- 1卷积神经网络的结构组成与解释(详细介绍)
- 2error in xxx setup command: use_2to3 is invalid._error in feedparser setup command: use_2to3 is inv
- 3毕业设计:热门旅游景点大数据分析系统+可视化 +贝叶斯预测模型 旅游大数据 (附源码)✅_景点酒店数据集
- 4uniapp中vue写微信小程序的生命周期差别
- 5分布式结构化数据表Bigtable
- 6Thrift协议_thrift协议和http协议
- 7Spring Boot:基本应用和源码解析_springboot源码工程
- 8深度学习+CRF解决NER问题
- 9GO: 快速升级Go版本_go 升级版本
- 10Golang 企业级web后端框架_go 后端框架
HDFS读写流程(最新史上最详细)
赞
踩
Namenode 和 Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。

Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace),以及客户端对文件的访问。负责元数据(hdfs的目录结构及每一个文件的块信息【块的id,块的副本数量,块的存放位置<datanode>】)的存储,namenode的实时的完整的元数据存储在内存中;namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件;namenode会把引起元数据变化的客户端操作记录在edits日志文件中。
集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
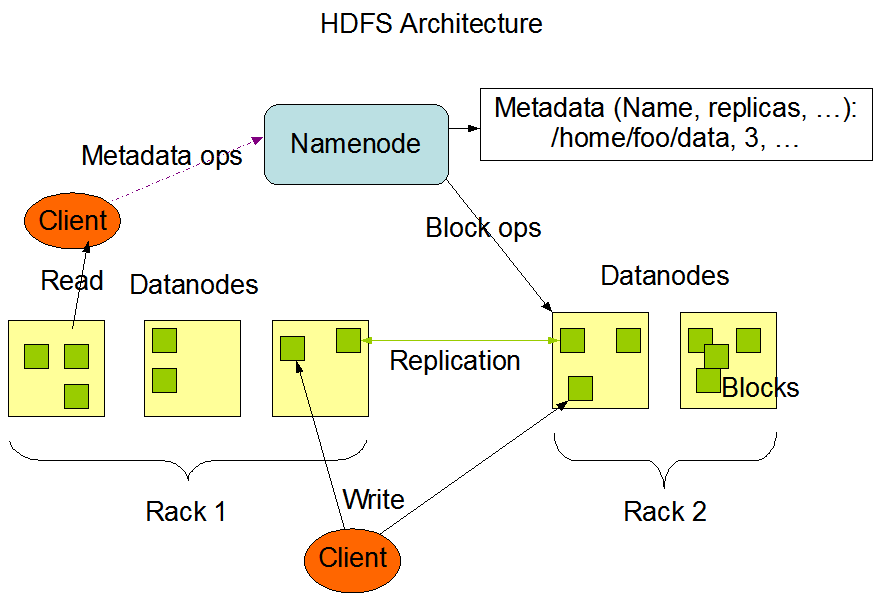
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
基本概念:
HDFS中的block、packet、chunk
很多博文介绍HDFS读写流程上来就直接从文件分块开始,其实,要把读写过程细节搞明白前,你必须知道block、packet与chunk。下面分别讲述。
- block:这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
- packet:是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
- chunk:是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
HDFS的写数据流程:

1、客户端跟NameNode通信请求上传文件/aa/jdk.tgz,NameNode检查目标文件是否已经存在,检查权限,父目录是否已经存在。若通过检查,直接先将操作写入EditLog,并返回输出流对象。(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
2、NameNode返回是否可以上传
3、Client先对文件进行切分,请求第一个block(一般为128MB)该传输到哪些DataNode服务器上
4、NameNode返回3个DataNode服务器DataNode 1,DataNode 2,DataNode 3
5、Client请求3台中的一台DataNode 1(网络拓扑上的就近原则,如果都一样,则随机挑选一台DataNode)上传数据(本质上是一个RPC调用,建立pipeline),DataNode 1收到请求会继续调用DataNode 2,然后DataNode 2调用DataNode 3,将整个pipeline建立完成,然后逐级返回客户端
6、Client开始往DataNode 1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以pocket(默认64KB)为单位。写入的时候DataNode会进行数据校验,它并不是通过一个packet进行一次校验而是以chunk为单位进行校验(512byte)。DataNode 1收到一个packet就会传给DataNode 2,DataNode 2传给DataNode 3,DataNode 1每传一个pocket会放入一个应答队列等待应答
7、当一个block传输完成之后,Client再次请求NameNode上传第二个block的服务器.
8、重复执行上述操作。
流程图如下:

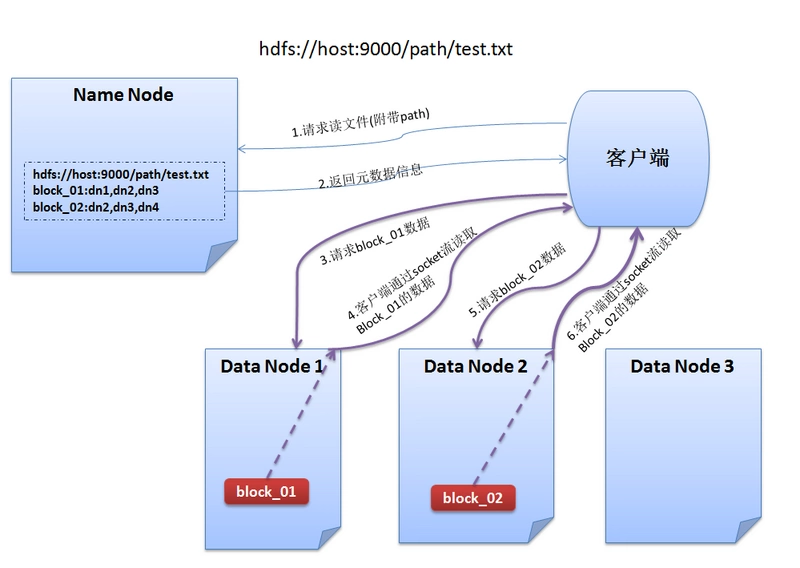
HDFS的读数据流程:

1、客户端与NameNode通信查询元数据,找到文件块所在的DataNode服务器
2、挑选一台DataNode(网络拓扑上的就近原则,如果都一样,则随机挑选一台DataNode)服务器,请求建立socket流
3、DataNode开始发送数据(从磁盘里面读取数据放入流,以packet(一个packet为64kb)为单位来做校验)
4、客户端以packet为单位接收,先在本地缓存,然后写入目标文件