- 1使用RD Client来远程桌面(cell-coder)
- 2request模块
- 3熟识 : 计算机文化(收藏)
- 4[Python] 解析Pcap三个Python库(Dpkt Scapy Pyshark)应用实例_python pcap
- 5基于ssm的网上教学平台源码_[内附完整源码和文档] 基于WEB的网上购物系统的设计与实现...
- 6Vue3——阶段练习(composition api的综合实战)_vue3组合式api练习
- 7lombok插件无法使用的原因_ant 不支持lambok
- 8[独有源码]java-jsp高校功能教室预约系统的设计与实现um4vl规划与实现适合自己的毕业设计的策略_教室预约系统设计与实现
- 9鸿蒙HarmonyOS教程-路由管理(Router)【入门篇】_鸿蒙 pushnamedroute
- 10在Vue中使用谷歌地图与vue-google-maps实现地图搜索、地图显示、坐标拾取及定位等功能_vue2-google-maps
数据结构-图的笔记(2)(图的邻接矩阵和邻接表)_输入一个邻接矩阵数组a,图的定点个数n,图的边数e,开始顶点编号v,建立图的领接表g
赞
踩
目录
邻接矩阵
1.数组(邻接矩阵)表示法
建立一个顶点表(记录各个顶点信息)和一个邻接矩阵(表示各个顶点之间关系)。
假设图 A=(V,E)有n个顶点,则
顶点表Vexs[n]

图的邻接矩阵是一个二维数组A.arcs[n][n],定义为:
A.arcs[i][j]={1(如果<i,j>属于E或者(i,j)属于E ),否则为0

1.无向图的邻接矩阵是对称的;
2.顶点i的度=第i行(列)中1的个数;
特别:完全图的邻接矩阵中,对角元素为0,其余为1。

注意:在有向图的邻接矩阵中:第i行含义:以结点vi为尾的弧(即出度边);
第i列含义:以结点vi为头的弧(即入度边)。
1.有向图的邻接矩阵可能是不对称的。
2.顶点的出度=第i行元素之和
顶点的入度=第i列元素之和
顶点的度=第i行元素之和+第i列元素之和
网(即有权图)的邻接矩阵表示法定义为:A.arcs[i][j]={Wij(<vi,vj>或(vi,vj)属于VR),否则无穷大(无边/弧)
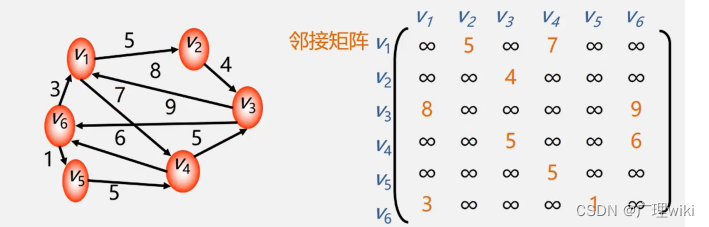
邻接矩阵的存储表示:用两个数组分别存储顶点表和邻接矩阵
代码实现:
- #define MaxInt 32767 //表示极大值,即无穷大
- #define MVNum 100 //最大顶点数
- typedef char VerTexType; //设顶点的数据类型为字符型
- typedef int ArcType; //假设边的权值类型为整型
-
- typedef struct{
- VerTexType vexs[MVNum];//顶点表
- ArcType arcs[MVNum][MVNum];//邻接矩阵
- int vexnum,arcnum;//图的当前点数和边数
- }AMGraph;//Adjacency Matrix Graph
2.采用邻接矩阵表示法创建无向网

算法思想:
1.输入总顶点数和总边数。
2.依次输入点的信息存入顶点表中。
3.初始化邻接矩阵,使每个权值初始化为极大值。
4.构造邻接矩阵。
代码实现:
- Status CreateUDN(AMGraph &G){
- //采用邻接矩阵表示法,创建无向网G
- cin>>G.vexnum>>G.arcnum;//输入总项点数,总边数
- for(i=0;i<G.vexnum;++i)
- cin>>G.vexs[i];//依次输入点的信息
- for(i=0;i<G.vexnum;++i)//初始化邻接矩阵
- for(j=0;j<G.vexnum;++j)
- G.arcs[i][j]=MaxInt;//边的权值均置为极大值
- for(k=0;k<G.arcnum;++k){//构造邻接矩阵
- cin>v1>v2>>w;//输入一条边所依附的顶点及边的权值
- i=LocateVex(G,v1);
- j=LocateVex(G,v2);//确定v1和v2在G中的位置
- G.arcs[i][j]=w//边<v1,v2>的权值置为w
- G.arcs[j][i]=G.arcs[i][j]//置<v1,v2>的对称边<v2,v1>的权值为w
- }//for
- return OK;
- }CreateUDN
补充:在图中查找顶点
代码实现:
- int LocateVex(AMGraph G,VertexType u){
- //图G中查找顶点u,存在则返回顶点表中的下标;否则返回-1
- int i;
- for(i=0;i<G.vexnum;++i)
- if(u==G.vexs[i]) return i;
- return -1;
- }
邻接矩阵的优点
1.直观、简单、好理解。
2.方便检查一对顶点间是否存在边。
3.方便找任一顶点所有的“邻接点”(有边直接相连的顶点)。
4.方便计算任一顶点的度(从该点发出的边数为“出度”,指向该点的边数为“入度”)。
无向图:对应行(或列)非0元素的个数。
有向图:对应行非0元素的个数是“出度”,对应列非0元素的个数是“入度”。
邻接矩阵的缺点
1.不便于增加和删除顶点。
2.浪费空间-对于稀疏图(点多边少)有大量无效元素,对于稠密图(特别是完全图)还是很合算。
3.浪费时间-统计稀疏图中一共有多少条边。
邻接表
1.邻接表表示法(链式)
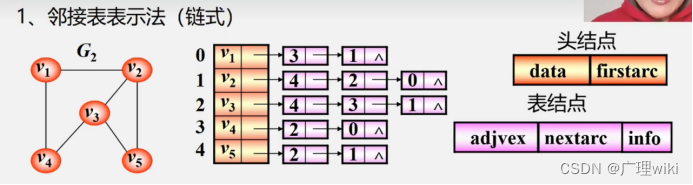
顶点:按编号顺序将顶点数据存储在一维数组中;
关联同一顶点的边(以顶点为尾的弧):用线性链表存储(adjvex邻接点域:存放与vi邻接的顶点在表头数组中的位置。nextarc链域:指示下一条边或弧。)
特点:邻接表不唯一,若无向图中有n个顶点,e条边,则其邻接表需n个头结点和2e个表结点。适宜存储稀疏图。
无向图中顶点vi的度为第i个单链表中的结点数。
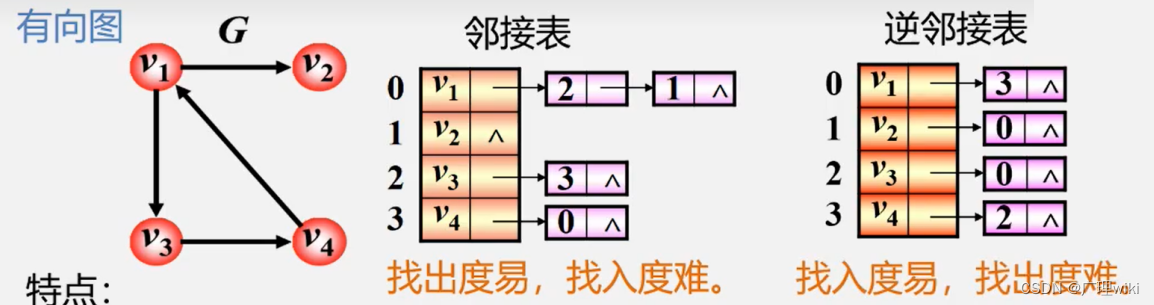
有向图邻接表:顶点vi的出度为第i个单链表中的结点个数。
顶点vi的入度为整个单链表中邻接点域值是i-1的结点个数。
有向图逆邻接表:顶点vi的入度为第i个单链表中的结点个数。
顶点vi的出度为整个单链表中邻接点域值是i-1的结点个数。
图的邻接表存储表示:

typedef struct VNode{
VerTexType data;//顶点信息
ArcNode *firstarc;//指向第一条依附该顶点的边的指针
}VNode,AdjList[MVNum];//AdjList表示邻接表类型
![]()
#define MVNum 100;//最大顶点数
typedef struct ArcNode{//边结点
int adjvex;//该边所指向的顶点的位置
struct ArcNode *nextarc;//指向下一条边的指针
OtherInfo info;//和边的相关的信息
}ArcNode;
图的结构定义:
typedef struct {
AdjList vertices;//vertices--vertex的复数
int vexnum,arcnum;//图的当前顶点数和弧数
}ALGraph;
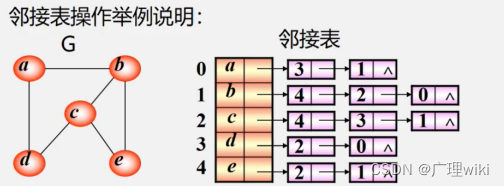
ALGraph G;//定义了邻接表表示的图G
G.vexum=5;G.arcnum=5;//图G包含5个顶点,5条边
G.vertices[1].data='b';//图G中第二个顶点是b
p=G.vertices[1].firtarc;//指针p指向顶点b的第一条边结点
p->adjvex=4;//p指针所指边结点是到下标为4的结点的边
2.采用邻接表表示法创建无向网
算法思想:
1.输入总顶点数和总边数。
2.建立顶点表
依次输入点的信息存入顶点表中
使每个表头结点的指针域初始化为NULL
3.创建邻接表
依次输入每条边依附的两个顶点
确定两个顶点的序号i和j,建立边结点
将此边结点分别插入到vi和vj对应的两个边链表的头部
代码实现:
- Status CreateUDG(ALGraph &G){//采用邻接表表示法,创建无向图G
- cin>>G.vexnum>>G.arcnum;//输入总顶点数,总边数
- for(i=0;i<G.vexnum;++i){//输入各点,构造表头结点表
- cin>>G.vertices[i].data;//输入顶点值
- G.vertices[i].firstarc=NULL;//初始化表头结点的指针域
- }//for
- for(k=0;k<G.arcnum;++k){//输入各边,构造邻接表
- cin>>v1>>v2;//输入一条边依附的两个顶点
- i=LocateVex(G,v1);
- j=LocateVex(G,v2);
- p1=new ArcNode;//生成一个新的边结点*p1
- p1->adjvex=j;//邻接点序号为j
- p1->nextarc=G.vertuces[i].firstarc;
- G.vertices[i].firstarc=p1;//将新结点*p1插入顶点vi的边表头部
- p2=new ArcNode;//生成另一个对称的新的边结点*p2
- p2->adjvex=i;//邻接点序号为i
- p2->nextarc=G.vertuces[j].firstarc;
- G.vertices[j].firstarc=p2;//将新结点*p2插入顶点vj的边表头部
- }//for
- return OK;
- }//CreateUDG
邻接矩阵和邻接表的区别
1.对于任一确定的无向图,邻接矩阵是唯一的(行列号与顶点编号一致),但邻接表不唯一(链接次序与顶点编号无关)。
2.邻接矩阵的空间复杂度为O(n^2),而邻接表的空间复杂度为O(n+e)(有向图)。
3.用途:邻接矩阵多用于稠密图,而邻接表多用于稀疏图。
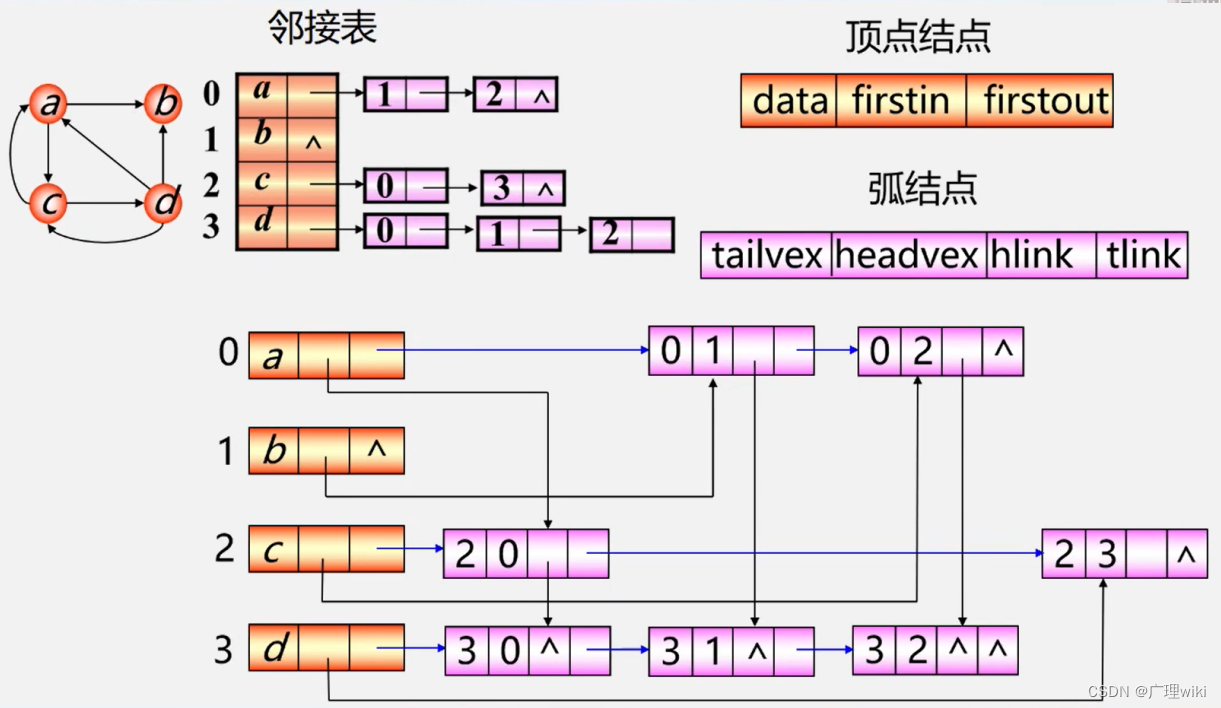
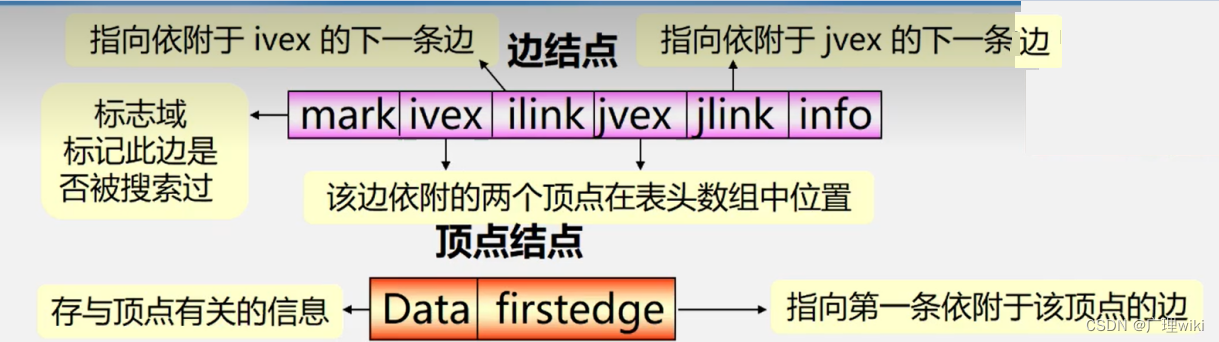
扩展:十字链表
十字链表(Orthogonal List)是有向图的另一种链式存储结构。我们也可以把它看成是将有向图的邻接表和逆邻接表结合起来形成的一种链表。
有向图中的每一条弧对应十字链表中的一个弧结点,同时有向图中的每个顶点在十字链表中对应有一个结点,叫做顶点结点。
十字链表如下图示: