
- 1基于天问51-Core自制开发WIFI模块连接MQTT&巴法云平台-微信小程序显示温度数据_天问51开发板运行的程序实例
- 2红外NEC通信协议_nec协议
- 3Android ipc数据传输方式之一 AIDL_android aidl传递 string c++
- 4卷积操作的过程、参数说明、用CNN实现分类任务的代码_cnn classifier conv-k-n
- 5linux usb ehci 驱动解读(一)_ehci 驱动分析
- 6矩阵错题本
- 7Trunk详解(笔记)_trunk类型
- 8基于人脸关键点的疲劳检测_基于人脸特征点实现疲劳检测_基于人脸识别的疲劳驾驶检测-csdn博客
- 9学PS基础:Photoshop 技能167个_photoshop中,如果要使图像按屏幕大小缩放,可以通过( )来实现
- 10Harmony开发 eTs公共样式抽取_鸿蒙开发怎么适用公共样式
Elasticsearch:dense vector 数据类型及标量量化_dense vector 设置精度
赞
踩

密集向量(dense_vector)字段类型存储数值的密集向量。 密集向量场主要用于 k 最近邻 (kNN) 搜索。
dense_vector 类型不支持聚合或排序。
默认情况下,你可以基于 element_type 添加一个 dend_vector 字段作为 float 数值数组:
- PUT my-index
- {
- "mappings": {
- "properties": {
- "my_vector": {
- "type": "dense_vector",
- "dims": 3
- },
- "my_text" : {
- "type" : "keyword"
- }
- }
- }
- }
-
- PUT my-index/_doc/1
- {
- "my_text" : "text1",
- "my_vector" : [0.5, 10, 6]
- }
-
- PUT my-index/_doc/2
- {
- "my_text" : "text2",
- "my_vector" : [-0.5, 10, 10]
- }

注意:与大多数其他数据类型不同,密集向量始终是单值。 不可能在一个密集向量字段中存储多个值。
kNN 搜索的索引向量
k 最近邻 (kNN) 搜索可找到与查询向量最接近的 k 个向量(通过相似性度量来衡量)。
密集向量字段可用于对 script_score 查询中的文档进行排名。 这使你可以通过扫描所有文档并按相似度对它们进行排名来执行强力(brute-force) kNN 搜索。
在许多情况下,强力 kNN 搜索效率不够高。 因此,dense_vector 类型支持将向量索引到专门的数据结构中,以支持通过 search API 中的 knn 选项进行快速 kNN 检索。
大小在 128 到 4096 之间的浮点元素的未映射数组字段动态映射为具有默认余弦相似度的密集向量。 你可以通过将字段显式映射为具有所需 similarity 的 dend_vector 来覆盖默认 similarity。
默认情况下为密集向量场启用索引。 启用索引后,你可以定义在 kNN 搜索中使用的向量 similarity:
- PUT my-index-2
- {
- "mappings": {
- "properties": {
- "my_vector": {
- "type": "dense_vector",
- "dims": 3,
- "similarity": "dot_product"
- }
- }
- }
- }
注意:用于近似 kNN 搜索的索引向量是一个昂贵的过程。 提取包含启用了 index 的向量字段的文档可能需要花费大量时间。 请参阅 k 最近邻 (kNN) 搜索以了解有关内存要求的更多信息。
你可以通过将 index 参数设置为 false 来禁用索引:
- PUT my-index-2
- {
- "mappings": {
- "properties": {
- "my_vector": {
- "type": "dense_vector",
- "dims": 3,
- "index": false
- }
- }
- }
- }
Elasticsearch 使用 HNSW 算法来支持高效的 kNN 搜索。 与大多数 kNN 算法一样,HNSW 是一种近似方法,会牺牲结果精度以提高速度。
自动量化向量以进行 kNN 搜索
密集向量类型支持量化以减少搜索浮点向量时所需的内存占用。 目前唯一支持的量化方法是 int8,并且提供的向量 element_type 必须是 float。 要使用量化索引,你可以将索引类型设置为 int8_hnsw。
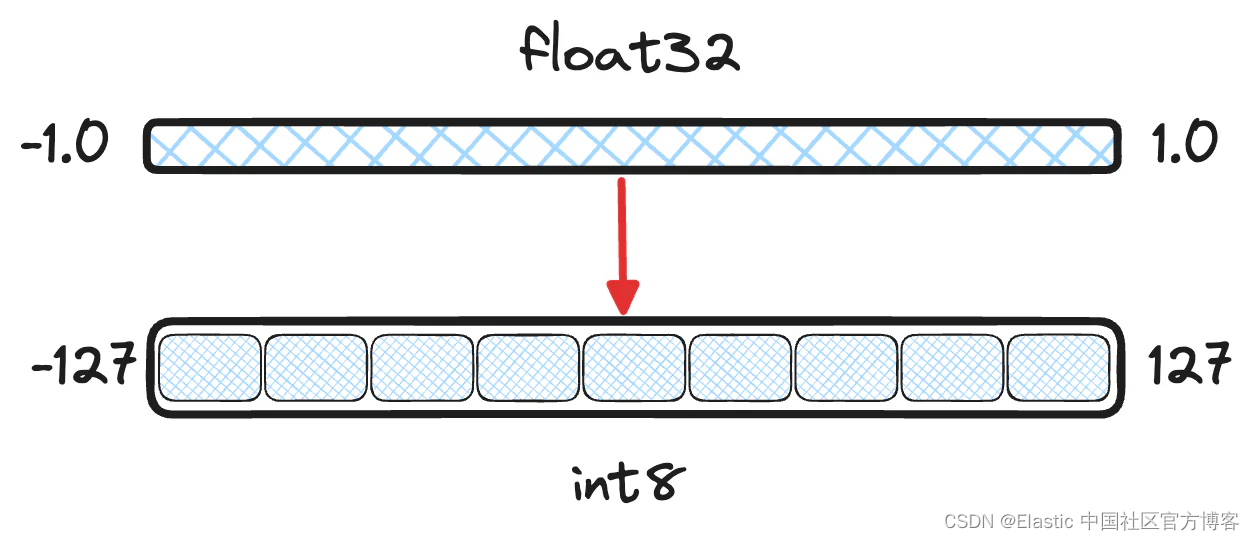
使用 int8_hnsw 索引时,每个浮点向量的维度都会量化为 1 字节整数。 这可以减少多达 75% 的内存占用,但会牺牲一定的准确性。 然而,由于存储量化向量和原始向量的开销,磁盘使用量可能会增加 25%。
- PUT my-byte-quantized-index
- {
- "mappings": {
- "properties": {
- "my_vector": {
- "type": "dense_vector",
- "dims": 3,
- "index": true,
- "index_options": {
- "type": "int8_hnsw"
- }
- }
- }
- }
- }
密集向量场的参数
接受以下映射参数:
element_type
(可选,字符串)用于对向量进行编码的数据类型。 支持的数据类型为 float(默认)和 byte。 float 对每个维度的 4 字节浮点值进行索引。 byte 索引每个维度的 1-byte 整数值。 使用 byte 可以显着减小索引大小,但代价是精度较低。 使用字节的向量需要具有 -128 到 127 之间整数值的维度,包括索引和搜索。
dims
(可选,整数)向量维数。 不能超过 4096。如果未指定 dims,它将设置为添加到该字段的第一个向量的长度。
index
(可选,布尔值)如果为 true,你可以使用 kNN 搜索 API 搜索此字段。 默认为 true。
similarity
(可选*,字符串)kNN 搜索中使用的向量相似度度量。 文档根据向量场与查询向量的相似度进行排名。 每个文档的 _score 将从相似度中得出,以确保分数为正并且分数越高对应于越高的排名。 默认为余弦。
* 该参数只有当 index 为 true 时才能指定。
| 值 | 描述 |
|---|---|
| l2_norm | 根据向量之间的 L2 距离(也称为欧氏距离)计算相似度。 文档 _score 的计算公式为 1 / (1 + l2_norm(query, vector)^2)。 |
| dot_product | 计算两个单位向量的点积。 此选项提供了执行余弦相似度的优化方法。 约定和计算得分由 element_type 定义。 当 element_type 为 float 时,所有向量都必须是 unit 长度,包括文档向量和查询向量。 文档 _score 的计算方式为 (1 + dot_product(query, vector)) / 2。 当 element_type 为 byte 时,所有向量必须具有相同的长度,包括文档向量和查询向量,否则结果将不准确。 文档 _score 的计算公式为 0.5 + (dot_product(query, vector) / (32768 * dims)),其中 dims 是每个向量的维度数。 |
| cosine | 计算余弦相似度。 请注意,执行余弦相似度的最有效方法是将所有向量标准化为单位长度,并改为使用 dot_product。 仅当需要保留原始向量且无法提前对其进行标准化时,才应使用余弦。 文档 _score 的计算方式为 (1 + cosine(query, vector)) / 2。余弦相似度不允许向量的幅值为零,因为在这种情况下未定义余弦。 |
| max_inner_product | 计算两个向量的最大内积。 这与 dot_product 类似,但不需要向量标准化。 这意味着每个向量的大小都会显着影响分数。 调整文档 _score 以防止出现负值。 对于 max_inner_product 值 < 0,_score 为 1 / (1 + -1 * max_inner_product(query, vector))。 对于非负 max_inner_product 结果,_score 计算为 max_inner_product(query, vector) + 1。 |
注意:尽管它们在概念上相关,但相似性参数与文本字段相似性不同,并且接受一组不同的选项。
index_options
(可选*,对象)配置 kNN 索引算法的可选部分。 HNSW 算法有两个影响数据结构构建方式的内部参数。 可以调整这些以提高结果的准确性,但代价是索引速度较慢。
* 该参数只有当 index 为 true 时才能指定。
| 属性 | 描述 |
|---|---|
| type | (必需,字符串)要使用的 kNN 算法的类型。 可以是 hnsw 或 int8_hnsw。 |
| m | (可选,整数)HNSW 图中每个节点将连接到的邻居数量。 默认为 16。 |
| ef_construction | (可选,整数)在组装每个新节点的最近邻居列表时要跟踪的候选者数量。 默认为 100。 |
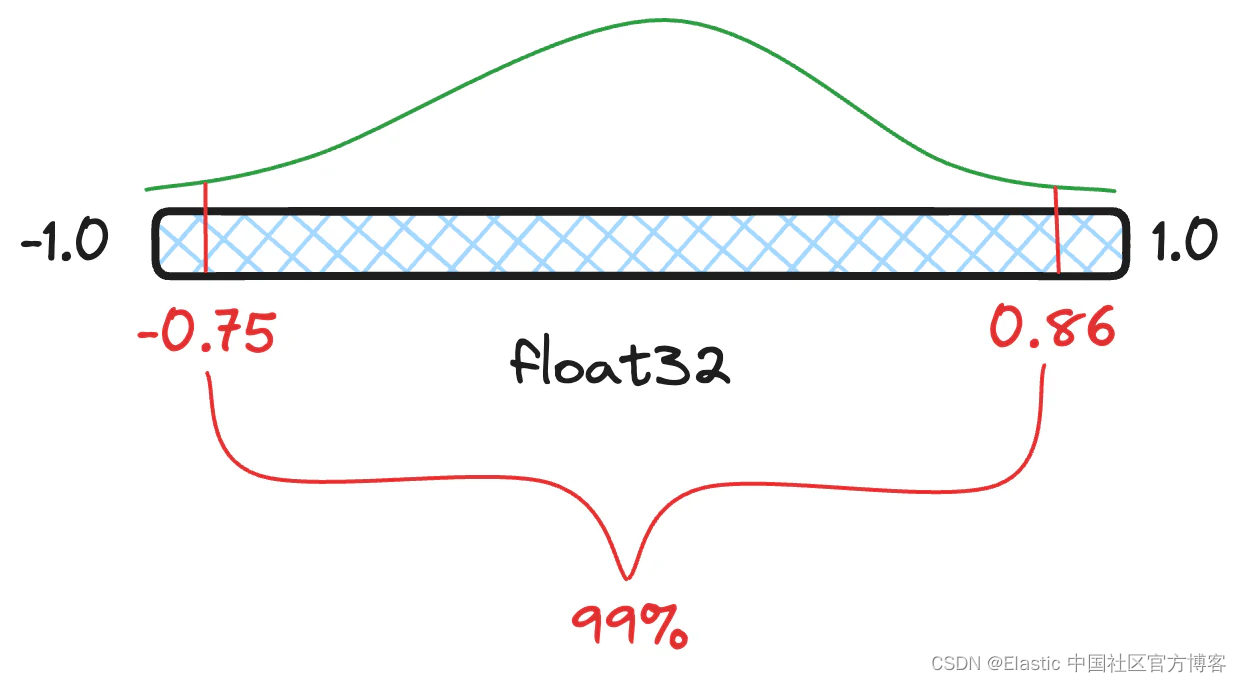
| confidence_interval | (可选,float)仅适用于 int8_hnsw 索引类型。 量化向量时使用的置信区间可以是 0.90 和 1.0 之间(包括 0.90 和 1.0)之间的任何值。 该值限制计算量化阈值时使用的值。 例如,值 0.95 在计算量化阈值时将仅使用中间 95% 的值(例如,最高和最低 2.5% 的值将被忽略)。 默认为 1/(dims + 1)。 |
Synthetic _source
重要:Synthetic _source 通常仅适用于 TSDB 索引(index.mode 设置为 time_series 的索引)。 对于其他索引,synthetic _source 处于技术预览阶段。 技术预览版中的功能可能会在未来版本中更改或删除。 Elastic 将努力解决任何问题,但技术预览版中的功能不受官方 GA 功能的支持 SLA 的约束。
dense_vector 字段支持 synthetic _source。
更多阅读:

