
- 1最新!2021年自然语言处理(NLP)算法学习路线
- 2从 Language Model 到 Chat Application:对话接口的设计与实现_yi-6b-chat pipeline
- 3自然语言处理(NLP)-spacy简介以及安装指南(语言库zh_core_web_sm)_安装spacy
- 4gpt文章改官方用语_用gpt改写文章的用语
- 5使用python进行nlp工程中的一些技巧(持续更新)_nlp 词典 保存
- 6Unity——JSON的读取_unity 读取json
- 7【nlp学习】中文命名实体识别(待补充)
- 8linux 测试程序性能,linux 压力测试性能IO MEM CPU
- 9BP神经网络的Matlab实现——人工智能算法
- 10c++中缓冲器的使用案例
智能聊天机器人的技术综述_智能语音聊天机器人的工作原理
赞
踩
本文转载,原文地址。
在转载过程中,资源和开放数据有更新,不代表原作者观点。
摘要
智能聊天机器人作为自然语言处理的一个重要分支,是目前最火热也最具挑战的研究方向,它对于促进人机交互方式的发展有着重要的意义。本文首先简要介绍了智能聊天机器人的分类和研究背景,对国内外研究现状进行比较,对生成和检索两种主流的实现技术进行优缺点分析,并分别列举了几项使用该技术手段实现的聊天机器人。然后,介绍了目前较为常用的生成型聊天机器人的模型以及评估方法,其中,对作为很多模型基础的Encoder-decoder模型做了详细介绍和分析,以及在此基础上完成的几个优化模型系统。最后,给出了一些参考的开源框架以及可使用的数据以供读者使用。
研究背景
目前市面上主要的智能聊天机器人可以分为如下两类:目标驱动型聊天机器人和无目标驱动型聊天机器人。目标驱动机器人是指机器人的服务目标或服务对象是明确的,是可以提供特殊服务的问答系统,处理特定领域的问题,即定领域的聊天机器人,比如客服机器人,订票机器人等。无目标驱动机器人是指机器人的服务对象和聊天范围不明确,可以处理的问题多种多样,解决问题时需要依赖于宇宙中的各种信息和本体,即开放领域的聊天机器人,比如娱乐聊天机器人等。
智能聊天机器人实际上是为了应对信息爆炸的今天存在的信息过载问题。具体来说,其来源是因为人们对于简单的搜索引擎仅仅返回一个网页集合的不满,而通常用户更想获得的体验是在向智能对话系统用自然语言提出一个问题之后,且智能对话系统也能够自然又通顺地回答问题,且回答内容与问题紧凑相关又答案精准。为使用者们节约了更多的时间,无需逐个浏览和仔细阅读搜索引擎返回的每个链接网址中的信息,再剔除冗余信息后才能得到期望的答案。
有关于对话机器人的研究可以被追溯到20世纪50年代,当Alan M. Turing提出了“机器可以思考吗?”的图灵测试问题来衡量人工智能发展的程度,该领域接下来就变成了人工智能领域中一个十分有趣又具有挑战性的研究问题。
随着各种互联网公司的蓬勃发展以及各类移动终端和应用小软件的爆炸式普及,如Twitter和微博等,很多大互联网公司都在投入重金完成此领域技术的研究并陆续推出此类应用产品,比如苹果Siri,微软Cortana,脸书Messenger,谷歌Assistant等,这些产品都让用户们在移动终端更加方便地获得需要的信息和服务,从而获得更好的用户体验。因而,人们发现智能机器人可以应用的领域十分广泛,它可以被应用到很多人机交互的领域中,比如技术问答系统,洽谈协商,电子商务,家教辅导,娱乐闲聊等。
不得不说,由于人们对于智能聊天机器人不断增长的渴望和需求,人工智能在自然语言处理领域的应用变成了不论国内国外都非常热门的一个研究方向。在信息技术飞速发展,以及移动终端逐渐普及的今天,研究聊天机器人相关的技术,对于促进人工智能以及人机交互方式的发展有着十分重大的意义。
国内外研究现状对比
在人工智能领域,智能聊天机器人的研究已经有了很长的历史,它们都试图吸引用户不断继续聊天,通常表现为使用主导谈话的主题的手段,从而掌控谈话内容及谈话进度。但由于最初的研究受限于计算能力和知识库,导致了所有有关人工智能的实验规模都比较狭小,因此设计者们还会将谈话的内容局限在某一个特定的专家系统领域以此降低难度。
但随着1995信息检索技术的发展,Baidu,Google等搜索引擎公司计算能力的飞速提升,以及2005年互联网业的蓬勃发展和移动终端的迅速普及,在这三方面的共同作用下,智能聊天机器人,或者说智能问答系统一下子被推到风口浪尖,研究进展也非常值得关注。
由于国外在人工智能聊天机器人及问答系统方向的研究起步较早,因而也产生了一系列比较成熟的聊天系统以供用户使用,比如苹果Siri,微软Cortana,脸书Messenger,谷歌Assistant等。
这些跨平台型人工智能机器人,都借助着本公司在大数据、自然语义分析、机器学习和深度神经网络方面的技术积累,精炼形成自己的真实有趣的语料库,在不断训练的过程中通过理解对话数据中的语义和语境信息,从而实现超越一般简单人机问答的自然智能交互,为用户带来方便与乐趣。
相比国外,我国国内在智能聊天领域的投入规模和研究水平上都有着不小的差距,研究成果也并不显著。但是还是有一系列高校在此领域成绩显著,位于前列的主要有清华大学、中科院计算所、香港大学、香港中文大学和哈工大(benben)等。其中,高校在此领域的研究主要集中于对于自然语言处理的工具开发,比如哈尔滨工业大学的HIT工具(中文词法分析、句法分析和语法分析)以及台湾国防大学的CQAS中文问答系统(侧重于命名实体及其关系的处理)等。
工程要求及分类
实现需求
- 语境整合
系统需要在训练过程中不断整合物理语境和语言语境来生成较为明智的回复。结合语言环境最普遍的例子就是在长对话中,人们会记录已经说过的话以及以及和对方交换过的信息。其中最普遍的方法就是将对话嵌入一个向量中,此向量还可能需要整合其它类型的语境数据,例如日期/时间、位置或者用户信息等。
- 人格一致性与互信息
对于语义相同或者类似的输入,不论在何时输入,我们希望智能机器人会有相同的回答,比如“你叫什么名字?”和“你多大了?”等问题。这个目标看似十分容易达成,但是实际上要将固定的知识或者人格整合到模型中去是一个十分困难的研究难题。目前许多的智能聊天机器人系统可以做出语义较为合理的回答,但是却没有被进一步训练生成在语义上同样一致的回复。这一般是由于为了实验效果的增加,训练模型的数据可能来源于不同的用户而导致的。
- 意图以及多样性
目前普遍的智能问答系统经常会生成“我不知道”或者“太好了”这样的可以适用于大部分输入问题的答案。例如,Google的Smart Reply早期版本常常用“我爱你”回复一切不确定的问题。由于生成系统,特别在开放领域,没有被训练成特定意图,只是根据数据和实际训练目标或算法训练的结果,不具备一个令人满意的智能聊天机器人应该有的多样性。
目前该领域该方向的实现技术手段主要集中于基于规则或基于学习的方法。因此,相对应的,智能聊天机器人的实现技术手段目前也分为两种:基于检索的方式和基于生成的方式。
- 检索式
检索式聊天机器人是指使用了预定义回复库和某种启发方式来根据输入和语境做出合适的回复,这种启发方式既可以像基于规则的表达式匹配一样简单,也可以像机器学习分类器一样复杂。换一句话说,在这种模式下,机器人回复的内容都处于一个对话语料库中,当其收到用户输入的句子序列后,聊天系统会在对话语料库中进行搜索匹配并提取响应的回答内容,进行输出。
该系统不要求生成任何新的文本,只是从固定的集合中挑选一种回复而已,因而这种方式要求语料库的信息尽可能的大和丰富,这样才能够更加精准地匹配用户内容,并且输出也较为高质量,因为语料库中的既定语句序列相对于生成的序列而言更加自然和真实。
该模式下的机器人使用基于规则的方式进行模型的构造,因此我们只需要完成一个模式或者样板,这样当机器人从用户端获得的问题句子在已有的模板中时,该模型就可以向用户返回一个已有的模板。理论上,任何人都可以照此方法实现一个简单的聊天机器人,但是该机器人不可能回答比较复杂的问题,其模式匹配意识是十分薄弱的。除此之外,人工地完成这些规则和模式的制定是十分耗时和耗力的。
目前,在基于规则方面的一个非常流行的智能机器人是CleverBot,该网站提供了一个可以直接进行与机器人进行聊天的网页。
- 生成式
生成式聊天机器人在接受到用户输入后,会采用其它技术生成一句回复,作为聊天系统的输出。这种方式并不要求非常大和精准的语料库,因为它不依赖于预定义的回复库,但生成的回复可能会出现语法错误或语句不通顺等缺点。
该模式下的机器人使用基于学习的方法进行对于对话数据和规律的学习,很好地弥补基于规则模式下实现的智能机器人的缺点,因此我们可以建造一个机器人,并让它不断地从已经存在的人与人之间的对话数据中自主得学习对话规律,并在每次收到用户问题时,自主地组织词语回答问题,这是一种十分智能的实现方法,也是目前更为火热的研究方向。
使用生成式方式并且结合机器学习的方法的优点是十分明显的:得到相较于检索式而言更加有趣多样的回答,赋有多样性,避免沉闷和无聊;端到端End-to-end神经网络模型的参与可以减少对于人为制定规则的依赖,提升模型在长对话数据中的性能;深度学习的应用使得模型的可扩展性较强,模型本身可以和训练数据的语言互相剥离,不需要针对不同语言的数据进行数据预处理工作;可以通过扩大数据的方式持续提升模型的效果。
工程分类
常见技术模型
Encoder-decoder加解密模型
在以往的研究中,我们会发现实际上智能对话系统问题可以被很好地应用到的自然语言的机器翻译框架中,我们可以将用户提出的问题作文输入机器翻译模型的源序列,系统返回的答案则可以作为翻译模型的目标序列。因此,机器翻译领域相对成熟的技术与问答系统所需要的框架模型有了很好的可比性,Ritter等人借鉴了统计机器翻译的手段,使用Twitter上的未被结构化的对话数据集,提出了一个问答生成模型的框架。
Encoder-decoder框架目前发展较为成熟,在文本处理领域已经成为一种研究模式,可应用场景十分广泛。它除了在已有的文本摘要提取、机器翻译、词句法分析方面有很大的贡献之外,在本课题中,也可以被应用到人机对话和智能问答领域。
图1将Encoder-Decoder框架在自然语言处理领域的应用抽象为一个通用处理模型,即一个序列(或文章)转换为另外一个序列(或文章)。对于句子序列对 ,Encoder-Decoder框架在输入源序列X的情况下,生成目标序列Y,并不断改变模型参数提升这种可能性。在实际的应用中,序列X和序列Y分别由各自的单词序列构成,可以是一样或者不一样的语言:
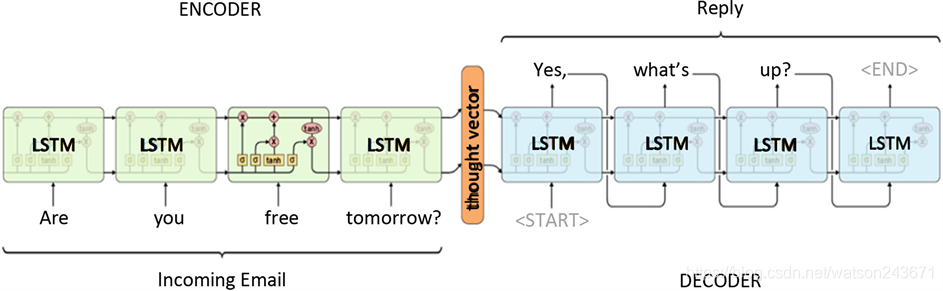
图1. 加解密模块实现的端到端模型
X
=
<
x
1
,
x
2
,
…
,
x
m
>
X=<x_1, x_2, \dots, x_m>
X=<x1,x2,…,xm>
Y
=
<
y
1
,
y
2
,
…
,
y
n
>
Y=<y_1, y_2, \dots, y_n>
Y=<y1,y2,…,yn>
模型中神经网络(如RNN或LSTM)将按照如下步骤计算此条件概率:首先,输入序列 (声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

