
- 1Github 令牌(Personal access tokens )申请及使用
- 2transformer详解:transformer/ universal transformer/ transformer-XL_transformer_xl用于图像
- 32023 工业 AR 关键词:纵深和开拓
- 4农业智能化灌溉系统_智慧农业灌区设备生产执行标准有哪些
- 5M1芯片Mac book pro部署stable diffusion模型_m1 stable diffusion
- 6MySQL面试题系列-8
- 7什么是CDC?
- 8使用LoRA和QLoRA微调LLMs:数百次实验的见解
- 9设备如何使用go sdk轻松连接华为云IoT平台_device-sdk-go集成
- 10每日论文速递 | 苹果发文:VLMs离视觉演绎推理还有多远
Unet网络---网络结构和pytorch实现_unet的pytorch代码
赞
踩
一、Unet网络
论文地址:https://arxiv.org/pdf/1505.04597.pdf
pytorch代码:https://github.com/milesial/Pytorch-UNet
二、网络结构
话不多说,先上图
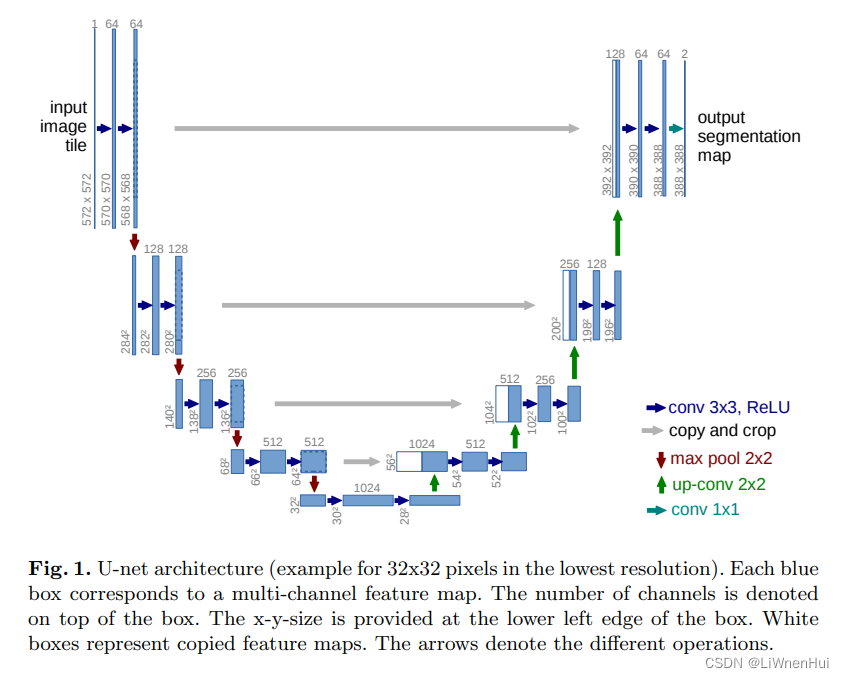
Unet很简单,具体可以看作为左右两个部分,自上而下的编码器Encode和和由下而上的解码器Decode。Unet相较于其他深度学习网络,更常用于计算机视觉领域,因为可以输出输入图像原始尺寸大小的图片,可以在输入图片上实现01分割,分类,语义分割等计算机视觉任务,且大部分只需要更改网络输出层的输出头,即可实现不同任务。Unet网络原文输出为一个2通道数据,可以完成01图像分割任务。
1、编码器(Encoder)
根据网络结构图,我们发现image图像二维图像输入,经过两次卷积使得通道由channel =1变为channel=64,随后使用Max pool对图像下采样至图像原始大小的一半通道数channel保持不变为64,继续使用两次卷积将通道数扩充为128,重复以上操作。压缩图片大小至32*32,通道为1024。
编码器负责将输入数据转换为一种更抽象、更紧凑的表示形式,通常是低维度的特征向量或特征图。它通过一系列的层和操作对输入数据进行逐层的处理和提取,以捕捉输入数据中的关键特征和信息。编码器的输出通常被认为是输入数据的高级表示,其中包含了输入数据的重要特征。
例如,我们描述一张人脸,如果我们只用一个特征即通道数表示人脸信息,我们可以说这张脸是一张圆脸,长脸,瓜子脸。但是我们仍然无法根据这个特征抽象出这个人脸是什么样子,我们可以增加人脸的特征值数量,例如:眼睛为桃花眼,眼间距是50mm,嘴唇宽厚等一系列人脸信息来描述这张人脸,就此我们就获得了这张人脸的特征信息。编码器的一系列卷积池化等操作也在尽可能抽象出输入图片的特征,并用深度学习的语言和可以理解的数据方式存储,以备后续使用。也即我们对人脸进行了编码。
2、解码器(Decode)
根据网络结构图,解码器自下而上,通过卷积和上采用操作,将图片通道数减少,尺寸不断变大。简单理解就是根据我编码后的结果,不断将特征值所提供的信息展现在输出结果上。解码器则与编码器相反,负责将编码器输出的抽象表示解码为原始输入数据的重建或生成。它通过逆向的层和操作,将编码器输出映射回原始数据空间,并尽可能恢复输入数据的细节和结构。解码器的目标是生成与原始输入数据尽可能相似的重建输出。
虽然我们没有见过网络输入的人脸,但是我们可以通过人脸的一些特征信息去恢复出一张人脸。
3、跳跃链接(skip)
在编码器和解码器之间的每个层级,U-Net 使用了跳跃连接来保留和传递更高层级的特征信息。这样可以将低层级的特征信息直接传递给高层级,帮助解码器更好地恢复细节和边缘信息。这样,解码器可以同时利用来自编码器的低层级特征和自身的高层级特征来进行重建。这种跳跃连接的结构使得 U-Net 具有较强的上下文感知能力和细节恢复能力,适用于图像分割任务。在Pytorch中,我们常常使用cat操作实现通道合并即:
torch.cat((y, x), dim=1)cat操作在维度dim=1,将y与x 实现合并操作(concatenate),在dim维度上,必须保证除了拼接维度上其他维度的大小是相同的。
三、代码实现
1、编码器
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
-
-
- class DoubleConv(nn.Module):
- """(convolution => [BN] => ReLU) * 2"""
-
- def __init__(self, in_channels, out_channels, mid_channels=None):
- super().__init__()
- if not mid_channels:
- mid_channels = out_channels
- self.double_conv = nn.Sequential(
- nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
- nn.BatchNorm2d(mid_channels),
- nn.ReLU(inplace=True),
- nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
- nn.BatchNorm2d(out_channels),
- nn.ReLU(inplace=True)
- )
-
- def forward(self, x):
- return self.double_conv(x)
-
-
- class Down(nn.Module):
- """Downscaling with maxpool then double conv"""
-
- def __init__(self, in_channels, out_channels):
- super().__init__()
- self.maxpool_conv = nn.Sequential(
- nn.MaxPool2d(2),
- DoubleConv(in_channels, out_channels)
- )
-
- def forward(self, x):
- return self.maxpool_conv(x)

2、解码器
- class Up(nn.Module):
- """Upscaling then double conv"""
-
- def __init__(self, in_channels, out_channels, bilinear=True):
- super().__init__()
-
- # if bilinear, use the normal convolutions to reduce the number of channels
- if bilinear:
- self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
- self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
- else:
- self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
- self.conv = DoubleConv(in_channels, out_channels)
-
- def forward(self, x1, x2):
- x1 = self.up(x1)
- # input is CHW
- diffY = x2.size()[2] - x1.size()[2]
- diffX = x2.size()[3] - x1.size()[3]
-
- x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
- diffY // 2, diffY - diffY // 2])
- # if you have padding issues, see
- # https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
- # https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
- x = torch.cat([x2, x1], dim=1)
- return self.conv(x)
-
-
- class OutConv(nn.Module):
- def __init__(self, in_channels, out_channels):
- super(OutConv, self).__init__()
- self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
-
- def forward(self, x):
- return self.conv(x)
3、分割头
- class OutConv(nn.Module):
- def __init__(self, in_channels, out_channels):
- super(OutConv, self).__init__()
- self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
-
- def forward(self, x):
- return self.conv(x)
4、完整网络结构
- from .unet_parts import *
-
-
- class UNet(nn.Module):
- def __init__(self, n_channels, n_classes, bilinear=False):
- super(UNet, self).__init__()
- self.n_channels = n_channels
- self.n_classes = n_classes
- self.bilinear = bilinear
-
- self.inc = (DoubleConv(n_channels, 64))
- self.down1 = (Down(64, 128))
- self.down2 = (Down(128, 256))
- self.down3 = (Down(256, 512))
- factor = 2 if bilinear else 1
- self.down4 = (Down(512, 1024 // factor))
- self.up1 = (Up(1024, 512 // factor, bilinear))
- self.up2 = (Up(512, 256 // factor, bilinear))
- self.up3 = (Up(256, 128 // factor, bilinear))
- self.up4 = (Up(128, 64, bilinear))
- self.outc = (OutConv(64, n_classes))
-
- def forward(self, x):
- x1 = self.inc(x)
- x2 = self.down1(x1)
- x3 = self.down2(x2)
- x4 = self.down3(x3)
- x5 = self.down4(x4)
- x = self.up1(x5, x4)
- x = self.up2(x, x3)
- x = self.up3(x, x2)
- x = self.up4(x, x1)
- logits = self.outc(x)
- return logits
-
- def use_checkpointing(self):
- self.inc = torch.utils.checkpoint(self.inc)
- self.down1 = torch.utils.checkpoint(self.down1)
- self.down2 = torch.utils.checkpoint(self.down2)
- self.down3 = torch.utils.checkpoint(self.down3)
- self.down4 = torch.utils.checkpoint(self.down4)
- self.up1 = torch.utils.checkpoint(self.up1)
- self.up2 = torch.utils.checkpoint(self.up2)
- self.up3 = torch.utils.checkpoint(self.up3)
- self.up4 = torch.utils.checkpoint(self.up4)
- self.outc = torch.utils.checkpoint(self.outc)
扩展
Unet网络结构简单,参数量少,但是可以获得细节丰富的输出,U形网络设计也为之后的计算机视觉工作提供了很多思路,同时也Unet网络也可以做很多优化改动,例如,可以在跳跃链接(skip)上添加注意力机制(Attention Mechanism)例如:通道-空间注意力机制;修改卷积层卷积核大小和数量可以影响感受野的大小和特征提取的能力。较小的卷积核可以捕捉更细节的特征,而较大的卷积核可以捕捉更全局的特征。
后面我也会做一些Unet网络优化的例子

