- 1git如何合并远程2个分支_git 合并两个分支
- 2论基于架构的软件设计方法(ABSD)及应用(系统架构师2024最新版)
- 3sd-webui-controlnet代码分析_controlnet控制sd源码
- 4Android 资源(resource)学习小结
- 5使用 DPO 微调 Llama 2
- 6ts中根据一个日期获取n天前后的日期或时间戳_ts 昨天、前天
- 7【Python基础】之元组tuple_python 初始化tuple
- 8鸿蒙开发页面之间如何传值_鸿蒙 params:{}使用
- 9Java从接触到放弃(二十六)----集合详解(上)_java.util.arraylist$itr cannot be cast to java.uti
- 10如何在自定义数据集上训练 YOLOv9
Python数据分析高薪实战第四天 构建国产电视剧评分数据集_.python 编程:在5.5.2节案例的基础上,考虑电视剧播放量对国产电视剧大众评分的预
赞
踩
10 实战:手把手教你构建国产电视剧评分数据集
在前面几讲,我们已经学习完了爬虫技术的三个基础环节:下载数据、提取数据以及保存数据。
今天我们将通过一个综合的实战案例来将之前的内容都串联起来,帮你加深印象,更好地掌握 Python 爬虫技术。
任务描述
近期,电视剧《司藤》热播,阿普闪购决定策划一场围绕国产口碑电视剧的周边特卖活动。为了最大化提升活动的成功率,需要对目前已经有的电视剧名称、演员和评分进行分析,以预判一个电视剧的评分走向。在一切预测与分析之前,首先就需要收集目前国产电视剧的相关数据,或者换句话说,需要构建一个国产电视剧和评分的数据集。
作为数据分析部门的实习生,暂时还承担不了具体的分析和建模的工作,所以数据集构建这个任务就自然落到了你的肩上。
任务说明
收集国产电视剧的数据,越全越好,至少收集评分、电视剧名称、主演信息三个信息。之后将数据存储在一个 csv 表中,表头如下:
-
title,代表电视剧的名称;
-
rating,代表电视剧的评分;
-
stars,代表电视剧的主演。
csv 的名字为,tv_rating.csv。
初步分析 — 选择抓取的网站
在基于 Python 技术来构建数据集的方式中,首当其冲要做的事情就是选择要抓取的网站。选择的标准一般主要看网站是否具备我们想要的信息,以及是否方便抓取。
这次我们要抓取的电视剧信息中,还有一个重要的考量因素就是**是否方便抓取多个页面,**毕竟一个网页一般都无法包含全部的电视剧信息。
我们在下载 HTML 页面的环节往往需要下载多个页才能获取完整的数据。
通过在搜索引擎搜索有电视剧列表的网站,我们筛选出了两个候选。
上述两个网站都有国产电视剧专区,我们接下来就逐一分析一下哪个更适合此次抓取任务。
豆瓣电视剧主页分析
打开豆瓣电视剧主页,我们可以看到如下的列表。
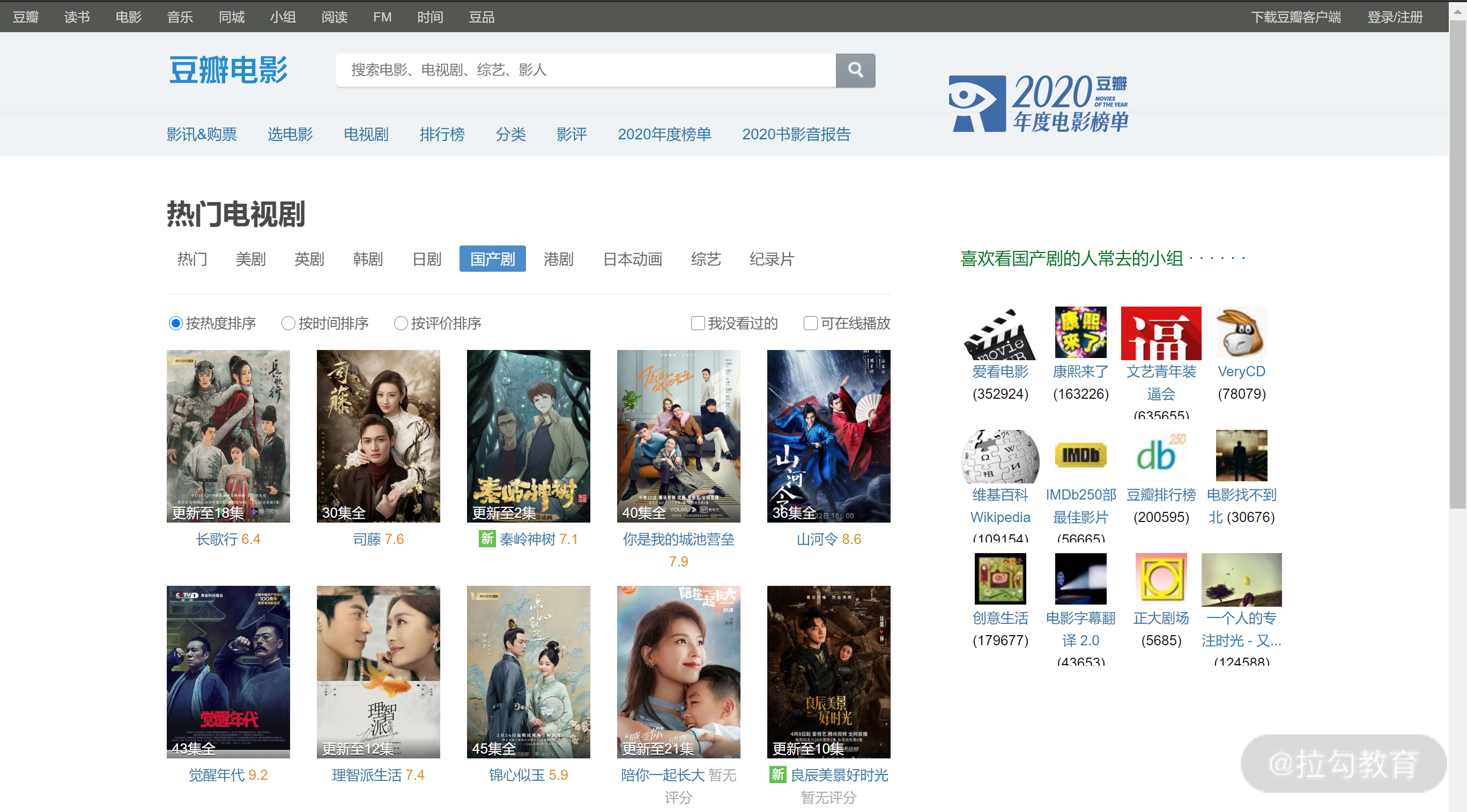
通过观察上述页面,可以看到一个比较明确的问题是:虽然有电视剧名和评分,但缺乏主演信息。
我们再来看它翻页的方式,拖到底部,可以看到一个加载更多的按钮,点击之后可以在底部加载更多的内容。没有传统的第一页,第二页这样的跳转链接。
总结下来,豆瓣的电视剧主页存在两个明显问题:
-
在电视剧列表中缺乏主演信息;
-
无法通过 URL 来下载第二页和之后的内容,因为加载更多内容是在第一页中动态生成的,而这样动态生成的内容很难通过 Python 拿到。
虽然这两个问题通过一些技巧也能解决,但是平添了很多工作量,所以我们暂时不考虑抓取豆瓣。
电视剧网主页分析
打开电视剧网,国产电视剧的主页,可以看到页面如下所示。
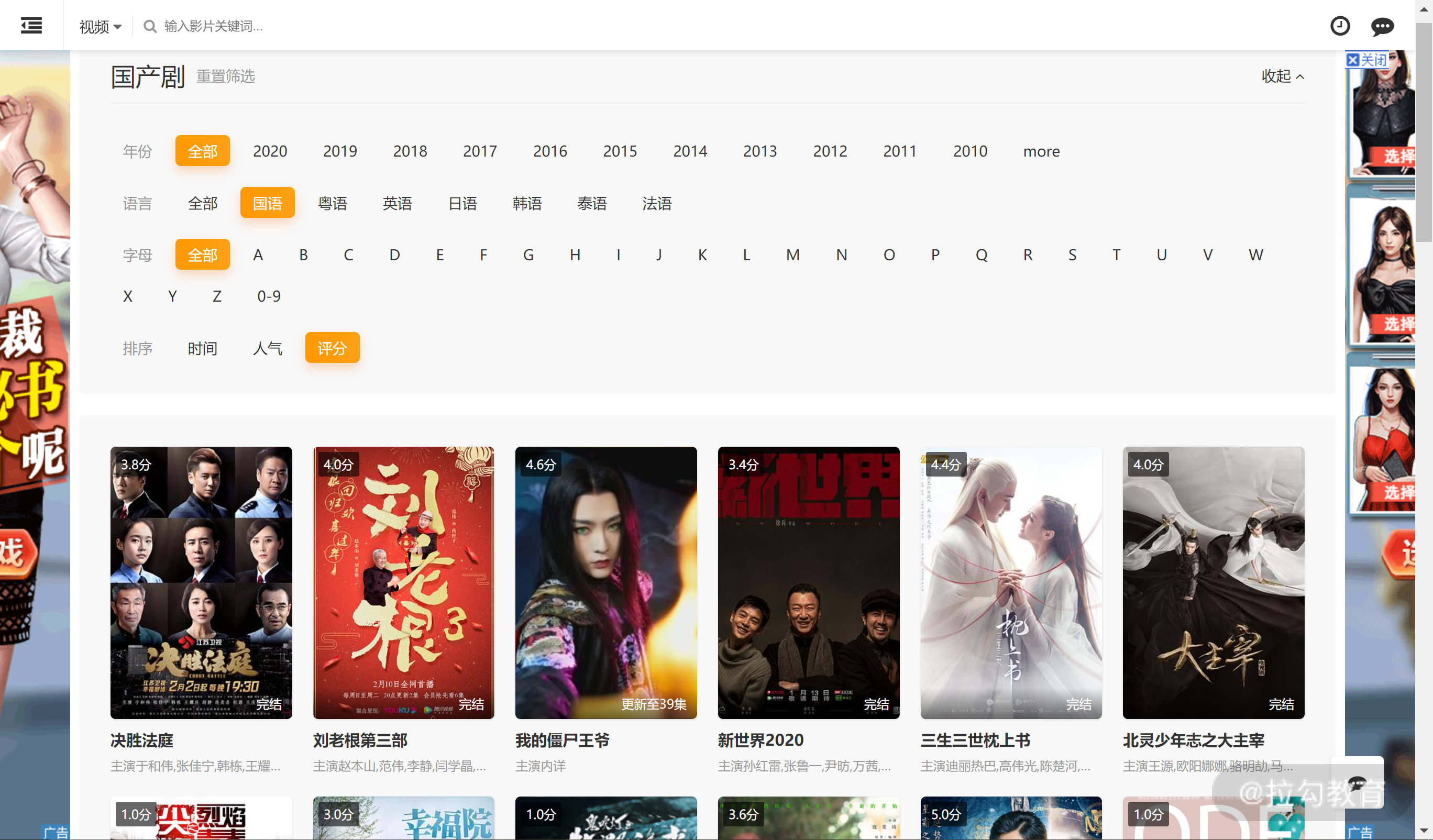
通过观察以上页面,可以发现该网页虽然弹窗广告比较多,但是我们想要的字段:标题、评分和主演信息在页面上都有显示,只要显示就说明我们可以通过爬虫拿到。
现在我们来考察它的加载方式,拉到底部,可以看到该网页提供的是传统的翻页操作。如下所示:
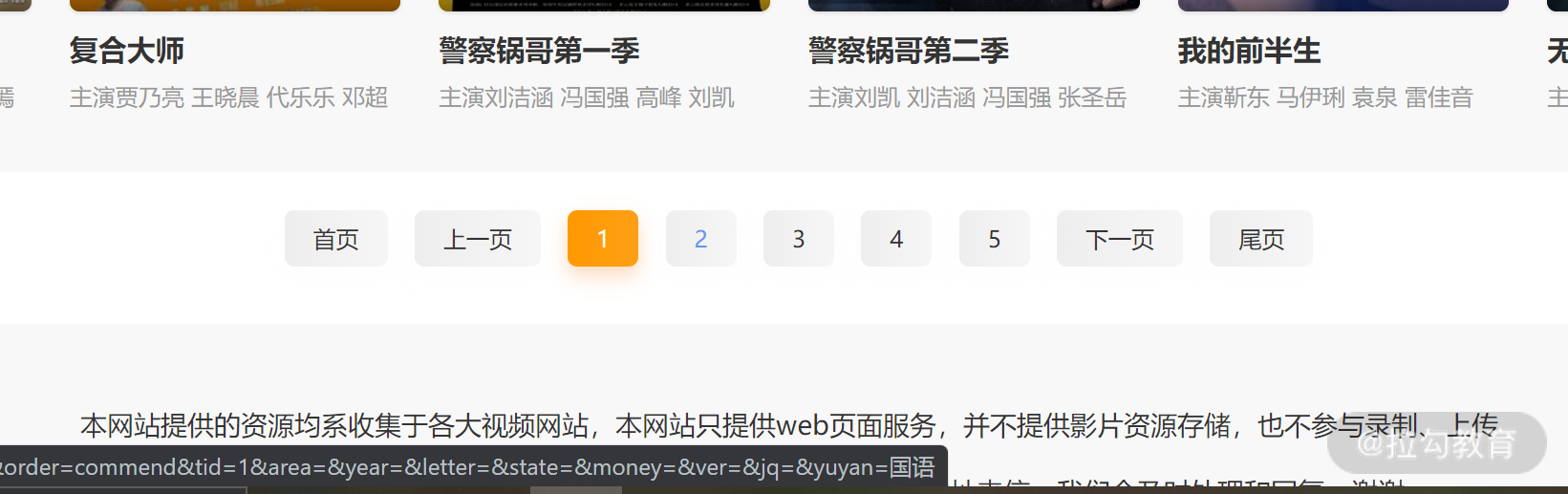
我们点击第二页,发现跳转到了一个新的页面,该页面的 URL 和我们一开始访问的差不多,只是其中有一个参数:page 的值变为了 2。
如下所示,我把有区分的地方加粗并加了下划线。
这说明我们可以通过不断改变 URL 中的 page 参数的值,来访问第二页之后的内容。这样在后续写代码中,我们只需要写针对一个页面的抓取代码,然后用一个循环来不断执行该方法,并每次叠加 page 的值就能实现将所有电视剧的内容抓取下来。
综上所述,电视剧网的页面更符合我们本次抓取的任务需求,我们后续就将该网页作为我们的抓取目标。
数据获取 — 下载所需要的网页
接下来就开始抓取电视剧网的网页,出于数据集总量的考虑。通过和具体负责分析的同事沟通,这次抓取我们只需要抓前 100 页的内容即可。
准备工作目录
首先,我们在你的课程目录中(也可以在桌面上)新建文件夹 chapter10 作为本次实战的主目录。之后打开 VS code, 选择文件 → 打开目录,选择 chapter10 这个目录并打开。
打开后,新建 Notebook 并保存为 chapter10.ipynb,我们本讲的代码将在这个 notebook 文件中书写。
因为我们这一次要下载的文件比较多(100 个 html),全部文件都放在同一个文件夹显然不是一个很好的选择,所以我们在 chapter10 中再建一个文件夹,用来保存下载的 HTML 文件。
由于我们已经打开了 VS code ,所以我们直接在 VS code 左边的文件夹视图区右键 → 新建文件夹,然后输入文件夹名为 htmls,如下图所示。

建立完后,我们 VS code 文件区是这个样子:有一个 notebook 文件,名为 chapter10 ,还有一个 htmls 的文件夹。
单个网页下载
在 07 讲中,我们讲到过,下载网页有两种方式,一种是使用 urllib3 直接下载,另一种是动态网页,需要使用 selenium 这样的模拟浏览器的技术下载。所以网页下载的第一步,我们需要首先判断我们希望下载的网页需要使用哪种方式。
我们首先测试是否可以直接使用 urllib3 直接下载电视剧网的网页,还记得我们在 07 讲中把 html 下载和保存到文件写成了两个函数:download_content 和 save_to_file, 这里我们直接拿来用即可。
打开 chapter10.ipynb,新建 Cell,将 07 讲的两个函数先搬过来。
import urllib3
# 第一个函数,用来下载网页,返回网页内容
# 参数 url 代表所要下载的网页网址。
# 整体代码和之前类似
def download_content(url):
http = urllib3.PoolManager()
response = http.request("GET", url)
response_data = response.data
html_content = response_data.decode()
return html_content
# 第二个函数,将字符串内容保存到文件中
# 第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量
def save_to_file(filename, content):
fo = open(filename,"w", encoding="utf-8")
fo.write(content)
fo.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
按 shift + enter 运行,这样我们之后就可以使用这两个函数来下载网页了。
现在我们来下载第一个电视剧,来测试 urllib3 的方案是否可以。
新建 Cell,输入以下代码:
# 将我们找到的电视剧网的网址存储在变量 url 中
url = "http://dianshiju.tv/search.php?page=1&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD"
# 将url 对应的网页下载下来,并把内容存储在 html_content 变量中
html_content = download_content(url)
# 将 html_content 变量中的内容存储在 htmls 文件夹中,文件名为 tv1.html 代表第一页
save_to_file("htmls/tv1.html", html_content)
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
下载网页的步骤大家都很熟悉了,这里就不过多解释了。
执行代码,之后可以看到 htmls 文件夹下多了 tv1.html,说明已经下载成功。
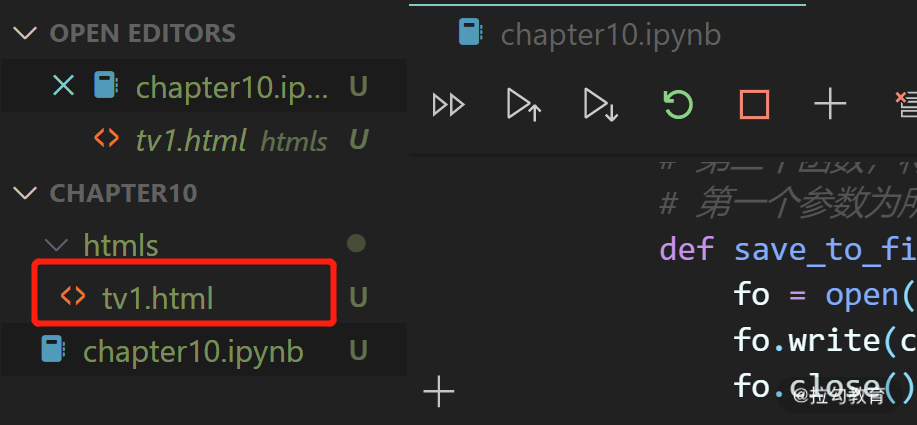
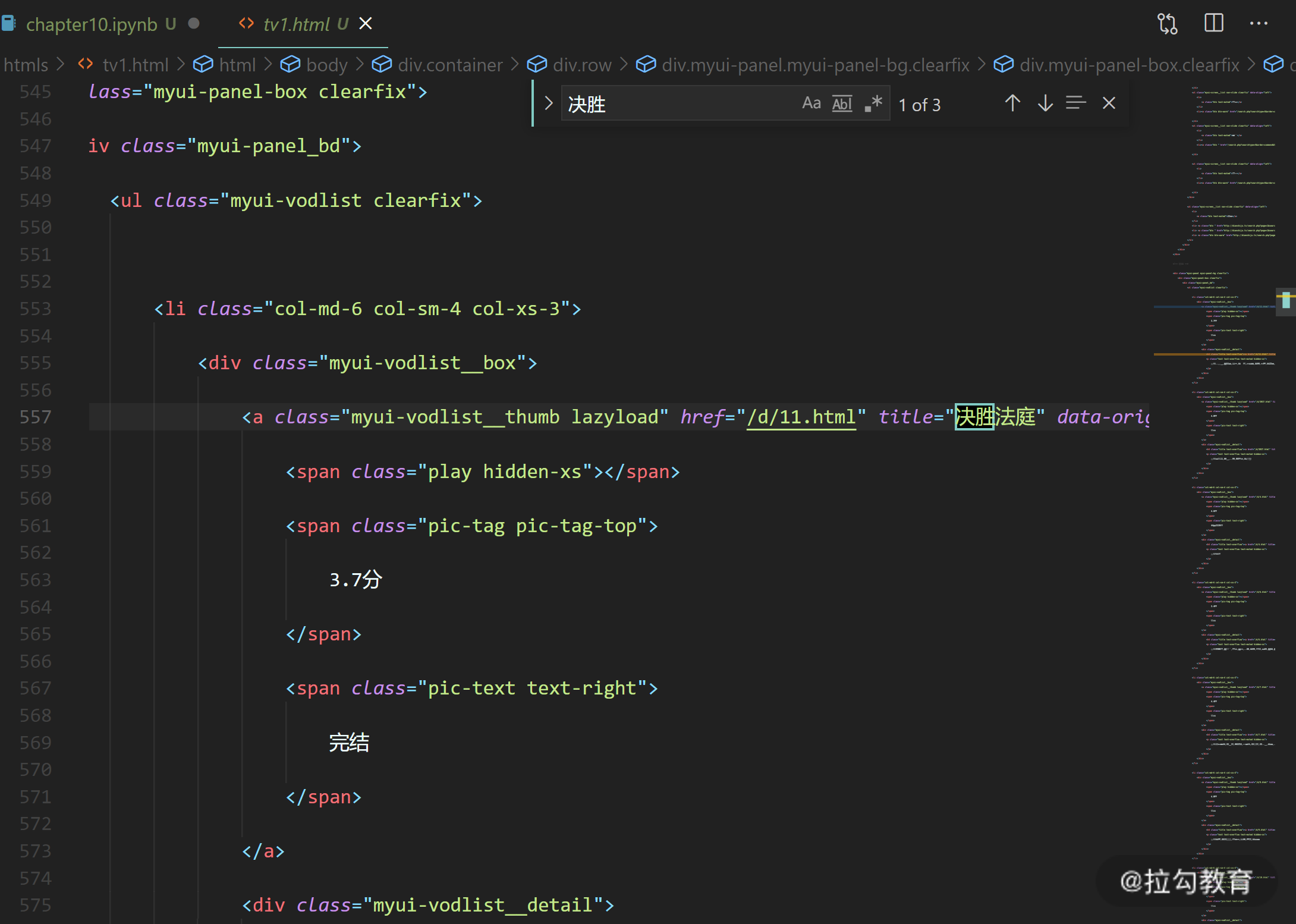
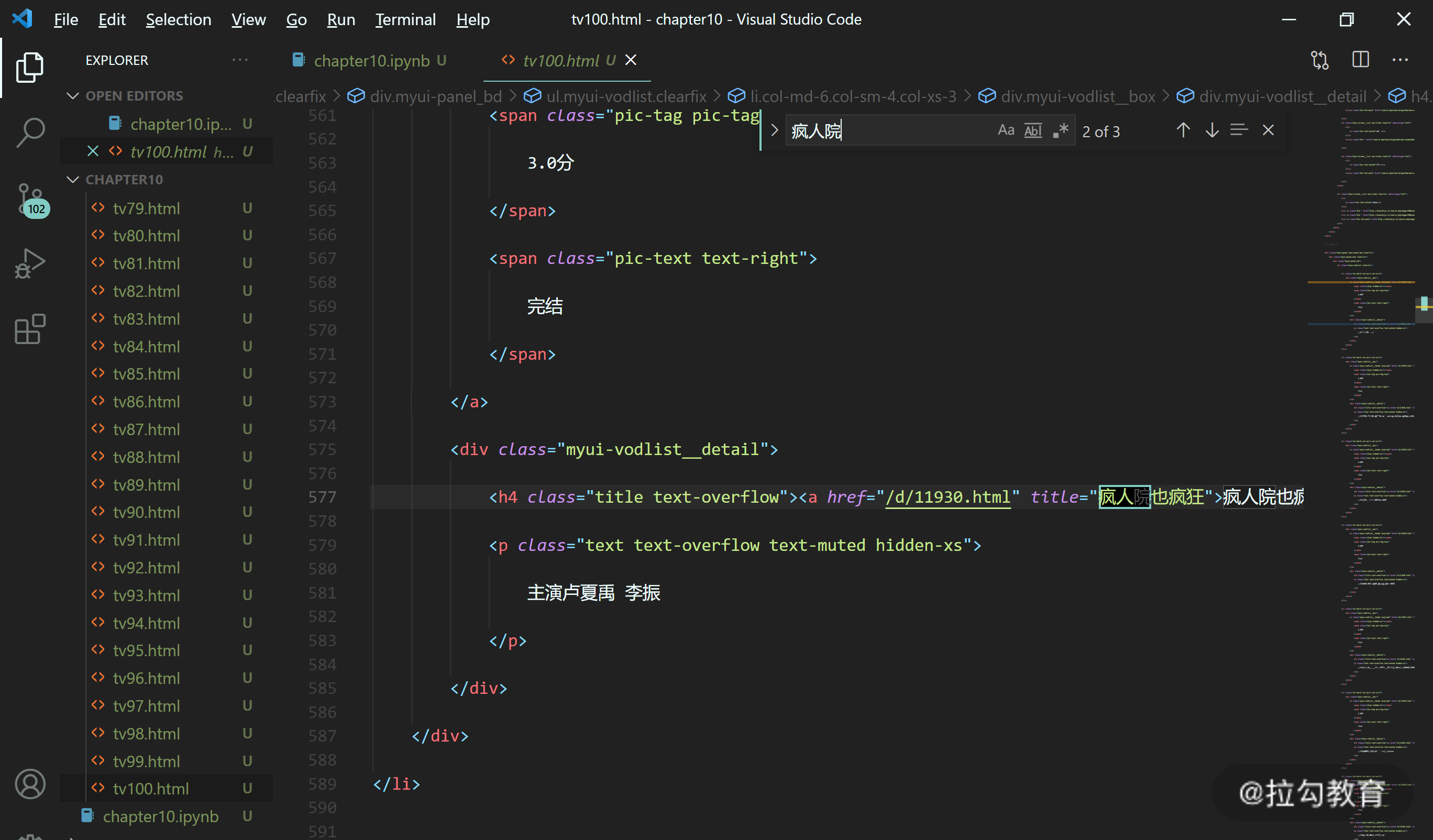
接下来,我们点击 tv1.html 打开,来查看是否有我们需要的电视剧信息。回过头去看我们上文中发的截图,第一个电视剧的名称是《决胜法庭》。
我们在 VS code 中搜索“决胜”,发现确实存在《决胜法庭》这个电视剧的信息。在下方还可以看到其评分:3.7。如下图所示。
说明电视剧网的内容不是动态生成的,可以用 urllib3 进行下载。
批量下载网页
现在第一个网页我们已经下载成功了。我们目标是下载 100 页的内容,所以剩余 99 页可以通过一个循环来下载。在我们之前的分析中,下载第二页和之后的内容只需要修改 URL 中的 page 的值即可。
另外,在我们通过循环来批量下载内容的时候,还有一个很重要的注意事项,一般都会在每次下载之后等待几百毫秒的时间,再进行下一次下载,这样可以避免短时间内对网站发起大量的下载请求,浪费网站的带宽资源。
在今天这个实战中,我们每次下载之后等待一秒再进行下一次下载。在 Python 中,我们可以通过 time 模块的 sleep 方法来使程序暂停固定的时间。
新建 Cell ,输入如下的代码:
import time
# 第一页已经下载完毕,循环下载第2页到第100页的内容
for i in range(2, 101):
# 每次循环,使用 replace 函数将 url 字符串中 page=1 的部分替换为 page + i,i为循环变量。
# 比如 i=3时,将page=1 替换为page=3,这样来下载第三页的内容
# 将替换后的url 存储在 a_url 变量中
a_url = url.replace("page=1", "page=" + str(i))
# 打印出即将下载的URL
print("begin download:", a_url)
# 下载当前页面的 url 的内容
html_content = download_content(a_url)
# 因为我们通过循环来下载,保存文件名也需要使用 i 来代表现在保存的是第几个网页。
# 比如 i = 3时,下载的是page=3的网页,最后则存储在 htmls/tv3.html
# 将本次循环要保存的文件名存储在 file_name 变量中
file_name = "htmls/tv" + str(i) + ".html"
# 将 html 文件的内容存储在 file_name 对应的文件夹里
save_to_file(file_name,html_content)
# 暂停一秒钟再继续下一次循环
time.sleep(1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
执行上述程序,可以看到程序每隔一秒钟输出一行信息,如下所示。大概执行 100 秒后,程序执行结束,部分日志如下所示。
begin download: http://dianshiju.tv/search.php?page=2&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD
begin download: http://dianshiju.tv/search.php?page=3&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD
begin download: http://dianshiju.tv/search.php?page=4&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD
begin download: http://dianshiju.tv/search.php?page=5&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD
begin download: http://dianshiju.tv/search.php?page=6&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD
begin download: http://dianshiju.tv/search.php?page=7&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD
begin download: http://dianshiju.tv/search.php?page=8&searchtype=5&order=commend&tid=1&area=&year=&letter=&state=&money=&ver=&jq=&yuyan=%E5%9B%BD%E8%AF%AD
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
执行完毕后,我们在侧边栏打开 htmls 文件夹,可以看到我们的 100 个 html 文件已经保存成功。
当然,不是下载出文件就算完了,我们还是需要查看一下这些 HTML 文件,看看是否包含我们预期的内容。比如以第 100 页为例。
我们将上文提到的 URL 中的 page 改为 100,在浏览器中访问,第 100 页的电视剧如下所示。
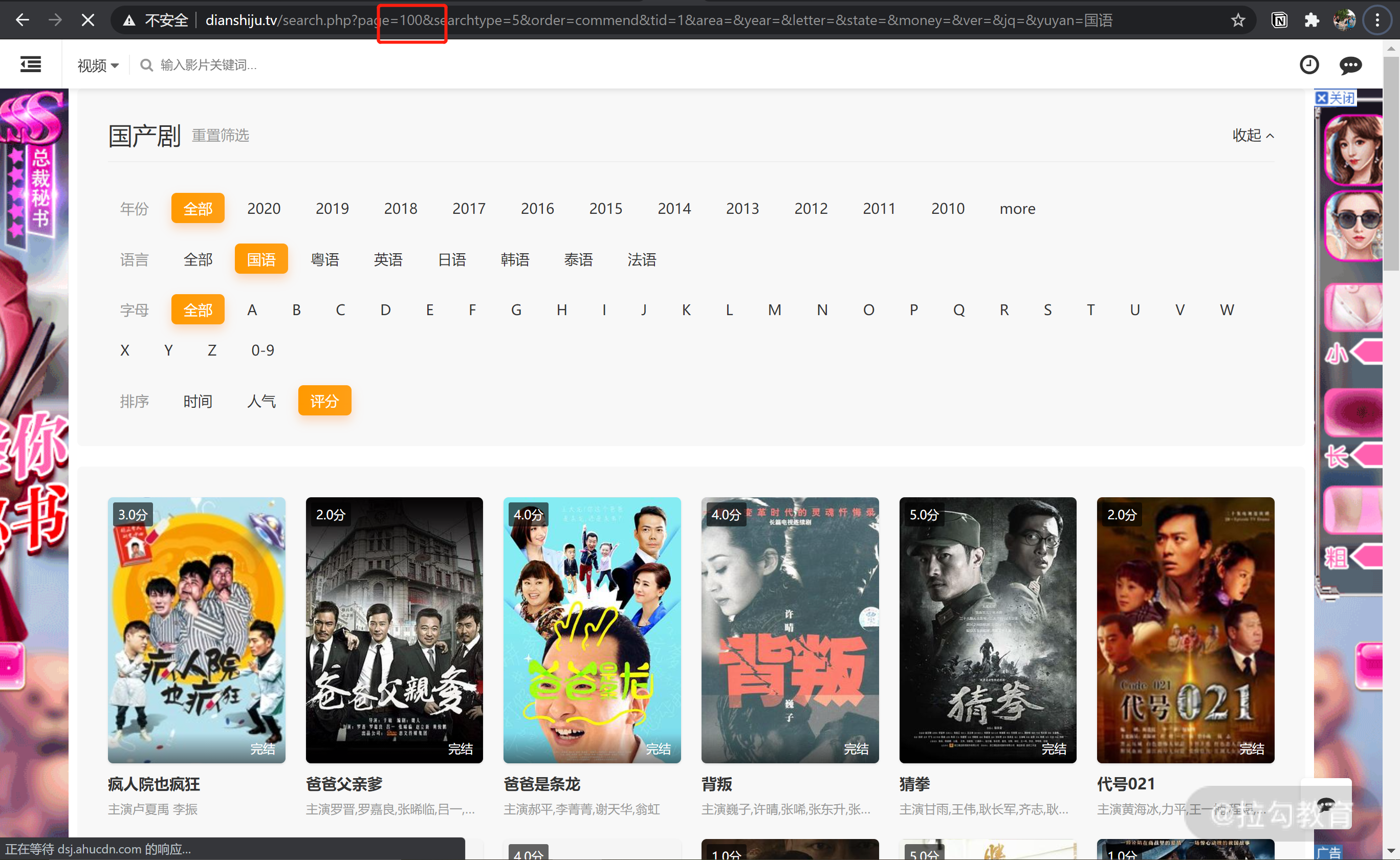
第一个电视剧名为《疯人院也疯狂》,之后我们打开我们下载到对应的 html 文件:tv100.html。搜索“疯人院”,发现可以搜索到内容(如下图所示),所以大概率我们下载的 html 都对应了电视剧网站中的每一页的内容。
至此,我们所需要的数据就都已经下载到本地了,接下来我们要做的就是编写代码去提取出我们想要的信息。
数据提取 — 过滤出我们需要的信息
初步分析
从之前学习的数据抓取一讲中我们学习到,要使用 BeautifulSoup 来提取数据,第一步首先应该分析我们想要的内容周围的标签结构,然后根据标签的层级关系来设计如何提取信息。
还是从第一页的 html 开始,打开 htmls/tv1.html ,搜索“决胜法庭”,定位到第一个电视剧的标签部分。可以看到在一个 class 为 myui-vodlist__box 的 div 标签内部,基本包含了我们想要拿的所有信息,如下图所示。
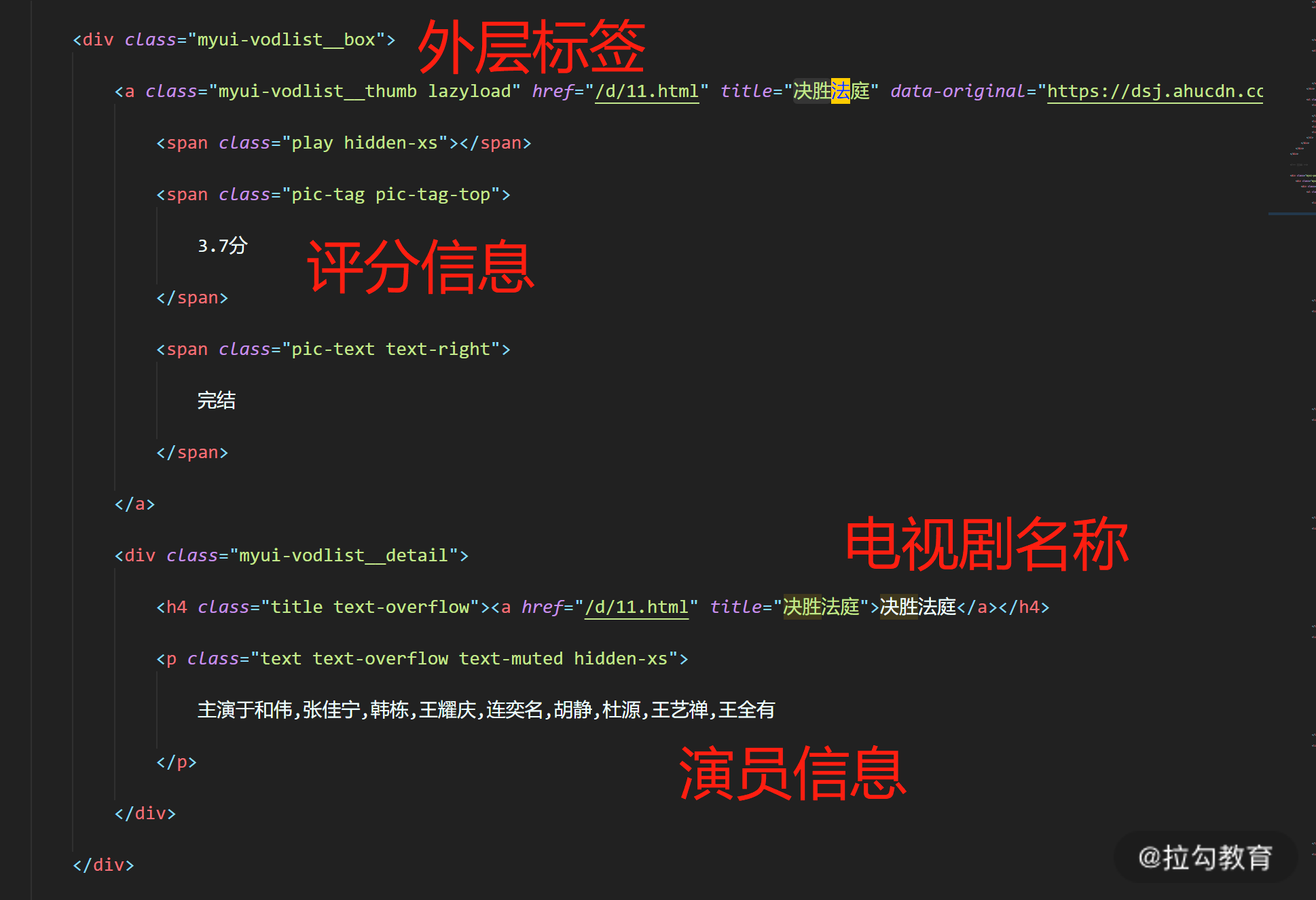
结合上图的分析,我们数据提取的思路大致是这样的。
-
获取所有 class=myui-vodlist__box 的 div 标签对象。
-
针对每一个标签对象,都尝试:
-
查找 h4 标签,并获得标签内的文本→电视剧名称;
-
查找 class = "pic-tag pic-tag-top" 的 span 标签,获得标签内文本→评分;
-
查找 p 标签,并获得标签内文本 → 演员信息。
-
因为在外层标签内部,h4 标签和 p 标签都只有一个,所以不需要更多的过滤条件。
提取单个 HTML 的所有电视剧信息
接下来,我们就开始编写从单个 html 文件抽取电视剧信息的代码,单个文件处理写完后扩展到多个就比较容易了。
此处我们要用到在第 9 讲整理的,直接从文件名创建 BeautifulSoup 对象的函数:create_doc_from_filename。
新建 Cell, 先将这个函数搬过来。
from bs4 import BeautifulSoup
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_filename(filename):
fo = open(filename, "r", encoding='utf-8')
html_content = fo.read()
fo.close()
doc = BeautifulSoup(html_content)
return doc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
之后根据初步分析中分析的步骤,实现内容的抓取。
新建 Cell,输入如下代码:
# 用 tv1.html 的内容创建 BeautifulSoup 对象
doc = create_doc_from_filename("htmls/tv1.html")
# 查找class="myui-vodlist__box" 的所有 div 标签
# 并以列表形式存储在 box_list 中
box_list = doc.find_all("div", class_="myui-vodlist__box")
# 使用遍历循环遍历 box_list 中的所有标签对象
for box in box_list:
# 根据上述分析的思路,分别获取包含标题、评分、和演员信息的标签
# 因为 find_all 总是返回列表,所以需要通过下标 0 来取第一个
title_label = box.find_all("h4")[0]
rating_label = box.find_all("span", class_="pic-tag pic-tag-top")[0]
stars_label = box.find_all("p")[0]
# 分别获取标签内部包含的文本,存储在 title, rating, stars 变量中
title = title_label.text
rating = rating_label.text
stars = stars_label.text
# 将获取的三个变量打印出来,看看是否正确。
print(title, rating, stars)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
执行之后,输出如下(截取了部分日志)。可以看到我们想要的信息是有了,但是却好像带了很多没必要的空格。
决胜法庭
3.7分
- 1
- 2
主演于和伟,张佳宁,韩栋,王耀庆,连奕名,胡静,杜源,王艺禅,王全有
- 1
- 1
- 1
- 2
刘老根第三部
4.0分
主演赵本山,范伟,李静,闫学晶,王小宝
- 1
我的僵尸王爷
4.6分
主演内详
- 1
新世界2020
3.4分
主演孙红雷,张鲁一,尹昉,万茜,李纯,胡静,秦汉,赵峥,张瑶,张晔子
- 1
有空格的原因是 html 页面中可能标签内部本来就有空格,但这好办,Python 的字符串有一个 strip 方法,可以去掉字符串前后的所有空格。
我们修改一下代码,如下所示。
# 用 tv1.html 的内容创建 BeautifulSoup 对象
doc = create_doc_from_filename("htmls/tv1.html")
# 查找class="myui-vodlist__box" 的所有 div 标签
# 并以列表形式存储在 box_list 中
box_list = doc.find_all("div", class_="myui-vodlist__box")
# 使用遍历循环遍历 box_list 中的所有标签对象
for box in box_list:
# 根据上述分析的思路,分别获取包含标题、评分、和演员信息的标签
# 因为 find_all 总是返回列表,所以需要通过下标 0 来取第一个
title_label = box.find_all("h4")[0]
rating_label = box.find_all("span", class_="pic-tag pic-tag-top")[0]
stars_label = box.find_all("p")[0]
# 分别获取标签内部包含的文本,存储在 title, rating, stars 变量中
# 【修改部分】并使用 strip 去除前后空格
title = title_label.text.strip()
rating = rating_label.text.strip()
stars = stars_label.text.strip()
# 将获取的三个变量打印出来,看看是否正确。
print(title, rating, stars)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
再次执行代码,部分输出如下,可以看到这一次的数据已经很接近我们想要的样子了。
决胜法庭 3.7分 主演于和伟,张佳宁,韩栋,王耀庆,连奕名,胡静,杜源,王艺禅,王全有
刘老根第三部 4.0分 主演赵本山,范伟,李静,闫学晶,王小宝
我的僵尸王爷 4.6分 主演内详
新世界2020 3.4分 主演孙红雷,张鲁一,尹昉,万茜,李纯,胡静,秦汉,赵峥,张瑶,张晔子
三生三世枕上书 4.4分 主演迪丽热巴,高伟光,陈楚河,郭品超,刘雨欣,刘芮麟,王骁,李东恒,袁雨萱,黄俊捷
北灵少年志之大主宰 4.0分 主演王源,欧阳娜娜,骆明劼,马月,徐浩,王奕婷
尖锋之烈焰青春 1.0分 主演宋轶,李佳航,牛骏峰,孙洪涛,万沛鑫,侍宣如,赵圆瑗,吴谨言,钱志,一真
幸福院之老有所安 3.0分 主演刘佩琦
鬼吹灯之牧野诡事 1.0分 主演王大陆 金晨 王栎鑫
秘果 3.6分 主演陈飞宇/欧阳娜娜
择天记 5.0分 主演鹿晗/娜扎/吴倩/曾舜晞
欢乐颂2 1.0分 主演刘涛/蒋欣/王子文/杨紫
关东大先生 4.0分 主演赵本山,范伟,小沈阳,刘流
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
提取多个 HTML 的内容
通过上述代码,我们已经可以将 tv1.html 文件中的所有电视剧信息给打印出来。但我们这次一共有一百个 html 文件,要怎么实现处理多个 html 文件呢?
因为这一百个 HTML 文件虽然电视剧内容不一样,但是标签结构却是基本一样的(在电视剧网翻页的时候,可以看到每一页的样子都是一样的)。所以我们只需要将上面的代码放在循环中循环运行,然后每次循环都处理不同的 html 文件即可。
为了让代码更加清晰,我们先将上面的处理单个文件的代码改写为函数,参数就是要处理的 html 文件名,函数则命名为:get_tv_from_html。
新建 Cell,输入如下代码。
# 从参数指定的 html 文件中获取电视剧的相关信息
def get_tv_from_html(html_file_name):
doc = create_doc_from_filename(html_file_name)
box_list = doc.find_all("div", class_="myui-vodlist__box")
for box in box_list:
title_label = box.find_all("h4")[0]
rating_label = box.find_all("span", class_="pic-tag pic-tag-top")[0]
stars_label = box.find_all("p")[0]
title = title_label.text.strip()
rating = rating_label.text.strip()
stars = stars_label.text.strip()
# 将获取的三个变量打印出来,看看是否正确。
print(title, rating, stars)
# 试试用新写的函数处理一 tv2.html
get_tv_from_html("htmls/tv2.html")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
输出节选如下。
醉玲珑 5.0分 主演 刘诗诗 陈伟霆 徐海乔 韩雪
河神 1.8分 主演李现 张铭恩 王紫璇CiCi 陈芋米
少林问道 4.0分 主演 周一围 郭京飞 郭晓婷 是安
鬼吹灯之黄皮子坟 3.0分 主演阮经天 徐璐 郝好 刘潮 尚铁龙
槑头槑脑第二季 3.0分 主演宋晓峰 霍云龙 程野
槑头槑脑 2.0分 主演宋晓峰 霍云龙 唐艺兮 程野 唐娜
学生兵 2.0分 主演张铎 孙艺宁 张光北 孙绍龙
绝密543 3.6分 主演王聪 陈维涵 顾宇峰 王超
深海利剑 3.0分 主演王强 高旻睿 刘璐 王阳
浪花一朵朵 5.0分 主演谭松韵 熊梓淇 黄圣池 张峻宁
镇魂街[真人版] 2.0分 主演 汪东城 安悦溪 侯明昊
黑土热血 1.0分 主演于毅,刘威葳,张芷溪,王劲松,曹克难,谭皓,侯煜,袁苑,齐千郡,山鹰,王今心
建军大业电视剧 4.0分 主演黄海冰,郭广平,周惠林,李飞
颤抖吧,阿部 5.0分 主演郑业成 安悦溪 王燕阳
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
可以看到,我们成功用我们写的函数来从 tv2.html 中提取了电视剧的信息。这样要实现从一百个文件中抽取信息,只需要写一个循环,来每次传给 get_tv_from_html 函数不同的文件名即可。
但现在还有一个问题,我们现在处理 html 之后,只是把我们要的信息打印了出来,打印在屏幕上显然是不满足做数据集的要求的。
接下来,我们就来将所有信息保存为 csv 文件。
数据保存 — 将我们的数据保存为 csv
回忆一下我们在第 09 讲学习的内容,要将数据保存为 csv 的记录,我们首先需要将每一行数据保存为字典,然后以一个字典列表的形式传递给 csv 模块的 DictWriter。
(1)准备保存到 csv 的函数
为了让后续代码更简洁,我们先将把字典列表保存到 csv 文件的操作写成一个函数。
新建 Cell,输入如下代码:
# 导入 csv 模块
import csv
# 输入有三个参数:要保存的字典列表,csv 文件名,和表头
def write_dict_list_to_csv(dict_list, filename, headers):
# 当要处理的网页比较复杂时,增加 encoding 参数可以兼容部分特殊符号
fo = open(filename, "w", newline='', encoding='utf_8_sig')
writer = csv.DictWriter(fo, headers)
writer.writeheader()
writer.writerows(dict_list)
fo.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
实现的代码在第 09 讲也讲过,这里不再赘述。
(2)创建保存所有电视剧字典的列表
我们需要一个列表来保存所有 html 文件中获取的电视剧信息。
新建Cell, 输入如下代码并运行。
all_tv_dict = []
- 1
- 1
(3)改造 get_tv_from_html 函数
我们在数据提取章节的末尾,实现了 get_tv_from_html 函数,可以方便地处理多个文件,但是当时只是把拿到了信息打印了出来。现在我们需要进行改造,不打印电视剧名、评分和演员信息,而是存储为字典。一个电视剧一个字典,而一个 html 文件中包含多个电视剧,所以 get_tv_from_html 最后会返回一个字典列表。
回到 get_tv_from_html 的 cell,修改代码为如下所示,其中有修改的部分都标注了【新增】。
# 从参数指定的 html 文件中获取电视剧的相关信息
def get_tv_from_html(html_file_name):
doc = create_doc_from_filename(html_file_name)
box_list = doc.find_all("div", class_="myui-vodlist__box")
# 【新增】当前处理的文件的字典列表
tv_list = []
for box in box_list:
title_label = box.find_all("h4")[0]
rating_label = box.find_all("span", class_="pic-tag pic-tag-top")[0]
stars_label = box.find_all("p")[0]
title = title_label.text.strip()
rating = rating_label.text.strip()
stars = stars_label.text.strip()
# 【新增】使用字典来保存,字典的 key 和 csv 的表头保持一致
# 【新增】在任务说明环节,表头为: title, rating, stars
tv_dict = {}
tv_dict["title"] = title
tv_dict["rating"] = rating
tv_dict["stars"] = stars
# 【新增】将电视剧的字典添加到当前文件的字典列表中
tv_list.append(tv_dict)
# 【新增】返回字典列表
return tv_list
# 【新增】用最新修改的 get_tv_from_html 处理 tv2.html,并将返回的结果存储在 tv_list 变量中
tv_list = get_tv_from_html("htmls/tv2.html")
# 【新增】打印获取到的列表
print(tv_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
运行代码,输出节选如下所示。
可以看到,这一次在 get_tv_from_html 中没有再进行输出,而是返回了字典列表。我们把字典列表打印了出来,其中的内容也就是我们想要的电视剧的信息。
[{'title': '醉玲珑', 'rating': '5.0分', 'stars': '主演 刘诗诗 陈伟霆 徐海乔 韩雪'}, {'title': '河神', 'rating': '1.8分', 'stars': '主演李现 张铭恩 王紫璇CiCi 陈芋米'}, {'title': '少林问道', 'rating': '4.0分', 'stars': '主演 周一围 郭京飞 郭晓婷 是安'}, {'title': '鬼吹灯之黄皮子坟', 'rating': '3.0分', 'stars': '主演阮经天 徐璐 郝好 刘潮 尚铁龙'}, {'title': '槑头槑脑第二季', 'rating': '3.0分', 'stars': '主演宋晓峰 霍云龙 程野'}, {'title': '槑头槑脑', 'rating': '2.0分', 'stars': '主演宋晓峰 霍云龙 唐艺兮 程野 唐娜'}, {'title': '学生兵', 'rating': '2.0分', 'stars': '主演张铎 孙艺宁 张光北 孙绍龙'}, {'title': '绝密543', 'rating': '3.6分', 'stars': '主演王聪 陈维涵 顾宇峰 王超'}, {'title': '深海利剑', 'rating': '3.0分', 'stars': '主演王强 高旻睿 刘璐 王阳'}, {'title': '浪花一朵朵',
- 1
- 1
(4)获取所有文件的电视剧信息
目前,我们通过 get_tv_from_file 函数,已经可以获取单个 html 的电视剧列表,现在我们需要通过一个循环,去处理所有的 html。对于每一个 html 文件,获取字典列表之后,都把列表添加到我们的总列表:all_tv_dict 中。这样,在循环执行结束后,all_tv_dict 变量中就包含了所有电视剧的信息。
现在我们就来实现上面说的逻辑,新建 Cell,输入以下代码。
# 因为是处理 tv1- tv100 的文件,所以i 循环从1到101
for i in range(1, 101):
# 拼出每一次要处理的文件名
file_name = "htmls/tv" + str(i) + ".html"
# 调用 get_tv_from_html 处理当次循环的文件
# 将这个文件中的电视剧列表存储在 dict_list 变量
dict_list = get_tv_from_html(file_name)
# 将 dict_list 的内容添加到总列表 all_tv_dict 中
# 列表的拼接可以直接使用 + 号
all_tv_dict = all_tv_dict + dict_list
# 打印出总列表的长度,看看我们一共抓取到了几部电视剧
print(len(all_tv_dict))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
按 shift+enter 执行,因为要用 BeautifulSoup 处理一百个文件,这里执行会有点慢。需要耐心等一下,执行完毕后输出结果为 3600。
3600
- 1
- 1
这说明我们一共抓取到了3600 部电视剧的信息。
(5)保存结果到 csv 文件中
在任务说明中,已经明确了要保存的 csv 文件名为:tv_rating.csv, 表头为:title, rating, stars。
现在,我们所有电视剧的信息都已经存储在 all_tv_dict 总列表中,现在我们只需要调用存储到 csv 的函数将其保存到 csv 文件即可。
# 调用之前准备的 write_dict_list_to_csv 函数
# 第一个参数为要保存的列表,这里就是我们存储了所有电视剧耳朵总列表 all_tv_dict
# 第二个参数为要保存的文件名
# 第三个参数为要保存的 csv 文件的表头
write_dict_list_to_csv(all_tv_dict, "tv_rating.csv", ["title", "rating", "stars"])
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
执行之后,没有内容输出,但是可以看到在 chapter10 文件夹下已经生成了 tv_rating.csv 文件。
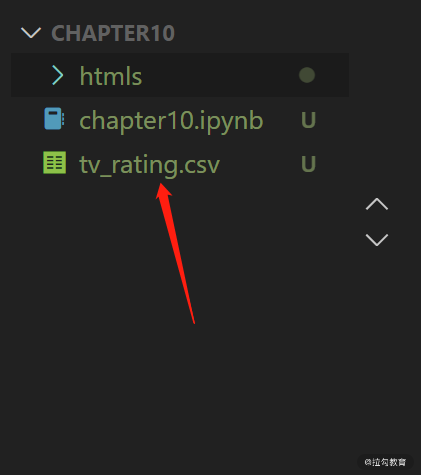
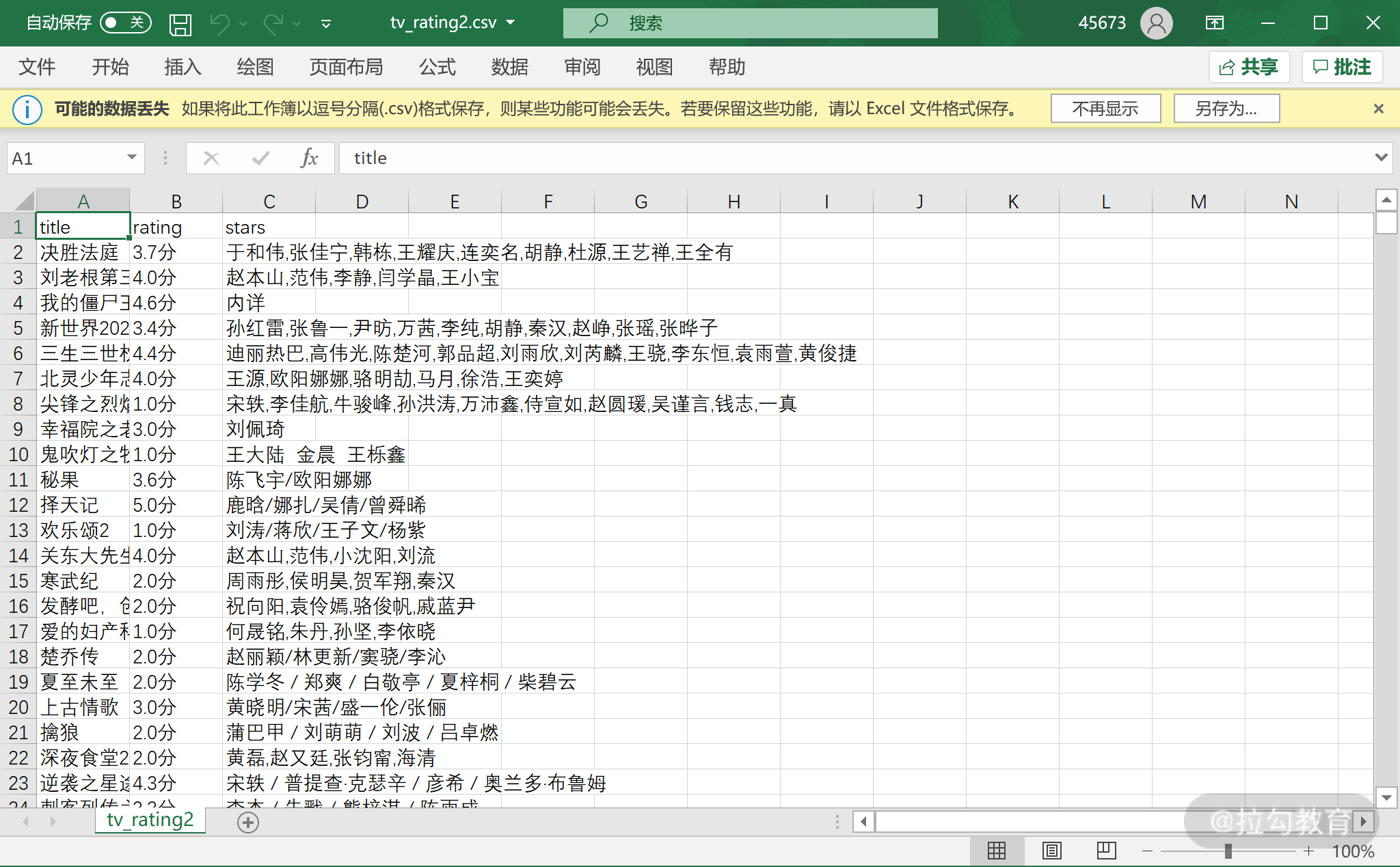
使用 Excel 打开该 csv 文件,可以看到我们的表头已经正确写入,表头对应的内容也已经正确写入。
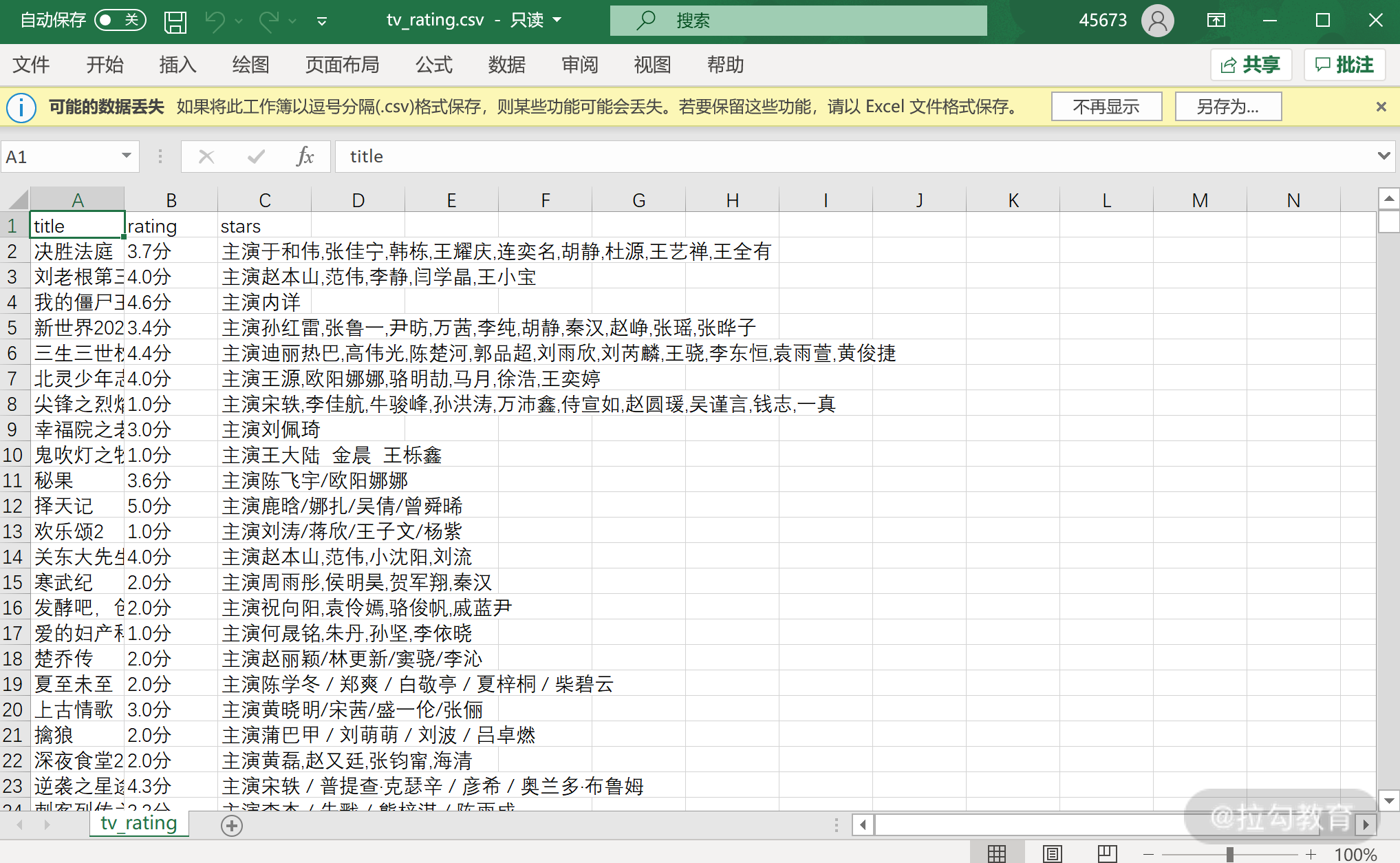
拉倒底部,可以看到最后一行记录是 3061,因为第一行是表头,所以我们最终保存了 3600 条电视剧的信息,这和之前我们列表的长度也对得上。
至此,一份国产电视剧评分的数据集就制作完毕了。
将数据集交给了数据分析部门的同事之后,大家都对你能够这么快就搞定这个任务感觉到刮目相看,Mentor 也露出了欣慰的笑容,想着是时候交给你更重要的任务了!
小结
总结一下本讲的内容,今天这个实战基本上用到了这一模块我们学习的所有知识,主要包括:
-
根据数据集的要求选择所要抓取的网页;
-
实现单个页面抓取;
-
实现多个页面的抓取;
-
实现页面内容的提取;
-
将提取到的内容转化成字典列表,并保存到 csv 文件。
到现在,我们数据获取部分的内容就学习完毕了。下一模块,我们将学习 Python 数据分析最广泛使用的框架:pandas。
课后习题
在刚才的 csv 中,演员一栏的内容都包含了“主演”两个字,是比较冗余的。请你编写代码,读取 tv_rating.csv 的内容,然后把每行记录的演员信息中的“主演”两个字删除,删完后新的内容保存至 tv_rating2.csv。
答案:
解题思路类似上一讲,我们先读取所有字典列表,通过一个循环遍历列表,对于每一个字典,通过 stars 这个key拿到演员信息,删除主演两个字后再存储回 stars 这个 key 对应的值中。
# 整理读取 CSV 的代码为函数
# 输入参数为 CSV 文件名,返回值为读取到的字典列表
def get_dict_list_from_csv(filename):
fo = open(filename, "r", encoding="utf_8_sig")
reader = csv.DictReader(fo)
dict_list = []
for item in reader:
dict_list.append(item)
return dict_list
# 读取 tv_rating.csv 文件,并将返回的字典列表赋值给 tv_list1 变量
tv_list1 = get_dict_list_from_csv("tv_rating.csv")
# 遍历循环 tv_list1
for item in tv_list1:
# 针对每个字典,将 stars 对应的value 的“主演” 替换为空,也就是删除主演两个字
# 并将结果存回 item 字典
item["stars"] = item["stars"].replace("主演","")
# 将修改之后的列表重新写到 tv_rating2.csv 中
write_dict_list_to_csv(tv_list1, "tv_rating2.csv", ["title", "rating", "stars"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
运行之后,可以看到生成了 tv_rating2.csv 打开后如下所示,可以看到“主演”二字都已经删除了。