
- 1javascript 实现 强制阅读协议后注册自动跳转页面_协议强制阅读
- 2FFmpeg 调用 Android MediaCodec 进行硬解码(附源码)
- 3【Android学习】【TabLayout】+【ViewPager2】简洁使用_android tablayout+viewpager2
- 4无人机如何远程控制其他设备
- 5Intellij IDEA远程向虚拟机hadoop集群提交作业(好多坑)_本地也有hadoop 如何把job提交到虚拟机上
- 6算法沉淀 —— 动态规划(子序列问题(上))
- 7虚拟摄像头之五: 详解 android8 的 Camera 子系统框架_安卓虚拟摄像头
- 8APP+后台+vue前端全套打包送,电商解决方案CRMEB开源啦
- 9运算放大器-放大倍数的表示方法:增益(Gain) 和 分贝(dB)_增益中的db
- 10ChatGPT 报错:“Your OpenAi account has been deactivated…”什么原因?如何处理!_the openai account associated with this api key ha
机器学习框架Ray -- 2.1 Ray 用例整理_ray serve
赞
踩
为扩展机器学习而设计的Ray常见使用案例进行索引。包含对博客、示例和教程的突出引用,这些资源也可以在Ray文档的其他位置找到。
1. Batch Inference
Batch Inference是指在一组输入观测值上生成模型预测。该模型可以是回归模型、神经网络,也可以仅是Python函数。Ray可以将批量推断从单GPU机器扩展到大型集群。
将训练模型的体系结构和权重导出到共享对象存储中,可以并行化对输入数据批量推断的过程。使用这些模型副本,Ray AIR的Batch Predictor可以跨工作进程扩展批量预测。

使用Ray AIR的BatchPredictor进行批量推断
以下整理了Batch interface的相关资源。
- 教程 Scalable Batch Inference with Ray 使用Ray进行可扩展的批量推断*
- 教程 Ray中的模型批量推断:Actors、ActorPool和Datasets
- 官方指南 使用Ray Core进行Batch Prediction
- 官方指南 使用Ray Datasets处理纽约的出租车数据*
- 官方指南 使用Ray Datasets扩展OCR
2. Many Model Training 多模型训练
在机器学习中,多模型训练是常见的用例,例如时间序列预测,需要在对应于位置、产品等多个数据批次上拟合模型。重点是在数据集的子集上训练许多模型,而不是在整个数据集上训练单个模型。
当您要训练的任何给定模型可以适合于单个GPU时,Ray可以将每个训练运行分配给一个单独的Ray任务。通过这种方式,所有可用的工作进程都被利用来运行独立的远程训练,而不是一个工作进程按顺序运行作业。
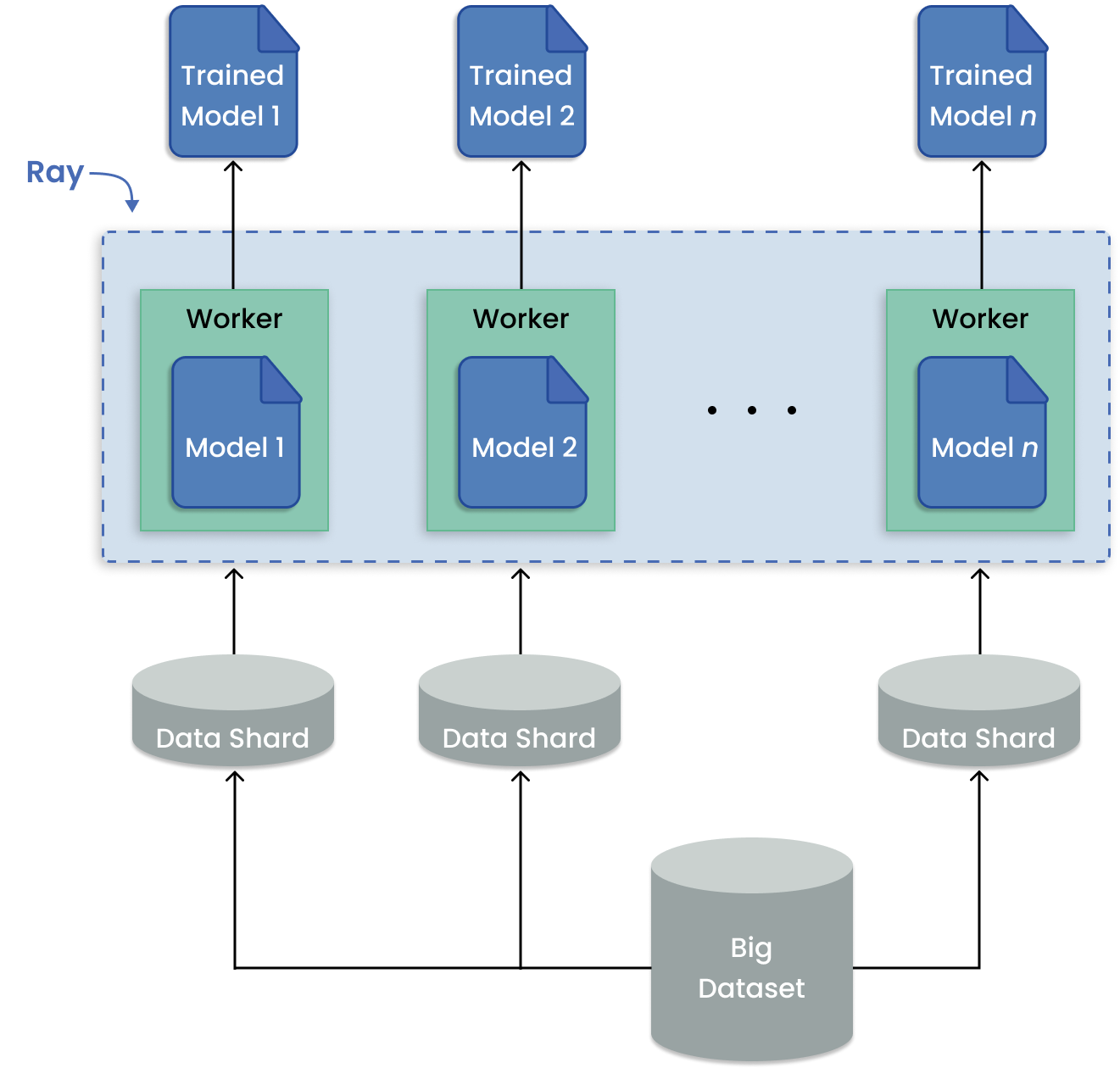
如何在Ray上进行多模型训练?
要训练多个独立的模型,请使用Ray Tune(教程)库。这是大多数情况下推荐使用的库。
如果您的数据源适合于单台机器(节点)的内存,您可以在当前的数据预处理流水线中使用Tune。如果您需要扩展数据,或者您希望规划未来的扩展,可以使用Ray Data库。要使用Ray Data,您的数据必须是受支持的格式。
对于较少见的情况,存在替代解决方案:
1.如果您的数据不在受支持的格式中,请使用Ray Core(教程)进行自定义应用程序。这是一个高级选项,需要理解设计模式和反模式。
2.如果您有一个庞大的预处理流水线,您可以使用Ray Data库来训练多个模型(教程)。
通过以下资源了解更多有关多模型训练的信息。
- 博客 使用Ray框架在记录时间内训练一百万个机器学习模型
- 官方指南 使用Ray Core批量训练
- 官方指南 使用Ray Datasets进行批量训练
- 官方指南 运行基本的调优实验*
- 官方指南 使用Ray Tune进行批量训练和调优
3. Model Serving 模型服务
Ray Serve非常适合模型组合,可以在Python代码中构建由多个ML模型和业务逻辑组成的复杂推断服务。
它支持需要协调多个Ray actors的复杂模型部署模式,在这些模式下,不同的actors为不同的模型提供推断。Serve处理批处理和在线推断,可以扩展到生产中的数千个模型。 了解更多关于模型服务的资源,请参考以下内容。
- 博客 Simplify your MLOPs with Ray and Ray Serve
- Getting Started with Ray Serve
- Model Composition in Serve
- 案例库 Examples of Serve
4. Hyperparameter Tuning 超参调整
Ray Tune库使得任何并行的Ray工作负载都可以在超参数调优算法下运行。
运行多个超参数调优实验是适合分布式计算的模式,因为每个实验都是独立的。Ray Tune处理了超参数优化的分布式部分,并提供了关键功能,例如最佳结果的检查点、优化调度和指定搜索模式。

- Getting Started with Ray tune
- 博客 How to distribute hyperparameter tuning with Ray Tune
- Hyperparameter Search with Transformers*
- Ray Tune的案例库
5.Distributed Training 分布式训练
Ray Train库将许多分布式训练框架集成到一个简单的Trainer API下,提供分布式编排和管理功能。
与训练多个模型相比,模型并行将一个大型模型分割成许多部分,然后在多台机器上进行训练。Ray Train具有内置的抽象层,可用于分发模型的分片、并行运行训练。
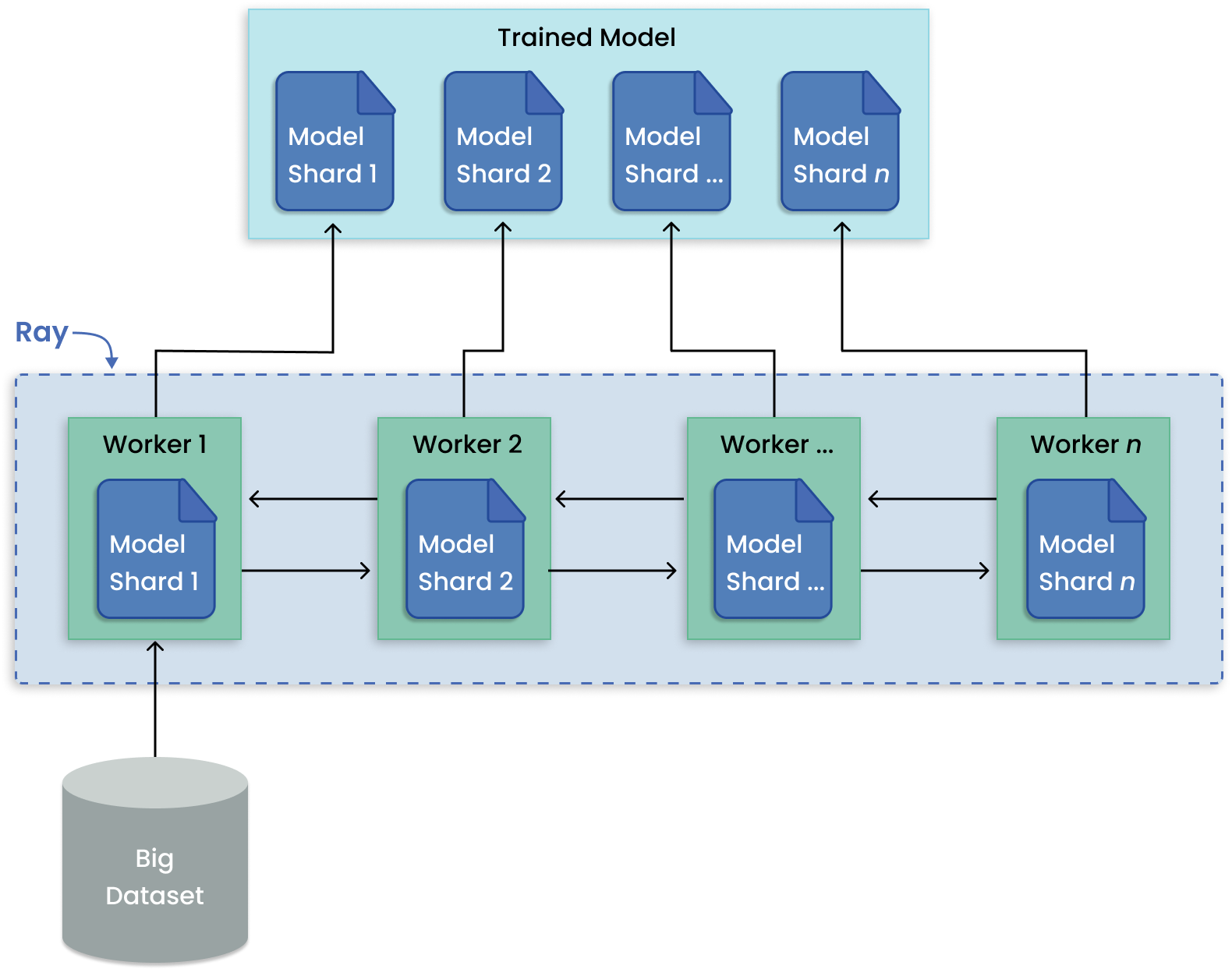
案例与教程:
6. Reinforcement Learning 强化学习
RLlib是一个开源的强化学习库,提供对生产级别、高度分布式强化学习工作负载的支持,同时维护了统一且简单的API,适用于各种行业应用。
RLlib被许多不同垂直领域的行业所使用,例如气候控制、工业控制、制造和物流、金融、游戏、汽车、机器人、船舶设计等等。

-
博客 RLlib介绍*:示例环境
7. ML Platform 机器学习平台
Ray提供了一个ML平台,可以帮助您构建、训练和部署机器学习模型。该平台提供了各种工具和API,包括自动化超参数调整、分布式训练、模型部署等功能,可以让您更轻松地管理整个机器学习流程。
8. End-to-End ML Workflows 端到端ML工作流
9. Large Scale Workload Orchestration
Ray提供了一些工具和API,可以帮助您管理大规模的工作负载编排,包括任务调度、资源管理、容错等功能。使用Ray,您可以轻松地管理大规模的工作负载,提高系统的可靠性和性能。

