
- 1机器学习、深度学习笔试题面试题整理_人工智能 & 机器学习 & 深度学习】基础选择题1~30题 练习 | 人工智能 面试题:请介
- 220万DBA都在关注的12个问题丨DBASK回答集萃第七期_12c ogg 10g
- 3基于C++的定时获取网页+源代码_c++ 获取360网页源代码
- 410.windows ubuntu 组装软件:spades,megahit
- 5java 分词搜索功能_给全文搜索引擎Manticore (Sphinx) search 增加中文分词
- 6关于胶质母细胞瘤的影像组学和影像基因组学
- 7python英文文本词性分析_python 输出英语单词词性
- 8清华裴丹|大模型时代的AIOps
- 9Attentional Feature Fusion 注意力特征融合_注意力融合
- 10在文本关键词提取中TF-IDF和TextRank算法结合使用的步骤_基于tf-idf算法和texttabk算法的文本特征提取
有哪些省内存的大语言模型训练/微调/推理方法?
赞
踩

©作者 | 李雨承
单位 | 英国萨里大学
研究方向 | Conceptual Reasoning
大模型(LLMs)现在是 NLP 领域的最主流方法之一了。
这个趋势带来的主要问题之一,就是大模型的训练/微调/推理需要的内存也越来越多。
举例来说,即使 RTX 3090 有着 24GB 的 RAM,是除了 A100 之外显存最大的显卡。但使用一块 RTX 3090 依然无法 fp32 精度训练最小号的 LLaMA-6B。
本文总结一些 Memory-Efficient 的 LLMs 的训练/微调/推理方法,包括:
● fp16
● int8
● LoRA
● Gradient checkpointing
● Torch FSDP
● CPU offloading

估算模型所需的RAM
首先,我们需要了解如何根据参数量估计模型大致所需的 RAM,这在实践中有很重要的参考意义。我们需要通过估算设置 batch_size,设置模型精度,选择微调方法和参数分布方法等。
接下来,我们用 LLaMA-6B 模型为例估算其大致需要的内存。
首先考虑精度对所需内存的影响:
● fp32 精度,一个参数需要 32 bits, 4 bytes.
● fp16 精度,一个参数需要 16 bits, 2 bytes.
● int8 精度,一个参数需要 8 bits, 1 byte.
其次,考虑模型需要的 RAM 大致分三个部分:
● 模型参数
● 梯度
● 优化器参数
模型参数:等于参数量*每个参数所需内存。
对于 fp32,LLaMA-6B 需要 6B*4 bytes = 24GB内存
对于 int8,LLaMA-6B 需要 6B*1 byte = 6GB
梯度:同上,等于参数量*每个梯度参数所需内存。
优化器参数:不同的优化器所储存的参数量不同。
对于常用的 AdamW 来说,需要储存两倍的模型参数(用来储存一阶和二阶momentum)。
fp32 的 LLaMA-6B,AdamW 需要 6B*8 bytes = 48 GB
int8 的 LLaMA-6B,AdamW 需要 6B*2 bytes = 12 GB
除此之外,CUDA kernel 也会占据一些 RAM,大概 1.3GB 左右,查看方式如下。

综上,int8 精度的 LLaMA-6B 模型部分大致需要 6GB+6GB+12GB+1.3GB = 25.3GB 左右。
再根据LLaMA的架构(hidden_size = 4096, intermediate_size =11008, num_hidden_layers = 32, context_length = 2048)计算中间变量内存。
每个 instance 需要:
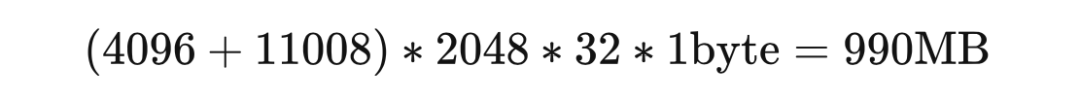
所以一张 A100(80GB RAM)大概可以在 int8 精度;batch_size = 50 的设定下进行全参数训练。
查看消费级显卡的内存和算力:
2023 GPU Benchmark and Graphics Card Comparison Chart
https://www.gpucheck.com/gpu-benchmark-graphics-card-comparison-chart

Fp16-mixed precision
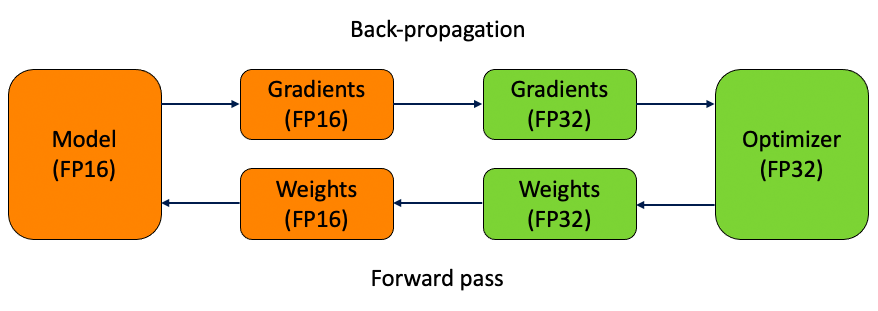
混合精度训练的大致思路是在 forward pass 和 gradient computation 的时候使用 fp16 来加速,但是在更新参数时使用 fp32。
用 torch 实现:
CUDA Automatic Mixed Precision examples
https://pytorch.org/docs/stable/notes/amp_examples.html
torch fp16 推理:直接使用 model.half() 将模型转换为fp16.

使用 Huggingface Transformers:在 TrainingArguments 里声明 fp16=True
https://huggingface.co/docs/transformers/perf_train_gpu_one#fp16-training

Int8-bitsandbytes
Int8 是个很极端的数据类型,它最多只能表示 - 128~127 的数字,并且完全没有精度。
为了在训练和 inference 中使用这个数据类型,bitsandbytes 使用了两个方法最大程度地降低了其带来的误差:
1. vector-wise quantization
2. mixed precision decompasition
Huggingface 在这篇文章中用动图解释了 quantization 的实现:
https://huggingface.co/blog/hf-bitsandbytes-integration
论文:
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
https://arxiv.org/abs/2208.07339
借助 Huggingface PEFT,使用 int8 训练 opt-6.5B 的完整流程:
https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb

LoRA
Low-Rank Adaptation 是微调 LLMs 最常用的省内存方法之一。
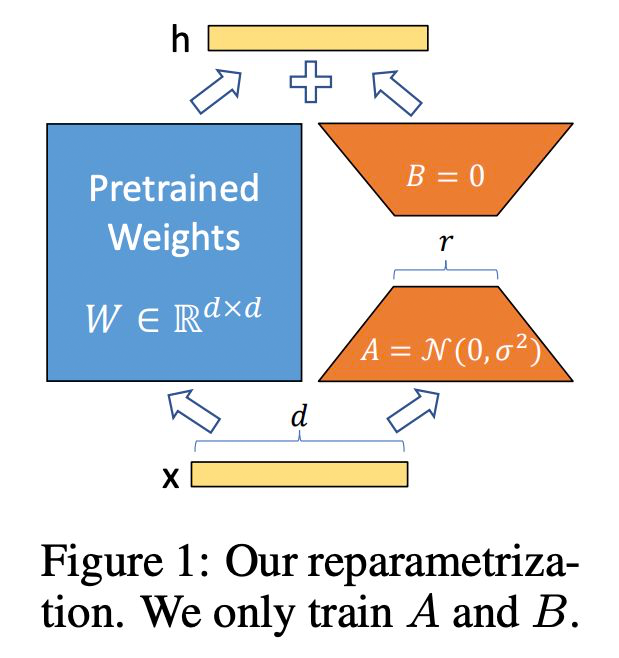
LoRA 发现再微调 LLMs 时,更新矩阵(update matrix)往往特别 sparse,也就是说 update matrix 是低秩矩阵。LoRA 的作者根据这一特点将 update matrix reparametrize 为两个低秩矩阵的积积 。
其中,,A 和 B 的秩为 r,且 。
如此一来,A+B 的参数量将大大小于 .
LoRA 的论文:
https://arxiv.org/pdf/2106.09685.pdf
借助 Huggingface PEFT 框架,使用 LoRA 微调 mt0:
https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq.ipynb

Gradient Checkpointing
在 torch 中使用 - 把 model 用一个 customize 的 function 包装一下即可,详见:
Explore Gradient-Checkpointing in PyTorch
https://qywu.github.io/2019/05/22/explore-gradient-checkpointing.html
在 Huggingface Transformers 中使用:
https://huggingface.co/docs/transformers/v4.27.2/en/perf_train_gpu_one#gradient-checkpointing

Torch FSDP+CPU offload
Fully Sharded Data Paralle(FSDP)和 DeepSpeed 类似,均通过 ZeRO 等分布优化算法,减少内存的占用量。其将模型参数,梯度和优化器状态分布至多个 GPU 上,而非像 DDP 一样,在每个 GPU 上保留完整副本。
CPU offload 则允许在一个 back propagation 中,将参数动态地从 GPU -> CPU, CPU -> GPU 进行转移,从而节省 GPU 内存。
Huggingface 这篇博文解释了 ZeRO 的大致实现方法:
https://huggingface.co/blog/zero-deepspeed-fairscale
借助 torch 实现 FSDP,只需要将 model 用 FSDPwarp 一下;同样,cpu_offload 也只需要一行代码:
https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
在这个可以查看 FSDP 支持的模型:
https://pytorch.org/docs/stable/fsdp.html
在 Huggingface Transformers 中使用 Torch FSDP:
https://huggingface.co/docs/transformers/v4.27.2/en/main_classes/trainer#transformers.Trainin
根据某些 issue,shard_grad_op(只分布保存 optimizer states 和 gradients)模式可能比 fully_shard 更稳定:
https://github.com/tatsu-lab/stanford_alpaca/issues/32
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

