
- 1Gradle多模块项目 gradle build打包失败问题、找不到符号问题_gradle 没有 build
- 2【抓包工具】win 10 / win 11:WireShark 下载、安装、使用_windows抓包工具
- 3渣渣二本的辛酸面试之路:从深圳到杭州,从外包到蚂蚁金服,4年小Android的心路历程_深圳去杭州找工作
- 4python 实现跳一跳自动化代码_跳一跳AI(wai gua)的实现原理详细介绍
- 5异常:java.lang.NoClassDefFoundError: net/sf/ezmorph/Morpher 解决办法
- 6【论文笔记】ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks_eca-net的网络结构图
- 7AI之图像识别_虚拟ai图片识别
- 8android resource xml,Android resource
- 9Android Studio发布项目到Maven仓库_install.repositories.maveninstaller
- 10空指针异常出现的几种原因及解决方法
什么是多模态深度学习?有哪些应用场景?
赞
踩

深度多模态学习能够更全面地理解数据,在准确性和效率上均有大幅提升。但首先,什么是多模态深度学习?它有哪些应用场景?本文将从定义、应用与前景三个角度来回答这两个问题。
随着深度神经网络的发展,深度学习也逐渐向多模态技术迈进。多模态技术为非结构化数据的智能处理提供了可能,包括图像、音频、视频、PDF 和 3D 网格。多模态深度学习不仅可以更全面地理解数据,还可以提高模型的效率和准确性。
Jina AI 是构建云原生多模态 AI 应用的最先进的 MLOps 平台,基于 Jina AI,用户可以将数据和几行代码转化为生产就绪的服务,而无需处理基础架构复杂性或扩展麻烦。
但首先,什么是多模态深度学习呢?它又有哪些应用场景呢?
模态是什么
“模态”对应于人类的五种感官,视觉、听觉、触觉、味觉和嗅觉,我们这里的“模态”实际指的是“数据模态”,也就是你需要处理的数据类型。
有时,人们把"多模态数据"和"非结构化数据"混淆使用,多模态数据是指包含多种数据模态的数据,例如可能包含文本、图像、视频和音频等。非结构化数据的含义更加宽泛,指没有固定数据结构的数据,它可能是文本、图像、视频或音频等任何格式,由于没有统一格式,无法被计算机直接处理。
真实世界的数据都是多模态的
早期的 AI 研究通常都是在单一模态数据上进行的,例如在自然语言处理领域,研究人员通常只关注文本数据,计算机视觉领域的研究人员只关注图像数据。因此,AI 应用总是局限于特定模态,垃圾邮件过滤应用处理的都是文本,照片分类应用处理的都是图像,语音识别应用处理的都是音频。
但是现实世界的数据往往是多模态的。视频常伴随着音轨,还有文本字幕。社交媒体平台的帖子、新闻文章或者其它互联网上的内容经常混合着文本、图像、视频和音频。因此,处理多模态数据的需求促进了多模态 AI 的发展。
多模态 vs 跨模态
“多模态”和“跨模态”是另外两个容易混淆的术语,它们的含义是不同的:
多模态深度学习是一个相对较新的领域,它关注从多模态数据中学习的算法。例如,人类可以同时通过视觉和听觉来识别人或物体,而多模态深度学习关注的是为计算机开发类似的能力,让模型也能同时处理来自不同模态的输入。
跨模态深度学习是一种多模态深度学习的方法,可以使用跨模态深度学习来学习跨越不同模态的关系,比如学习声音和文本之间的关系,图像和文本之间的关系。
多模态深度学习是将多种不同的模态作为输入来训练模型,而跨模态深度学习则是学习跨越不同模态的关系。“多模态”指用于多模态数据的 AI 系统,当狭义地指集成不同模式并将它们一起使用的 AI 系统时,“跨模态”则更为准确。
多模态深度学习应用
多模态深度学习有着广泛的应用,以下是已经可用的应用:
自动生成图像的文本描述,为图像自动生成语言描述,例如盲人字幕。
搜索与文本匹配的图像,例如“找一张蓝色狗的图片”。
文本生成图像,利用文本描述创作图像的生成式艺术系统,例如,创作一张蓝色狗的图片。
这些应用都依赖于两个关键技术:搜索 和 生成。
神经搜索
神经搜索的核心思想是利用前沿的神经网络模型构建搜索系统的每个组件,简而言之,神经搜索就是深度神经网络驱动的信息检索。
以下是 DocArray 生成 embedding projector 的示例,可以用于基于内容的图像检索。

将图像 embedding 投影到三维空间的可视化展示
越是相似的图像在嵌入空间中的距离就越近,也就是说搜索与某张图片最相似的图像,就相当于在嵌入空间中寻找距离最近的图像,你可以通过 DocArray API 轻松实现相似图像搜索任务。
- db = ...# a DocumentArray of indexed images
- queries = ...# a DocumentArray of query images
-
- db.find(queries, limit=9)
-
- for d in db:
- for m in d.matches:
- print(d.uri, m.uri, m.scores['cosine'].value)
神经搜索在处理多模态数据时表现相当出色,这是因为它可以将多模态数据(例如,文本和图像)映射到同一嵌入空间。这使得神经搜索引擎可以利用文本查询搜索图像,并利用图像查询搜索文本。
超越搜索框的搜索
问答机器人,将用户查询映射到与 FAQ、指南或者预留答案相同的嵌入空间中。
智能设备,利用语音识别技术将用户的语音转化为可用命令。
推荐系统,通过在嵌入空间中寻找距离最近的向量,搜索与用户选择商品最相似的产品。
生成式 AI
生成式 AI 是指利用神经网络模型生成新内容,比如文本、图像、视频等的技术。例如,OpenAI 的 GPT-3 可以根据文本提示创作新文本。GPT-3 是在拥有大量书籍、文章和网站的语料库上训练的。给定一个文本提示,它会根据提示自动生成文本。人们可以用 GPT-3 创作故事和诗歌,它的创作能力几乎和人类不相上下。
OpenAI 的 DALL·E 可以根据文本提示创作图像,下图是在 DALL·E Flow 根据提示“an oil painting of a humanoid robot playing chess in the style of Matisse”生成的图像。DALL·E Flow 是一个基于 Jina 构建,并托管在 Jina AI Cloud 上的完整的文本图像生成系统。
DALL·E Flow: https://github.com/jina-ai/dalle-flow
- server_url = 'grpc://dalle-flow.jina.ai:51005'
- prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'
-
- from docarray import Document
-
- doc = Document(text=prompt).post(server_url, parameters={'num_images': 8})
- da = doc.matches
-
- da.plot_image_sprites(fig_size=(10, 10), show_index=True)

生成式 AI 具有巨大的潜力,通过以下方式,它可能会彻底改变我们与机器的交互方式:
人机交互过程中更个性化的体验。
在电影、游戏和其它视觉媒体更加逼真的人和物体的 3D 图像和视频。
用于游戏或其它交互媒体的更加自然的对话。
用于制造业和其它行业的产品新设计。
全新的市场营销文案。
多模态关系
多模态深度学习可以将不同模态的信息连接起来,这对于生成式 AI 和神经搜索十分有用。在以下示例中,我们将 cat, dog,human,ape 的文本和图像映射到同一嵌入空间中:
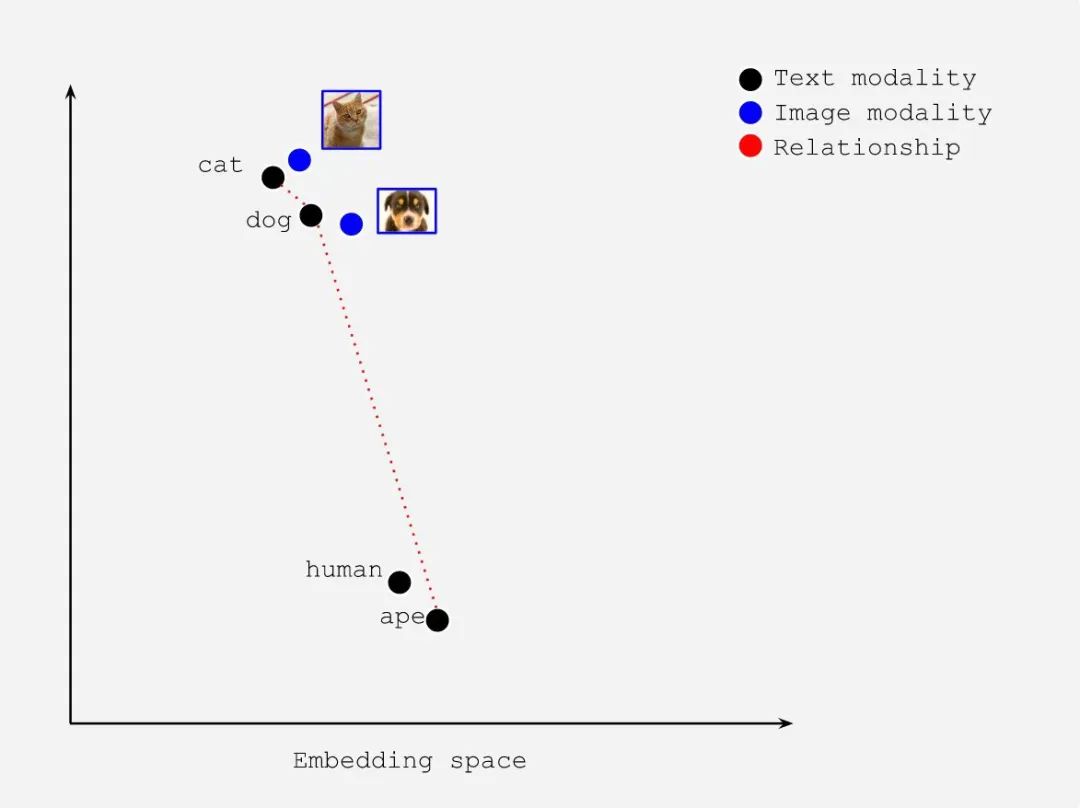
这些项目在单个嵌入空间中的位置编码了它们之间的关系信息:
cat 的文本 embedding 和 dog 的文本 embedding 更近(相同模态);
human 的文本 embedding 和 ape 的文本 embedding 更近(相同模态);
cat 和文本 embedding 和 human 的文本 embedding 很远(相同模态);
cat 的文本 embedding 和 cat 的图像 embedding 更近(不同模态);
cat 的图像 embedding 和 dog 的图像 embedding 更近(相同模态)。
这些信息很明显可以用于信息检索中,但是生成式 AI 也可以使用这些信息。相比于在一组文本或图像 embedding 中寻找距离最近的向量,生成式 AI 是为提示的 embedding 创建距离最近的文本或图像。
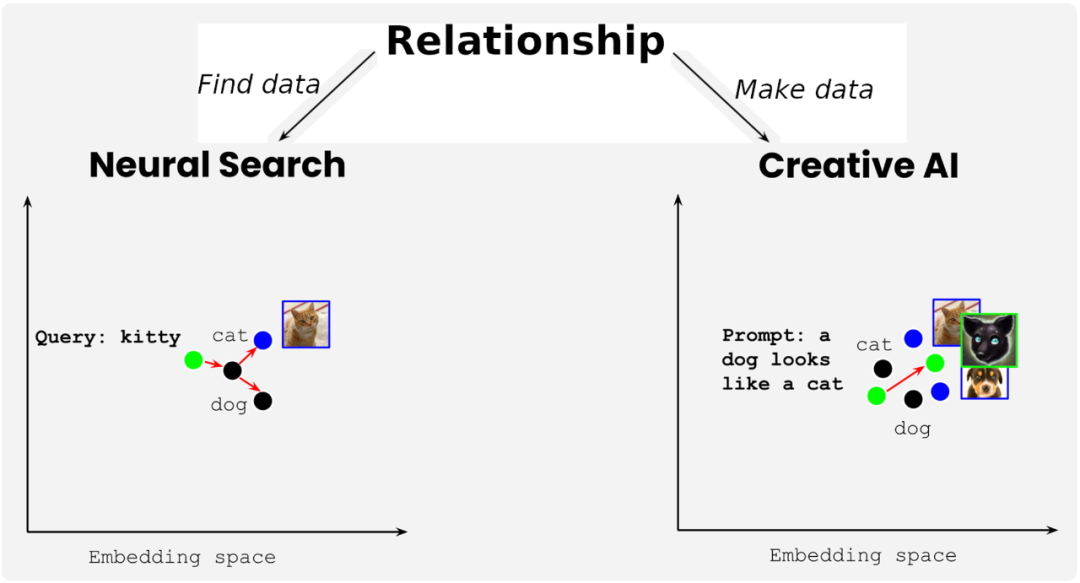
综上,多模态深度学习的关键就是理解不同模态信息之间的关系,你可以利用这种关系搜索现有数据,也就是神经搜索;或者也可以生成新的数据,也就是生成式 AI。更多关于多模态深度学习的信息,可以阅读这篇文章:Jina AI创始人肖涵博士解读多模态AI的范式变革。
更多技术文章
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

