
- 1Win11安卓子系统怎么安装?_127.0.0.1:58526
- 2【Linux】文件描述符与重定向操作_将存放用户信息文件中的后5行通过重定向符号 导入到file02.txt中
- 3新概念英语(第二册)复习——Lesson 1 - Lesson5
- 4Jenkins配置远程服务器SSH Server流程_jenkins ssh server
- 5SpringBoot3整合Mybatis-plus报错IllegalArgumentException
- 6【深度学习笔记】6_5 RNN的pytorch实现
- 72023阿里最新发布Java后端面试八股文PDF合集,共计1700页_java面试八股文pdf 下载
- 8Flutter 成功在鸿蒙上运行;微信 8.0 发布;支付宝和微信支付达到反垄断标准 | 极客头条...
- 9linux----------2--3----(无名)管道通信原理及管道编程实战_无名管道为什么有两个文件按描述符
- 10在cmd命令行下使用VS Build Tools 编译运行C/C++源文件_vs_buildtools
DolphinScheduler——蔚来汽车数据治理开发平台的应用改造
赞
踩
目录
原文大佬的这篇基于调度系统的数据治理案例有借鉴意义,这里摘抄下来用作学习和知识沉淀。
一、业务痛点
蔚来汽车构建一个统一的数据中台之前,我们面临这样一些业务痛点和困境:
(1)数据缺乏治理,数仓不规范、不完整
-
没有统一的数据仓库,无全域的数据资产视图
-
存在数据孤岛;
(2)工具散乱,用户权限不统一,学习成本高
- 用户需要在多个工具之间切换,导致开发效率低
- 底层运维成本高
(3)数据需求响应周期长,找数难,取数难
- 无沉淀的数据资产与中台能力,重复处理原始数据;
- 业务数据需求从提出到获取结果的周期长
基于这些痛点和问题,我们构建了一个公司层面的业务中台,内部叫做 DataSight。
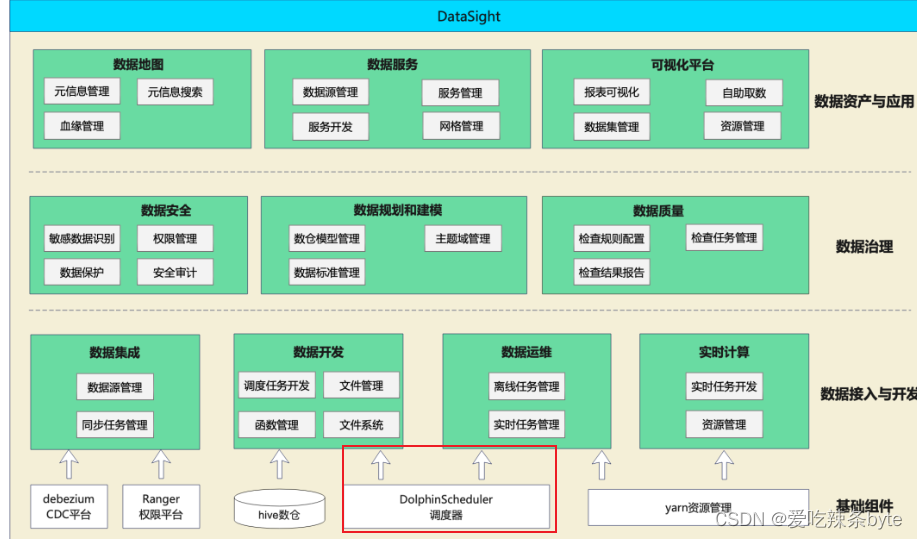
由上图可知,最底下是一些基础组件;往上一层,这些基础组件主要是支撑了一些数据接入与开发的模块;再向上是数据治理,以及数据资产与应用层模块。其中, DolphinScheduler调度系统的在公司内部主要应用于交互的模块,就是数据开发和数据运维两个模块。
二、应用现状
作业现状:DolphinScheduler( 版本2.0.7)集群机器共有 9 台,分别是两台 Master 机器,是8c 和 32G;六台 Worker 机器,16c 和 64G,以及一台 Alert 机器,8c 和 32G。目前DS线上运行大概一年多,日均的调度工作流实例大概在 4w+,日均调度任务实例大概在 10w+ 左右,主要的任务节点有Spark 节点、SparkSQL、prestoSQL、Python 和 Shell,其中 Spark 节点占比约 70%。
三、技术改造
为了适应业务需求,我们对DolphinScheduler 进行了一些技术改造,核心目标是确保作业调度稳定性。
3.1 稳定性
3.1.1 滚动重启+黑名单机制+精准路由
这个改造是因为我们遇到的一些痛点,首先,大家知道,DolphinScheduler 的 Worker 重启机制在重启时会把所有的任务给 kill 掉,然后去Restart 这个任务,把这个 kill 的任务分发到新的 Worker 机器上。这样会导致任务执行时间较长,这不符合我们的预期。
同时,我们也无法在特定的worker上进行验证任务的,对比我们的解决方案就是滚动重启,在重启某台机器之先下线这台机器,也就是加上黑名单,这样的话,Master 机器就不会给这台下已经下线的机器去分发Worker任务。这台机器会在上面的任务全部处理完毕后自动上线,也就是移出这个黑名单,接下来所有的worker节点都按照此时方式重启,达到平滑重启的目标。
这样做的好处在于不会阻塞每个任务的执行,集群在重启的时候稳定性能得到大幅提升。

如图所示,我们在这个任务后面加一个specific dispatch-worker02 的话,那这个任务一定会被分配到Worker02这台机器上去。这样的好处在于,假设我们想要去某一个功能点,我们只需要把某一台Worker 机器下线重启,需要测试的功能点按照这个方式就一定能够打到这台特定的机器上去,实现最小范围的灰度,有助于提高稳定性。
-
优化存储
在存储方面,我们痛点也很明显,就是process instance和task instance 这两张表数据量是比较大的,由于我们每天的数据量比较大,目前已经达到了千万级别,造成 MySQL 的存储压力比较大。另外,部分 SQL 执行时间长,业务响应变慢;而且 DDL 时会造成锁表,导致业务不可用。
针对这些问题,我们的解决方案包括去梳理所有的慢 SQL,然后去添加合适的索引。与此同时,还有降低查询频率,特别是针对依赖节点。因为我们知道依赖节点每 5 秒钟查询一次数据库,所以我们根据依赖节点所在的 tasks instance ID 去做一个“打散”,偶数节点每 30 秒查询一次,奇数节点每 30 秒查询一次,把他们分开来降低对整个数据库的查询压力。
另外,为了减轻表数据量大的问题,我们也做了一个定期删除的策略,以及定时同步历史数据的策略。
定时删除就是我们利用 DolphinScheduler 自身的调度能力建立两个工作流去删除这两张表,保证 process instance 这张表保留两个月的数据,task instance 这张表保留一个月的数据。同时在删表的时候,我们要注意在非业务高峰期时去做这个动作,每次删表的时候,batch size 要控制好,尽量不要影响线上的任务。
定时同步历史数据,就是我们针对 process instance这个表,依据schedule time 按年去分表;针对task instance这张表,按first submit time 按月去分表。
-
Spark任务优化
我们提交Spark任务的方式是通过Spark Submit 去提交的,它的缺点在于提交 Spark 任务后,常驻机器,导致机器内存过大,会有机器宕机的风险,worker 的运行效率较低。我们优化了 Spark 任务提交和运行的逻辑,就是通过 Spark Submit 提交的时候添加spark.yarn.submit.waitAppCompletion=false 这个参数,这样任务提交完以后这个进程就消失了。考虑到要保证Worker 机器任务的线程和Spark 和 Yarn 上的状态一致,我们间隔一定时间查询 Spark任务状态,如图所示:
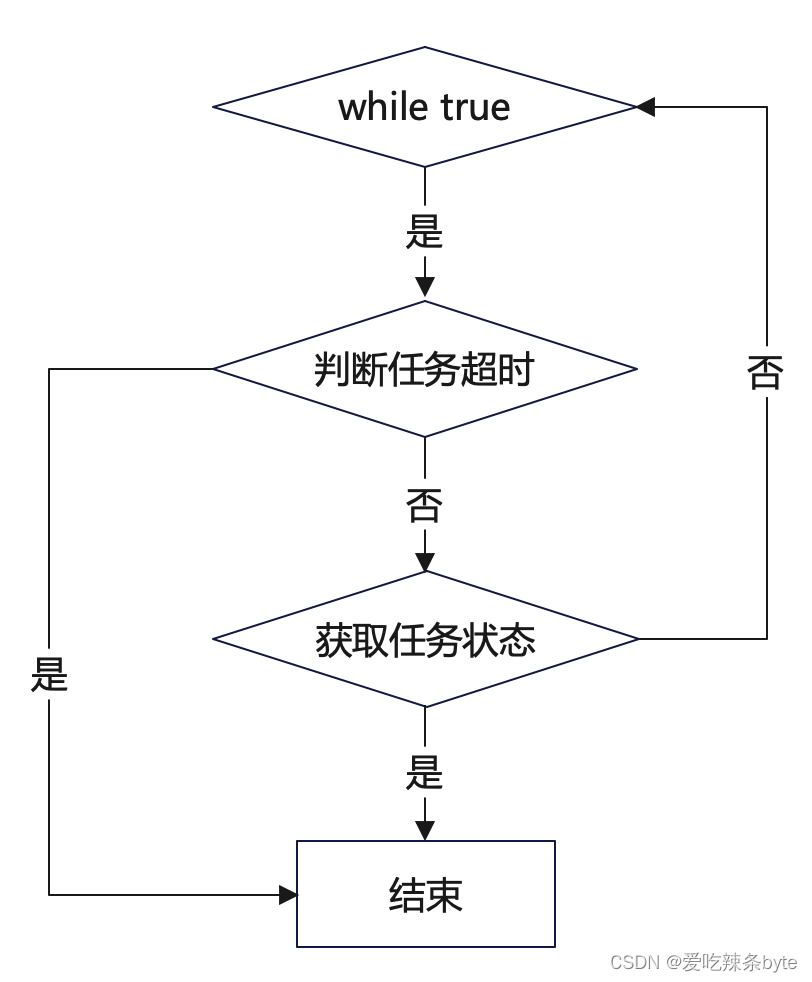
这里的while true循环,首先去判断这个任务是否超时,如果任务已经超时就会结束这个spark任务,同时会kill掉集群上的那个真正在跑的任务。
如果任务没有超时,我们会去获取任务的状态,如果任务状态是终止状态,就直接跳出这个循环,否则会间隔一定的时间,比如 30秒,再继续这个while true 循环。这种方式让整个 Worker 机器所能承载的Spark任务大大增加。
3.2 易用性
我们的依赖节点之前的痛点在于,它的使用规则不太符合用户的需求,比如之前是单次查询不到上游即失败;日志内容显示信息不全,对用户不友好;用户无法自定义依赖范围。
针对这些问题,我们做的工作包括修改了查询逻辑为继续等待,就是说当这个任务查询不到上游的时候,我们会继续等待,而不是直接失败。同时我们会也有个极端的保证,就是这个依赖节点超过 24 小时以后就让它自动失败,然后给用户发一个报警。
针对依赖节点,我们也做了强制成功这样一个小技巧,并支持用户自定义依赖范围。

另外,我们还优化了依赖节点的日志输出,当用户点击依赖节点的日志的时候,可以比较清楚地看到依赖的上游所在的空间,这个空间内任务所对应的维护人是什么,以及工作流节点是什么和完成状态,让用户可以点对点地找到上游的同学,快速解决这个依赖节点卡住的问题。

针对补数之前的痛点,比如补数任务没有进度提示,并行补数流程实例不严格按照时间顺序,停止并行补数任务逻辑比较麻烦等问题,我们的解决方案包括并行任务引入线程池,也就是把任务按照时间顺序一个一个抛到新建的线程池里,执行完毕以后退出这个线程池,然后再放一个新的进来,达到并行补数的状态。同时,执行时间按递增的顺序。
当我们想停止这个补数任务的时候也比较简单,直接把这个线程池 shutdown 就行。

最后是关于多 SQL 执行方面的优化。我们之前面临的痛点包括:
-
多 SQL 需要多节点执行浪费集群资源;
-
自定义环境变量无法实现;
-
无法跟踪 SparkSQL 的运行日志。
我们的解决方案包括拆分这条 SQL,支持多条 SQL 同时执行。与此同时,我们可以在 SparkSQL 任务执行之前拦截执行select engine_id() as engine_id语句。
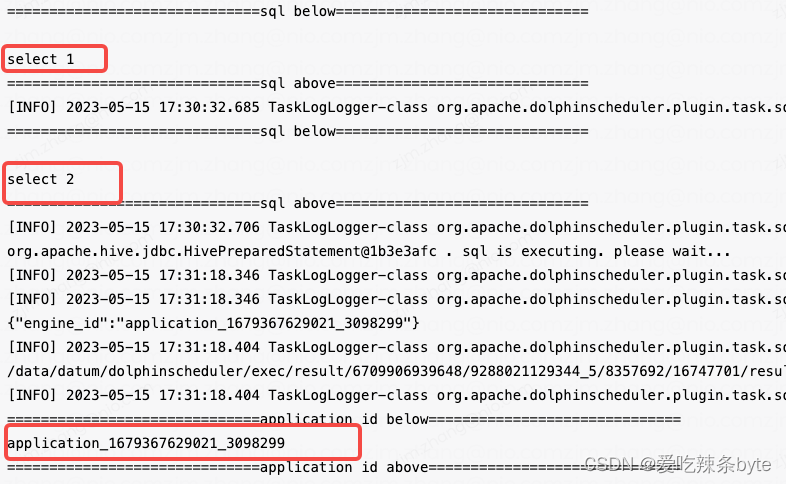
如上图所示,对于 SQL 1 和 SQL 2,之前我们会在两个任务里面去放着,但是现在可以在一个任务节点里面放下来,它会执行两次。同时我们可以清晰地看到这个 SparkSQL 所在的 application ID 是什么,用户能够清晰地根据这个 application ID 找这个业务所在的地址,了解这个作业的进度。
参考文章:

