
- 1应用服务器(App Server)_app服务器应用
- 2python 漂亮的excel_python 读取excel文件数据生成比较好看的html报告
- 3阿里新突破!自主创新的下一代匹配&推荐技术:任意深度学习+树状全库检索
- 4Android Studio 升级gradle异常_the following dependencies do not satisfy the requ
- 5mysql mvcc 读写阻塞_全网最全一篇MySQL数据库MVCC详解,不全你打我
- 6Trie树 c++实现_c++ trie树
- 7(九) android基础介绍--ContentProvinder内容提供者_android 11设置contentpro的值
- 8在Windows下远程桌面连接Linux - VNC篇_win远程桌面可以连接但vnc viewer
- 9基于变因子加权学习与邻代维度交叉策略的单目标优化算法求解——改进乌鸦算法
- 10RBTree——红黑树_undefined symbol: rbtree
【2024】英伟达吞噬世界!新架构超级GPU问世,AI算力一步提升30倍
赞
踩
「这才是我理想中的 GPU。」—— 黄仁勋。
「这不是演唱会。你们是来参加开发者大会的!」当黄仁勋走上舞台时,现场爆发出热烈的掌声。
就在今晨四点,位于加州圣荷西的英伟达公司,全球市值排名第三的科技巨头,举办了一年一度的GTC大会。

今年的GTC大会之所以引人关注,不仅是因为生成式AI技术的突破,同时英伟达的市值也有了显著增长。伴随着的是算力市场的火热,不仅硬件竞争激烈,软件竞争同样如火如荼。
英伟达推出的全新产品再次将AI芯片的性能标准推向了前所未有的高度。

「通用计算的时代已经过去,现在,我们需求更庞大的模型,因此也需要更强大的GPU,甚至需要将多个GPU叠加使用。”黄仁勋表示,“这样做并非为了降低成本,而是为了拓宽技术的边界。」
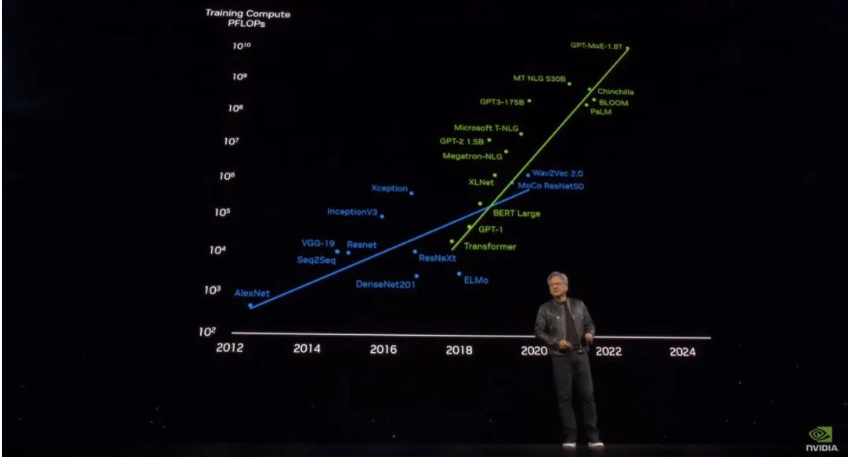
黄仁勋还提到,目前大型模型的参数量增长呈现出指数级的速度,OpenAI开发的最大型号已经达到了1.8T参数,需要处理上百亿的token。哪怕是拥有PetaFLOP级性能的GPU,想要训练这样庞大的模型也需要千年的时间。这也意味着GPT-4的参数量就达到了令人难以置信的1.8万亿。
于是,为了帮助全世界构建更大型的AI,英伟达带来了全新的GPU —— Blackwell。黄仁勋直白地说:「这是块非常非常大的 GPU!」
Blackwell GPU的发布标志着,近八年来,AI的算力增长了一千倍。网友们对此惊叹不已:Nvidia吞噬世界!

这块拥有2080亿个晶体管的Blackwell GPU
让竞争对手不知所措,后继乏力
尽管全球科技公司还在争抢H100芯片,但英伟达已经推出了下一代产品。
今天的GTC大会上,Blackwell平台正式亮相。随着Blackwell的推出,构建和运行数万亿参数的实时生成式AI大型语言模型的成本和能耗将降至原来的1/25。
Blackwell之名,是为了纪念首位入选美国国家科学院的非裔美国数学家、博弈论学者David Harold Blackwell。新平台继承了Hopper GPU架构,为加速计算设立了新的标杆。预计Blackwell架构的GPU将在今年晚些时候开始发货。

David Harold Blackwell。图源 britannica
作为英伟达首款采用MCM(多芯片封装)设计的GPU,Blackwell在同一芯片封装中集成了两颗GPU。
在发布会上,黄仁勋举着Blackwell(右手)对比了一下与Hopper (左手)GH100 GPU的体积大小。

It’s OK, Hopper.
他宣称,Blackwell将成为世界上最强大的芯片。这款GPU采用了先进的双Reticle台积电4NP(4N 工艺的改进版本)工艺,拥有2080亿晶体管,两个小芯片之间互联速度可达10TBps,大幅提升了处理性能。
重要的是,此设计不存在内存局部性问题或缓存问题,CUDA视其为单块GPU。
配备了高速度8Gbps、高容量192GB的HBM3E内存,AI算力可达到20 petaflops(FP4 精度),相比之下,上一代的H100 GPU仅有4 petaflops的性能。
这可能是世界上第一个如此高效整合的多die芯片平台,随着制造工艺升级速度的放缓,这也许是提升算力的唯一可行路径。

Blackwell不仅仅是芯片的名称,它也代表整个平台。分别有B200和GB200两个系列,后者由1个Grace CPU和2个B200 GPU组成。
其中,B200 GPU通过2080亿晶体管实现了20 petaflops的FP4吞吐量。GB200则通过900GB/秒的高效芯片间连接,把两个B200 GPU与一个Grace CPU连接起来。

GB200 架构,包含两个 GPU 和一个 CPU。
相比H100 Tensor Core GPU,GB200能够为大型语言模型(LLM)的推理工作提供高达30倍的性能提升,同时大大降低了成本和能耗。
「大家都以为我们是在制造GPU,但现在的GPU已经不再是以前那样了,」黄仁勋说。「我现在一手拿着 100 亿(晶体管),一手拿着 50 亿(晶体管)。」

英伟达已经不再单独卖显卡,而是将其作为整套系统出售,因为只有使用英伟达自家的组件,才能达到最佳效能。「如今,我们出售的是7000多个部件、重达3000磅的GPU系统。」
基于Blackwell的AI计算平台,将以DGX GB200服务器的形式提供给客户,整合了36颗NVIDIA Grace CPU和72个Blackwell GPU。这些超级芯片通过第五代NVLink成为了一个超级计算集群。
更进一步,基于Grace和Blackwell架构的DGX SuperPOD由8个或更多的DGX GB200系统组成。通过NVIDIA Quantum InfiniBand网络,这些系统能扩展到成千上万个GB200芯片。用户可以连接576块GPU,从而训练下一代AI模型。
比较一下性能升级,以前Hopper需要8000块GPU训练GPT-MoE-1.8T花费90天,而现在GB2000只需要2000块,且能耗仅为之前的四分之一。

在生成式AI的下一个阶段,即多模态和视频领域,需要进行更大规模的训练。Blackwell为此带来了更多的可能性。
对于大型语言模型的推理,这是一个持续的挑战,不适合单个GPU处理。在拥有1750亿参数的GPT-3基准测试中,GB200的性能是H100的7倍,而训练速度则是原来的4倍。
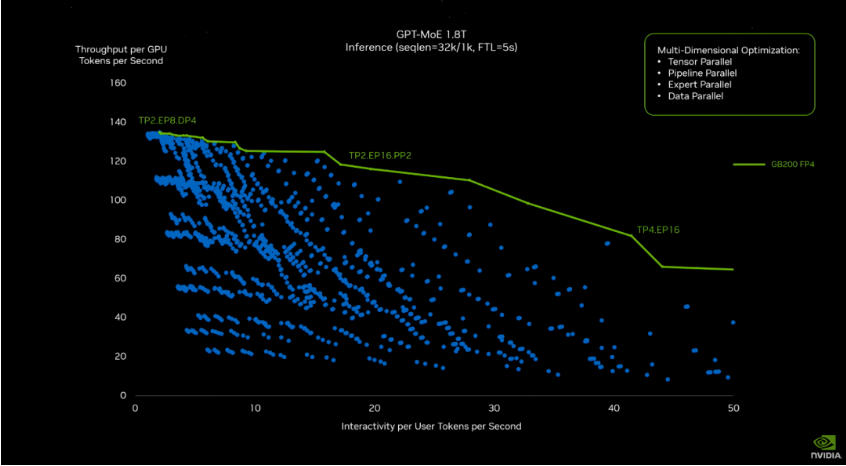
如今,大模型推理的速度比前一代快了30倍。黄仁勋展示了一张性能对比图,其中蓝色代表Hopper。
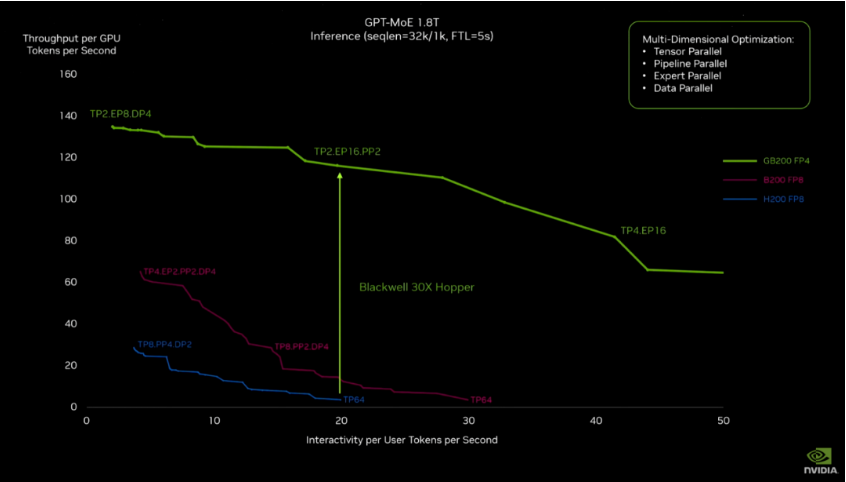
「DGX超级计算机是推动AI行业变革的工厂。新一代的DGX SuperPOD集计算加速、网络以及软件发展的最新成果于一身,能够帮助每家公司、各个行业和各国政府改进并制造自己的AI。」黄仁勋说道。
随着Blackwell的推出,我们距离生成式AI应用的普及又更近了一步。
两大技术革新
得益于第二代 Transformer 引擎和第五代 NVLink的联合革新
30倍的AI算力是怎样实现的?除了采用先进的制造技术,将两块芯片结合使用外,Blackwell的关键在于它的第二代Transformer引擎,它支持FP4和FP6,使得计算能力、带宽以及模型的规模都得以加倍。
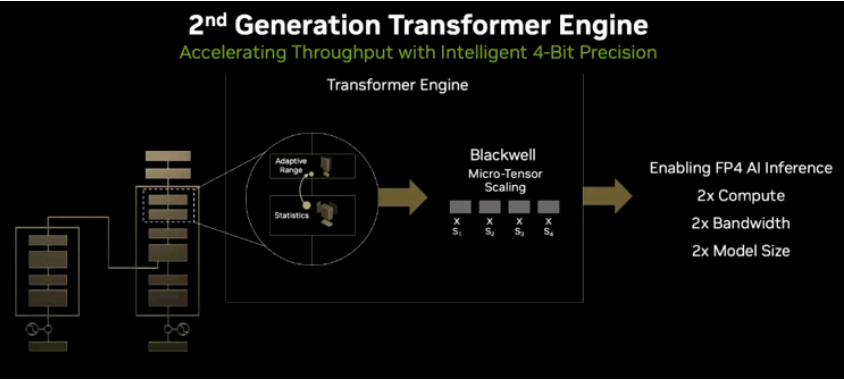
得益于新引入的微张量(micro-tensor)扩展支持和集成到TensorRT-LLM以及NeMo Megatron框架中的先进动态范围管理算法,Blackwell采用4-bit浮点数进行AI推理,使得它的算力和模型规模都提高了一倍。

而当大量这样的GPU互连时,下一代NVLink交换机成为了一个突破性的创新。它可以让576个GPU进行互通,双向带宽达到每秒1.8TB。
英伟达表示,集群系统以前60%的时间都在处理GPU间的通信,现在,新的NVLink Switch Chip让所有芯片高速互联,没有任何瓶颈。

这样,DGX GB200 NVL72基本上可以作为一个超级GPU来看待。它的FP8训练吞吐量高达720 PFLOPS,FP4推理吞吐量为1.44 ExaFLOPS,多节点All-to-All通信速度为130TB每秒,多节点All-Reduce通信速度为260TB每秒。
在具体架构上,DGX GB200 NVL72有18个GB200节点机架,每个节点都配备2个GB200 GPU,还有9个NVSwitch机架,这为GB200 NVL提供了720 PFLOPS的FP8吞吐量,以及ExaFLOPS精度的FP4。

所以今年的DGX形象焕然一新,有着5000条NVLink电缆,总长2英里,这些纯铜导线取代了昂贵的光纤收发器,节约了20kW的计算成本。

由于功耗过大,它还需要液冷来散热,它的重量高达3000磅(约1361公斤)。

2016年,黄仁勋亲手将第一台DGX系统交给OpenAI,现在,这里的GB200算力以Exaflop为单位。

在英伟达所定义的新摩尔定律下,算力提升的速度不仅没有放缓,反而加快了。
构建生态,入场具身智能
而在构建生态系统方面,英伟达也通过生成式AI技术,在元宇宙、工业数字孪生技术、以及机器人训练方面进行了扩展。
英伟达正在把它的Omniverse企业技术带入苹果生态中,使得开发者们能够通过Vision Pro工具在AR/VR环境中利用Omniverse工具。在GTC大会上,英伟达展示了设计师是如何使用Vision Pro虚拟地配置汽车,然后进入其中进行体验。通过Omniverse Cloud API,还可以将图像直接流传输至Vision Pro。
在机器人技术最前沿,英伟达公布了人形机器人项目GR00T。
在大会的主题演讲上,黄仁勋展示了GR00T项目推动的人形机器人是如何执行各类复杂任务的,这些机器人来自著名企业如Agility Robotics、Apptronik、傅利叶智能以及宇树科技,体现了人形机器人技术的前沿成就。

GR00T项目是基于英伟达的Isaac机器人平台衍生发展的,其采用了全新的通用基础模型。通过这一平台,人形机器人能够接收文本、语音、视频甚至是现场演示的输入,并处理这些数据以完成特定的动作。这些机器人具备了理解自然语言和模拟人类行为的能力,还能在现实环境中自如地导航和互动。
更进一步,英伟达还开发了一款名为Jetson Thor的高级计算芯片,这是一种专为机器人设计的“大脑”,有能力执行复杂任务,并利用Transformer引擎管理众多传感器。

人形机器人领域最近活跃度大增。举例来说,英伟达的大客户OpenAI,就在不断地运用其AI模型为一家名叫Figure的初创企业的人形机器人提供智能支持。
现在,随着英伟达把GR00T摆在了其技术展示的窗口位置,黄仁勋对未来机器人技术的发展充满期待。「ChatGPT时代的机器人可能即将来临。」

这是不是意味着我们距离拥有智能会对话、理解并行动的机器人仅一步之遥?英伟达的这一系列革新技术可能很快就会将这一愿景变为现实。
关于Figure的文章我也有写【2024】当ChatGPT拥有了身体,并且与人类并且全面对话并学习,你还感觉AI与你很远吗?
,感谢大家阅读。
参考文章:
【2024】英伟达吞噬世界!新架构超级GPU问世,AI算力一步提升30倍
参考链接:
Nvidia reveals Blackwell B200 GPU, the ‘world’s most powerful chip’ for AI - The Verge
NVIDIA Blackwell Platform Arrives to Power a New Era of Computing | NVIDIA Newsroom
Nvidia unveils next-gen Blackwell GPUs with 25X lower costs and energy consumption | VentureBeat
Nvidia shows off Project GR00T, a multimodal AI to power humanoids of the future | VentureBeat
https://www.nextplatform.com/2024/03/18/with-blackwell-gpus-ai-gets-cheaper-and-easier-competing-

