
- 1LeetCode哈希表篇【两数之和】_两数之和 力扣题目链接 (opens new window) 给定一个整数数组 nums 和一个目
- 2SpringBoot面试题 44道
- 318款顶级开源与商业流分析平台推荐与详解
- 4数据挖掘复习笔记-3.数据预处理实例_labormissing.txt
- 5k8s资源监控_bitnami metrics-server v0(1),2024一位Linux运维中级程序员的跳槽面经
- 6大数据复习(第五六章)_大数据lp
- 7手把手教你使用 IDEA 连接 kingbase 人大金仓数据库(2024最新)_idea database连接kingbase8
- 8Matlab|基于蒙特卡洛的风电功率/光伏功率场景生成方法
- 9算法刷题题单
- 10机器学习保险行业问答开放数据集: 2. 使用案例_商业保险个性化推荐数据集
如何在自定义数据集上训练 YOLOv9
赞
踩
作者:James Gallagher
编译:东岸因为@一点人工一点智能
2024 年 2 月 21 日,Chien-Yao Wang、I-Hau Yeh 和 Hong-Yuan Mark Liao 发布了“YOLOv9:Learning What You Want to Learn Using Programmable Gradient Information”论文,介绍了一种新的计算机视觉模型架构:YOLOv9。目前,源代码已开源,允许所有人训练自己的 YOLOv9 模型。
据项目研究团队称,在使用 MS COCO 数据集进行基准测试时,YOLOv9 实现了比现有流行的 YOLO 模型(如 YOLOv8、YOLOv7 和 YOLOv5)更高的 mAP。
在本文中,我们将展示如何在自定义数据集上训练 YOLOv9 模型。我们将通过一个训练视觉模型来识别球场上的足球运动员。话虽如此,您可以使用在本文中使用所需的任何数据集。

YOLOv9简介
YOLOv9 是由 Chien-Yao Wang、I-Hau Yeh 和 Hong-Yuan Mark Liao 开发的计算机视觉模型。Hong-Yuan Mark Liao 和 Chien-Yao Wang 还参与了 YOLOv4、YOLOOR 和 YOLOv7 等模型架构的开发。YOLOv9 引入了两个新的架构:YOLOv9 和 GELAN,这两个架构都在随论文一起发布的yolov9 Python 存储库中。
使用 YOLOv9 模型,您可以训练对象检测模型。目前不支持分段、分类和其他任务类型。
YOLOv9 有四种型号,按参数计数排序:
-
v9-S
-
v9-M型
-
v9-C
-
v9-E系列
在撰写本文时,v9-S 和 v9-M 的权重尚不可用。
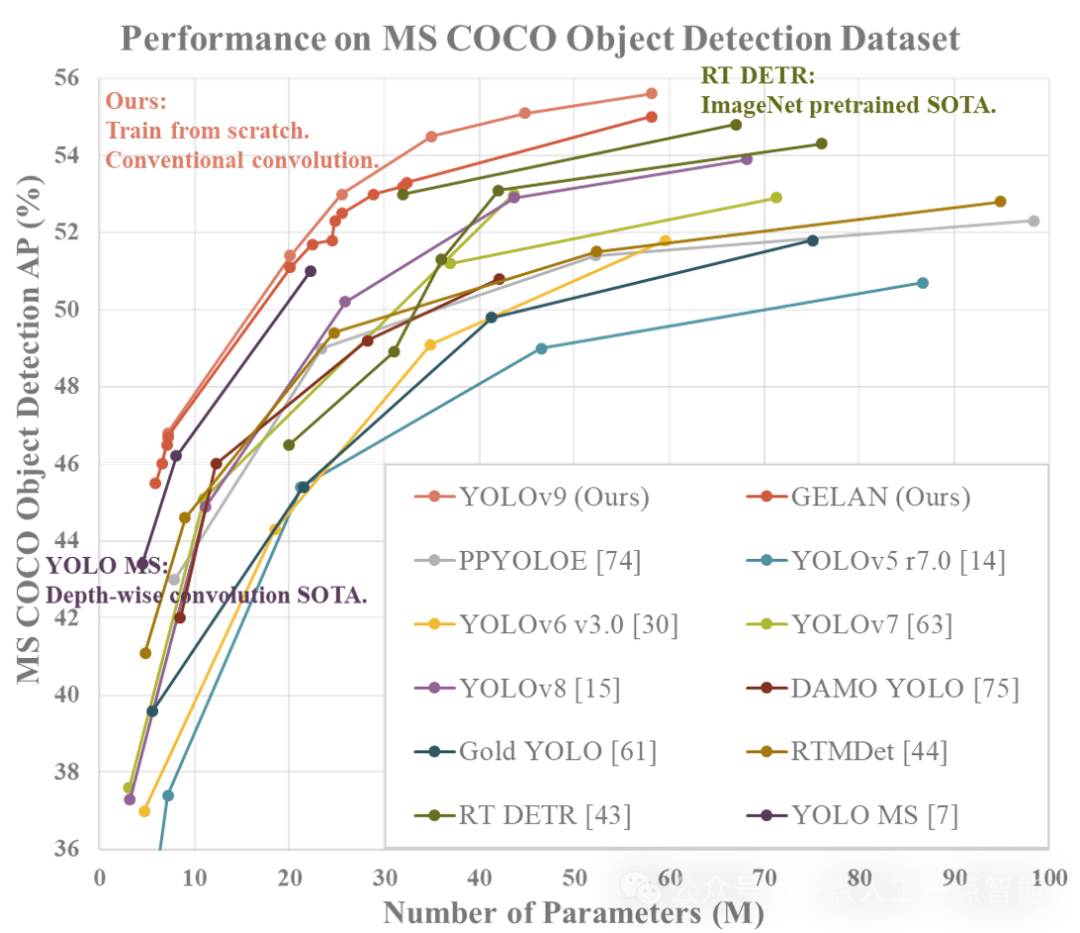
最小的模型在MS COCO数据集的验证集上实现了46.8%的AP,而最大的模型实现了55.6%。这为物体检测性能奠定了新的技术水平。下图显示了YOLOv9研究团队的研究结果。

如何安装YOLOv9
YOLOv9被打包为一系列可以使用的脚本。在编写本文时,还没有官方的Python包或安装包可以用来与模型交互。
要使用YOLOv9,您需要下载项目存储库。然后,您可以从现有的COCO检查点运行训练作业或推理。
本文假设您在Google Colab中工作。如果您在笔记本环境之外的本地机器上工作,请根据需要调整命令。
YOLOv9中有一个错误,它阻止您在映像上运行推理,但Roboflow团队正在维护一个带有补丁的非官方分叉,直到修复程序发布。要从已修补的fork安装YOLOv9,请运行以下命令:
- git clone https://github.com/SkalskiP/yolov9.git
- cd yolov9
- pip3 install -r requirements.txt -q
让我们设置一个HOME目录:
- import os
- HOME = os.getcwd()
- print(HOME)
接下来,您需要下载模型权重。目前只有v9-C和v9-E权重可用。您可以使用以下命令下载它们:
- !mkdir -p {HOME}/weights
- !wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
- !wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt
- !wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt
- !wget -P {HOME}/weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt
现在,您可以使用项目存储库中的脚本对YOLOv9模型进行推理和训练。

YOLOv9模型的运行推理
让我们在一个示例图像上使用v9-C COCO检查点来运行推理。创建一个新的数据目录,并将示例图像下载到笔记本中。您可以使用我们的狗狗图像作为示例,也可以使用您想要的任何其他图像。
- !mkdir -p {HOME}/data
- !wget -P {HOME}/data -q https://media.roboflow.com/notebooks/examples/dog.jpeg
- SOURCE_IMAGE_PATH = f"{HOME}/dog.jpeg"
我们现在可以对我们的图像进行推断:
!python detect.py --weights {HOME}/weights/gelan-c.pt --conf 0.1 --source {HOME}/data/dog.jpeg --device 0Image(filename=f"{HOME}/yolov9/runs/detect/exp/dog.jpeg", width=600)模型结果:

我们的模型能够成功地识别图像中的人、狗和车。话虽如此,但该模型将一条带子误认为手提包,未能检测到背包。
让我们试试参数最多的v9-E模型:
!python detect.py --weights {HOME}/weights/yolov9-e.pt --conf 0.1 --source {HOME}/data/dog.jpeg --device 0Image(filename=f"{HOME}/yolov9/runs/detect/exp2/dog.jpeg", width=600)模型结果:

该模型能够成功识别人、狗、车和背包。

如何训练一个YOLOv9模型
您可以使用YOLOv9项目目录中的train.py文件来训练YOLOv9模型。
步骤#1:下载数据集
要开始训练模型,您需要一个数据集。在本文中,我们将使用足球运动员的数据集。由此产生的模型将能够识别球场上的足球运动员。
如果你没有数据集,请查看Roboflow Universe,这是一个公开共享了20多万个计算机视觉数据集的社区。你可以找到涵盖从书脊到足球运动员再到太阳能电池板的所有数据集。
运行以下代码下载我们将在本文中使用的数据集:
- %cd {HOME}/yolov9
-
- roboflow.login()
-
- rf = roboflow.Roboflow()
-
- project = rf.workspace("roboflow-jvuqo").project("football-players-detection-3zvbc")
- dataset = project.version(1).download("yolov7")
当您运行此代码时,将要求您使用Roboflow进行身份验证。按照终端中显示的链接进行身份验证。如果您没有帐户,您将被带到一个可以创建帐户的页面。然后,再次单击链接以使用Python包进行身份验证。
此代码下载YOLOv7格式的数据集,该数据集与YOLOv9模型兼容。
您可以将任何以YOLOv7格式格式化的数据集与本指南一起使用。
步骤#2:使用YOLOv9Python脚本来训练模型
让我们在数据集上训练20个epochs的模型。我们将使用GELAN-C架构来实现这一点,这是作为YOLOv9 GitHub存储库的一部分发布的两个架构之一。GELAN-C训练速度快。GELAN-C推理时间也很快。
您可以使用以下代码执行此操作:
- %cd {HOME}/yolov9
-
- !python train.py \
- --batch 16 --epochs 20 --img 640 --device 0 --min-items 0 --close-mosaic 15 \
- --data {dataset.location}/data.yaml \
- --weights {HOME}/weights/gelan-c.pt \
- --cfg models/detect/gelan-c.yaml \
- --hyp hyp.scratch-high.yaml
你的模型将开始训练。随着模型的训练,您将看到每个epoch的训练指标。
一旦您的模型完成了训练,您就可以借助YOLOv9生成的图形来评估训练结果。
运行以下代码以查看您的训练图:
Image(filename=f"{HOME}/yolov9/runs/train/exp/results.png", width=1000)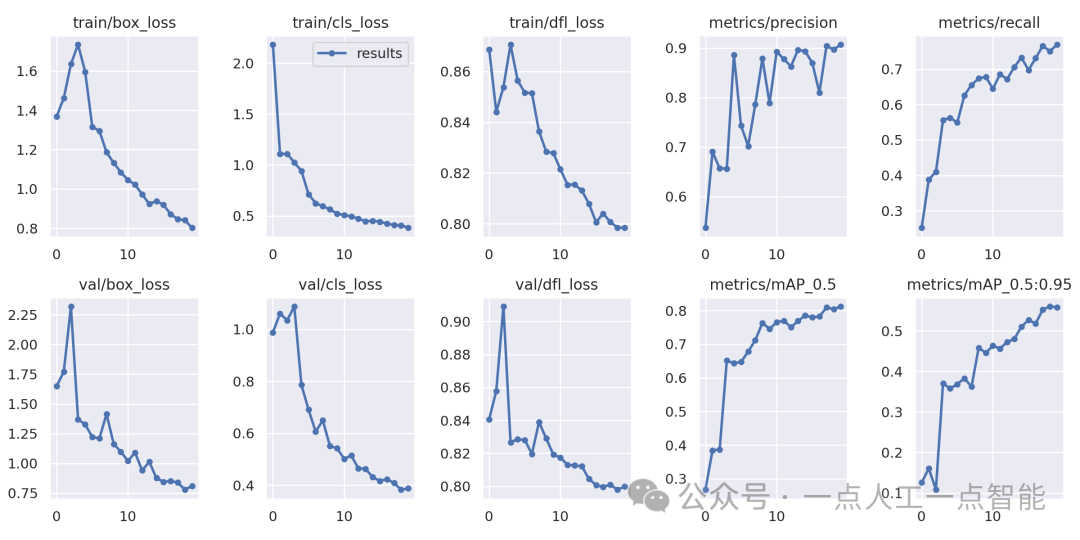
运行以下代码以查看您的混淆矩阵(confusion matrix):
Image(filename=f"{HOME}/yolov9/runs/train/exp/confusion_matrix.png", width=1000)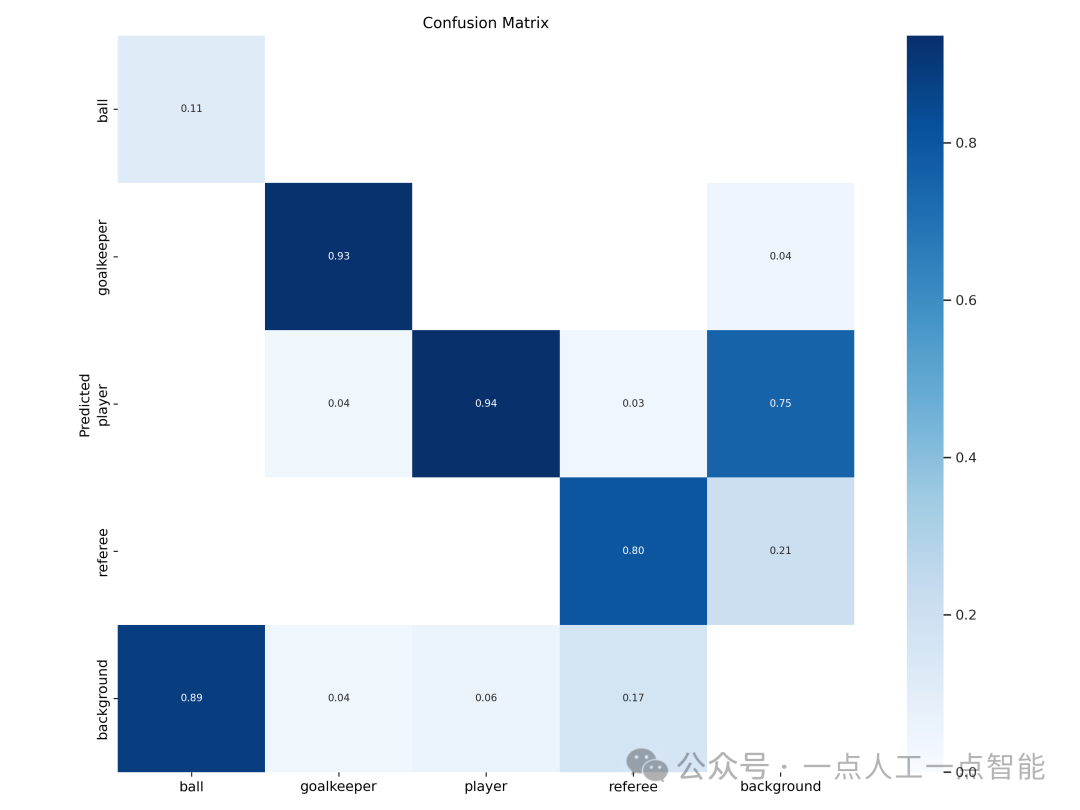
运行以下代码集中查看验证一批图像的模型结果:
Image(filename=f"{HOME}/yolov9/runs/train/exp/val_batch0_pred.jpg", width=1000)
步骤#3:在自定义模型上运行推理
既然我们有了一个经过训练的模型,我们就可以进行推理了。为此,我们可以使用YOLOv9存储库中的detect.py文件。
运行以下代码以对验证集中的所有图像运行推理:
- !python detect.py \
- --img 1280 --conf 0.1 --device 0 \
- --weights {HOME}/yolov9/runs/train/exp/weights/best.pt \
- --source {dataset.location}/valid/images
-
- import glob
- from IPython.display import Image, display
-
- for image_path in glob.glob(f'{HOME}/yolov9/runs/detect/exp4/*.jpg')[:3]:
- display(Image(filename=image_path, width=600))
- print("\n")
我们在640大小的图像上训练了我们的模型,这使我们能够用较少的计算资源训练模型。在推理过程中,我们将图像大小增加到1280,使我们能够从模型中获得更准确的结果。
以下是我们模型的三个结果示例:

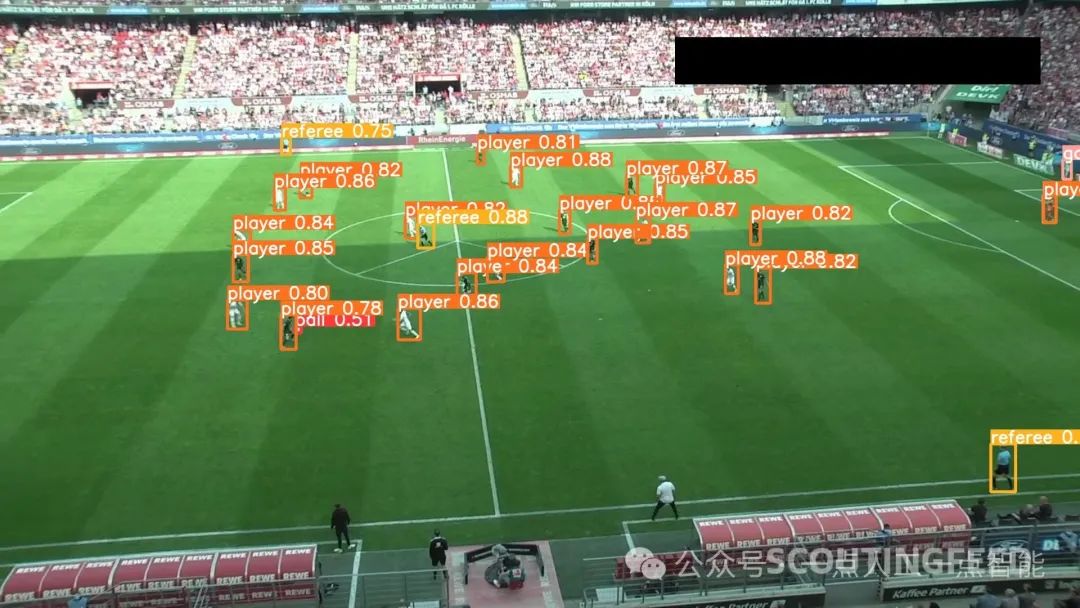
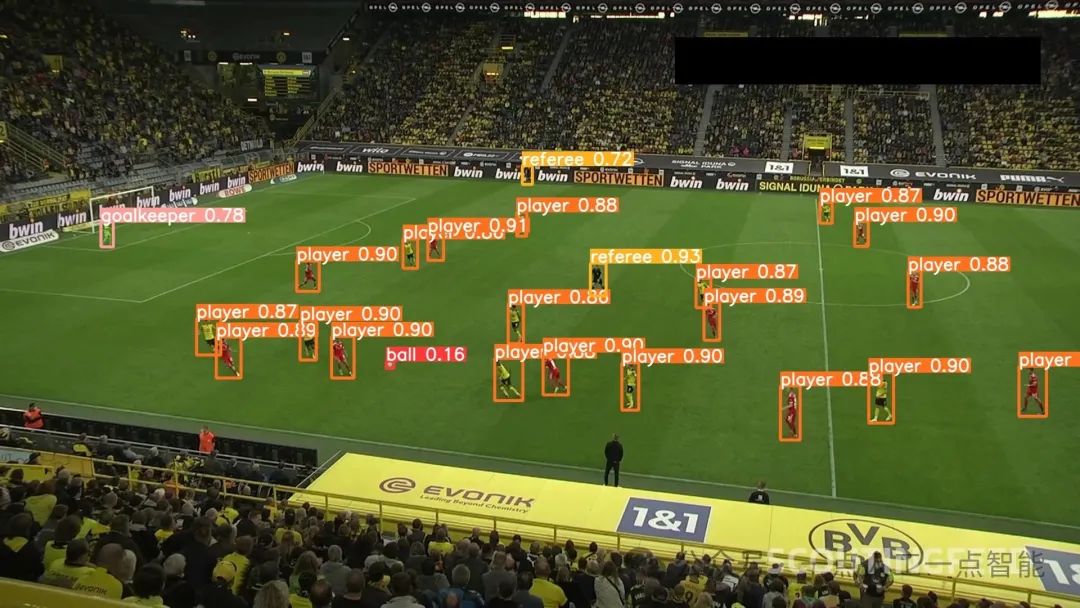
我们的模型成功地识别了球员、裁判和守门员。

如何部署YOLOv9模型
使用经过训练的YOLOv9模型,在将模型投入正式使用之前还有一项任务:模型部署。
您可以使用Roboflow Inference(一个开源的计算机视觉推理服务器)来完成这项任务。使用Roboflow Inference,您可以使用Python SDK在应用程序逻辑中引用模型,或者在Docker容器中运行模型,该容器可以作为微服务进行部署。在本文中,我们将展示如何使用推理Python SDK部署您的模型。
在开始的时候,您需要将您的模型权重上传到Roboflow。这将使云API可用于您的模型,并允许您将权重带入本地推理部署。你需要在你的Roboflow账户中有一个项目,以便上传你的权重。
在您的Roboflow帐户中创建一个新项目,然后上传您的数据集。单击侧边栏中的“生成”以生成数据集版本。准备好数据集版本后,您可以上传模型权重。
要上传模型权重,请运行以下代码:
- from roboflow import Roboflow
-
- rf = Roboflow(api_key='YOUR_API_KEY')
- project = rf.workspace('WORKSPACE').project('PROJECT')
-
- version = project.version(1)
- version.deploy(model_type="yolov9", model_path=f"{HOME}/yolov9/runs/train/exp")
上面,设置您的Roboflow工作区ID、模型ID和API密钥。
· 查找您的工作空间和型号ID
· 查找您的API密钥
一旦你运行了上面的代码,你的权重将在你的Roboflow帐户中可用,用于你的本地推理部署。
要将您的模型部署到您的设备,请首先安装推理和监督:
pip install inference supervision然后,您可以使用以下代码来运行您的模型:
- from inference import get_model
-
- model = get_model(model_id="model-id/version", api_key="API_KEY")
-
- image_paths = sv.list_files_with_extensions(
- directory=f"{dataset.location}/valid/images",
- extensions=['png', 'jpg', 'jpeg']
- )
- image_path = random.choice(image_paths)
- image = cv2.imread(image_path)
-
- result = model.infer(image, confidence=0.1)[0]
- detections = sv.Detections.from_inference(result)
-
- label_annotator = sv.LabelAnnotator(text_color=sv.Color.BLACK)
- bounding_box_annotator = sv.BoundingBoxAnnotator()
-
- annotated_image = image.copy()
- annotated_image = bounding_box_annotator.annotate(scene=annotated_image, detections=detections)
- annotated_image = label_annotator.annotate(scene=annotated_image, detections=detections)
-
- sv.plot_image(annotated_image)

上面,设置您的Roboflow模型ID和API密钥。
· 查找您的型号ID
· 查找您的API密钥
在上面的代码中,我们在数据集中的一个随机图像上运行我们的模型。以下是输出示例:valid
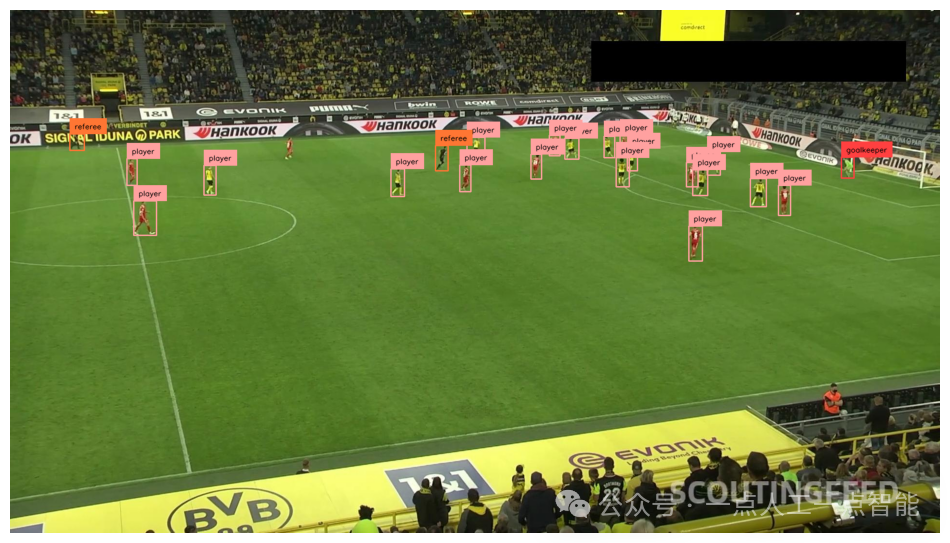
我们已经成功地在我们自己的硬件上使用推理部署了我们的模型。
要了解有关使用推理部署模型的更多信息,请参阅推理文档。
(https://inference.roboflow.com/?ref=blog.roboflow.com)

结论
YOLOv9是一个新的计算机视觉模型体系结构,由Chien-Yao Wang, I-Hau Yeh和Hong-Yuan Mark Liao共同发布。您可以使用YOLOv9体系结构来训练对象检测模型。
在本文中,我们演示了如何在自定义数据集上运行推理和训练YOLOv9模型。我们克隆了YOLOv9项目代码,下载了模型权重,然后使用默认的COCO权重进行推理。然后,我们使用足球运动员检测数据集训练了一个微调模型。我们回顾了训练图和混淆矩阵,然后在验证集的图像上测试了模型。
参考链接:https://blog.roboflow.com/train-yolov9-model/

