
- 1JAVA实现单链表快速排序_java单链表快速排序
- 22018年安徽省机器人大赛单片机与嵌入式系统应用技能竞赛试题(1)_单片机与嵌入式竞赛简答题
- 3Out of Vocabulary处理方法
- 4linux /proc/net/tcp 文件分析_seq_operations
- 5RDP连接Ubuntu远程桌面
- 6Kaggle入门比赛:灾难推文的自然语言处理 详细教程_kaggle自然语言处理入门项目
- 7TS学习笔记_ts笔记
- 8python学习-结构化的文本文件_中文文本结构化实例python
- 9【保姆级教程】如何订阅OnlyFans?如何在OnlyFans上面支付?OnlyFans虚拟卡订阅教程_onlyfuns
- 10【C2】【字符串】【入门】删除单词后缀_除该描述 给定一个单词,如果该单词以er、ly或者ing后缀结尾, 则删除该后缀(题目保
浅谈Kafka Broker的硬件配置选型
赞
踩
前言
笔者之前写了一篇关于建设实时数仓的初步方案(参见这里),经过研讨与部分修改之后已经开始施工。在我们设计的实时数仓体系中,Kafka占有核心地位,ODS层的原始数据与DW层的事实/明细数据都需要用它来存储,故我们需要搭建专用的Kafka集群。工欲善其事,必先利其器,本文简单讨论一下该如何为Kafka Broker服务器选择合适的硬件(虽然这并不是笔者的主业)。
CPU
Kafka是I/O密集型而非计算密集型的框架,所以对CPU的需求是各个指标里最宽松的,消耗CPU的点主要在于消息的压缩和解压缩。一个Kafka Broker节点往往要承载许多个Topic Partition并与许多个Producer/Consumer交互,所以并行度(核心/线程数)要比单核性能(频率)更重要。
一般来讲单节点8C/16T,主频2GHz以上(按Broadwell架构计)就可以满足小型生产环境,负载比较重的集群可以配到12C/24T甚至16C/32T。注意根据CPU规格的不同,Broker的num.network.threads和num.io.threads参数也要适当改变。
内存
笔者之前专门写过一篇重要的文章《聊聊page cache与Kafka之间的事儿》,如果看官还未读过的话,强烈建议先看一眼。
该文已经说明:Kafka对JVM堆内存的需求不大(分配6~8GB足够),但是会非常积极地使用page cache。如果Consumer在消费时能够命中Broker的page cache,那么消息的读写就可以空中接力而不必执行磁盘I/O,所以Broker内存大小与Consumer的吞吐量关系密切。Kafka集群最好是专用的,不混合部署其他吃内存的服务,因为它们会挤占Kafka的page cache空间,产生脏页,造成性能下降。
现在内存的价格并不高,一般64GB是较低要求,128GB应付高吞吐的场景也轻松愉快了。
硬盘
Producer发送的消息最终都要持久化,所以Broker的硬盘配置与Producer的吞吐量关系密切。Kafka的数据盘最好与系统、ZooKeeper等的存储分开,以免拖累性能。
HDD vs SSD?
毫无疑问,SSD的性能(尤其是随机读写性能)比HDD要高不少。但是Kafka是顺序读写的,SSD的优势并没有那么大,并且考虑到成本问题,普通7.2K/10K转的SAS/SATA HDD就足够了。
JBOD vs RAID?
为了尽量增大吞吐量,最好使用多块磁盘。JBOD和RAID是最常见的两种组织多块磁盘的方法。
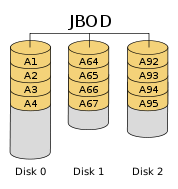
JBOD即“Just a Bunch of Disks”的缩写,中文意译为“磁盘簇”,就是指多块磁盘简单地挂载为一个或多个不同的逻辑设备,只提供容量与并行度的增加,不提供任何冗余。示意图如下。
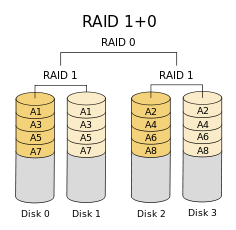
RAID即“独立磁盘冗余阵列”(Redundant Array of Independent Disks),在大学操作系统课程中肯定讲过,所以不再赘述。RAID能够提供读写性能提升和/或冗余机制,生产环境中常用的RAID10的示意图如下。
那么该用哪种呢?Kafka在应用层提供数据冗余(副本)机制,所以选择JBOD是完全可行的,但是如果Partition之间的数据倾斜比较严重,可能会造成不同磁盘占用率相差悬殊。对数据安全性和性能要求比较高的场合可以选择RAID10,并且RAID可以在底层平衡磁盘用量,不过可用的存储空间会减半,成本也会高一些。
容量
硬盘容量需要根据消息数量、消息平均大小、副本数、保留时长(即log.retention.hours)和压缩率来综合考虑。举个栗子,业务端每天产生10亿条消息,每条消息平均大小为1KB,副本数为2,消息保留一周,那么可计算出集群内至少需要预留的磁盘空间为14TB。
网络
Kafka集群内外的数据交换非常频繁,可以说网络带宽是制约吞吐量的重要瓶颈,需要根据业务忙时的尖峰流量来配置。目前数据中心的服务器配置的基本都是万兆(10 Gbps)网卡,问题不大。
参考配置
我司的云服务器全部为阿里云ECS(毕竟有大客户优惠),给出一个参考配置如下。
规格族:大数据网络增强型d1ne
实例规格:ecs.d1ne-c8d3.8xlarge
CPU:32 vCPU(Intel Xeon E5-2682 V4 @ 2.5GHz)
内存:128 GB
系统盘:200 GB
数据盘:500 GB(供ZK等服务使用)
本地存储:5500 GB * 12 SATA HDD(可以JBOD,也可以RAID10)
内网带宽:20 Gbps
民那晚安晚安。

