
- 1Eric6安装、配置及使用_eric6安装旧版
- 2华为手机tiktok怎么在国内看
- 3介绍golang限流库以及漏桶与令牌桶的实现原理_go x 漏桶
- 4Java中实现http请求的方式_java http请求
- 5Flutter框架:从入门到实战,构建跨平台移动应用的全流程解析
- 6关于源码阅读:源码资源、阅读工具、阅读方法_source code 和sourcetrail
- 7maven plugin 简单介绍和实战 (2021-05-29)
- 8amazon的一个大牛谈各种语言,包括c、c++、java、python、ruby、lisp、perl(翻译后的中文版)
- 9Docker 基本概念解读_docker理解
- 10CSS 伸缩动画输入框_动画伸缩input输入框
Python neo4j建立知识图谱,药品知识图谱,neo4j知识图谱,知识图谱的建立过程,智能用药知识图谱,智能问诊必备知识图谱
赞
踩
一、知识图谱概念
知识图谱的概念是由谷歌公司在2012年5月17日提出的,谷歌公司将以此为基础构建下一代智能化搜索引擎,知识图谱技术创造出一种全新的信息检索模式,为解决信息检索问题提供了新的思路。本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。现在的知识图谱已被用来泛指各种大规模的知识库。
知识图谱,简而言之就是图数据库,既可以存储信息,又能直观地表达两个实体之间的关系。
知识图谱的基本单位就是三元组,即“实体1”-“关系”-“实体2”,本文以药品的知识图谱为例,即“药品”-“适应症”-“疾病”,如图所示:
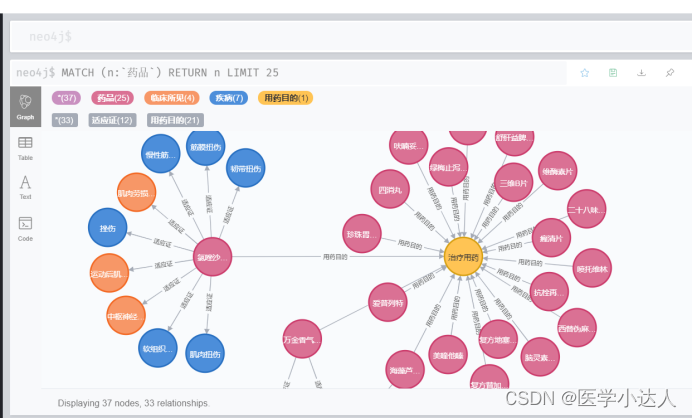
“氯唑沙宗片”-“适应症”-“韧带扭伤”
下面是实体标签和关系标签:
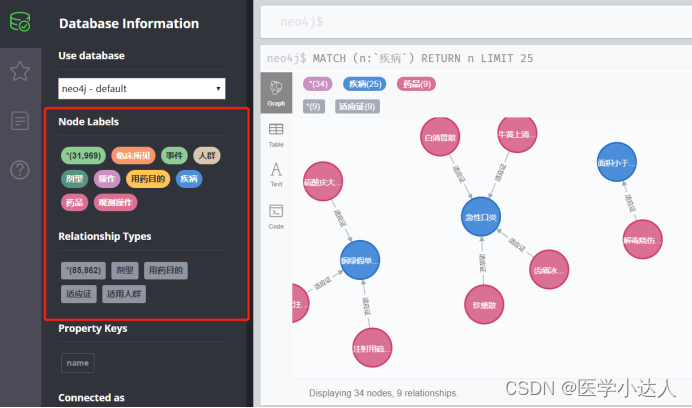
在示例中,实体类型主要有药品、疾病、观测操作、用药目的、临床所见、事件、人群等;关系类型主要有适应症、适用人群、剂型等。
二、知识图谱常用的数据库
在这里我只给出我知道和常用的,不全请见谅哈,哈哈哈哈哈
(1)Neo4j
Neo4j是一个流行的图形数据库,它是开源的。最近,Neo4j的社区版已经由遵循AGPL许可协议转向了遵循GPL许可协议。尽管如此,Neo4j的企业版依然使用AGPL许可。Neo4j基于Java实现,兼容ACID特性,也支持其他编程语言,如Ruby和Python。
比较简单易学,以上例子就是neo4j的数据效果。
官网:https://neo4j.com/
下载界面:Neo4j Download Center - Neo4j Graph Data Platform
(2)Nebula Graph
Nebula Graph是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
优点很多,很多大厂都在用,不细介绍,就是学起来比neo4j复杂一点。
下载安装包:(有学习指南)
Releases · vesoft-inc/nebula-console · GitHub
(3)OrientDB
OrientDB是兼具文档数据库的灵活性和图形数据库管理链接能力的可深层次扩展的文档-图形数据库管理系统。可选无模式、全模式或混合模式下。支持许多高级特性,诸如ACID事务、快速索引,原生和SQL查询功能。可以JSON格式导入、导出文档。若不执行昂贵的JOIN操作的话,如同关系数据库可在几毫秒内可检索数以百记的链接文档图。
学习起来也比较简单,研究生时候做过相关项目,体验一般。
官网:https://orientdb.com/
W3C教程:https://www.w3cschool.cn/orientdb/
三、基于neo4j进行知识图谱的实例创建
neo4j安装过程:略,我安装的是桌面版的neo4j
(1)数据准备
知识图谱的数据需要是三元组的形式,如果不是三元组,则需要我们通过代码转化为三元组的形式。本文的样例数据是:药品适应症和禁忌症数据,这个需要小伙伴们自己提前清洗数据
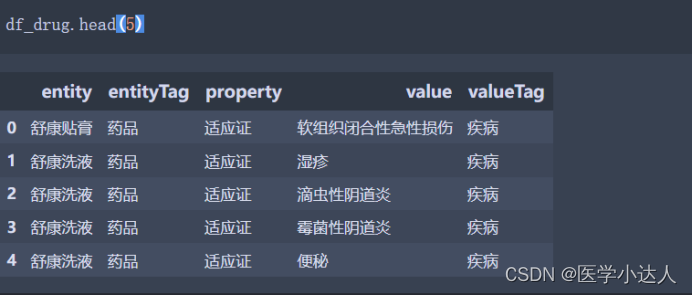
(2)Python 代码模块
应用的是py2neo包,这个是第三方开发的实用性比较高的开源模块,它支持批量导入neo4j数据库数据,进而快捷地建立图数据库,并且交互性比较好。用pip语句安装py2neo库即可。
- pip install py2neo
- pip3 install py2neo
- #清华镜像安装
- pip install --user -i https://pypi.tuna.tsinghua.edu.cn/simple py2neo
首先打开,neo4j桌面版,创建一个空如数据库,自己起名(不改名字就是默认的)和创建密码:
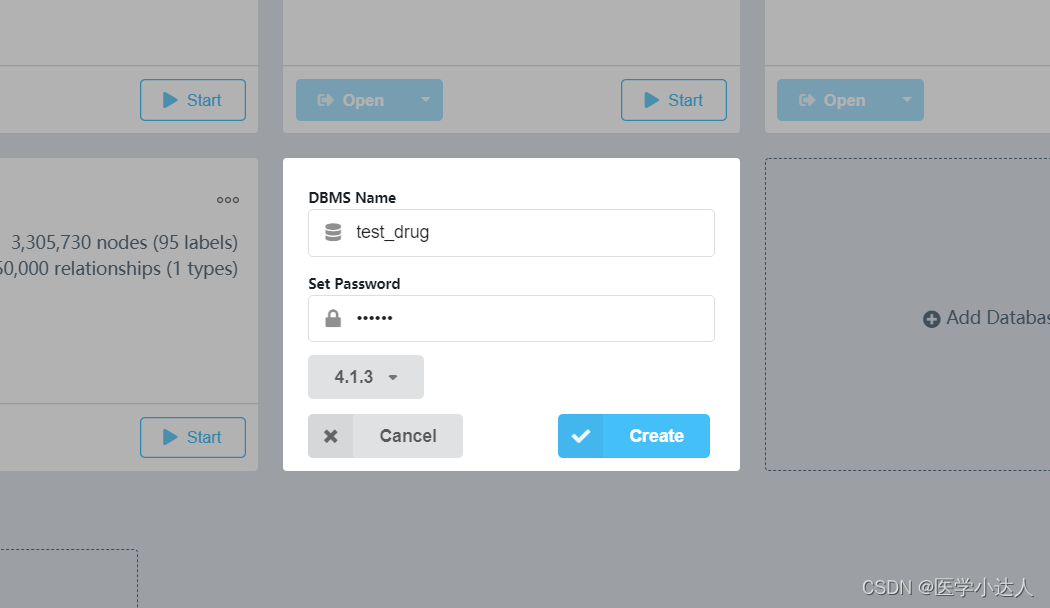
运行数据库,start:
打开python的IDE,在这里我用的是jupyter notebook,连接数据库,test_drug是我自己的数据库,需要改成你的,密码也是:
- from py2neo import Graph, Node, Relationship, NodeMatcher
- from py2neo.matching import RelationshipMatcher
-
- # 连接数据库
- graph = Graph("http://localhost:7474", username="test_drug", password='123456')
创建节点:
- p1 = Node("drug", name="伸腿瞪眼丸")
- p2 = Node("disease", name="精神恍惚")
- graph.create(p1)
- graph.create(p2)
创建关系:
- r = Relationship(p1, "特效治疗", p2)
- graph.create(r)
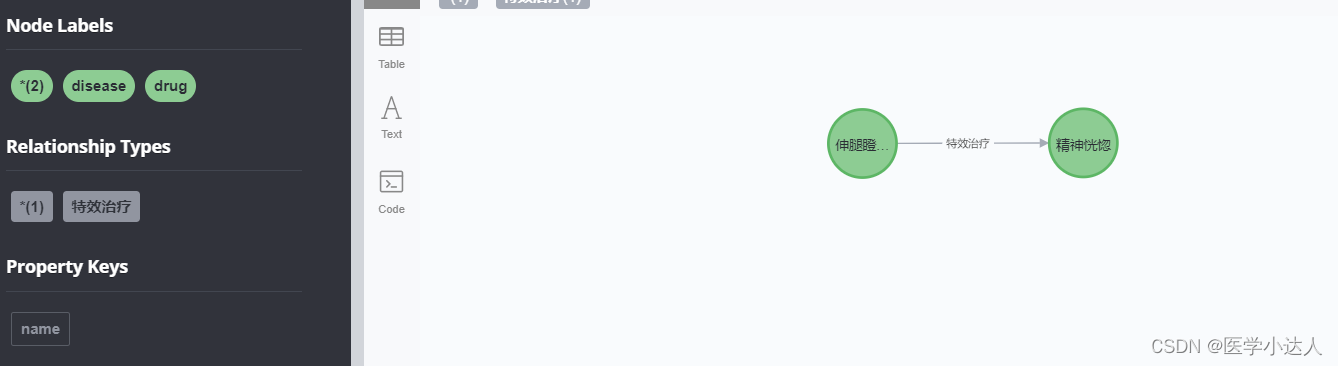
现在就创建了一个节点,打开neo4j检查一下:
(3)批量创建节点和关系
需要读取自己的数据,并转化为三元组的形式,创建节点集合,批量导入节点:
- # -------------------------------------------------------------------------------
- # coding:utf-8
- # Description:
- # Reference:
- # Author: dacongming
- # -------------------------------------------------------------------------------
-
- import pandas as pd
- from py2neo import Graph, Node, Relationship, NodeMatcher, Subgraph
- from py2neo.matching import RelationshipMatcher
-
- #读取数据
- df = pd.read_excel('drug.xlsx')
- test_graph = Graph('http://localhost:7474',username = 'test_drug',password = '123456')
-
- #创建节点集合
- a = df[['entity','entityTag']]
- b = df[['value','valueTag']]
- b.columns = ['entity','entityTag']
- entity = pd.concat([a,b])
-
- node_lis = []
- for i in entity.values:
- node = Node(i[1], name = i[0])
- node_lis.append(node)
- nodes=Subgraph(node_lis)
- test_graph.create(nodes)

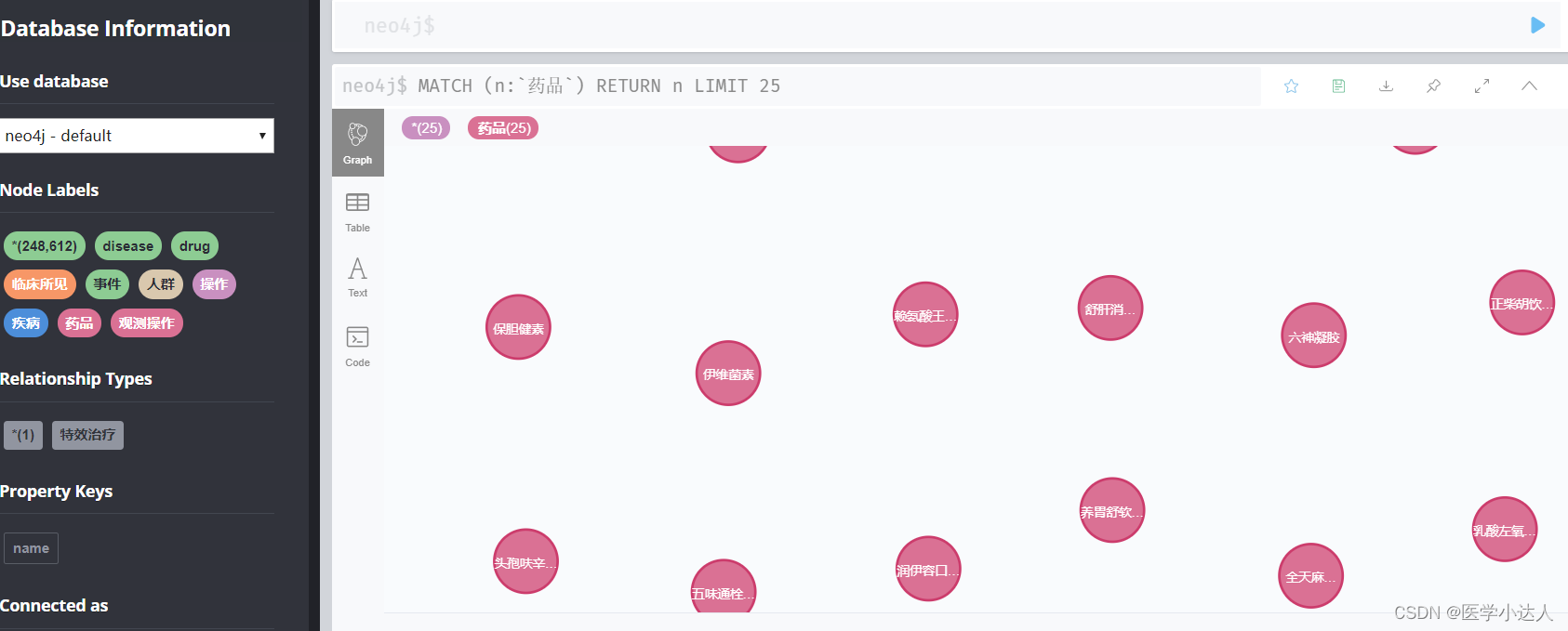
效果如图:
批量导入关系:
- #创建关系集合
- lis = []
- count = 0
- for i in df.values:
- count +=1
- print(count)
- c= test_graph.nodes.match(i[1],name=i[0]).first()
- d = test_graph.nodes.match(i[4],name=i[3]).first()
- rel_a=Relationship(c,i[2],d)
- lis.append(rel_a)
-
- #导入关系
- nodes=Subgraph(relationships=lis)
- test_graph.create(nodes)
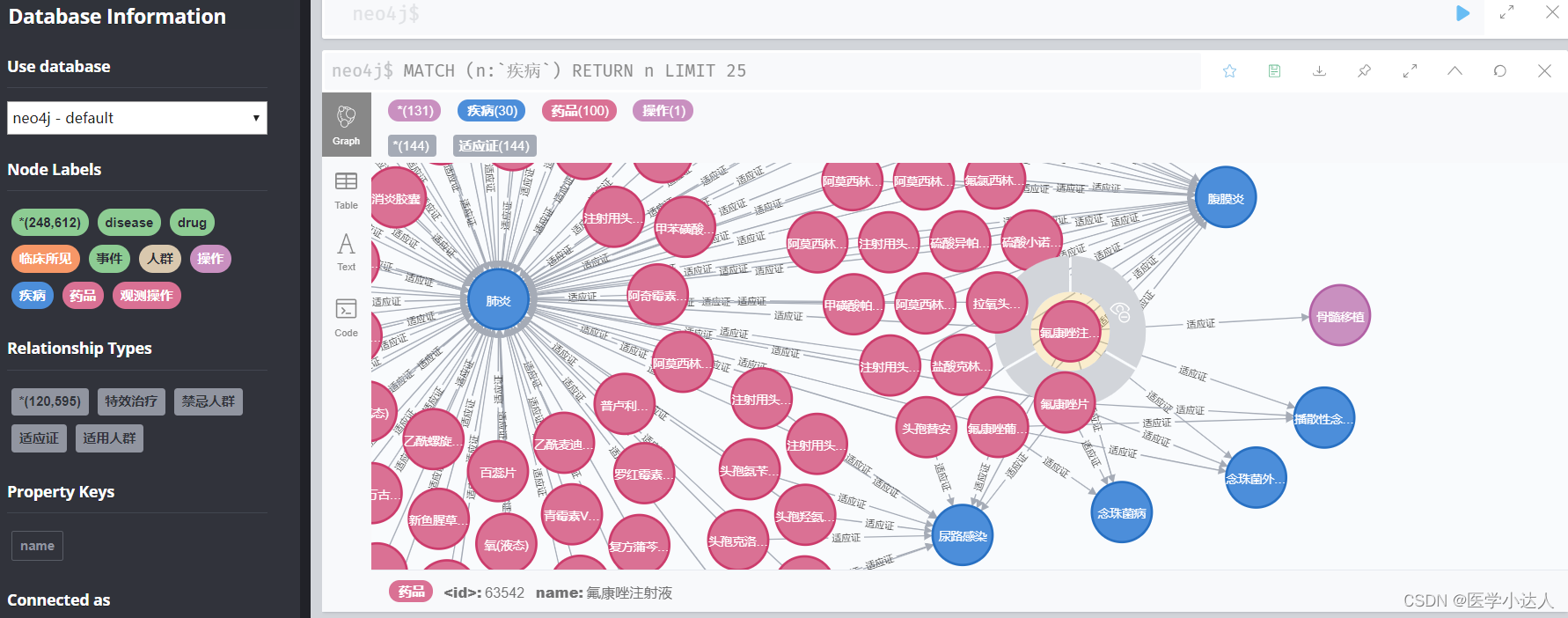
这样就建立了一个完整的知识图谱,导入了3个小时左右终于完成了,如图所示:
总结:在知识图谱的建设过程中,最复杂的是数据的获取和处理过程,数据越全面和越标准,搭建的知识图谱越实用,其赋能的业务场景也越广泛。在合理用药方面,知识图谱的应用有智能问诊、智能开药、药品审核等方向,这些都以全面和标准的数据为基础,所以,我们所要做的工作还有很多很多!

