
- 1MATLAB与ROS联合仿真——实例程序搭建思路_matlab与ros联合路径规划
- 2采样方法_采样估计期望
- 310 | Swoole与Go系列教程之Redis连接池的应用_swoole\database\redispool 方法
- 4【前沿技术杂谈:NLP技术的发展与应用】探索自然语言处理的未来_nlp最新方向技术
- 5二分查找那点事_二分查找是谁发明的
- 6自注意力机制(self-attention)
- 7android studio 没有SDK Location选项问题_android studio没有sdk location
- 8The cost from the bebe Daniela
- 9小程序常问面试题_小程序面试题
- 10什么是数据清洗?带你了解关于数据清洗的三大问题!_请解释数据清洗的定义,并列举三种常见的数据质量问题。
大模型之二十-中英双语开源大语言模型选型_中英文大模型 选哪个
赞
踩
从ChatGPT火爆出圈到现在纷纷开源的大语言模型,众多出入门的学习者以及跃跃欲试的公司不得不面临的是开源大语言模型的选型问题。
基于开源商业许可的开源大语言模型可以极大的节省成本和加速业务迭代。
当前(2023年11月17日)开源的大语言模型如下:
| 模型 | 所属公司 | 发布时间 | 开放模型 | 许可 | 词表大小 | 语料 | Huggingface下载量 | 模型结构 | 位置编码 | 激活函数 | 隐变量维度dimension | 自注意力头的个数n heads | 层数n layers | 输入序列长度sequence length | 训练时长 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-2 | Meta | 2023年8月 | 7B 13B 70B | 允许商用,月活超7亿需向Meta申请许可 | 32000 | 2.0T | 70B-chat下载量1.69M,变种还有若干 | Casual decoder | RoPE | SwiGLU | Pre RMS Norm | 7B 4096, 13B 5120, 70B 8192 | 7B 32, 13B 40, 70B 64 | 7B 32, 13B 40, 70B 80 | 4096 | A100 7B 184320, 13B 368640, 70B 1720320 |
| baichuan-2 | 百川智能 | 2023年9月6日 | 7B 13B base/chat | 代码Apache 2.0,模型非商用 | 125696 | 2.6T | 1-7B 95.5k,2-13B 40.8k, 2-7B 20.5k | Prefix decoder | RoPE | GeGLU | Post Deep Norm | 7B 4096, 13B 5120 | 7B 32, 13B 40 | 7B 32, 13B 40 | 4096 | |
| ChatGLM3 | 智普 | 2023年10月 | 6B | 填问卷登记后允许免费商业使用 | 65024 | 1.5T左右中英 | 8k | Casual decoder | RoPE | SwiGLU | Post Deep Norm | 4096 | 32 | 28 | 8192 | |
| 千问 | 阿里 | 2023年8月 | 7B 14B | 允许商用,超过1亿用户机构需申请 | 151936 | 7B 2.4T,14B 3.0T | 25k | Casual decoder | RoPE | SwiGLU | Pre Layer Norm | 4096 | 32 | 32 | 8192 | |
| Bloom | BigScience | 2022年7月 | 560M 1.1B 1.7B 3B 7.1B | 允许商用 | 250880 | 366B | 125M | Casual decoder | ALiBi | GeLU | Pre Layer Norm | 4096 | 32 | 30 | 2048 |
- LLaMA-2的词表是32k,在中英文上的平均token数最多,对中英文分词比较碎,比较细粒度。尤其在中文上平均token数高达1.45,这意味着大概率会将中文字符切分为2个以上的token。
- ChatGLM3-6B是平衡中英文分词效果最好的tokenizer。由于词表比较大,中文处理时间也有增加。
- BLOOM虽然是词表最大的,但由于是多语种的,在中英文上分词效率与ChatGLM-6B基本相当。
还有很多其他的开源中英大语言模型,但基本都有Llama的影子,有些是直接扩充Lllama的词汇再用新的数据集重新训练,这些大语言模型包括Chinese-LLaMA-Alpaca-2、OpenChineseLLaMA、Panda、Robin (罗宾)、Fengshenbang-LM等,这里就不一一列出了。
和信息大爆炸一样,模型也是呈现大爆炸的态势,如何选择一个合适自己/公司业务场景的基座大模型就显得十分重要,模型选择的好,至于训练方法和一些训练技巧以及超参设置都不那么重要,相对而言数据工程确是相对重要的。一个模型的选择需要结合自身的目的和资源决定。
从模型到落地,涉及到方方面面的东西,相对而言模型公司也注意到了,所以开源模型也会附带一些Agent等支持。选择模型第一要考虑的是license问题,如果是学习目的,那么几乎所有开源的大语言模型都可以选择,结合算力和内存资源选择合适参数量的模型即可,如果是蹭免费GPU的,建议选择7B及以下的模型参数。
如果是商用目的的建议选择70B及以上的模型,个别很窄的垂直领域也可以考虑30B左右的,甚至是7B的参数,如果是端上智能,考虑7B参数量。
10B以内的中英模型,建议选择chatglm3-6B(生态工具支持也挺好,性能在10B里中英文很不错,上下文长度基座有8k,长上下文大32k)以及llama-2的变种(LlaMA-2生态很好,工具很多)模型。算力有限的学生建议选择Bloom 1.1B模型。
chatglm和LlaMA-2在模型有些差异,关于mask和norm的差异性区别如下。
transformer中的mask机制:
mask机制是用于Transformer模型self-attention机制中的技术,用以控制不同token之间的注意力交互。有两种类型的mask:padding mask和sequence mask。
- Padding mask(填充掩码):在自注意力机制中,句子中的所有单词都会参与计算。但是,在实际的句子中,往往会存在填充符,用来填充句子长度不够的情况。Padding mask就是将这些填充符对应的位置标记为0,以便在计算中将这些位置的单词忽略掉。
- Sequence mask(序列掩码):sequence mask用于在Decoder端的self-attention中,以保证在生成序列时不会将未来的信息泄露给当前位置的单词。
Norm层
-
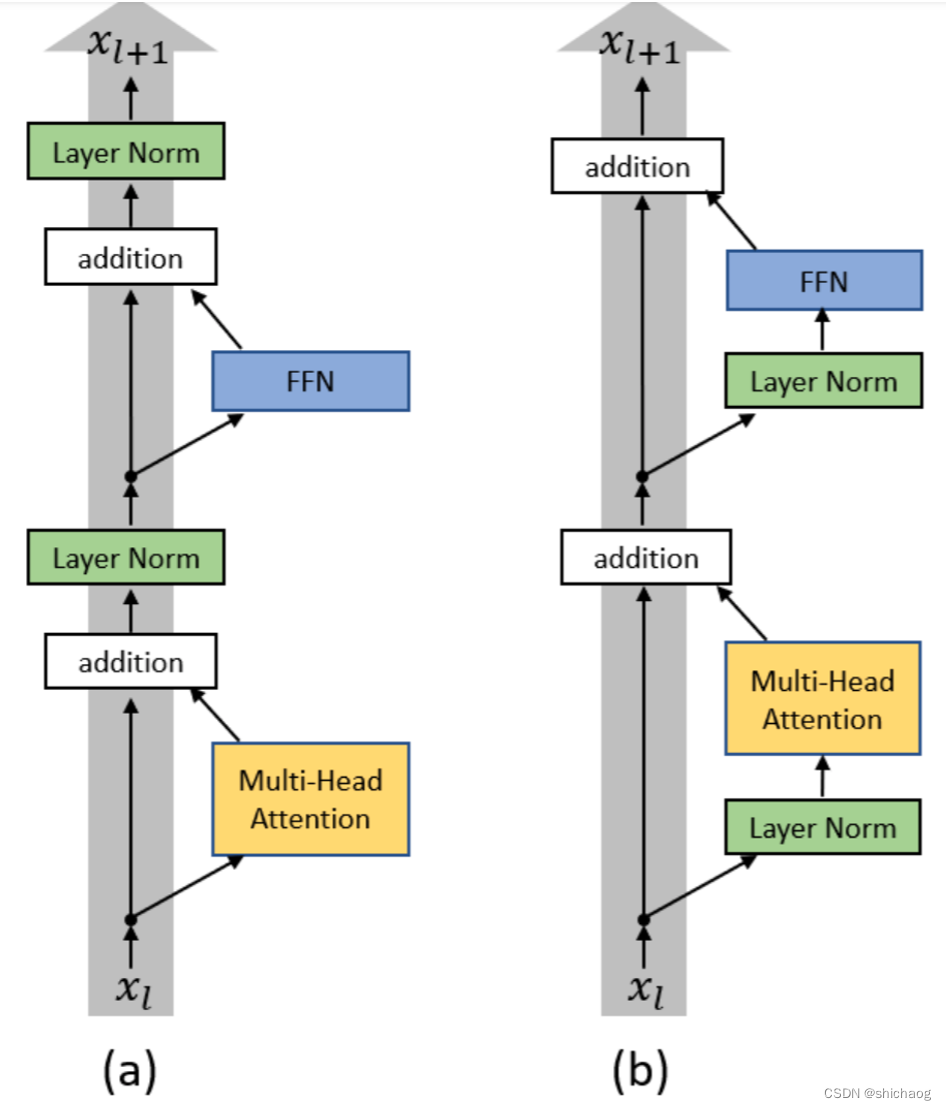
post layer norm。在原始的transformer中,layer normalization是放在残差连接之后的,称为post LN。使用Post LN的深层transformer模型容易出现训练不稳定的问题。post LN随着transformer层数的加深,梯度范数逐渐增大,导致了训练的不稳定性。
-
pre layer norm。将layer norm放在残差连接的过程中,self-attention或FFN块之前,称为“Pre LN”。Pre layer norm在每个transformer层的梯度范数近似相等,有利于提升训练稳定性,但缺点是pre LN可能会轻微影响transformer模型的性能,为了提升训练稳定性,GPT3、PaLM、BLOOM、OPT等大语言模型都采用了pre layer norm。
- LayerNorm:LayerNorm对每一层的所有激活函数进行标准化,使用它们的均值和方差来重新定位和调整激活函数。其公式如下:
x − μ σ ⋅ γ β , μ = 1 d ∑ i = 1 d x i , σ = 1 d ∑ i = 1 d ( x i − μ ) 2 \frac{\mathbf x -\mu}{\sqrt{\sigma}} \cdot \gamma \beta, \mu=\frac{1}{d} \sum_{i=1}^dx_i, \sigma=\sqrt{\frac{1}{d}\sum_{i=1}^{d}(x_i-\mu)^2} σ x−μ⋅γβ,μ=d1i=1∑dxi,σ=d1i=1∑d(xi−μ)2 -
- RMSNorm:RMSNorm通过仅使用激活函数的均方根来重新调整激活,从而提高了训练速度。
x R M S ( x ) ⋅ γ , R M S ( x ) = 1 d ∑ i = 1 d x i 2 \frac{\mathbf x}{RMS(\mathbf x)} \cdot \gamma, RMS(\mathbf x)=\sqrt{\frac{1}{d}\sum_{i=1}^dx_i^2} RMS(x)x⋅γ,RMS(x)=d1i=1∑dxi2
- LayerNorm:LayerNorm对每一层的所有激活函数进行标准化,使用它们的均值和方差来重新定位和调整激活函数。其公式如下:
-
- DeepNorm:为了进一步稳定深度Transformer的训练,Microsoft推出了DeepNorm。这是一个创新的方法,它不仅用作标准化,还作为残差连接。有了DeepNorm的帮助,我们现在可以轻松训练高达1000层的Transformer模型,同时保持稳定性和高性能。其中,GLM-130B和ChatGLM就是采用了这种技术的代表。其公式如下:其中SublayerSublayer是FFN或Self-Attention模块。
L a y e r N o r m ( α ⋅ x + S u b l a y e r ( x ) ) LayerNorm(\alpha\cdot \mathbf x+Sublayer(\mathbf x)) LayerNorm(α⋅x+Sublayer(x))
- DeepNorm:为了进一步稳定深度Transformer的训练,Microsoft推出了DeepNorm。这是一个创新的方法,它不仅用作标准化,还作为残差连接。有了DeepNorm的帮助,我们现在可以轻松训练高达1000层的Transformer模型,同时保持稳定性和高性能。其中,GLM-130B和ChatGLM就是采用了这种技术的代表。其公式如下:其中SublayerSublayer是FFN或Self-Attention模块。

