
热门标签
热门文章
- 1深入了解AI大模型在语音识别领域的挑战
- 2EncryptUtil加密解密工具类,实测可以,复制粘贴皆可。全套代码加使用案例方法。
- 3为了避免内存攻击,美国国家安全局提倡Rust、C#、Go、Java、Ruby 和 Swift,但将 C 和 C++ 置于一边...
- 4redux的基础学习使用
- 5pytorch,torchvision与python版本对应关系_torch1.10.1对应的torchvision
- 6JavaScript基础(一)_js根据条件显示
- 7多种方式实现Android页面布局的切换_安卓 切换布局文件
- 8主题模型LDA教程:主题数选取 困惑度perplexing_lda困惑度
- 9自然语言处理之准确率、召回率、F1理解_nlp f1
- 10机器学习的入门教学-scikit-learn_scikit-learn教程
当前位置: article > 正文
数据挖掘复习笔记-3.数据预处理实例_labormissing.txt
作者:花生_TL007 | 2024-04-10 04:37:20
赞
踩
labormissing.txt
最近在复习数据挖掘和数据库,复习的内容就放在这里方便以后自己看,其他那些没有代码的我就仅自己可见了,这些有代码的会放出来,所以可能会发现我的编号并不连续。
注:本文数据是本科期间上课做实验的时候用的(感谢我最爱的邵老师)
代码是在老师提供的指导手册基础上改的
1.对数据进行归一化处理
Q: 为什么要做normalisation?
normalization可以使不同的列都处于同一大小,因此做回归以后各列的系数之间可以相互比较,否则有些列的数据过大,可能会导致该列系数较小,但不能就此认为该列对结果的影响小。
首先把txt里除了数据的其他东西(对文件的描述)全部删掉,得到这样的内容:
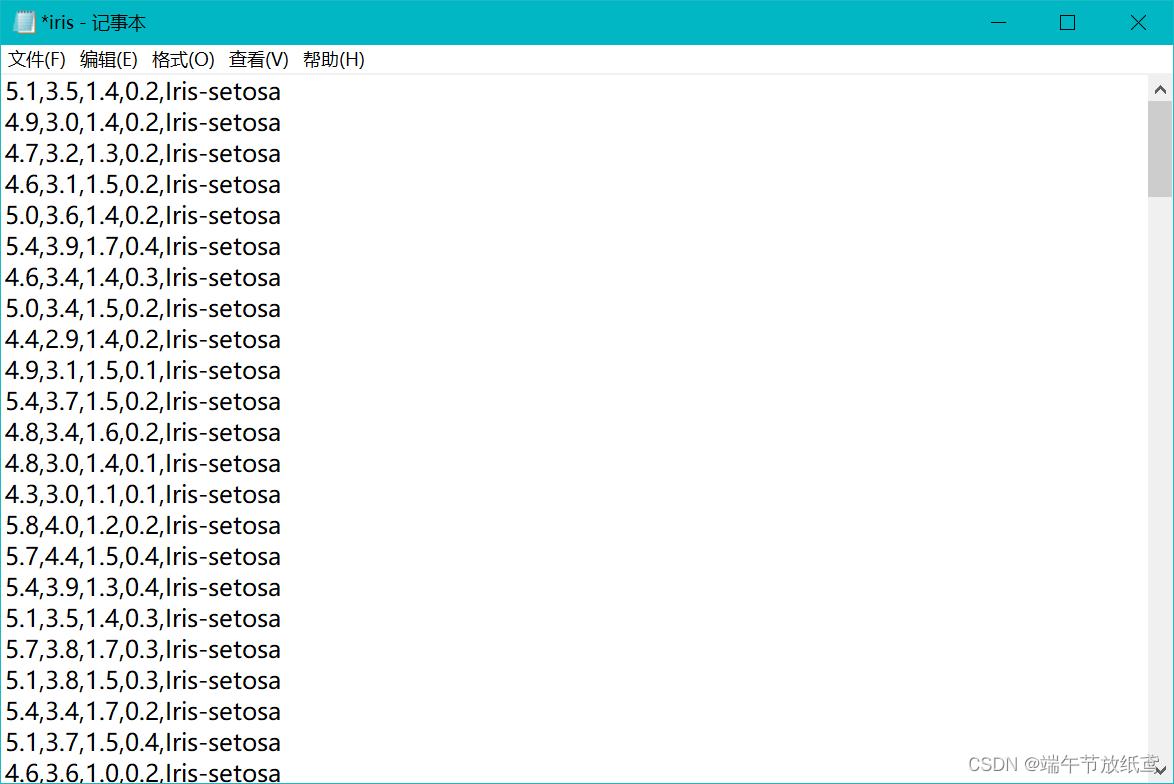
import numpy as np import pandas as pd def loadIris(address): spf=pd.read_csv(address,sep=',',index_col=False,header=None) strs=spf[4]#第五列spf[4]存储的是字符串 spf.drop([4],axis=1,inplace=True)#去掉字符串的列 return spf.values,strs#返回数值内容和字符串内容 def normalization(data_matrix): e=1e-5 for c in range(4):#4是列数,对每一列做处理 maxNum=np.max(data_matrix[:,c])#第c列的最大值 minNum=np.min(data_matrix[:,c])#第c列的最小值 data_matrix[:,c]=(data_matrix[:,c]-minNum+e)/(maxNum-minNum+e)#为了防止最大值等于最小值,这里加一个很小的数字e #这里是将数值规范到[0,1]区间,可以通过乘和加规范到其他区间,不过[0,1]区间比较常见。 return data_matrix if __name__=='__main__': filepath='iris.txt' writepath='iris_normal.txt' data_matrix,str_name=loadIris(filepath)#读数据 data_matrix=normalization(data_matrix)#normalizaiton spf=pd.DataFrame(data_matrix) strs=str_name.values#字符串内容(因为字符串没办法做normalization,只能提前取出来) spf.insert(4,4,strs)#将字符串内容加入spf中 spf.to_csv(writepath,index=False,header=False)#存储normalization后的数据

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
然后就会得到:
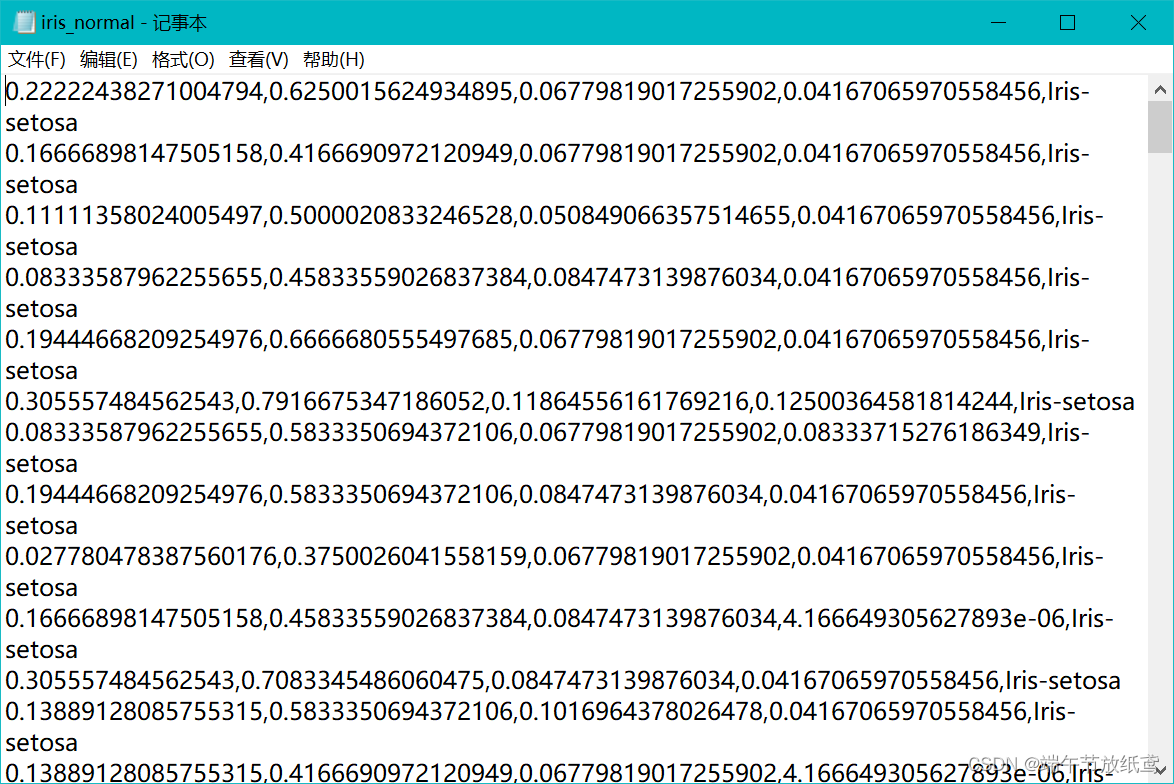
2.缺失值填充
本实验需要读取txt文件内存储的数据,当然,如果是.CSV文件更好,表格里的会更好操作,这里放一张图看看txt的数据。
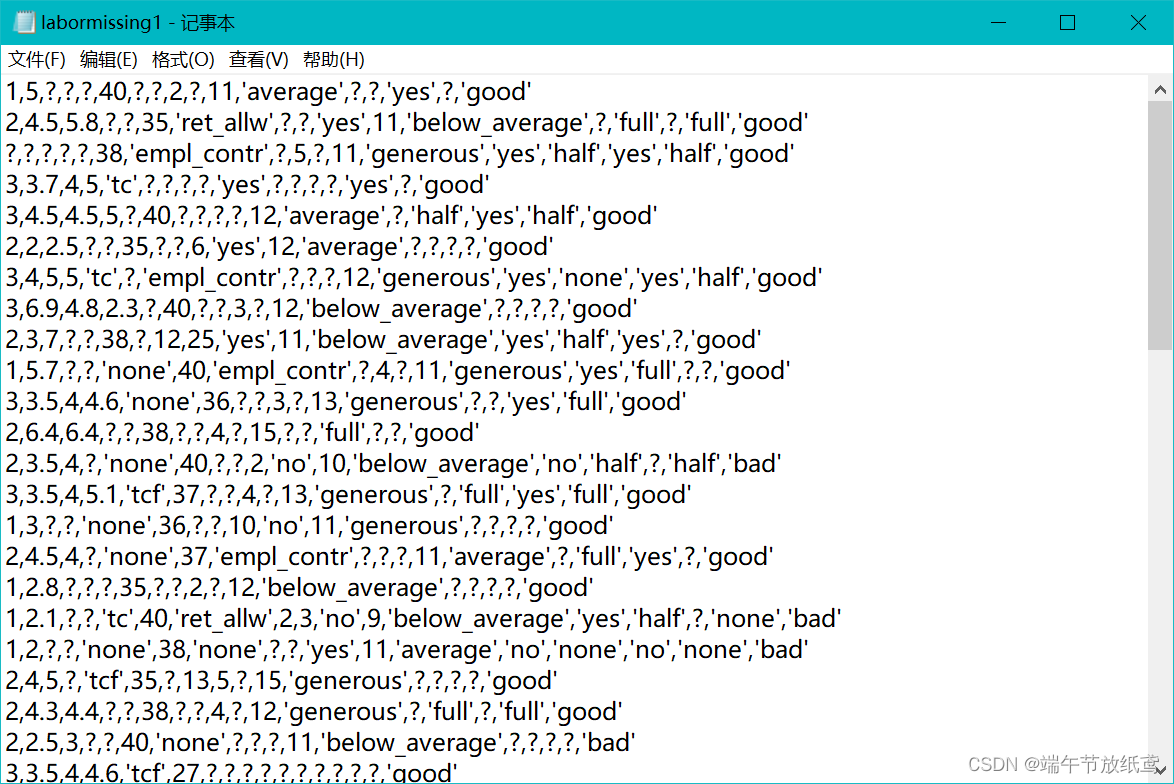
缺失值处理代码如下:
import pandas as pd import numpy as np from collections import Counter #这里是导入数据 def loadLabor(address): spf = pd.read_csv(address, sep=',',index_col=False, header=None)#数据中心不存在行名和列名所以是False和None column = ['duration', 'wage-increase-first-year', 'wage-increase-second-year','wage-increase-third-year', 'cost-of-living-adjustment','working hours','pension','standby-pay', 'shift-differential','education-allowance','statutory-holidays','vacation', 'longterm-disability-assistance','contribution-to-dental-plan','bereavement-assistance', 'contribution-to-health-plan','class']#手动命名每一列的名称,对于txt中存了列名的就不需要这一步了。 spf.columns = column str_typeName = ['cost-of-living-adjustment','pension','education-allowance', 'vacation','longterm-disability-assistance','contribution-to-dental-plan', 'bereavement-assistance','contribution-to-health-plan','class']#这是手动选出这些数据中以字符串形式存储的列 #这里建议不知道列名的时候给每一列取一个简单的名字,比如abcd这样的,这样方便选取字符串的列 str2numeric = {} str2numeric['?'] = '-1' spf = spf.replace(str2numeric)#将spf中所有的'?'转换为'-1'(用-1临时填充) #spf.to_csv('xxx.csv')#这里可以输出看看我们读到的数据变成什么样了 return spf, str_typeName #填补缺失值的函数 def fillMissData(spf, str_typeName): row, col = spf.shape columns = spf.columns for column_name in columns:#遍历spf中的每一列 if column_name not in str_typeName:#如果该列不是存的str型数据 tmp = spf[column_name].apply(float)#变成浮点型存储在tmp中 ave = np.average(tmp[tmp != -1])#取该列不是-1的项的平均值 tmp[tmp == -1] = ave#用平均值替代tmp中的-1 spf[column_name] = tmp#使用tmp替换spf中的该列 #数值型用均值替换 else:#如果该列存的是str数据 v = spf[column_name].values#将该列数据存在v中 v1 = v[v != '-1']#找到v中不是-1的项存在v1中 c = Counter(v1)#对v1中的不同取值进行计数存在c中 cc = c.most_common(1)#找到c中计数最大的项 v[v == '-1'] = cc[0][0]#将v中-1的项替换为最常见的项 #字符型用众数替换 spf[column_name] = v return spf if __name__=='__main__': filepath = 'labormissing1.txt' fillFilepath = 'laborMissing_handle.txt' spf, str_typeName = loadLabor(filepath)#读取文件 spf = fillMissData(spf,str_typeName)#缺失值填补 spf.to_csv(fillFilepath, index=False,header=False)#存储处理后的文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
处理过后得到一个这样的txt文档。
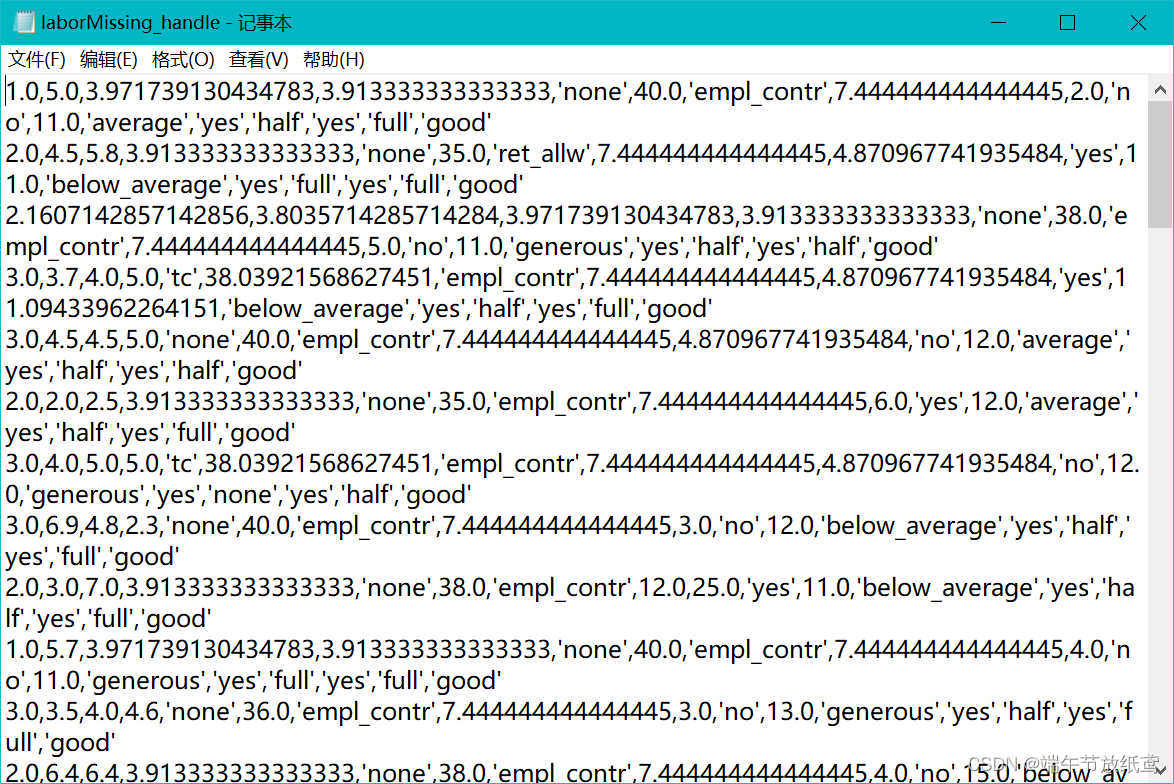
3.特征筛选
信息增益率的计算
本次所用数据同归一化处理的数据相同
import numpy as np import pandas as pd from collections import Counter def loadIris(address): spf = pd.read_csv(address, sep=',', index_col=False, header=None)#读取数据 strs = spf[4]#字符串的列 spf.drop([4], axis=1, inplace=True)#去掉字符串 return spf.values, strs#返回数值项和字符项 def getEnergy(c, data, label):#计算条件信息熵 #其中c里存的是data中不同取值的数量 dataLen = len(label) energy = 0.0 for key, value in c.items()#遍历条件的不同取值 #其中key是data中存在的某一取值,value是该取值出现的次数 c[key] /= float(dataLen) #将value改变为出现的比率 label_picked = label[np.where(data == key)] #选出data为key时对应的那些label的取值 l = Counter(label_picked)#对选出的label的不同取值计数 e = 0.0 for k, v in l.items():#遍历当data取值为key时label的数据 r = v/float(value) #value是data取key的次数,这里计算在确定data为key时label为v的几率 e -= r*np.log2(r)#信息熵公式 #遍历完data取值为key时label的不同取值得到一部分条件信息熵 energy += c[key]*e#将data取不同值时的条件信息熵相加得到label在data下的条件信息熵 return energy#返回条件信息熵 def featureSelection(features, label):#这里的输入是数值型和字符项 featureLen = len(features[0,:])#数值项的列数 label_count = Counter(label)#计算不同label取值的数量 samples_energy = 0.0 data_len = len(label)#数据的行数 for i in label_count.keys():#遍历label的不同取值 label_count[i] /= float(data_len) samples_energy -= label_count[i]*np.log2(label_count[i])#信息熵:直接得知label所需的信息 informationGain = [] for f in range(featureLen):#遍历数值项不同的列 af = features[:,f]#列f的数据 minf = np.min(af) maxf = np.max(af) +1e-4 width = (maxf-minf)/10.0 d = (af-minf) / width#normalization到[0,10] dd = np.floor(d)#向下取整,将列f的数据变为0-9的整数 c = Counter(dd)#对变化后的列f不同取值进行计数 sub_energy = getEnergy(c, dd, label)#条件信息熵:在确定f的基础上得知label所需的信息 informationGain.append(samples_energy - sub_energy)#将f带来的信息增益补充仅informationGain里 return informationGain if __name__ == '__main__': filepath = 'iris.txt' data_matrix, str_name = loadIris(filepath) informationGain = featureSelection(data_matrix, str_name.values) print(informationGain)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
得到如下输出
[0.7299038051886471, 0.43049145713504644, 1.3510281744340518, 1.427355764201518]
可以看出第二列数据带来的信息增益最少,因此当需要剔除数据时,可以优先考虑剔除第二列
可以在主函数中添加
writepath = 'iris_processed.txt'
spf = pd.DataFrame(data_matrix)
spf.drop([1], axis=1, inplace=True)
strs=str_name.values
spf.insert(3,4,strs)#将字符串内容加入spf中
#在第3+1列插入一个列名为4的列(因为列名为0,2,3的在,列名为1的刚刚被删了)
spf.to_csv(writepath,index=False,header=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
来实现
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/396645
推荐阅读
相关标签

