系
由二者的定义公式可知,经标准化的样本数据的协方差矩阵就是原始样本数据的相关矩阵。这里所说的标准化指正态化,即将原始数据处理成均值为0,方差为1的标准数据。
即:
X'=(X-EX)/DX
用matlab函数表达为:
X'=zscore(X)
则协方差矩阵和相关矩阵的关系可表达为:
correoff(X)=cov(zscore(X))

