
- 1Android资源ID获取方法及应用包下指定资源ID的实例详解
- 2JVM的内存结构(下)——堆和方法区_jvm1.7设置堆区大小是包含方法区吗
- 3Android——Intent_intent.setaction
- 4c++实现数组小和_c++数组小和
- 5java自定义注解的使用_java自定义注解什么时候执行
- 6Css Flex 弹性布局中的换行与溢出处理方法_flex布局换行
- 7AIGC绘画关键词 - 神兽类(一)_a huge white fox with nine tails in a jungle backg
- 8计算机毕业设计题目参考大全
- 9python-时间序列-pandas基础知识_使用pandas生成12行5列的二维数据,索引为月份,列为abcde
- 10为什么.net中引用dll文件属性窗口中的“复制到本地”属性不可用(Why is the Copy Local property for my reference disabled?)_引用属性复制本地false
Stable diffusion(二)
赞
踩
SD colab安装
https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb#scrollTo=PjzwxTkPSPHf
https://www.youtube.com/watch?v=Q37eGFvMDbY
https://www.youtube.com/watch?v=Q37eGFvMDbY
https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb#scrollTo=PjzwxTkPSPHf
- 1
- 2
界面介绍

- 底模:不同的数据集训练出来的模型效果不同。有的是卡通风、有的是现实风。可以类比于GPT,用什么文案训练,对于改文案的语言通用能力就越强。
- VAE:用于将图片压缩到潜在空间的组件,这里没有出现。
- 采样器:用于调整迭代次数和迭代数的组合组件。不同的策略,不同结果
- CLIP:tokenizer + text encoder。有些时候,会选择词向量/图向量的倒数第二层来作为输入。
- CFG Scale:Classifier-Free Guidance scale,控制了提示词的参数。通常设置在7~9附近。
- 图像生成种子/Seed:-1代表使用随机数。数量越高,代表加入的噪音越多。
- 面部修复/高清修复:生分成真人模型的时候i要用,其他时候用不用都行
- 脚本:用于规整化数据集的工具,后续再看用处
- 图片信息:图片下的信息栏目,表示生成这张图片用到的参数是什么。
- Embedding:在AI绘图里面,一个Embedding可以实现,一个关键词 = {词语1、词语2、词语3}这样的效果
VAE、底模(checkpoint)、Lora对于一张图片的影响
| 底模(checkpoint) | Lora | VAE |
|---|---|---|
| 比如大家都是计算机院的学生。有的学生是学物联网的、有的学生是学计算机网络的、有的是学软件工程的,最后他们就业理论上应该是不同的(虽然现在都是转Java) | 大家都是后端选手,有的学了 C,有的学了Java,有的学了Golang,虽然都是后端,你非要让写Java的人写C也能写,但是效果还是差点意思。 | 这个模型的作用就差点意思,把图片的信息压缩到潜在空间中去,实际反馈在图片的中的效果就是加不加滤镜,这个学到后面再研究 |
总结一下,底模就是决定了大方向,你要画二次元的图片、显示风格的图片等等。Lora就是纠正一下底模。
civita介绍
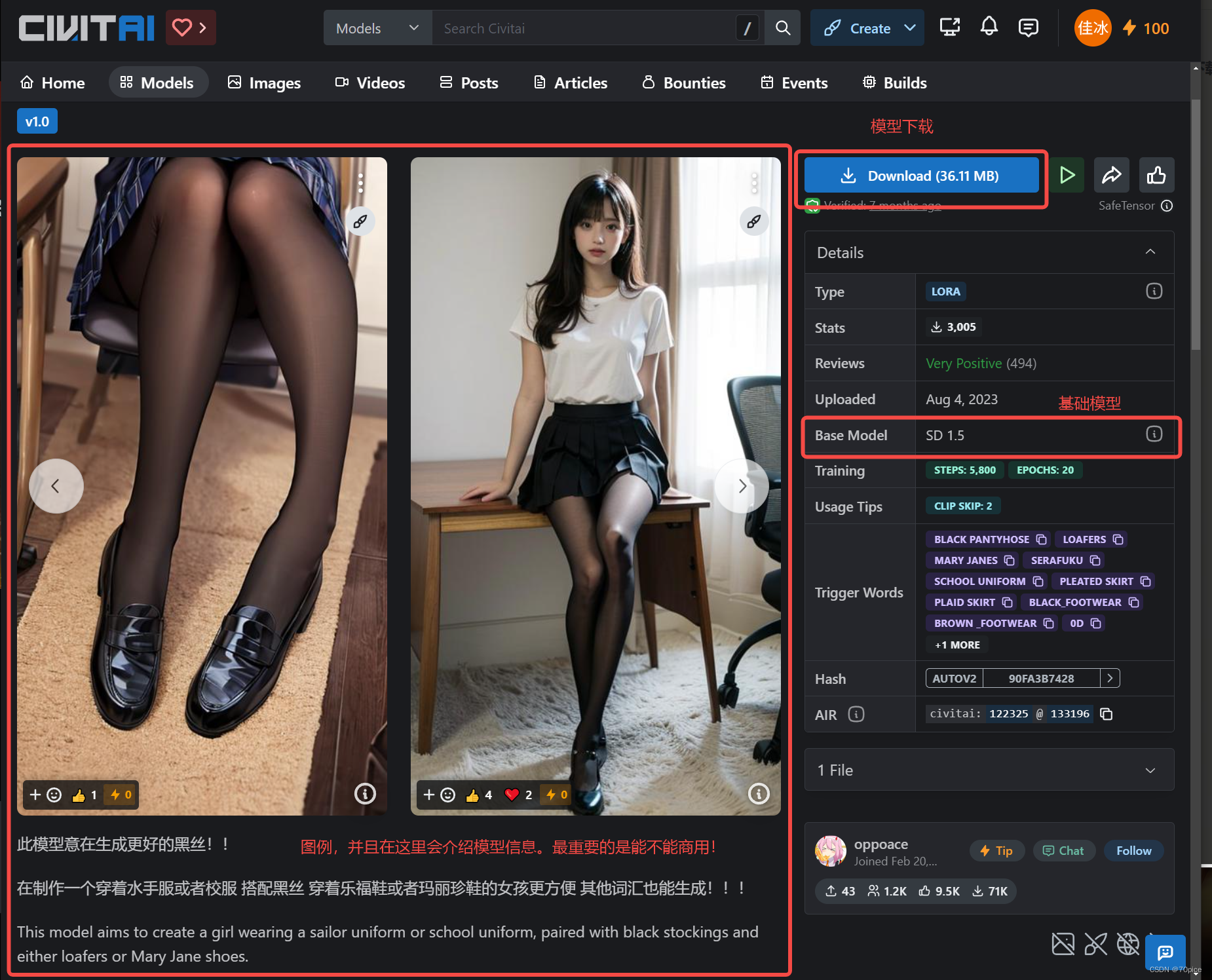
Lora介绍
如果神经网络用 Y = WX的方式来表示,那么神经网络的训练核心就是通过反向传播的方式去训练W。训练不是一蹴而就的,而是通过一次一次的迭代训练成的。每一次训练,就是在对W这个矩阵中的每一个元素做加减肥。那么Lora就是记录这个差值的矩阵集合。
举个例子
有一个 2 * 2 的矩阵
1
1
1
1
这样的好处在于,在后面反向传播中,矩阵的计算是非常复杂的,使用Lora可以降低计算的难度。并且Lora记录差值,相对较小。并且还可以通过矩阵分解的方式进一步拆分Lora。

