
- 12021年G3锅炉水处理报名考试及G3锅炉水处理模拟考试_臭屁的玻璃件及其电位与溶液中氢离子浓度成
- 2网页适配 iPhoneX,就是这么简单_chrome调试ios安全距离
- 3手机免root安装kali linux 步骤,离线版(最终可行版)_kali linux手机版安装
- 4Android/iOS APP备案流程指南
- 5vue错误:Property or method "**" is not defined 和 Invalid handler for event "click"_property or method is not defined
- 6android viewpager 内容有的不能滑动,关于viewpager无法滑动
- 7欧拉操作系统在线安装mysql8数据库并用navicat premium远程连接_欧拉系统安装mysql数据库
- 8单神经元自适应控制算法,bp神经网络缺点及克服_bp神经网络能优化单个的因素吗
- 9spring-framework-3.2.16.RELEASE源码编译并导入eclipse_org.springframework:spring-beans:3.2.16.release
- 10组合式(Composition)API_组合式api
【论文阅读】MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection --- 多模态,谣言检测,注意力机制
赞
踩
本博客系博主根据个人理解所写,非逐字逐句翻译,预知详情,请参阅论文原文。
论文标题:MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection;
作者:Jiaqi Zheng1 , Xi Zhang1∗ , Sanchuan Guo1 , Quan Wang1 , Wenyu Zang2 and Yongdong Zhang3,1 ;
- Key Laboratory of Trustworthy Distributed Computing and Service (MoE), Beijing University of Posts and Telecommunications, China
- China Electronics Corporation
- University of Science and Technology of China
发表地点:IJCAI 2022;
论文下载链接:[PDF] MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection | Semantic Scholar
(作者们在github上提供了文中所用数据集的下载地址,非常贴心)
摘要:
社交网络上,谣言的传播者更多地开始利用多模态/多媒体(multimedia)内容来吸引读者的注意。尽管最近的多模态谣言检测方法已经探索了用文本(textual)和视觉(visual)特征来对谣言进行分类,但是他们没有考虑到社交结构特征(social structure features),而这个特征在谣言的识别中非常关键。
考虑到不同模态之间复杂的异构(heterogeneous)关系,将多个模态特征融合起来是具有挑战性的。因此本文提出一个特征增强的多模态注意力网络(Multi-modal Feature-enhanced Attention Networks, MFAN)来做谣言检测,该工作首次尝试将textual,visual,social graph features同时考虑到一个框架中。具体而言,本文同时考虑到不同模态的补充(complement)关系和对齐(alignment)关系来更好地进行模态融合(fusion)。同时考虑到由于数据收集的限制,social network data中存在不完整链接(incomplete links),本文提出了推测(infer)隐藏链接的方法来更好地学习social graph特征。
实验表明MFAN比SOTA方法在检测谣言上更有效,性能更好。
本文动机及现有方法的问题:
- 谣言的产生和传播甚嚣尘上,自动检测谣言才能最小化他们带来的有害影响。
- 传统的谣言检测模型大多只提取post的文本特征(textual features)来进行分类。随着多媒体post的出现,基于文本和视觉的多模态谣言检测方法取得了比单文本模态方法更好的结果。但是现有多模态方法大多没有考虑到社交上下文信息(graphical social contexts),而这个特征对检测谣言也非常有用。
- 现有的考虑了social context的方法也有问题:1.极度依赖现有的实体之间的链接,但是由于数据抓取的限制,social graph中非常可能缺失重要的链接。因此本文补全潜在链接以获取更好的谣言检测准确率。2.graph的节点之间会有多种边关系,而传统的GNN无法区分不同边对目标节点的影响。3.如何有效融合social graph features和另外模态的信息研究较少。
本文主要贡献:
- 提出一个多模态特征增强的注意力网络用于多模态谣言检测,能够将textual,visual,social graph 特征融合进一个统一的框架;
- 介绍了一种自监督的损失函数从不同的角度对齐post表示,以实现更好的多模态融合;
- 通过增强图拓扑结构和邻居聚合过程来改进graph的特征学习过程;
- 实验表明本文的方法在两个大规模现实世界数据集上检测谣言的性能高于SOTA方法;
本文模型及方法:
本文中的social context包括post的发推用户(forwarding users)和相关联的评论(corresponding comments)。
4.1. 文本和视觉特征提取 textual and visual feature extractor;
- 文本特征表示 textual representations;
本文先用[1]中提供的word vectors作为text中word的初始embedding,然后用CNN和max pooling作用于一个text的word embeddings,得到一个text的特征表示。通过分别使用k=3,4,5的感受野,得到三个text的表示之后拼接起来,作为本文的text feature。
![]()
- 视觉特征表示 visual representations;
本文使用在ImageNet上训练的预训练模型ResNet50来提取图像的特征。将ResNet50的倒数第二层输出结果经过一个全连接层,得到本文的visual feature。
![]()
4.2. 社交图特征学习 social graph feature learning;
- 推测隐藏的链接;
为了降低缺失链接的影响,本文补全social graph中可能缺失的链接。
首先,本文将所有post,comment和user作为节点node,一起构建为一个graph。该graph中post,comment节点的初始emb用其sentence vectors表示,然后user节点的初始emb用该user所发的所有post的初始emb的均值表示。
然后,作者计算该graph中每两个节点之间的余弦相似度(用节点的初始emb表示计算余弦相似度),如果余弦相似度>0.5,就认为这两个节点之间应该有一条潜在边(也就是有隐藏的链接)。
通过上述方式,作者构建了一个新的graph,补全了原始graph中的缺失链接。
- 捕获多角度的邻居关系;
本文采用GAT捕获social graph structure信息。原始GAT在计算了目标节点与它所有邻居节点的attention权重之后,直接softmax得到重要程度值。这种情况下attention权重如果是较大的负值,就会被赋予较小的重要程度。
然而,在本文任务中,post和comment组成的图中,负值的attention权重可能代表了一种相反的观点(比如post是谣言,而它的comment反对该post内容),那么这种情况下,负值就具有了重要的意义,不能直接被softmax为不重要的东西。
因此,本文保留最开始计算出的attention权重![]() ,及该权重的取反值
,及该权重的取反值![]() ,然后分别进行后续softmax,加权和的计算。最后将得到的两个表示拼接并经过一个全连接层,得到最终的目标节点的emb。
,然后分别进行后续softmax,加权和的计算。最后将得到的两个表示拼接并经过一个全连接层,得到最终的目标节点的emb。

![]()
- 图特征提取 graph feature extractor;
基于4.2第一部分构建的新的graph(包含推测的隐藏链接),本文使用GAT获取其中所有post节点的特征表示。
首先,初始化graph中post,comment,user节点的emb。对于post和comment节点,使用他们的textual features作为初始emb。对于user节点,使用该user的所有post及comment的emb的均值作为初始emb(为什么和4.2第一部分的节点初始化过程不同呢?我个人的理解,这里的 textual features是公式 2中的 R_t,user节点也是用post和comment的R_t的均值得到的,这些表示全都参与本文模型的训练。而4.2第一部分中计算余弦相似度的节点emb是本文从[1]中直接拿的word emb,是不需要经过训练的。)。
然后如同公式9,用本文改进过的attention更新graph中每一个节点的emb表示,最后使用多头自注意力机制得到graph中所有节点的最终feature。其中所有post节点的特征就是本文提取的social graph feature,记为![]() .
.
4.3 多模态特征融合 multi-modal feature fusion;
- 跨模态co-attention机制
经过上述过程,本文得到了一个post的三种模态特征,分别是textual R_t,visual R_v,social graph R_g features。本文需要融合这三种模态的特征。
首先对每一个模态的特征做多头自注意力,以textual为例,Z_t 的学习过程见下面的两个公式。 然后也得到了视觉模态和社交图模态的特征:![]() 。
。
![]()
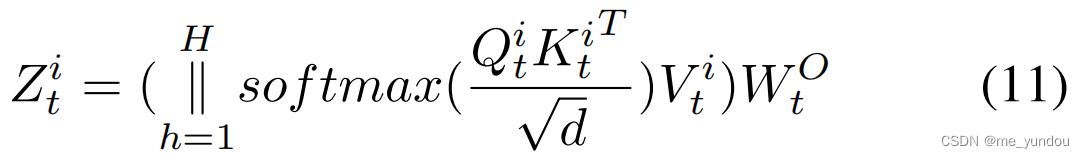
然后,针对文本和视觉模态,采用co-attention机制进行融合。具体而言,将上述多头自注意力中的query Q由视觉特征 Z_v 计算得到,key和value由文本特征 Z_t 计算得到,然后计算出 Z_vt:
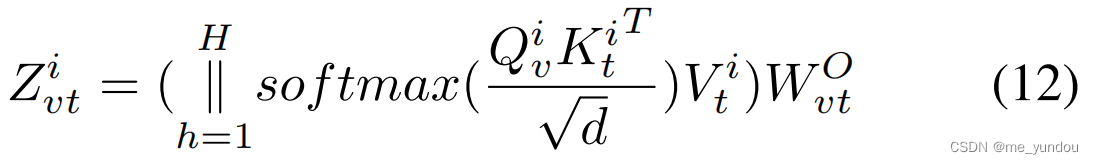
同时,交换 Z_v 和 Z_t ,同样可以计算得到 Z_tv。就完成了对textual和visual特征的融合。
- 多模态对齐
这一部分只对齐了post的textual feature和social graph feature(为什么不考虑visual和social graph的对齐呢?我不理解)。
首先将textual和graphical features映射到同一个模态空间,

然后计算映射后的特征表示的均方误差MSE loss,用最小化均方误差的方式来实现他俩的对齐。
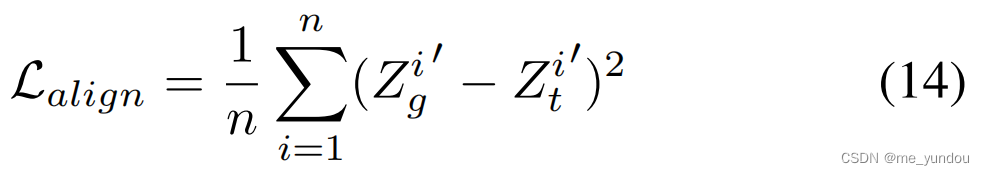
- 融合上述多模态特征
本文直接把上述过程获取的textual,visual,social graph features两两经过一个co-attention模块,最终得到6个特征,然后拼接这6个特征作为最终得到的post的特征表示。
![]()
4.4 借助对抗训练的分类 classification with adversarial training;
最后将公式15的特征表示经过一个全连接层后接一个softmax,来预测输入post的真假。
![]()
然后计算二分类的交叉熵损失,最后和MSE损失一起用于训练本文的模型。
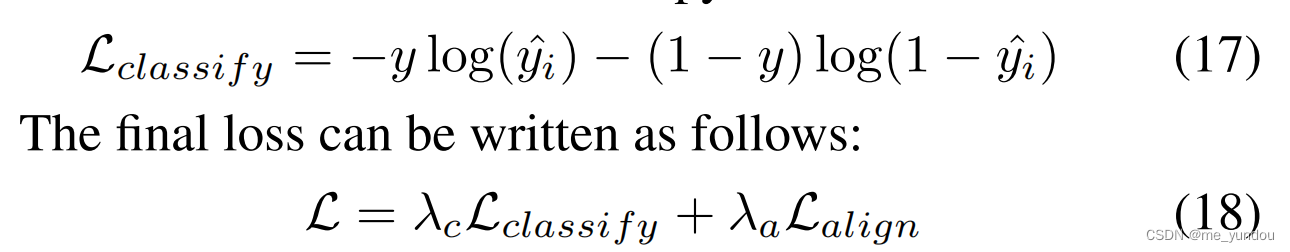
其中,由于社交网络上的文本通常不严格遵守语言的语法规范,所以本文采取了一种对抗扰动的方式来提升模型的鲁棒性,主要作用于模型的训练过程,和模型结构没什么大关系,所以博主没有去仔细了解,预知详情,大家可以自行参考[2]。
实验及分析:
5.1 数据集
本文使用Weibo [3] 和PHEME [4] 两个数据集,见下图。数据集中包含post的texts,images和comments,没有这些信息的post本文不考虑进实验。作者给的代码地址中有数据集获取方式。

5.2 对比方法:
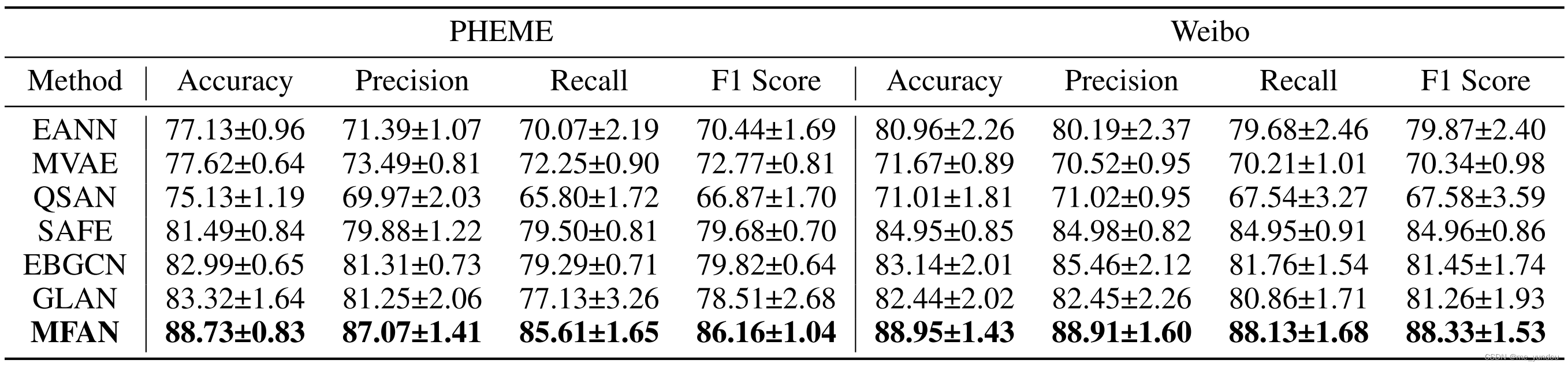
EANN,MVAE,QSAN,SAFE, EBGCN,GLAN;
其中EANN,MVAE,SAFE使用了textual和visual特征。QSAN只用了textual数据。EBGCN和GLAN考虑了social graph特征。但是他们都没有同时考虑三种模态的特征。
5.4 结果及分析
由下表可见,本文模型好于其他所有baselines。说明同时提取三种模态的特征对于检测谣言是有必要的。
5.5 消融实验
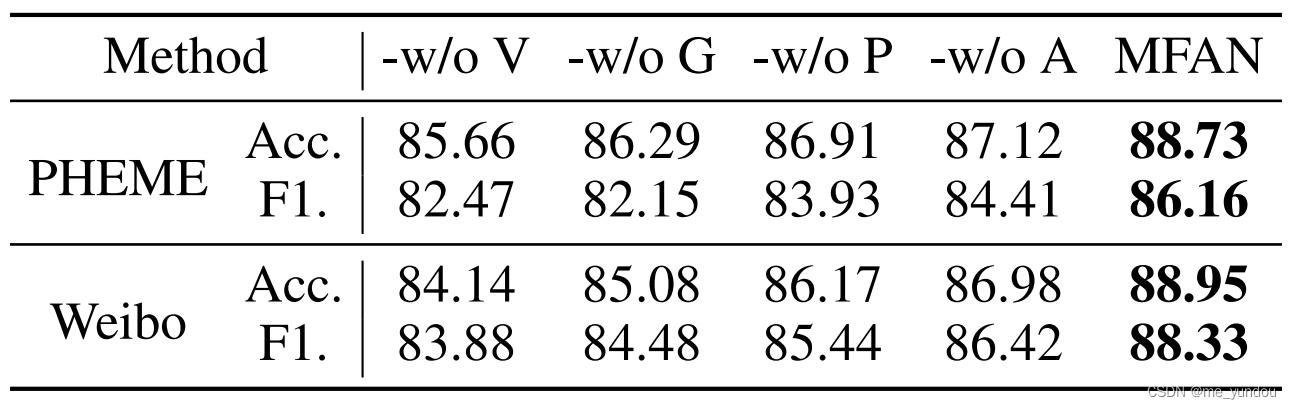
对本文模型的变体分别进行了实验,结果如下表。-w/o V/G/P/A 分别表示本文完整模型分别去掉视觉信息,社交网络信息,潜在链接部分,模态对齐部分,之后的模型。结果表明,本文对视觉信息,社交网络信息的利用是有助于检测谣言的。本文模型中的推测隐藏social graph中链接,以及模态对齐模块,都是有效的。
个人理解和问题:
1. 多模态谣言检测真的是太卷了,文本,图像,社交网络信息,外部知识库,各种数据都要拿来用一用,只用文本和图像的方法感觉都落伍了TAT,科研真难啊。
2. 本文在textual和visual特征融合时,对这两个特征一视同仁,采用了相同的处理方式(公式12)。在最终融合三个模态特征时也是一视同仁(公式15)。那么为什么在多模态对齐的时候只对齐了textual和social graph feature呢?
3. 2017年的多模态谣言检测方法att-RNN同时考虑了textual,visual,social context三种模态的特征,本文为什么没有和这个方法做对比呢?
参考文献:
[1] Chunyuan Yuan, Qianwen Ma, Wei Zhou, Jizhong Han, and Songlin Hu. Jointly embedding the local and global relations of heterogeneous graph for rumor detection. In ICDM, pages 796–805. IEEE, 2019.
[2] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
[3] Changhe Song, Cheng Yang, Huimin Chen, Cunchao Tu, Zhiyuan Liu, and Maosong Sun. Ced: Credible early detection of social media rumors. IEEE Transactions on Knowledge and Data Engineering, 33(8):3035–3047, 2019.
[4] Arkaitz Zubiaga, Maria Liakata, and Rob Procter. Exploiting context for rumour detection in social media. In International Conference on Social Informatics, pages 109–123. Springer, 2017.


