
- 1HarmonyOS ArkTS 三方库的基本使用(十六)_harmony三方组件中心仓
- 2递归方法实现阶乘_防抖和节流 就返回5*4*3*2*1的结果用递归实现阶乘比如传入5
- 3c语言 奥数题目及答案,小学奥数题C语言解法
- 4【数据标注】数据集标注规范与常见情况
- 5【微信小程序】-- WXML 模板语法 - 事件绑定 -- tap & input (十)_input tap
- 6UWB/蓝牙/WiFi/红外/Zigbee/LoRa Edge…….室内定位技术的百家争鸣时代_zigbee uwb lora
- 7浅谈Fortran语言
- 8Prompt Engineering、Finetune、RAG:OpenAI LLM 应用最佳实践
- 9struct queue_limits结构体参数学习
- 10Windows 11/10/7离线安装.NET3.5_net35离线一键安装工具
总结!聊一聊三种三维重建经典算法
赞
踩

作者:PCIPG-晨艺| 来源:3DCV
添加微信:dddvisiona,备注:3D点云,拉你入群。文末附行业细分群。
1 什么是三维重建
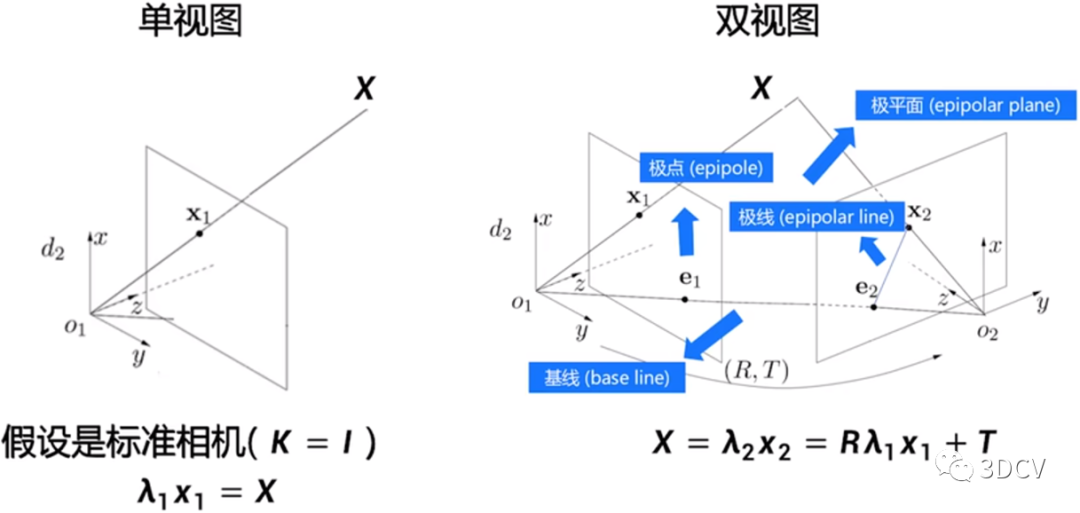
在计算机视觉中,三维重建是指根据单视图或者多视图的图像重建三维信息的过程。由于单视频的信息不完全,因此三维重建需要利用经验知识,而多视图的三维重建(类似人的双目定位)相对比较容易,其方法是先对摄像机进行标定,即计算出摄像机的图像坐标系与世界坐标系的关系,然后利用多个二维图像中的信息重建出三维信息。如下图所示,故三维重建可以简单理解为相机摸象的过程。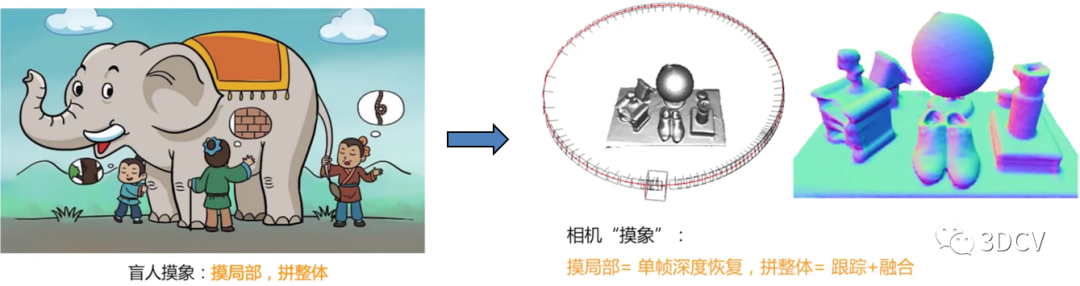
2 重建的结果如何表达
1、深度图 (depth) 每个像素值代表的是物体到相机xy平面的距离,由深度摄像头获取 2、点云(point cloud) 某个坐标系下的点的数据集,由三维激光雷达获取
2、点云(point cloud) 某个坐标系下的点的数据集,由三维激光雷达获取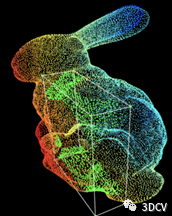 3、网格(mesh) 全部由三角形组成的多边形网格
3、网格(mesh) 全部由三角形组成的多边形网格 4、体素 (voxel) 三维空间中的一个有大小的点,一个小方块,相当于是三维空间种的像素。
4、体素 (voxel) 三维空间中的一个有大小的点,一个小方块,相当于是三维空间种的像素。
3 如何实现整个重建过程
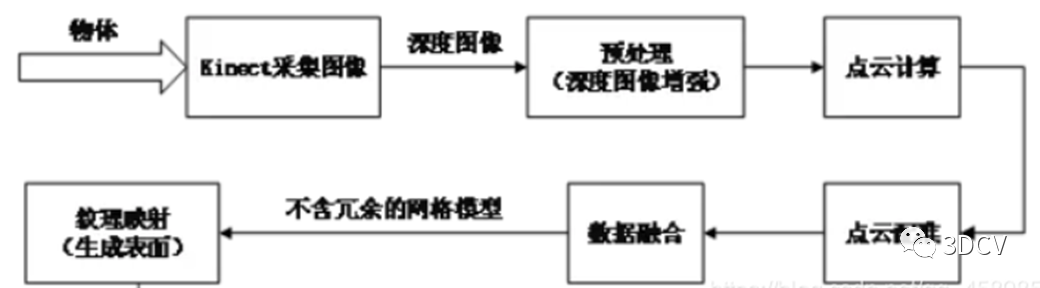
3.1 深度图像的获取
景物的深度图像由Kinect在Windows平台下拍摄获取,同时可以获取其对应的彩色图像。为了获取足够多的图像,需要变换不同的角度来拍摄同一景物,以保证包含景物的全部信息。具体方案既可以是固定Kinect传感器来拍摄旋转平台上的物体;也可以是旋转Kinect传感器来拍摄固定的物体。
推荐学习3D视觉工坊三维点云课程:
3.2 预处理
受到设备分辨率等限制,它的深度信息也存在着许多缺点。为了更好的促进后续基于深度图像的应用,必须对深度图像进行去噪和修复等图像增强过程。目前深度相机输出的depth图还有很多问题,比如对于光滑物体表面反射、半/透明物体、深色物体、超出量程等都会造成深度图缺失。而且很多深度相机是大片的深度值缺失,这对于算法工程师来说非常头疼。
3.3 计算点云数据
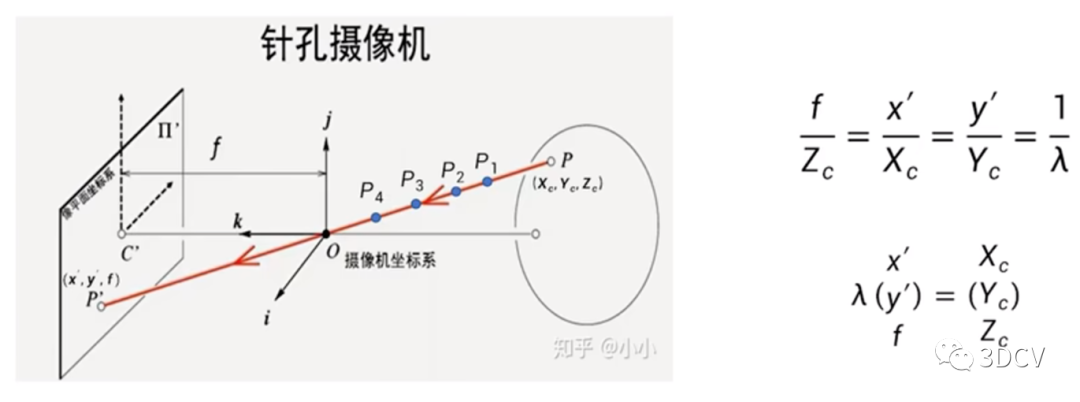
 整个计算过程实际上是从世界坐标系到像素坐标系(不考虑畸变)的过程,用一幅图来总结其转换关系:
整个计算过程实际上是从世界坐标系到像素坐标系(不考虑畸变)的过程,用一幅图来总结其转换关系: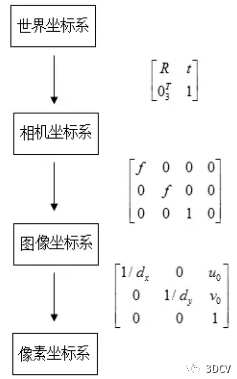
-
世界坐标系:描述环境中任何物体的位置。
-
相机坐标系:在相机上建立的坐标系,为了从相机的角度描述物体位置而定义,作为沟通世界坐标系和图像/像素坐标系的中间一环。单位为m。以相机的光心为坐标原点,X 轴和Y 轴分别平行于图像坐标系的 X 轴和Y 轴,相机的光轴为Z 轴,用(Xc, Yc, Zc)表示其坐标值。
-
图像坐标系(image coordinate system):描述物体从相机坐标系到图像坐标系的投影透射关系,方便进一步得到像素坐标系下的坐标。以图像平面的中心为坐标原点,X轴和Y 轴分别平行于图像平面的两条垂直边,用( x , y )表示其坐标值。图像坐标系是用物理单位(例如毫米)表示像素在图像中的位置。
-
像素坐标系(pixel coordinate system):描述物体成像后的像点在数字图像上(相片)的坐标,是我们真正从相机内读取到的信息所在的坐标系。单位为个(像素数目)。以图像平面的左上角顶点为原点,X 轴和Y 轴分别平行于图像坐标系的 X 轴和Y 轴,用(u , v )表示其坐标值。数码相机采集的图像首先是形成标准电信号的形式,然后再通过模数转换变换为数字图像。每幅图像的存储形式是M × N的数组,M 行 N 列的图像中的每一个元素的数值代表的是图像点的灰度。这样的每个元素叫像素,像素坐标系就是以像素为单位的图像坐标系。
3.4 点云配准
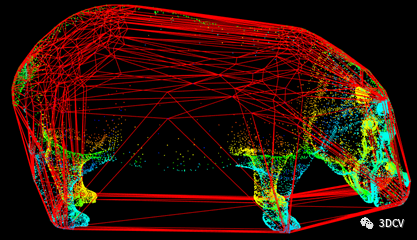
对于多帧通过不同角度拍摄的景物图像,各帧之间包含一定的公共部分。为了利用深度图像进行三维重建,需要对图像进行分析,求解各帧之间的变换参数。深度图像的配准是以场景的公共部分为基准,把不同时间、角度、照度获取的多帧图像叠加匹配到统一的坐标系中。计算出相应的平移向量与旋转矩阵,同时消除冗余信息。点云配准除了会制约三维重建的速度,也会影响到最终模型的精细程度和全局效果。因此必须提升点云配准算法的性能。三维深度信息的配准按不同的图像输入条件与重建输出需求被分为:粗糙配准、精细配准和全局配准等三类方法。配准过程中,匹配误差被均匀的分散到各个视角的多帧图像中,达到削减多次迭代引起的累积误差的效果。值得注意的是,虽然全局配准可以减小误差,但是其消耗了较大的内存存储空间,大幅度提升了算法的时间复杂度。
3.5 数据融合
经过配准后的深度信息仍为空间中散乱无序的点云数据(如下图),仅能展现景物的部分信息。因此必须对点云数据进行融合处理,以获得更加精细的重建模型。 以Kinect传感器的初始位置为原点构造体积网格,网格把点云空间分割成极多的细小立方体,这种立方体叫做体素(Voxel)。为了解决体素占用大量空间的问题,提出了TSDF (Truncated Signed Distance Field,截断符号距离场)算法(如下图),该方法只存储距真实表面较近的数层体素,而非所有体素。因此能够大幅降低KinectFusion的内存消耗,减少模型冗余点。
以Kinect传感器的初始位置为原点构造体积网格,网格把点云空间分割成极多的细小立方体,这种立方体叫做体素(Voxel)。为了解决体素占用大量空间的问题,提出了TSDF (Truncated Signed Distance Field,截断符号距离场)算法(如下图),该方法只存储距真实表面较近的数层体素,而非所有体素。因此能够大幅降低KinectFusion的内存消耗,减少模型冗余点。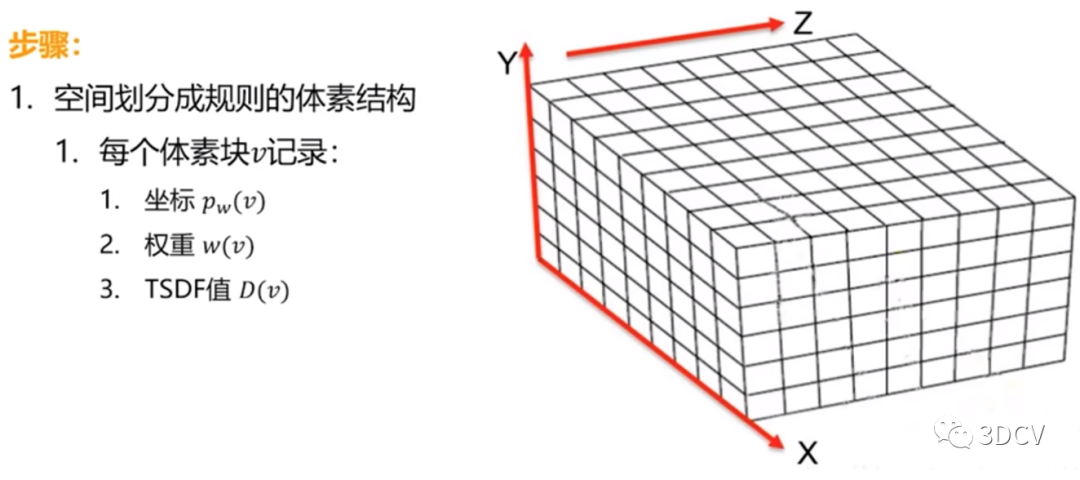 通过为所有体素赋予TSDF(Truncated Signed Distance Field,截断有效距离场)值,来隐式的模拟表面。下图所示,计算出TSDF值,即此体素到重建表面的最小距离值。当TSDF值大于零,表示该体素在表面前;当TSDF小于零时,表示该体素在表面后;当TSDF值越接近于零,表示该体素越贴近于场景的真实表面。于是形成重建的表面。
通过为所有体素赋予TSDF(Truncated Signed Distance Field,截断有效距离场)值,来隐式的模拟表面。下图所示,计算出TSDF值,即此体素到重建表面的最小距离值。当TSDF值大于零,表示该体素在表面前;当TSDF小于零时,表示该体素在表面后;当TSDF值越接近于零,表示该体素越贴近于场景的真实表面。于是形成重建的表面。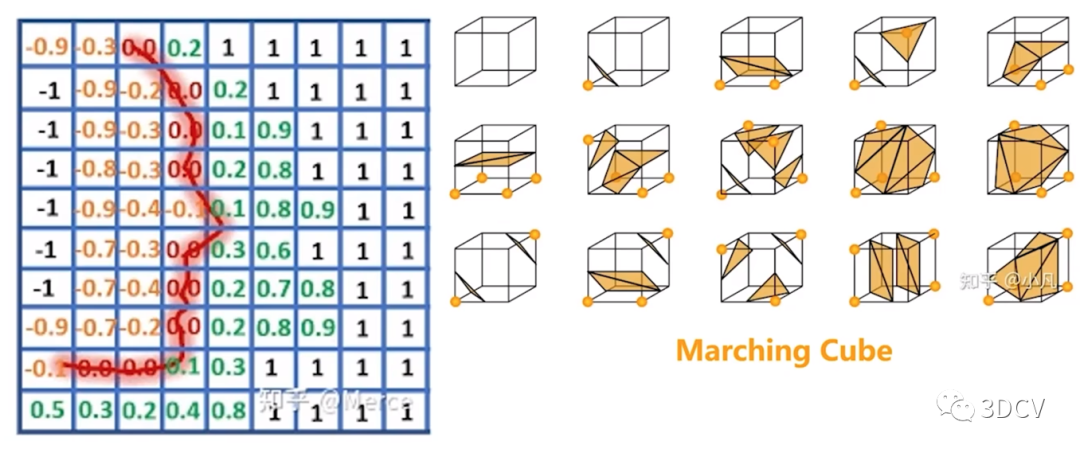
4 三维重建的经典算法
4.1 泊松算法
1、原理基于八叉树和泊松方程的一种网格三维重建算法,利用指示函数,可以对空间内部的所有有效指示函数实现梯度计算,通过求解这个函数提取等值面,得到表面的过程,即构建泊松方程并对其求解的过程。2、算法流程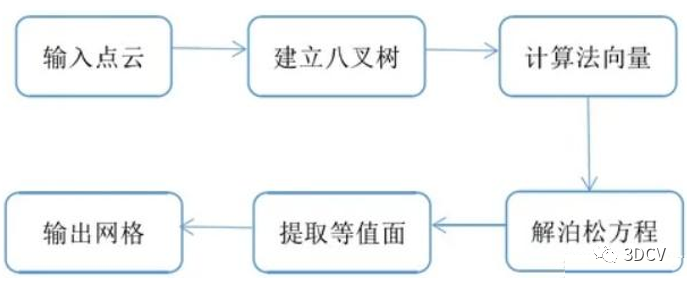 3、核心代码
3、核心代码
- //----------------------------------法线估计------------------------------------
- pcl::NormalEstimation<pcl::PointXYZ, pcl::Normal> n;//法线估计对象
- pcl::PointCloud<pcl::Normal>::Ptr normals(new pcl::PointCloud<pcl::Normal>);//存储估计的法线
- pcl::search::KdTree<pcl::PointXYZ>::Ptr tree(new pcl::search::KdTree<pcl::PointXYZ>);
- tree->setInputCloud(cloud);
- n.setInputCloud(cloud);
- n.setSearchMethod(tree);
- n.setKSearch(10);
- n.compute(*normals);
- //-------------------------------连接法线和坐标---------------------------------
- pcl::PointCloud<pcl::PointNormal>::Ptr cloud_with_normals(new pcl::PointCloud<pcl::PointNormal>);
- pcl::concatenateFields(*cloud, *normals, *cloud_with_normals);
- //---------------------------------泊松重建-------------------------------------
- pcl::search::KdTree<pcl::PointNormal>::Ptr tree2(new pcl::search::KdTree<pcl::PointNormal>);
- tree2->setInputCloud(cloud_with_normals);
- pcl::Poisson<pcl::PointNormal> pn;
- pn.setSearchMethod(tree2);
- pn.setInputCloud(cloud_with_normals);
- pn.setDepth(6); // 设置将用于表面重建的树的最大深度
- pn.setMinDepth(2);
- pn.setScale(1.25); // 设置用于重建的立方体的直径与样本的边界立方体直径的比值
- pn.setSolverDivide(3); // 设置块高斯-塞德尔求解器用于求解拉普拉斯方程的深度。精度
- pn.setIsoDivide(6); // 设置块等表面提取器用于提取等表面的深度 平滑度
- pn.setSamplesPerNode(10); // 设置每个八叉树节点上最少采样点数目 八叉树节点上的采样点数速度
- pn.setConfidence(false); // 设置置信标志,为true时,使用法线向量长度作为置信度信息,false则需要对法线进行归一化处理
- pn.setManifold(false); // 设置流行标志,如果设置为true,则对多边形进行细分三角话时添加重心,设置false则不添加
- pn.setOutputPolygons(false); // 设置是否输出为多边形(而不是三角化行进立方体的结果)。

4、结果展示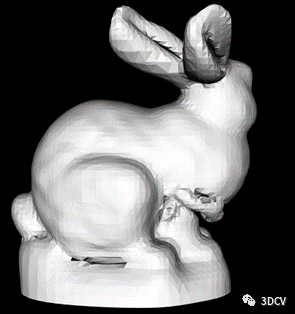
4.2 凸包算法
1、算法流程给出三维空间中的n个顶点,求解由这n个顶点构成的凸包表面 1)首先任选4个点形成的一个四面体(初始凸包)然后每次新加一个点P分两种情况:a. P在凸包内,则可以跳过。b. P在凸包外,对于某边,找到从这个点可以“看见”的包含该边的面S(能不能看见可以用法向量来计算,看点是否在面外侧),删除这些面S,然后用S的除该边外的另外两边与点P新构成两个面。这样遍历所有边,就将P加入该凸包中,并形成了新的凸包。2)遍历所有点,最后得到整个点集的凸包。2、核心代码
1)首先任选4个点形成的一个四面体(初始凸包)然后每次新加一个点P分两种情况:a. P在凸包内,则可以跳过。b. P在凸包外,对于某边,找到从这个点可以“看见”的包含该边的面S(能不能看见可以用法向量来计算,看点是否在面外侧),删除这些面S,然后用S的除该边外的另外两边与点P新构成两个面。这样遍历所有边,就将P加入该凸包中,并形成了新的凸包。2)遍历所有点,最后得到整个点集的凸包。2、核心代码
- //---------------------对上述点云构造凸包-----------------------
- pcl::ConvexHull<pcl::PointXYZ> hull; //创建凸包对象
- hull.setInputCloud(cloud); //设置输入点云
- hull.setDimension(3); //设置输入数据的维度(2D或3D)
- vector<pcl::Vertices> polygons; //设置pcl:Vertices类型的向量,用于保存凸包顶点
-
- pcl::PointCloud<pcl::PointXYZ>::Ptr surface_hull(new pcl::PointCloud<pcl::PointXYZ>);//该点云用于描述凸包形状
-
- hull.setComputeAreaVolume(true); //设置为真,则调用qhr库来计算凸包的总面积和体积
- hull.reconstruct(*surface_hull, polygons);//计算3D凸包结果
- float Area = hull.getTotalArea(); //获取凸包的总面积
- float Volume = hull.getTotalVolume(); //获取凸包的总体积
- cout << " 凸包的面积为: " << Area << endl;
- cout << " 凸包的体积为: " << Volume << endl;
3、结果展示
4.3 凹包算法
1、原理在三维层面上来讲,该算法我们可以想象为一个球在一堆点集中进行滚动,符合条件的三个点即会构成一个多边形,这个条件是一种“空球法则” (类似于空圆法则),也就是说这个球除三个基本点之外不会包含其他的点。
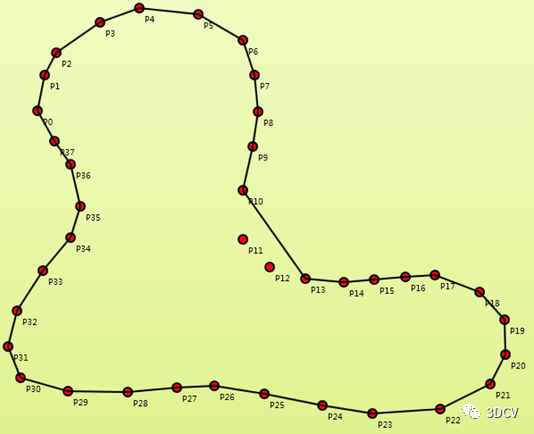 从右图中可以看出,球并没有滚到P11和P12两个点,那么这时我们猜想:如果缩小球的半径,是否就可以遍历更多的点,从而输出的点云就更加的清晰完整呢?2、核心代码
从右图中可以看出,球并没有滚到P11和P12两个点,那么这时我们猜想:如果缩小球的半径,是否就可以遍历更多的点,从而输出的点云就更加的清晰完整呢?2、核心代码
- pcl::ConcaveHull<pcl::PointXYZ> cavehull;
- cavehull.setInputCloud(cloud);
- cavehull.setAlpha(0.001);
- vector<pcl::Vertices> polygons;
- cavehull.reconstruct(*surface_hull, polygons);// 重建面要素到点云
3、结果展示设置半径分别为0.5、0.1、0.05、0.02时,得到下面四种结果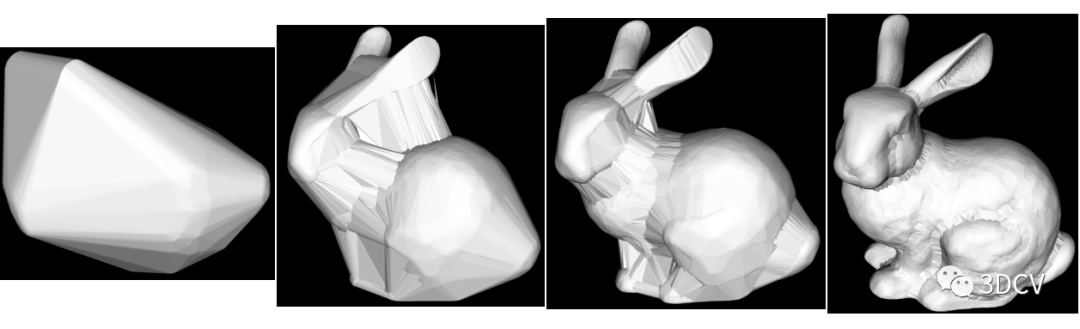 因此,之前的猜想是正确的。
因此,之前的猜想是正确的。
除此三种重建算法外,还有贪婪、Delaunay三角剖分算法等等。这一部分我们后续会在「3D视觉从入门到精通」知识星球内进行讲解。
5 参考资料
https://mp.weixin.qq.com/s/LGnOqDVefzIF_yRZO2ZB7w
https://www.bilibili.com/video/BV1zY4y1X7UJ
—END—
高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
科研论文写作:
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
[2]面向三维视觉的Linux嵌入式系统教程[理论+代码+实战]
工业3D视觉方向课程:
[1](第二期)从零搭建一套结构光3D重建系统[理论+源码+实践]
SLAM方向课程:
[1]深度剖析面向机器人领域的3D激光SLAM技术原理、代码与实战
[1]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[2](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[3]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[4]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:
[1] 深度剖析面向自动驾驶领域的车载传感器空间同步(标定)
[2] 国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程
[4]面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
[5]如何将深度学习模型部署到实际工程中?(分类+检测+分割)

