
- 1HTML简易的用户名密码登录页面_艾孜尔江撰_简单账号密码登陆页面html代码
- 2vue-router 路由跳转传参刷新页面后参数丢失问题_vue跳转后路由刷新浏览器参刷新页面参数丢失
- 3HCIA实验,华为ensp基础实验。_[r1]aaa [r1-aaa]local-user huawei password cipher
- 4微服务容器化如何实现顺序启动_微服务依次启动
- 5关于Airtest的使用探索
- 6批量更改图片名称_批量修改图片名称
- 7CentOS6上编译OpenSSH为Rpm包并升级到新版本_centos6.9 openssh rpm
- 8CHAPTER 1:Numerical Techniques 第一章:数值运算技术_ntnyn
- 9windows insightface库 人脸识别入门教程_insightface教程
- 10Linux gcc g++ 编译C++程序_g++编译c++的阶乘程序
CIKM 2021 | Deep Retrieval:字节跳动深度召回模型论文精读
赞
踩

©作者 | 杰尼小子
单位 | 字节跳动
研究方向 | 推荐算法

文章动机/出发点
这是一篇字节跳动发表在 CIKM 2021 的论文,这一项工作在字节很多业务都上线了,效果很不错。但是这篇文章整体读下来,感觉有挺多地方让人挺迷茫的,有可能是因为文章篇幅有限。值得一提的是,这篇 paper 曾经投过 ICLR,有 open review,所以最后也会总结一下 reviewer 的问题同时写一下自己的一些思考。

论文名称:
Deep Retrieval: Learning A Retrievable Structure for Large-Scale Recommendations
论文名称:
https://arxiv.org/abs/2007.07203
To the best of our knowledge, DR is among the first non-ANN algorithms successfully deployed at the scale of hundreds of millions of items for industrial recommendation systems.
正如文章所说的,作者提出了一种非 ANN based 召回方法,之前的方法通常是基于 ANN(approximate nearest neighbors)或者 MIPS(maximum inner product search)的算法,这种算法有一些众所周知的问题:
基于 ANN 的召回模型通常是双塔模型,User Tower 跟 Item Tower 通常是分开的,这就导致了用户的交互比较简单,只在最后內积的时候进行交互
而 ANN 跟 MIPS 算法比如:LSH, IVF-PQ, HNSW。是为了近似 Top K 或者搜索最大內积而设计的,并不是直接优化 user-item 训练样本。
另一个就是召回模型与索引构建是分开的,容易存在召回模型跟索引的版本不一致的问题,特别是新 item 进来的时候。
TDM 是阿里提出来的一种树召回模型,主要用来解决这种不一致问题,把之前基于內积模型的 two-stage 变成了直接学习训练样本的 one-stage 模型。但是作者认为这种方法存在一些问题:每个 item 都被映射到树中的一个叶节点,这使得树结构本身很难学习。在叶级别上可用的数据可能很稀少,并且可能无法提供足够的信号来为拥有数亿条目的推荐系统学习更精细的树结构。
因此作者也提出了 end-to-end 的方法,与 TDM 为主的树模型不同,每个 item 可以被分到多个 path 或者 cluster,从而可以改进一个叶子节点样本过少的问题。
作者针对內积模型的一些问题,所以 DR 是直接 end-to-end 的学习训练样本的,针对树模型的一些问题,所以 DR 可以让一个 item 属于多个 path/cluster。但其实 DR 的架构加了挺多东西,既没有做消融实验去分解每一部分的作用,也没有通过实验去解释如何解决了这些问题,只通过了一些“直觉上”的分析来解释为什么要 xxx,如果作者可以加上这一部分的实验分析个人感觉就是一个特别棒的的工作了,毕竟他的实际效果很有保证。

模型框架
第一次读完论文比较懵,原文写的比较分散,因此在这里我重新梳理逻辑,希望可以清晰易懂介绍一下 DR 的模型框架。
2.1 总体概述
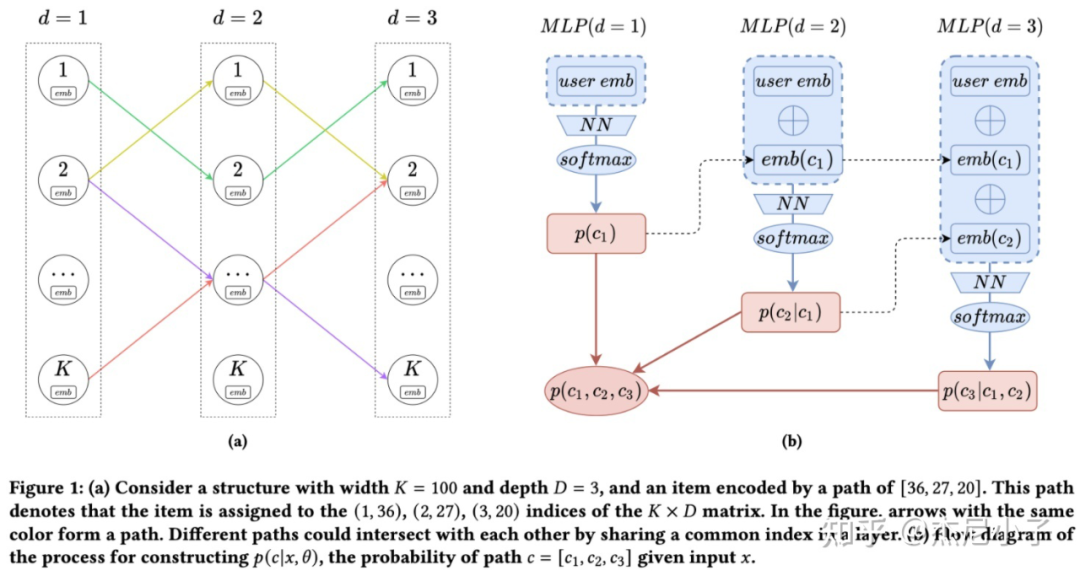
首先说一下 DR 的整体框架,如上图所示,DR 有 D 层网络,每一层是一个 K 维 softmax 的 MLP,每一层的输入是原始的 user emb 与前面每一层的 Embedding 进行 concat。因此这里有 条 path,每一条 path 都可以理解成一个 cluster。
DR 的目的就是:给定一个 user,把训练集这个用户互动过的所有 item(比如点击 item 等)映射到这 里面的某几个 cluster 中,每个 cluster 可以被表示成一个 D 维的向量,比如 [36, 27, 20],其中可以包括多个 item,每个item也可以属于多个 cluster。所有的 user 共享中间的网络,线上 serve 的时候,输入 user 信息(比如 user id)即可自动找到与其相关的 cluster,然后把每个 cluster 中的 item 当做召回的 item candidate.
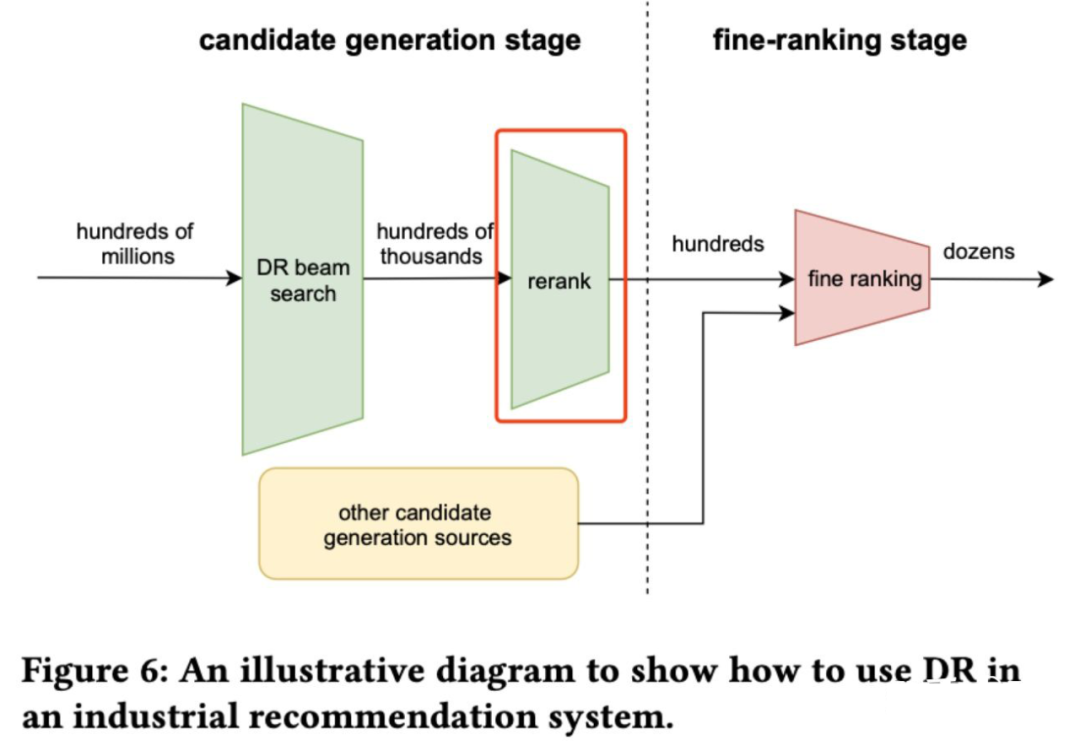
另外, 经过上述流程最后的召回候选集可能比较大,因此 DR 在后面又加了一个 rerank 模块,这里的 rerank 不是我们通常说的 精排后面的重排/混排, 而且用来对前面 DR 模型召回的 item 进行进一步过滤,如上图所示。也就是把前面 DR 召回的候选集当做新的训练集,送给后面的 rerank 模型, 论文里公开数据集离线实验使用的是 softmax 去学习,真正字节业务上使用的是 LR,softmax 分类的 loss 如下, 可以加深理解:
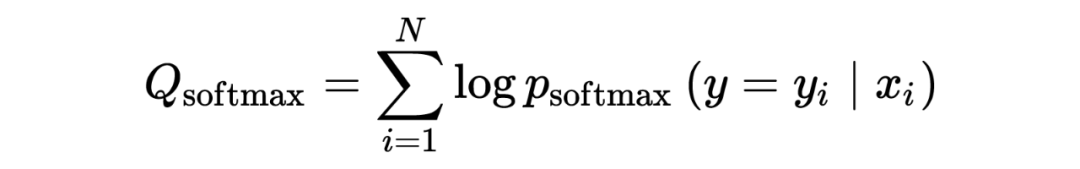
这里 softmax 输出的 size 是 V(所有 items 的数量),然后使用 sample softmax 进行优化。个人觉得这里目的是:给定 ,预测用户与这个 item 交互过的置信度,选出 top N 送入下面流程。
rerank 这一小节的名字叫做:Multi-task Learning and Reranking with Softmax Models,我其实没搞明白为啥是 multi-task 了。另外在 rerank 这里进行控量而不是在粗排那里过滤的原因是通常 DR 给的 item 很多,粗排阶段容易挤压别的路的候选集从而主导粗排的学习?
通过上述的整体框架,可以发现以下几个特点:
DR 的输入只用了 user 的信息,没有使用 item 的信息,与 YouTube DNN 类似
DR 的训练集只有正样本,没有负样本。
DR 不但要学习每一层网络的参数,也要学习给定 user 如何把一个 item 映射到某一个 cluster/path 里面(item-to-path mapping )。
之前 introduction 说基于內积的召回模型 user 跟 item 交互比较少,然后 DR 根本没用到 item 的信息……
接下来,我们详细介绍模型每一部分是如何学习的,先定义一下符号体系:
一共 D 层 MLP,每层 MLP 有 K 个 node
是所有 item 的 label
item-to-path mapping : 代表如何将一个 item 映射成 里面的某几条 path。
(x, y) 代表用户 x 与 item y 的一条正样本(比如点击,转化,点赞等)。
代表将 item y 映射成一条 path,其中 .
每一条 path 的概率是 D 层 MLP 每一层 node 概率的连乘。
2.2 网络参数的学习
之前说了,我们不但要学习 D 层 MLP 的参数,也要学习如何进行 item-to-path mapping,这里我们首先固定 path 的学习,也就是假设我们知道每个 item 最后属于哪几条 path 。
给定一个 N 条样本的训练集 ,对于其中一条 path 的最大 log 似然函数为:
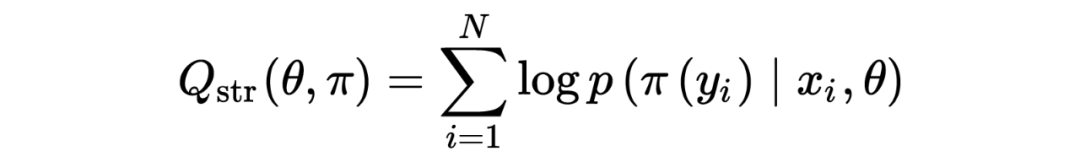
这里作者认为将每个 item 分类到一个 cluster 其实是不够的,比如巧克力可以是“food”,也可以是“gift”,因此作者将一个 item 映射到 J 个 path 里面,因此对于 itme 他的 path 表示为:,多条 path 的 log 似然函数表示为:

属于多条路径的概率是属于每条路径的概率之和。但是直接优化这个目标有一个很严重的问题,就是直接把所有的 item 都分类到某一个 path 即可,这样对于每个 user 属于这个 path 的概率都是 1,因此所有的 item 都在一个类别了,召回也就失效了。因此对上述函数加了惩罚:
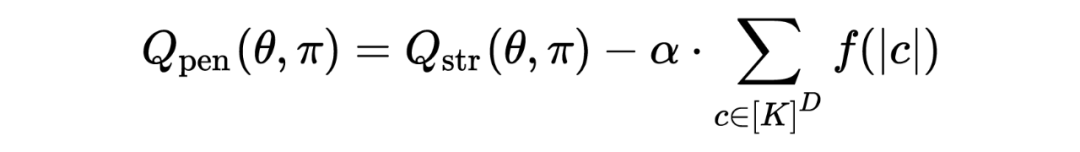
其中 是惩罚因子,这里 f 字节实验用的是 。联合之前的 rerank 学习,最后的 loss 就是 。
到这里我们就了解了当给定 path 的时候如何进行网络参数的优化,比较棘手的是如何确定每个 item 分到哪几个 path 里面。
2.3 Beam Search for Inference
在讲如何学习 之前,首先讲一下如何 inference,也就是给定一个用户 x,如何学习他属于哪个 cluster。这里的场景有点类似 NLP 里面的 seq2seq 的 inference,主流有 Greedy Search 与 Beam Search,文章使用的是 Beam Search。
设 B 为Beam Search的搜索参数,每一层有 K*B 个候选,复杂度为:O(KBlogB),整体复杂度为:O(DKBlogB)。具体的算法流程如下:

2.4 item-to-path learning
下面来介绍重头戏,就是一个 item 如何确定去哪几个 path,这个跟网络参数不一样的是,他不是连续的不用能梯度下降进行优化, 因此作者使用 EM 的形式交替进行优化。首先随机初始化 跟其他参数,在第 t 个 epoch:
跟其他参数,在第 t 个 epoch:
E-step:锁住 ,通过最大化 structure objective 优化 。
M-step:同样通过最大化 structure objective 更新 。
首先不考虑惩罚项,尝试优化 ,给定 ,我们需要选出 来让 最大,重新梳理一下公式:
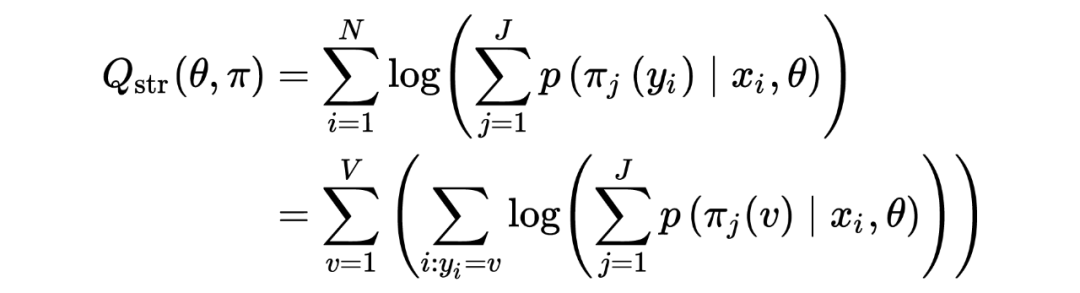
外面的加法是所有 item 这一层次上的 ,里面这个加法是 item 出现在所有样本这一层次上的。最直接方法就是枚举 中路径,然后找出 top J 大的路径,这显然不可能。因此作者尝试根据 优化公式的上界:
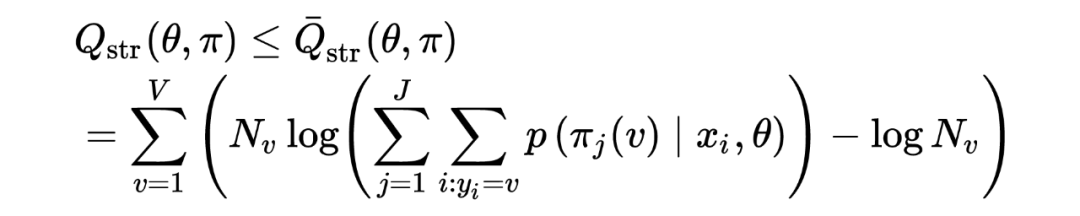
其中 样本 出现在训练集的次数,主要把 放到了 log 里面。定义 score functools 为:
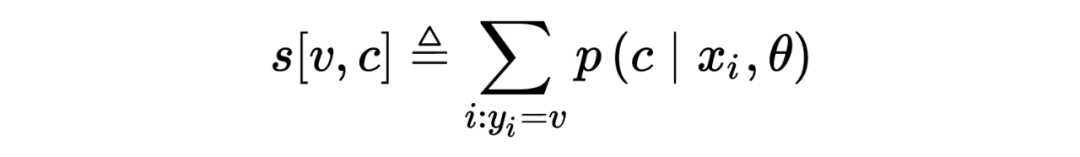
所以 score 可以理解为 item 在 c 上的所有概率和,当然不可能把所有的 c 都枚举一遍,因此使用了 beam search 挑出来 top S 个 path(具体多少文章没有说),然后其他的 path 得分设置为 0。
一般是最大化一个函数的下界,最小化一个函数的上界来优化这个函数,这里是相反的,作者指出这里不能保证可以优化函数,但是他们实验是有效果的,因此这样去优化。
现在知道了 的定义,结合最终目标 ,我们 M-Step 的优化目标是:
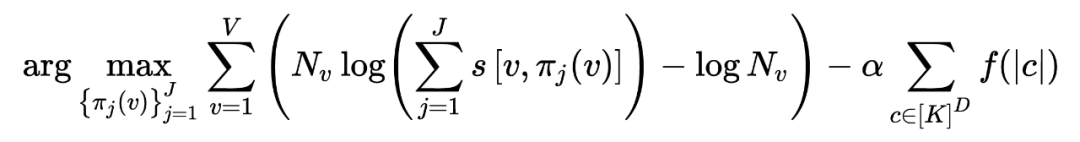
其中 与要优化的无关,所以可以直接去掉,最终的优化目标就是
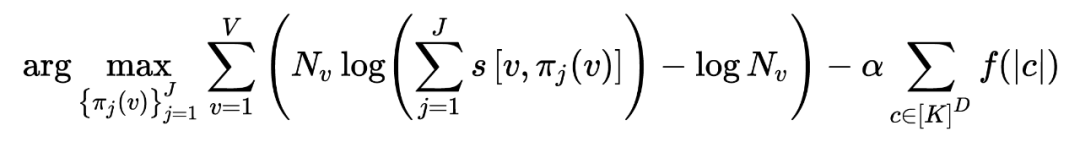
以上函数没有封闭解(closed-form solution),所以使用坐标下降法求解(coordinate descent algorithm),锁住其他 item 只优化其中一个 item 的 。对于每个 v 我们一步一步的学习他的 。详细的算法流程如下:

对于第 i 步,选择 的收益为:
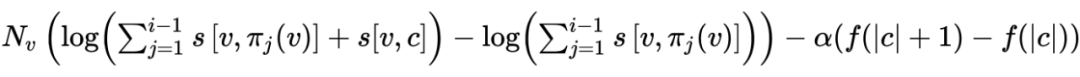
因此我们就从 i=1 开始每次贪心的选择增益最大的最为当前 path。作者指出,3 到 5 次迭代就足以保证算法收敛。时间复杂度随词汇量 V、路径多样性 J 和候选路径数量 S 呈线性增长。
2.5 两个数据流合并score
因为字节是流式计算,所以肯定是要合并数据流的, 基本的思想就是追踪 top S 的 score,对于 item v 我们有一个 score list ,然后新来一批数据,我们有了新的 score list ,合并规则如下:

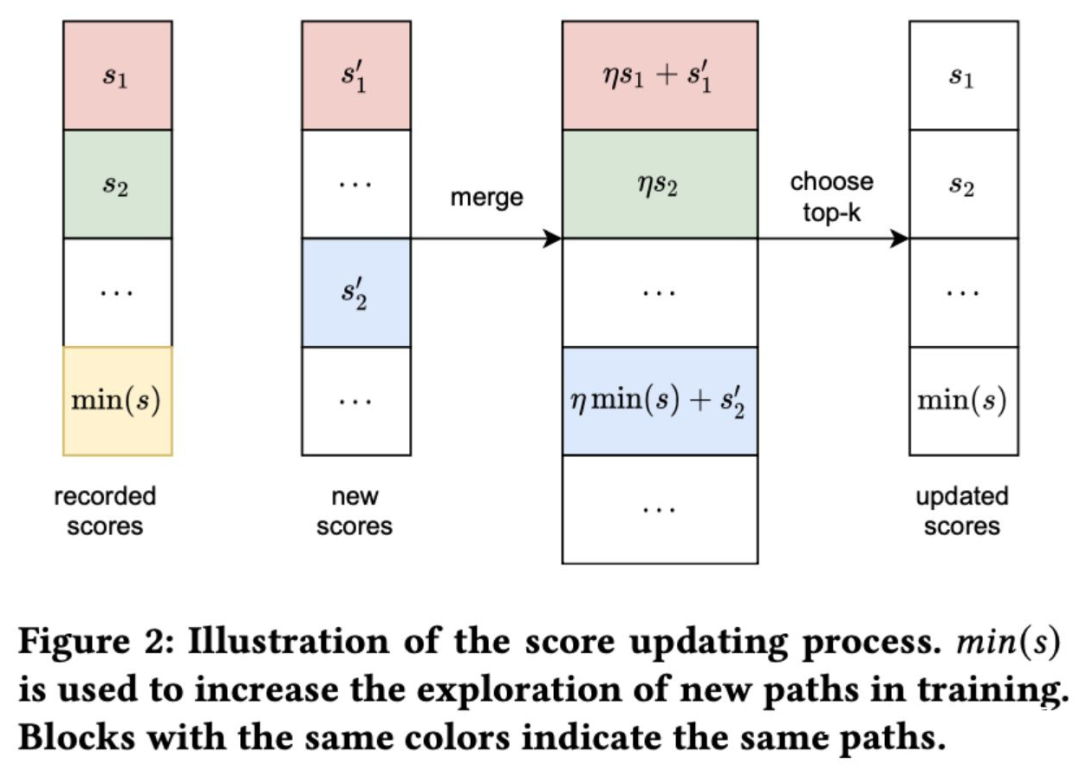
作者指出这种方法增加了在流方式中探索新路径的可能性。

实验
因为实验做的比较少,重点也比较少,这里就简单一说:
离线公开数据集这里因为训练集测试集是分开的,因此没有使用 user id 去提取 Embedding,而是截取用户历史行为到 69(多了截断少了补 default),过一个 GRU 获取最后的 emb 当做输入。
实验结果:
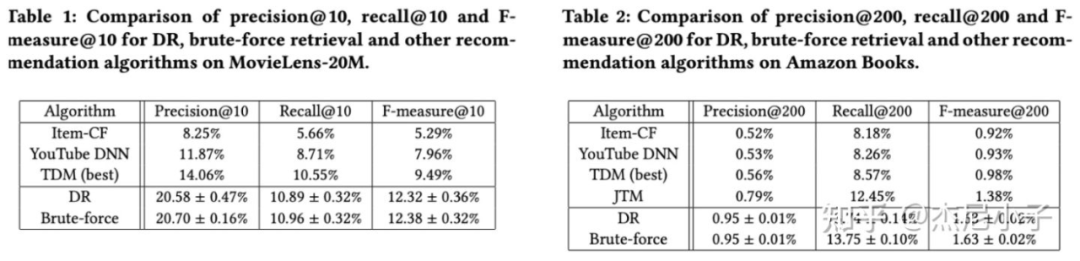
超参的影响,都在亚马逊数据集上做的,没必要分析了:
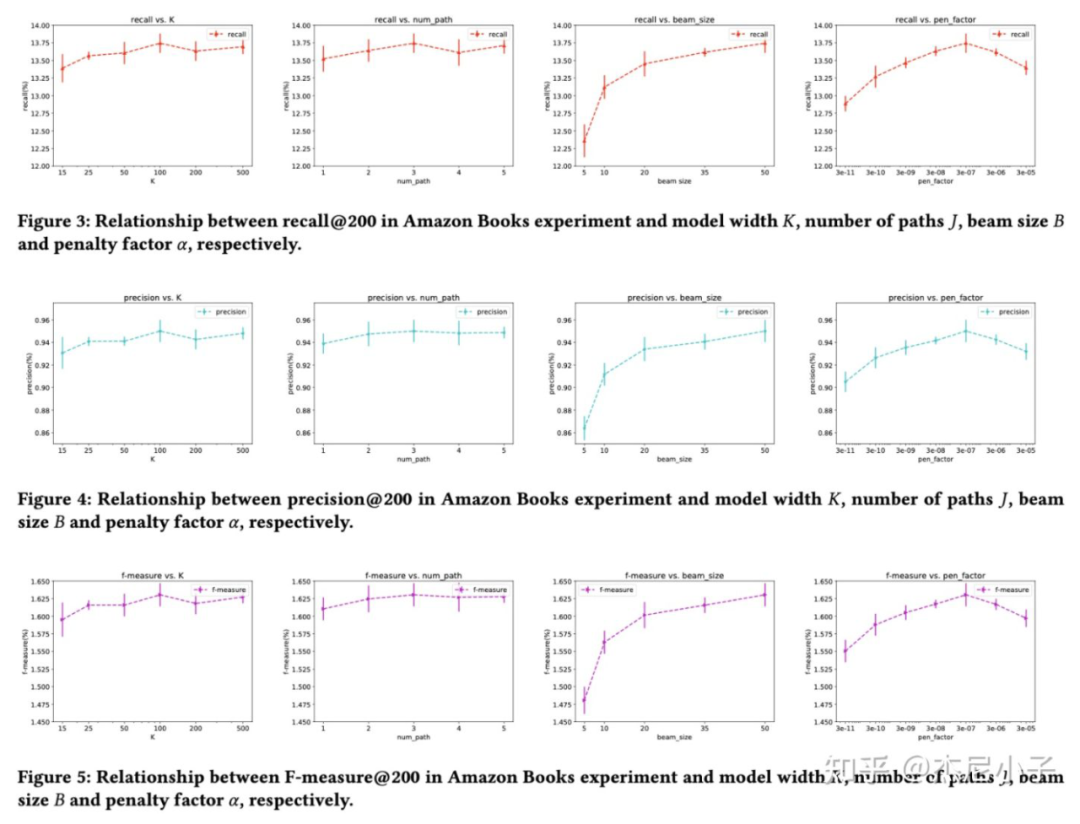
在线的结果:
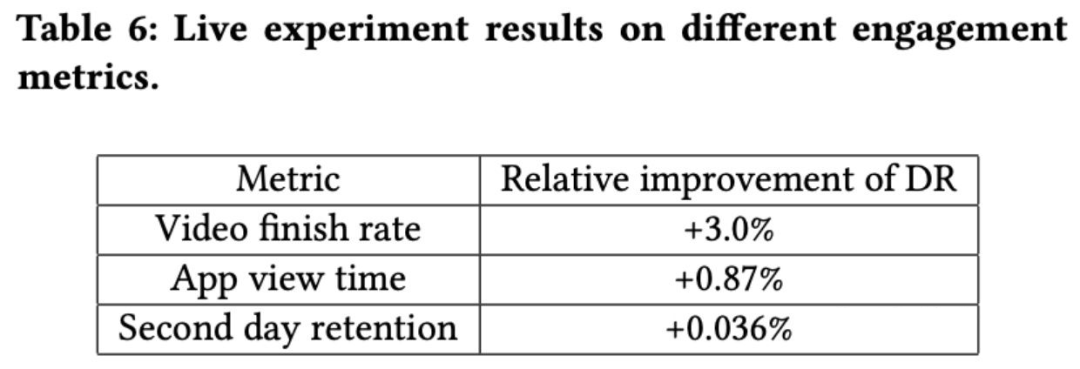
作者发现 a/b 测试的时候,DR 对于一些长尾视频以及长尾作者比较友好,他们认为在 DR 结构的每个路径中,item 是不可区分的,这允许检索不太受欢迎的 item,只要它们与受欢迎的 item 共享一些类似的行为。
DR 适合于流训练,而且构建检索结构的时间比 HNSW 要少得多,因为 DR 的 M-step 中不涉及任何用户或项目嵌入的计算。用多线程 CPU 实现处理所有项目大约需要 10 分钟。

ICLR review
这里放一些 ICLR 的 review(review 地址 [1]),可以一起思考一些问题,因为作者没有进行 rebuttal,所以是看不到作者的回复的,很多 review 真的是一针见血。
The paper lacks a motivation for using the proposed scheme. It says that for tree-based models, the number of parameters is proportional to the number of clusters and hence it is a problem. This is not clear why this is such a problem. Successful application of tree-structure for large-scale problem has been demonstrated in [1,2]. Also, it is not clear how the proposed method addresses data scarcity, which according to the paper happens only in tree-based methods, and not in the proposed method as there are no leaves.
It is not clear how the proposed structure model (of using K \times D matrix) is different from the Chen etal 2018. The differences and similarities compared to this work should be clearly specified. Also, what seems to be missing is why such an architecture of using stacked multi-layer perceptrons should lead to better performance especially in positive data-scarcity situations where most of the users 'like' or 'buy' only few items.
The experimental comparison looks unclear and incomplete. The comparison should also be done with the approach proposed in Zhou etal 2020 ICML paper. At the end of Page 6 it is said that the results of JTM were only available for Amazon Books. How do you make sure that same training and test split (as in JTM) is used as the description says that test and validation set is done randomly. Also, it would also be good to see the code and be able to reproduce the results.
References of some key papers are based on arxiv versions, such as Chen etal 2018 and Zhou etal. 2020, where both the papers have been accepted in ICML conference of respective years.
The authors mainly claim that the objective of learning vector representation and good inner-product search are not well aligned, and the dependence on inner-products of user/item embeddings may not be sufficient to capture their interactions. This is an ongoing research discussion on this domain. I'd recommend the authors to refer to a recent paper, proposing the opposite direction from this submission: Neural Collaborative Filtering vs. Matrix Factorization Revisited (RecSys 2020) arxiv.org/abs/2005.0968
According to Figure 1, a user embedding is given as an input, and the proposed model outputs probability distribution over all possible item codes, which in turn interpreted as items. That being said, it seems the user embedding is highly important in this model. A user can be modeled in a various ways, e.g., as a sequence of items consumed, or using some meta-data. If the user embeddings are not representative enough, the proposed model may not work, and on the other hand, if the user embedding is strong, it will estimate the probs more precisely. We would like to see more discussion on this.
In the experiment, there are multiple points that can be addressed. (a) Related to the point #2, the quality of embeddings is not controlled. Thus, comparing DR against brute-force proves that the proposed method is effective on MIPS, but not on the end-to-end retrieval. Ideally, we'd like to see experiments with multiple SOTA embeddings to see if applying DR to those embeddings still improves end-to-end retrieval performance. See examples below. (b) The baselines used in the experiment are not representing the current SOTA. Item-based CF is quite an old method, and YouTube DNN is not fully reproducible due to the discrepancy on input features (which are not publicly available outside of YouTube). We recommend comparing against / using embeddings of LLORMA (JMLR'16), EASE^R (WWW'19), and RecVAE (WSDM'20). (c) Evaluation metrics are somewhat arbitrary. The authors used only one k for P@k, R@k, and F1@k, arbitrarily chosen for each dataset. This may look like a cherry-picking, so we recommend to report scores with multiple k, e.g., {1, 5, 10, 50, 100}. Taking a metric like MAP or NDCG is another option.
The main contribution of this paper seems faster retrieval on MIPS. Overall, the paper is well-written. We recommend adding more intuitive description why the proposed mathematical form guarantees / leads to the optimal / better alignment to the retrieval structure. That is, how/why the use of greedy search leads to the optimal selection of item codes.
The significant feature of the DR model (from the claim in the abstract) to encode all candidates in a discrete latent space. However, there are some previous attempts in this direction that are not discussed. For example VQ-VAE[1] also learns a discrete space. Another more related example is HashRec[2], which (end-to-end) learns binary codes for users and items for efficient hash table retrieval. It's not clear of the connections and why the proposed discrete structure is more suitable.
The experiments didn't show the superiority of the proposed method. As a retrieval method, the most common comparison method (e.g. github.com/erikbern/ann) is the plot of performance-retrieval time, which is absent in this paper. The paper didn't compare the efficiency against the baselines like TDM, JTM, or ANN-based models, which makes the experiments less convincing as the better performance may due to the longer retrieval time.
What's the performance of purely using softmax?
It seems only DR uses RNNs for sequential behavior modeling, while the baselines didn't. This'd be a unfair comparison, and sequential methods should be included if DR uses RNN and sequential actions for training.
I didn't understand the motivation of using the multi-path extension. As you already encode each item in D different clusters, this should be enough to express different aspects with a larger D. Why a multi-path variant is needed for making the model more expressive?
The Beam Search may not guarantee sub-linear time complexity due to the new hyper-parameter B. It's possible that a very large B is needed for retrieving enough candidates.

一些疑问
1. EM 的训练方式基于一个最大化函数上界的优化,收敛性怎么在理论上进行保证呢。
2. 如果不加原来的 rerank 效果会掉很多吗。
3. 如果 user 比较低活,可能 d 层 mlp 学习的不太好,会不会召回性能反而不好,可以考虑一下分人群看一下结果。
4. 论文并没有定性分析,好奇每个 path 里面的 item 真的足够相关吗,因为感觉 m-step 并没有哪里可以促进相关 item 映射成一个 path 的地方。

总结
这是一篇在字节很多场景已经取到很好效果的文章,但相对来说业务经验输出的少了一些,一些观点论证包括实验也少了一些。超参数很多,真正落地可能需要针对自己的业务进行大量的调参。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

