
- 1应用 OpenCV 进行 增强相关系数(ECC)最大化的图像配准_findtransformecc
- 2因果推断与机器学习中的推荐系统与个性化_因果推荐系统
- 3《C++ AMP:用Visual C++加速大规模并行计算》——1.2 CPU并行技术
- 43.1_3 连续分配管理方式
- 5Mac os 本地化localizations_mac如何配置localization
- 6002——编译鸿蒙(Liteos -a)
- 7android手势检测类的扩展支持单点和多点触摸_android手势 单点隐藏控件
- 8AndroidStudio实现用户登录注册界面代码(二)_andriod studio 登录系统 cadn
- 9【力扣】322-零钱兑换_零钱兑换力扣
- 10RNNoise: 一种致力于实时全频段语音增强的DSP+深度学习混合方法
机器学习之层次聚类算法_层次聚类 类间距离的方法
赞
踩
层次聚类(Hierarchical Clustering)是对给定数据集在不同层次进行划分,形成树形的聚类结构,直到满足某种停止条件为止。数据集的划分可采用自底向上或自顶向下的划分策略。
1、凝聚的层次聚类算法AGNES
AGNES(AGglomerative NESTing)采用自底向上的策略,先将每个样本作为一个初始聚类簇,然后循环将距离最近的两个簇进行合并,直到达到某个停止条件,如指定的簇数目等。
两个簇间距离可以由这两个不同簇中距离最近的数据点的相似度来确定,计算方法有:
(1)最小距离single/word-linkage(SL聚类)
两个聚簇中最近的两个样本之间的距离
最终得到的模型容易形成链式结构。
(2)最大距离complete-linkage(CL聚类)
两个聚簇中最远的两个样本之间的距离
如果存在异常值,那么构建可能不太稳定。
(3)平均距离average-linkage(AL聚类)
两个聚簇中样本间两两距离的平均值
(4)中值距离median-linkage
两个聚簇中样本间两两距离的中值
比AL更能消除个别偏离样本对结果的干扰。


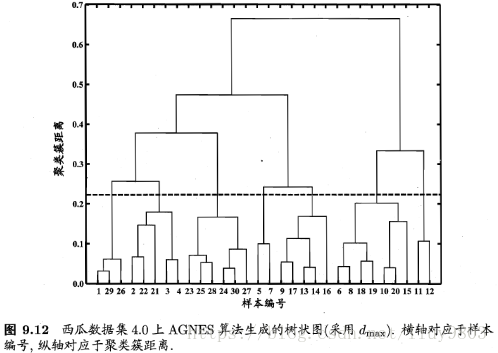
2、分裂的层次聚类算法DIANA
DIANA(DIvisive ANAlysis)采用自顶向下的策略,先将所有的样本归为一个簇,然后按照某种规则逐渐分裂为越来越小的簇,直到达到某个停止条件,如指定的簇数目等。分裂方式如下:
(1)在同一个簇c中计算两两样本之间的距离,找出距离最远的两个样本a、b;
(2)将样本a、b分配到不同的类簇c1、c2中;
(3)计算c中剩余的其他样本分别和a、b的距离,若dist(a)<dist(b),则将样本分入c1中,否则分入c2中。
AGENS、DIANA算法的优缺点:
简单、理解容易;
合并点/分裂点的选择不太容易;
合并点/分裂点的操作不能进行撤销;
不太适合大数据集、样本量很大的情况,伸缩性差、执行效率较低O(t*m2),t为迭代次数,m为样本数量。
层次聚类优化算法
3、平衡迭代削减聚类法BIRCH
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)也称利用层次方法的平衡迭代规约和聚类算法,适合数据量非常大、簇数量也比较多的情况。此算法运行效率极高,只需扫描一遍数据集即可聚类,并能有效地处理离群点。BIRCH算法的主要步骤是:
(1)扫描数据集,动态建立一棵CF-Tree存放在内存中;
(2)若内存不够,则增大阈值T,在原树的基础上构建一棵比较小的树;
(3)对CF-Tree叶节点使用全局性的聚类算法如K-means等,以消除由于样本读入顺序导致的不合理的树结构,改进聚类质量。
BIRCH算法的核心是用聚类特征CF表示一个簇的相关信息,构建满足分支因子和簇直径限制的聚类特征树CF-Tree,然后对叶子节点进行聚类。
聚类特征Cluster Feature指的是一个满足线性关系的三元组(N,LS,SS),其中:
N表示这个CF中包含的样本数量;
LS表示这个CF中包含的样本点的各特征维度的向量和;
SS表示这个CF中包含的样本点的各特征维度的平方和(标量)。

聚类特征树CF-Tree的每一个节点由若干CF组成,内部节点指向叶节点,所有的叶节点用一个双向链表链接起来。由于CF满足线性关系,因此CF-Tree父节点中的每个CF三元组的值等于它所指向的子节点的所有CF三元组之和。CF-Tree的构建是动态的,可以随时根据新增数据对树模型进行更新。
CF-Tree的几个关键超参数:
B:每个内部节点最大的CF个数;
L:每个叶节点最大的CF个数;
T:叶节点每个CF的最大样本半径阈值,即新样本若被分类到某一个CF中,其到该CF中心的距离最大值。
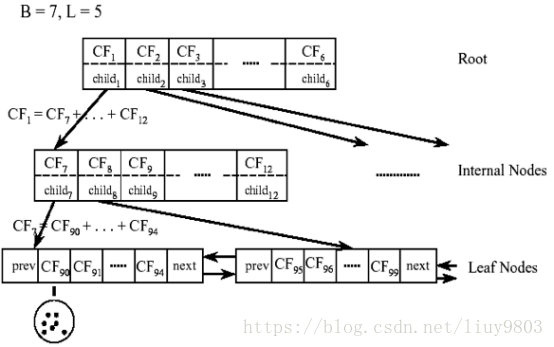
CF-Tree构建步骤:
(1)初始状态时CF-Tree是空的,没有任何样本。读入第一个样本,生成这个节点的第一个CF三元组,此时N=1,令它为CF1。
(2)读入第二个样本,若它到CF1的距离小于T,那么这个样本也归入CF1(N=2),更新其三元组数据;如果大于T,则此节点新增一个CF三元组CF2,这个样本作为CF2中的首个样本(N=1)。
(3)节点分裂:从根节点开始,自上而下选择叶节点,令新样本进入最近的叶节点;考察新样本与叶节点所有CF的距离,如果都大于T,则生成一个新的CF;但是如果此时叶节点的CF总个数大于L,就需要对该叶节点进行分裂:
找到该叶节点内各个CF之间的距离最大的两个CF,分别作为两个新叶节点的CF,再计算其余CF到这两个CF之间的距离,将原叶节点的数据划分到这两个新叶节点中。
如果叶节点分裂过后导致上一层的内部节点的CF总数超过B,则该内部节点需要进行分裂,分裂方式和叶节点分裂方式相同。
(4)循环上述过程,当有样本无法插入时,需要提升阈值T并重建树,直到所有样本均进入CF树为止。
BIRCH算法的特点:
(1)速度快、节约内存,适合处理大规模数据集,线性效率(I/O花费与数据量呈线性关系);
(2)可识别噪声点,建立CF-Tree后将包含数据点少的子簇剔除;
(3)采用多阶段聚类技术,单次扫描产生基本的聚类,多次扫描改善聚类质量;
(4)是一种增量的聚类方法,对每个点的决策基于当前已经处理过的点;
(5)由于CF-Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的分布不同;
(6)由于CF-Tree各节点阈值相同,只适合体积相差不大的簇之间的聚类,对体积相差较大的簇聚类的效果不是很好。因此可以引入多阈值BIRCH算法,为每个簇设一个阈值,将CF表示为四元组(N,LS,SS,T);
(7)只适合分布呈凸形或者超球形的数据集,因为使用了半径或直径的概念来控制聚类的边界;
(8)对高维特征的数据聚类效果不好,此时可选择Mini Batch K-means。
(9)BIRCH算法过程一旦中断,必须从头再来。
4、使用代表点的聚类法CURE
CURE(Clustering Using REpresentatives)该算法先把每个点作为一个簇,然后合并距离最近的簇直到簇个数达到要求为止。CURE和AGNES算法的区别是:不是使用所有点或质心+距离来表示一个簇,而是从每个簇中抽取固定数量、分布较好的点作为簇的代表点,并将这些代表点乘以一个适当的收缩因子,使它们更加靠近类中心点。代表点的收缩特性可以调整模型匹配非高斯分布的应用场景,而且收缩因子的使用可以减少噪音数据对聚类的影响。
CURE算法实现过程如下:
(1)从原始数据中随机抽样,得到数据集S;
(2)对S进行分区,在内存中对每个分区分别进行局部聚类;
(3)如果一个类簇增长缓慢或不增长,说明它是噪声,要去除掉;
(4)新的类簇由固定个数的代表点经过收缩后表示;
(5)对磁盘上整个原始数据根据代表点进行全局聚类。
由于CURE算法的时间复杂度较高,可以使用堆、k-d树、随机抽样和分区等技术改善效率;CURE的聚类效果受参数的影响较大,如随机抽样的比例、聚类个数、收缩因子的设定等。

