
- 1ESP32 开发笔记(三)源码示例 7_WS2812_RMT 使用ESP32的RMT实现彩虹变色效果_mic 朋友w2812 esp32
- 2mysql大量查询导致锁表_mysql数据库大规模数据读写并行时导致的锁表问题
- 3Boostrap(五)组件_pootstrap组件
- 4库卡机器人编程语言di_清华打造首支中国风机器人乐队,最早的人形机器人在哪?机器编程...
- 55分钟读懂什么是虚拟数字人_数字人 ue
- 6kafka sasl_ssl配置
- 7iOS 常用第三方开源框架介绍_mgboxprovider
- 8C++-vector:判断vector中是否存在特定元素【std::find(v.begin(), v.end(), key)】_std::vector 查找元素
- 9bert-实体抽取
- 10硬件安全模块 (HSM)、硬件安全引擎 (HSE) 和安全硬件扩展 (SHE)的区别_se芯片与hsm模块的区别
Hive分区表的分区操作_hive是如何实现分区
赞
踩
为了对表进行合理的管理以及提高查询效率,Hive可以将表组织成“分区”。一个分区实际上就是表下的一个目录,一个表可以在多个维度上进行分区,分区之间的关系就是目录树的关系。
1、创建分区表
通过PARTITIONED BY子句指定,分区的顺序决定了谁是父目录,谁是子目录。
创建有一个分区的分区表:
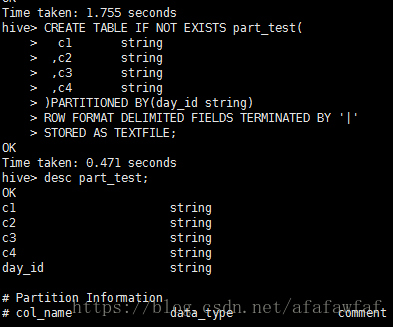
CREATE TABLE IF NOT EXISTS part_test(
c1 string
,c2 string
,c3 string
,c4 string
)PARTITIONED BY (day_id string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE;
创建有两个分区的分区表:
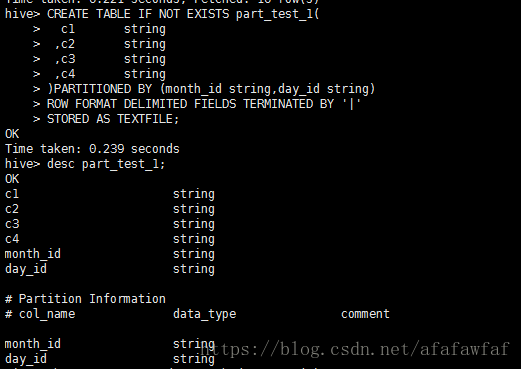
CREATE TABLE IF NOT EXISTS part_test_1(
c1 string
,c2 string
,c3 string
,c4 string
) PARTITIONED BY (month_id string,day_id string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE;
2、 外部分区表
外部表也可以建成分区表,如hdfs目录/user/tuoming/part下有
201805和201806两个目录,201805下有一个20180509子目录,201806下有20180609和20180610两个子目录。

创建一个映射到/user/tuoming/part目录的外部分区表:
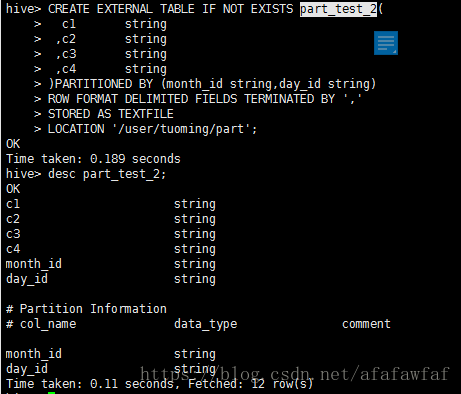
CREATE EXTERNAL TABLE IF NOT EXISTS part_test_2(
c1 string
,c2 string
,c3 string
,c4 string
)PARTITIONED BY (month_id string,day_id string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/tuoming/part';
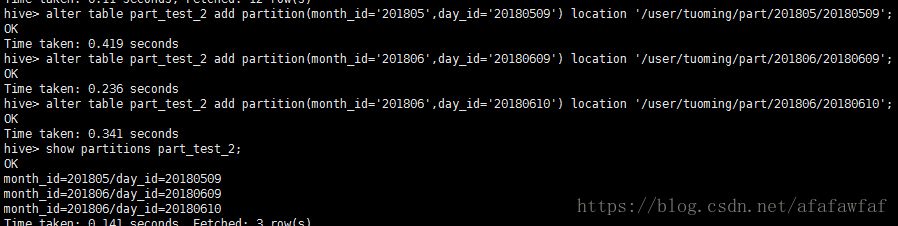
为part_test_2增加分区:
alter table part_test_2 add partition(month_id='201805',day_id='20180509') location '/user/tuoming/part/201805/20180509';
alter table part_test_2 add partition(month_id='201806',day_id='20180609') location '/user/tuoming/part/201806/20180609';
alter table part_test_2 add partition(month_id='201806',day_id='20180610') location '/user/tuoming/part/201806/20180610';
show partitions part_test_2;
3、 内部分区表
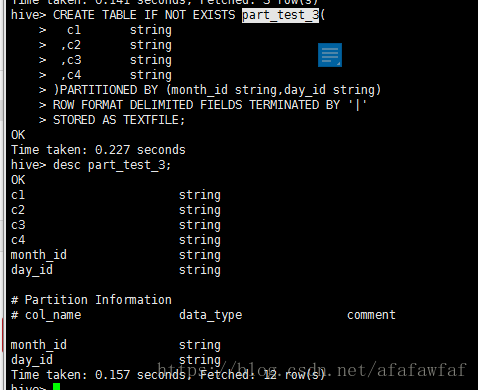
创建一个主分区为month_id,子分区为day_id的内部分区表:
CREATE TABLE IF NOT EXISTS part_test_3(
c1 string
,c2 string
,c3 string
,c4 string
)PARTITIONED BY (month_id string,day_id string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE;
为内部分区表加载数据
(1)使用load data inpath…overwrite into table partition语句从hdfs目录加载:
load data inpath '/user/tuoming/test/test' overwrite into table part_test_3 partition(month_id='201805',day_id='20180509');
数据内容如下:
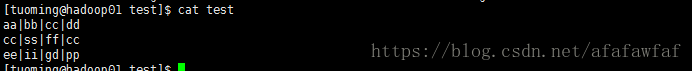

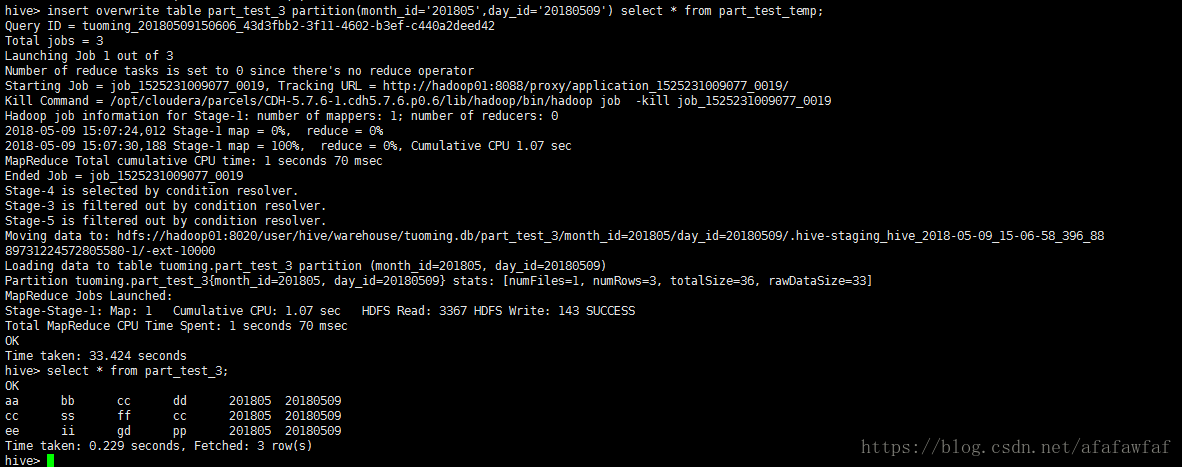
覆盖插入:
insert overwrite table part_test_3 partition(month_id='201805',day_id='20180509') select * from part_test_temp;
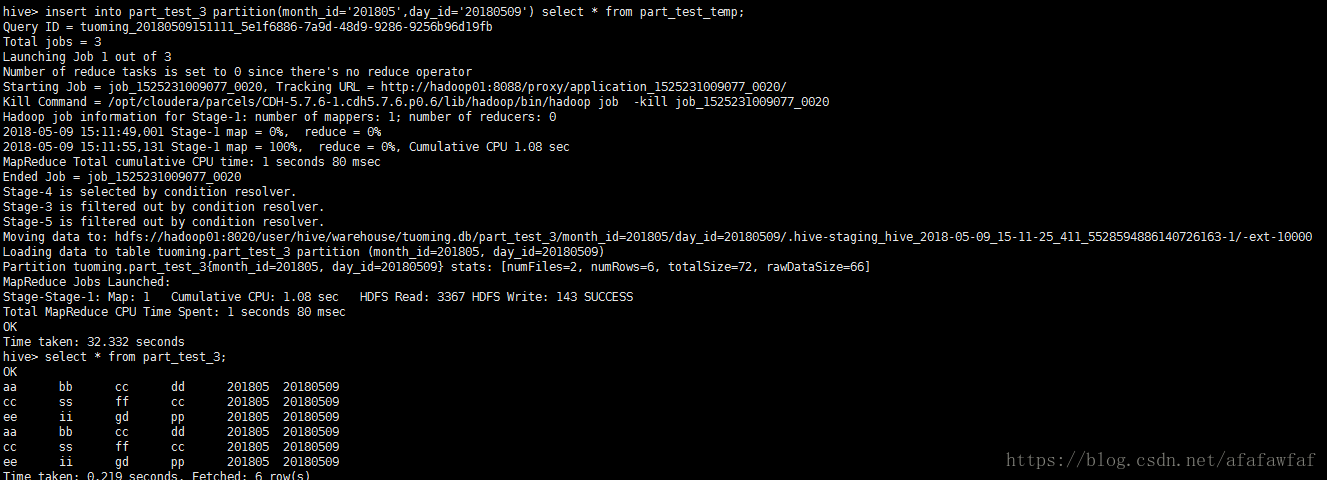
追加插入:
insert into part_test_3 partition(month_id='201805',day_id='20180509') select * from part_test_temp;
注意:使用以上两种方法为内部分区表加载数据不需要预创建分区,加载数据时会自动创建相应的分区。如果想要为内部表预先创建分区,需要使用hadoop fs –mkdir命令在表目录下先创建相应的分区目录,然后再使用alter table add partition语句增加分区:
4、 删除分区
使用alter table…drop partition语句删除对应分区:
alter table part_test_3 drop partition(day_id='20180509');

注意:外部分区表使用alter table…drop partition语句删除分区,只会删除元数据,相应的目录和文件并不会删除。内部表使用该语句删除分区,既会删除元数据,也会删除相应的目录和数据文件。
5、 动态分区
上述使用insert overwrite table…partition…从查询结果加载数据到分区,必须指定特定的分区,而且每个分区都需要使用一条插入语句。当需要一次插入多个分区的数据时,可以使用动态分区,根据查询得到的数据动态分配到分区里。动态分区与静态分区的区别就是不指定分区目录,由hive根据实际的数据选择插入到哪一个分区。
#启动动态分区功能
set hive.exec.dynamic.partition=true;
#允许全部分区都是动态分区
set hive.exec.dynamic.partition.mode=nostrick;
#month_id为静态分区,day_id为动态分区:
insert overwrite table dynamic_test partition(month_id='201710',day_id)
select c1,c2,c3,c4,c5,c6,c7,day_id from kafka_offset
where substr(day_id,1,6)='201710';
# month_id和 day_id均为动态分区:
insert overwrite table dynamic_test partition(month_id,day_id)
select c1,c2,c3,c4,c5,c6,c7,substr(day_id,1,6) as month_id,day_id from kafka_offset;
为了让分区列的值相同的数据尽量在同一个mapreduce中,这样每一个mapreduce可以尽量少的产生新的文件夹,可以借助distribute by的功能,将分区列值相同的数据放到一起。
insert overwrite table dynamic_test partition(month_id,day_id)
select c1,c2,c3,c4,c5,c6,c7,substr(day_id,1,6) as month_id,day_id from kafka_offset
distribute by month_id,day_id;

