
- 1程序人生:新媒体运营毅然转行测试涨薪3k,我的入行秘籍是什么..._java转测试还是新媒体运营
- 2媒体梦工厂AI智聊:轻松提升工作效率的智能助手
- 3Java面试题总结(1-111)_java: 方法不会覆盖或实现超类型的方法且函数名变灰色
- 4结构设计到项目管理:工程师是怎么练成的._冰箱结构工程师项目经验怎么写
- 5为大模型而生!顶流大佬发起成立学术会议 COLM,或成为未来 NLP 最强顶会?!_如何看待 colm 顶会
- 6Java【动态规划】图文详解 “路径问题模型“ , 教你手撕动态规划_java 动态规划
- 7让 macOS 终端走代理的四种方法_mac 终端不能访问代理
- 8RabbitMQ集群搭建详细介绍以及解决搭建过程中的各种问题 + 配置镜像队列——实操型
- 9Oracle中的plsql编程_oracle plsql编程
- 10基于Springboot+Vue的Java项目-大学生租房平台系统(附演示视频+源码+LW)
[学习笔记]yolo系列算法总结
赞
踩
YOLO(You Only Look Once)声名显赫,是检测领域一个基于回归思想的算法,已经成为机器人、无人驾驶汽车和视频监控应用的核心实时物体检测系统。目前已经从yolov1更新到了yolov8,本文参考网上的资料,对yolo各个版本进行一次全新的梳理总结。
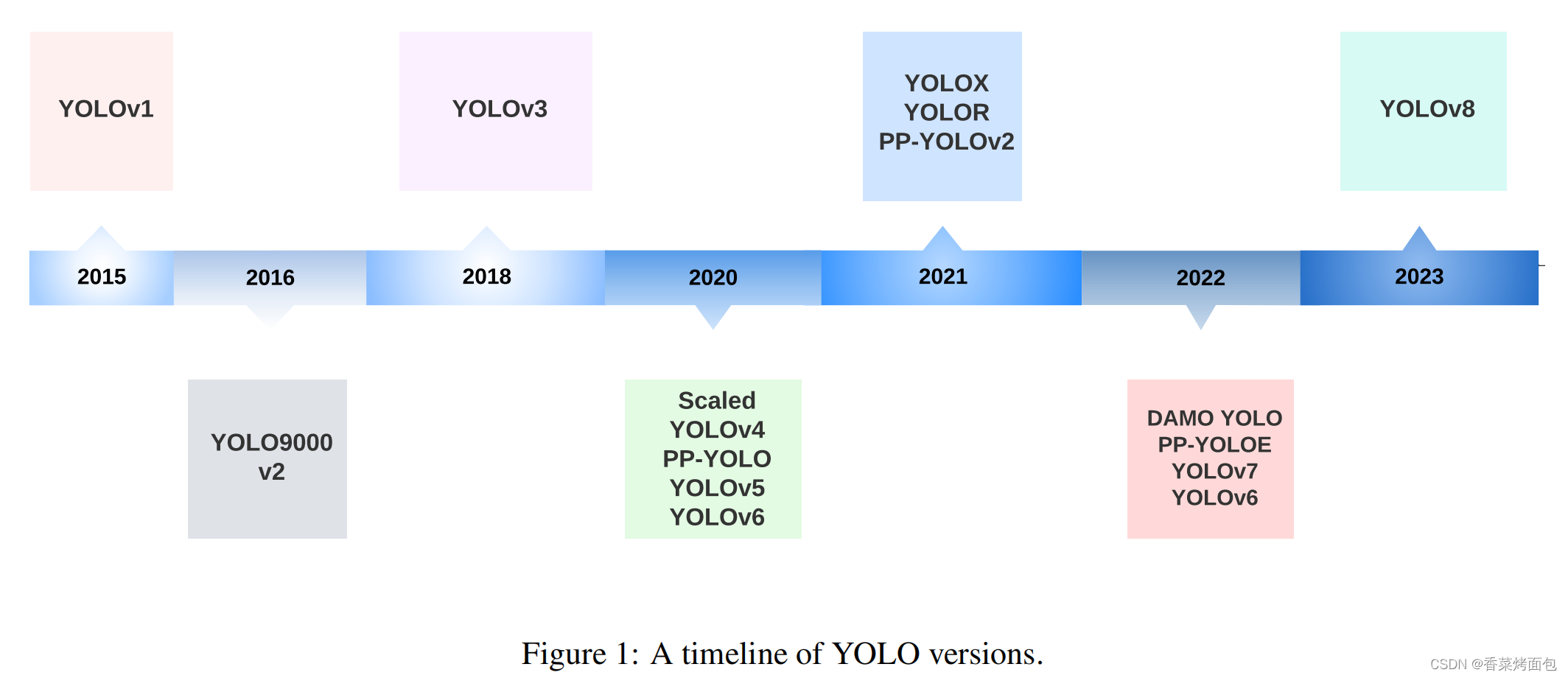
1. yolov1
核心思想: 把整张图片作为网络的输入,直接在输出层对bbox的位置和类别进行回归预测。
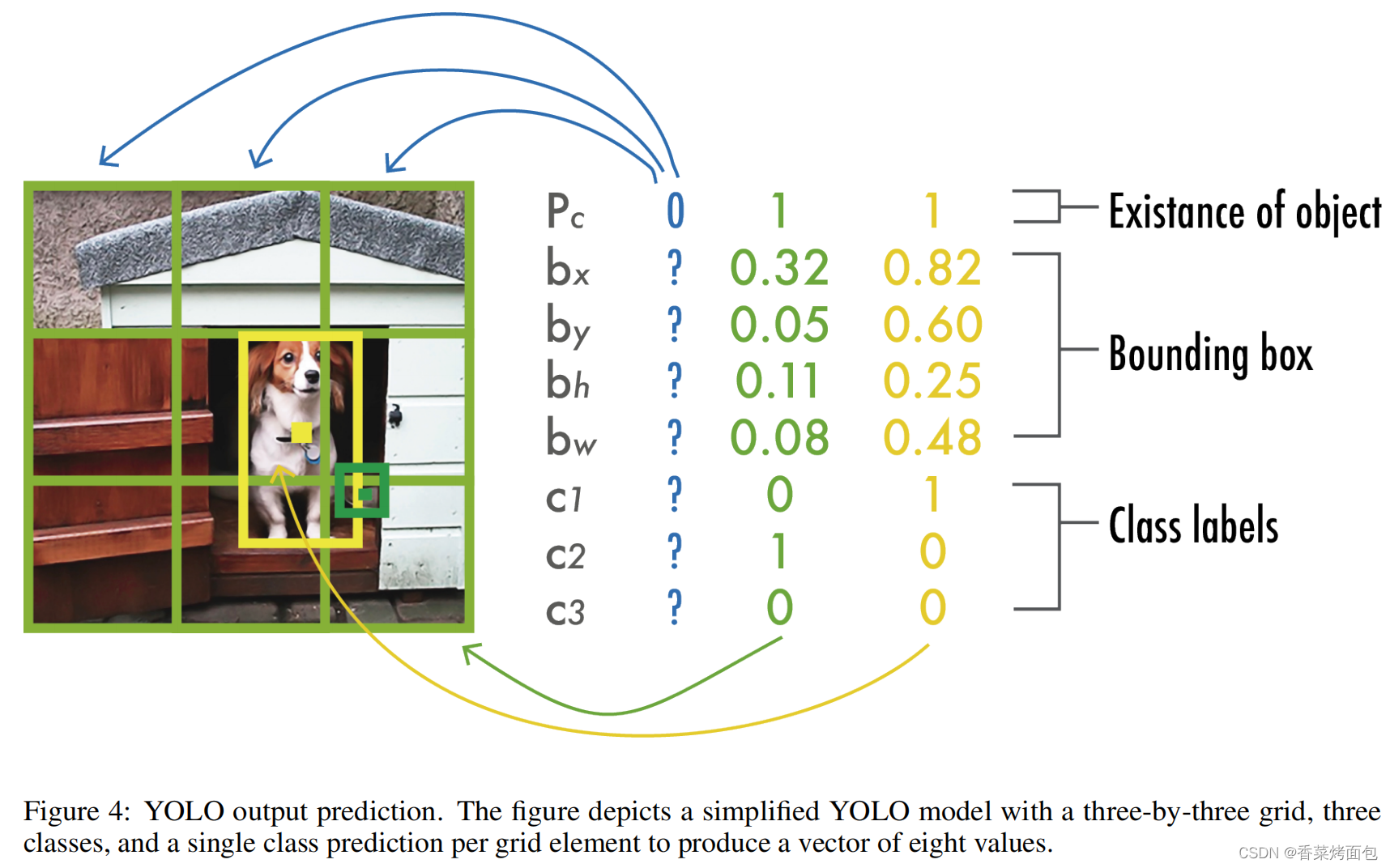
如图,yolo把整图分为个格子, 每个格子负责预测
个边框,每个边框有5个属性
和C个类别概率,所以输出为
的张量,最后用NMS去除重复的检测结果。
网络的输出搞清楚了,最重要的要清楚损失函数,即怎么训练,才能从原理上理解Yolo的思想。完整的损失函数如下:
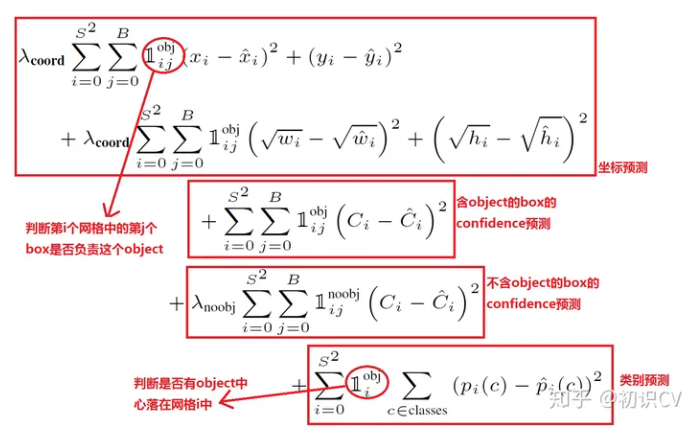
从公式中看出,损失函数包括边框的损失,置信度损失,类别损失三者之和,且都采用平方误差。 且各部分用权重系数来区分重要性。
YOLO的简单结构,加上其新颖的全图像单次回归,使其比现有的物体检测器快得多,允许实时性能。然而,虽然YOLO的表现比任何物体检测器都快,但与最先进的方法如快速R-CNN[39]相比,定位误差更大。造成这种限制的主要原因有三个:
- 它在网格单元中最多只能检测到两个相同类别的物体,限制了它预测附近物体的能力
- 它在预测训练数据中未见的长宽比物体时很吃力
- 由于下采样层,它只能从粗略的物体特征中学习
2. yolov2
yolov2主要在v1的基础上做了以下改进
- 所有卷积增加BN层,批量归一化,改善收敛性并减少过拟合;
- 全卷积,去掉了全连接层,使用全卷积架构;
- 使用Anchor来预测边界。使用一组先验框Anchor, 这些Anchor具有预定义的形状,每个网格单元都定义了多个Anchor, 系统预测每个Anchor的坐标和类别。相当于自定义yolov1里的B,且通过数据里标注好的框kmeans聚类来获取先验Anchor;
- 多尺度训练。

3. yolov3
YOLOv3于2018年由Joseph Redmon和Ali Farhadi发表在ArXiv。它包括重大的变化和更大的架构,以便在保持实时性能的同时与最先进的技术接轨。在下文中,我们描述了相对于YOLOv2的变化。
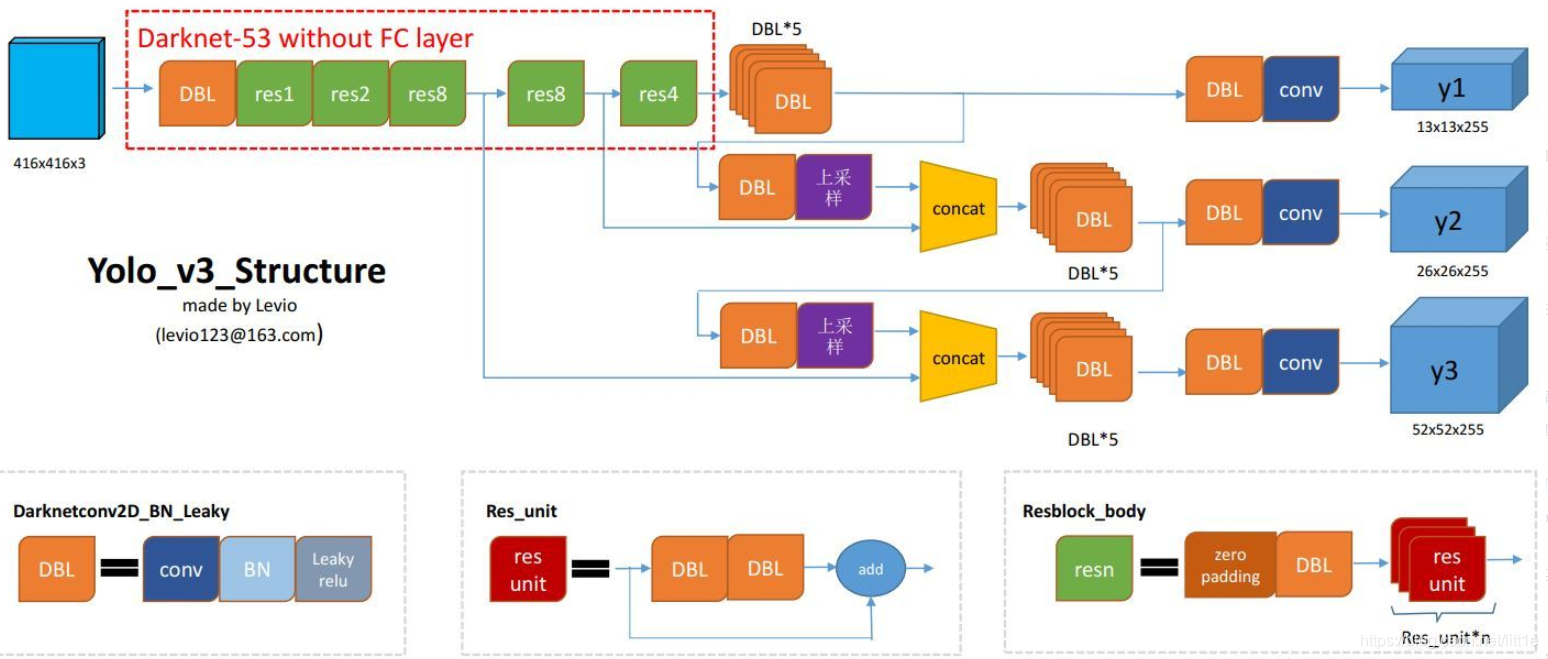
与yolov2相比,yolov3主要有以下改进:
1. BackBone创新:使用darknet53
2. Neck端:使用FPN特征金字塔, 在Head端有三种尺度的prediction。
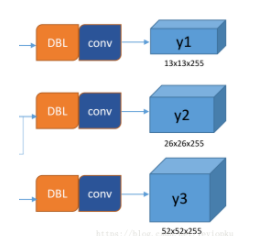
所谓的多尺度就是来自这3条预测之路,y1,y2和y3的深度都是255,边长的规律是13:26:52。yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3×(5 + 80) = 255。这个255就是这么来的
三次检测,每次对应的感受野不同,32倍降采样的感受野最大,适合检测大的目标,所以在输入为416×416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。16倍适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。8倍的感受野最小,适合检测小目标,因此anchor box为(10,13); (16,30); (33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box。
3. head端:Bounding box先验。与YOLOv2一样, 作者也使用k-means来确定Anchor的bounding box预设。不同的是, 在YOLOv2中,他们每个单元共使用了五个先验盒,而在YOLOv3中,他们使用了三个不同尺度的先验盒。
当YOLOv3发布时,物体检测的基准已经从PASCAL VOC变成了Microsoft COCO。因此,从这里开始, 所有的YOLO都在MS COCO数据集中进行评估。YOLOv3-spp在20FPS的情况下,平均精度AP为36.2%, AP50 为60.6%,达到了当时的最先进水平,速度快了2倍。
这时,物体检测器的结构开始被描述为三个部分:Backbone, Neck和Head。图10显示了一个高层次的Backbone, Neck 和 Head图。
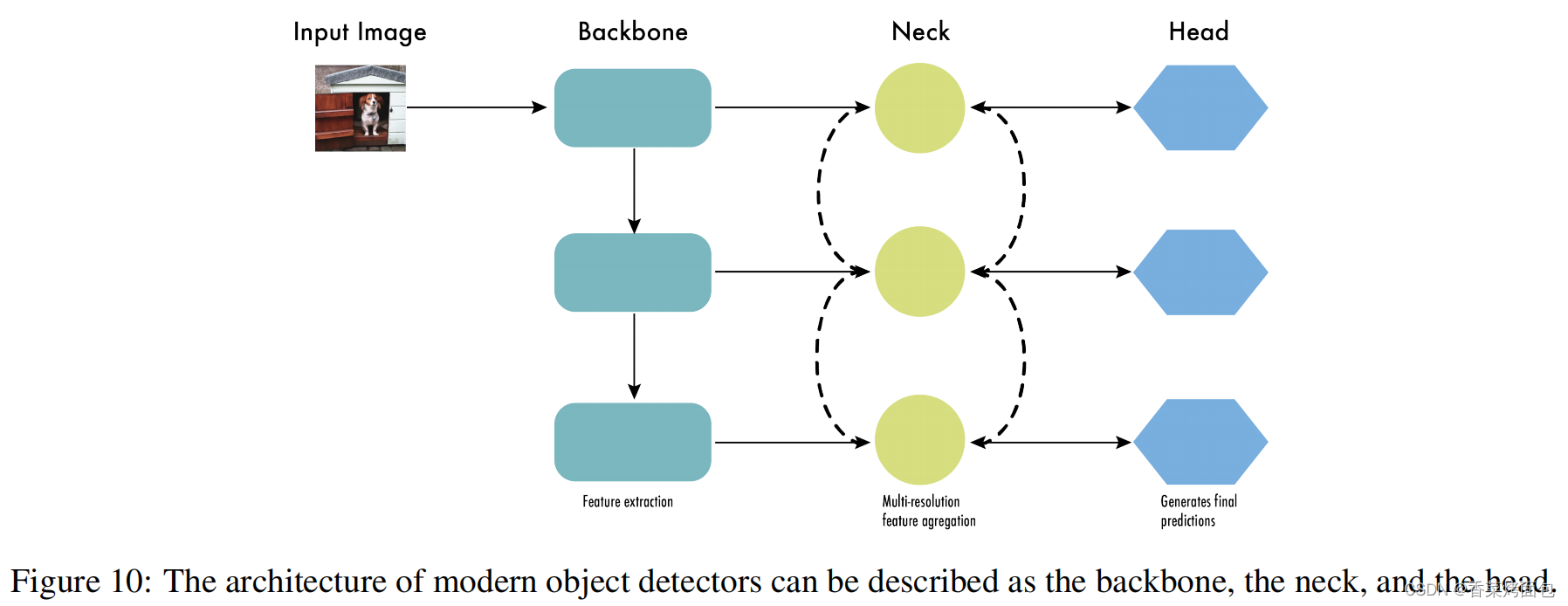
- Backbone: 负责从输入图像中提取有用的特征。它通常是一个卷积神经网络(CNN),在大规模的图像分类任务中训练,如ImageNet。骨干网在不同的尺度上捕捉层次化的特征,在较早的层中提取低层次的特征(如边缘和纹理),在较深的层中提取高层次的特征(如物体部分和语义信息)。
- Neck: 是连接Backbone和Head的一个中间部件。它聚集并细化骨干网提取的特征,通常侧重于加强不同尺度的空间和语义信息。颈部可能包括额外的卷积层、特征金字塔网络(FPN),或其他机制,以提高特征的代表性。
- Head:是物体检测器的最后组成部分;它负责根据Backbone和Neck提供的特征进行预测。它通常由一个或多个特定任务的子网络组成,执行分类、定位,以及最近的实例分割和姿势估计。头部处理颈部提供的特征,为每个候选物体产生预测。最后,一个后处理步骤,如非极大值抑制(NMS),过滤掉重叠的预测,只保留置信度最高的检测。
4. yolov4
我们先看一下yolov4的网络架构
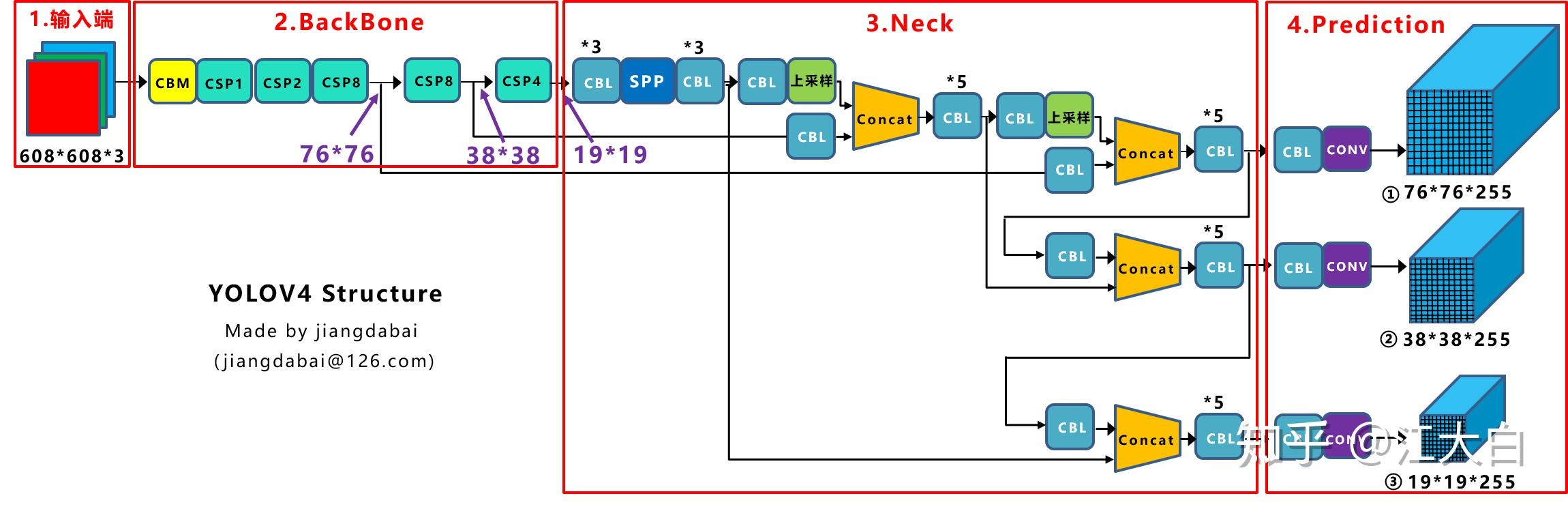
我们将YOLOv4的主要变化总结为以下几点:
1. 输入端创新:数据增强Mosaic,cmBN、SAT自对抗训练。Mosaic数据增强采用4张图片,随机缩放剪切的方式进行拼接,这种方式可以丰富数据集,增加很多小目标,同时直接计算4涨图片的数据,使用mini-batch大小不需要很大,一个GPU就可以达到比较好的效果。
2. BackBone创新:使用CSPDarknet53特征提取网络。这里主要介绍下CSP模块,如下图所示
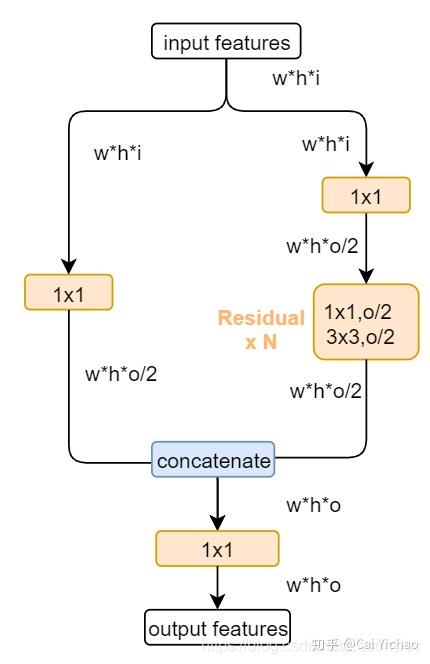
由上图可知,CSP其实就是让featuremap经过经过1*1卷积后压缩一部分通道,直接给resnet并联,然后再concate一起,这样相当于不是所有的通过都经过了卷积层,压缩了参数的数量,可以更好的优化。
3. Neck的创新:采用了SPP模块、FPN+PAN的方式。

所谓SPP,就是把用不同的池化核尺寸进行最大值池化,然后拼接起来。作者认为这种方式更有效的增加主干特征的接收范围。
4. Head端的创新:使用CIOU。
IOU顾名思义就是交并比,IOU损失中,应该IOU越大,loss越小才对,即为:
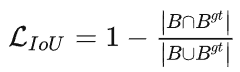
但IOU体现的只是粗略的位置关系,不同的位置时IOU完全可能相等,且在两者不相交时,IOU为0无法迭代。
为了更加准确的体现出预测框和groundtruth框的位置关系,有了DIOU(Distantce-IOU)
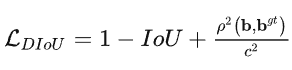
DIOU损失就是给IOU损失加了一个距离的惩罚项,惩罚项为两个框的中心点欧式距离和两个框的最小封闭框的对角线长度的比值。
基于DIOU损失,通过添加长宽比的一致性来提高性能表现,就出现了CIOU(Complete IOU Loss)

CIOU损失就是在DIOU基础上,又增了长宽比的惩罚项,a为权衡参数,v为两个框长宽比的反正切值的平方差。即

5. yolov5
YOLOv5是在YOLOv4之后几个月于2020年由Glenn Jocher发布。主要区别是它是用Pytorch而不是Darknet开发的。YOLOv5是开源的,由Ultralytics积极维护YOLOv5很容易使用、培训和部署。Ultralytics提供了一个iOS和Android的移动版本,以及许多用于标签、培训和部署的集成。
YOLOv5 提供了五个版本: YOLOv5n( 纳米级)、YOLOv5s( 小型)、YOLOv5m( 中型)、YOLOv5l(大型)和YOLOv5x(特大型)。

Yolov5的结构和Yolov4很相似,同样在输入端采用了mosaic增强,Neck使用了FPN+PAN结构,主要区别如下:
1. 输入端:自适应anchor计算
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。
但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。

控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
2. BackBone: Focus结构,CSP结构。

Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。
比如右图的切片示意图,4*4*3的图像切片后变成2*2*12的特征图。
YOLOv5发布的版本越来越多, 从7.0版,包括能够进行分类和实例分割的YOLOv5版本
6. yolov6
主要变化如下:
- 一个基于RepVGG的新骨架,称为EfficientRep,比以前的YOLO骨架使用更高的并行性。对于颈部, 他们使用PAN增强了RepBlocks 或CSPStackRepBlocks , 用于大型模型。而受YOLOX的启发,他们开发了一个高效的解耦头;
- 新的分类和回归损失。他们使用了一个分类VariFocal损失和一个SIoU/GIoU回归损失;
- 使用RepOptimizer和信道明智蒸馏的检测量化方案,有助于实现更快的检测器
- 无锚(Anchor-free)。自YOLOv2以来,所有后续的YOLO版本都是基于锚点的检测器。受到YOLOX最先进的无锚物体检测器的启发,回到了一个无锚结构,简化了训练和解码过程。
7. yolov7
YOLOv7由YOLOv4和YOLOR的同一作者于2022年7月发表在ArXiv。当时,在5 FPS到160 FPS的范围内,它的速度和准确度超过了所有已知的物体检测器。与YOLOv4一样,它只使用MS COCO数据集进行训练,没有预训练的骨干。YOLOv7提出了一些架构上的变化和一系列的免费包,在不影响推理速度的情况下提高了准确率,只影响了训练时间
YOLOv7的架构变化是:
- 扩展高效层聚合网络(E-ELAN)。ELAN[是一种策略,通过控制最短的最长梯度路径,让深度模型更有效地学习和收敛。YOLOv7提出的E-ELAN适用于具有无限叠加计算块的模型。E-ELAN通过洗牌和合并cardinality结合不同组的特征,在不破坏原始梯度路径的情况下增强网络的学习;
- 基于串联的模型的模型缩放。缩放通过调整一些模型属性来生成不同大小的模型。YOLOv7的架构是一个基于串联的架构,其中标准的缩放技术,如深度缩放,导致过渡层的输入通道和输出通道之间的比例变化,这反过来又导致了模型的硬件使用量的减少。YOLOv7提出了一种新的基于串联模型的缩放策略,其中块的深度和宽度以相同的因素进行缩放,以保持模型的最佳结构。
与YOLOv4相比,YOLOv7实现了参数减少75%,计算量减少36%,同时平均精度(AP)提高了1.5%。与YOLOv4-tiny相比,YOLOv7-tiny设法将参数和计算量分别减少39%和49%,同时保持相同的AP。最后,与YOLOR相比,YOLOv7的参数数量和计算量分别减少了43%和15%,同时AP也略微增加了0.4%。
8. yolov8
YOLOv8 是由小型初创公司 Ultralytics 创建并维护的,支持图像分类,检测和实例分割。值得注意的是 YOLOv5 也是由该公司创建的。
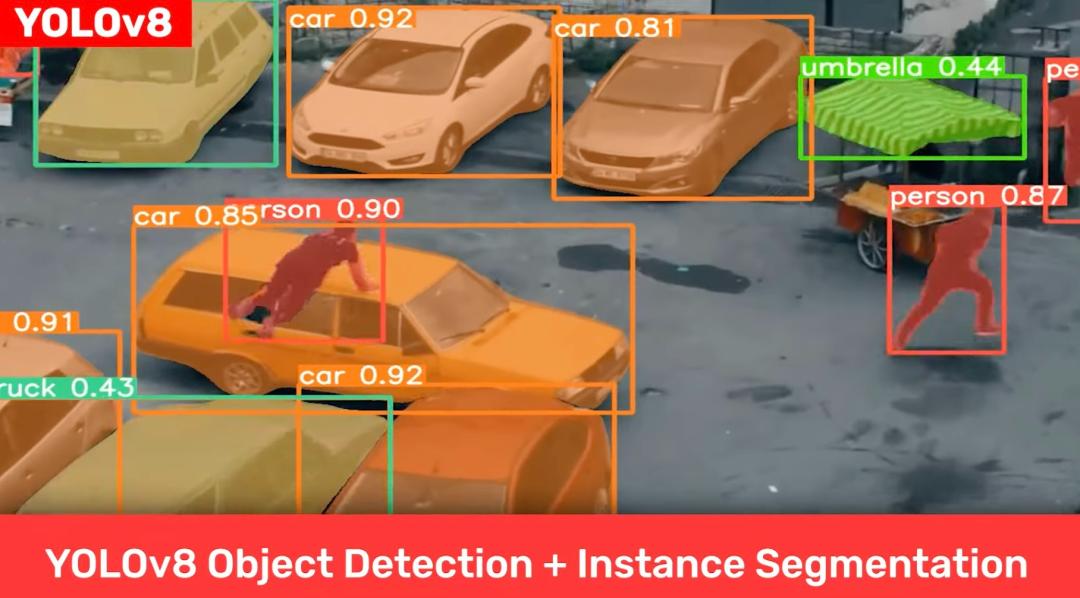
YOLOv8 的主要具有以下特点:
- 对用户友好的 API(命令行 + Python);
- 模型更快更准确;
- 模型能完成目标检测、实例分割和图像分类任务;
- 与先前所有版本的 YOLO 兼容可扩展;
- 模型采用新的网络主干架构;
- 无锚(Anchor-Free)检测;
- 模型采用新的损失函数。
相比于之前的 YOLO 系列,YOLOv8 模型似乎表现得更好,不仅领先于 YOLOv5,YOLOv8 也领先于 YOLOv7 和 YOLOv6 版本。

