
- 1git&github自学(8):发起Pull Request_pull requests
- 22022.11.20 第9次周报
- 3esp32cam和esp32-s3烧录human_face_detect实现人脸识别_quad_psram: psram id read error: 0x00ffffff, psram
- 4PHP-人员权限管理(RBAC)_php实现权限rubc
- 5Linux sysctl 网络相关参数_fwmark_reflect
- 6《Git与Github使用笔记》分享3款Git可视化工具_github可视化管理工具
- 7YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!
- 8hive:函数:collect_list和collect_set (行转列-多行转单行)_collect_set 分列
- 9Java初阶(类和对象 ---- > 基础概念)_java类和对象的基本概念
- 10中国大学生计算机设计大赛之小程序开发全过程_计算机设计大赛小程序开发
【自然语言处理与文本分析】自然语言处理概要_自然语言处理材料分析
赞
踩
-
-
- 自然语言处理的研究范畴
-
自然语言处理的基本流程
文本数据——》分词/词根还原——》词性标注——》【同义词标定】——》【概念标定】——》角色标定——》句法分析——》文本数据
案例:
1.伊拉克连续第四天将原油倾入波斯湾
2.伊拉克|连续|第四天|将|原油|倾入|波斯湾
3.伊拉克nrt|连续a|第四天m|将|d原油|n倾入|v波斯湾ns(只保留名词,也就只留下n开头的数据)
4.欢畅和欢乐,厕所和茅房同义词
5.意大利面——》西式餐点,牛排——》西式餐点 (根据你要做的事进行合并)
6.人/事/时/地/物:伊拉克——》国家,波斯湾——》地名
主词/受词代名词分析。

案例如下

前两篇是社会新闻,第三篇是娱乐新闻,第四五是国际新闻
中文分词:

词性标注:保留一些你需要保留的词性

英文比较特别:

英文本身就已经分词了,但是它有词性变化,把英文的词还原会圆形。
PorterStemmer方法:
Says——》say annies——》anni political——》polit
它只能还原成词根,但是会不认识该单词含义。
WordNetlemmatizer方法:
Support——》support
比较接近还原为原型,而不是词根。它能让我们看得懂。比较合适。
英语会自动标注。有很多系统
-
-
- 自然语言处理的应用
-
文字云、文件分类、情感分析、文件聚类、文章摘要
文字云:
又称“词云”,概念由美国西北大学1血副教授,新媒体专业主任里奇戈登(Rich Gordon)提出
文字云就是对网络文本中频率较高的“关键词”予以视觉的突出,形成“关键词云层”或“关键词渲染”,一般字体大的说明出现频率大,字体小的说明出现频率小,特别少出现的甚至不予显示,从而过滤掉大量的文本信息,使浏览网页者一眼扫过文本就可以领略文本的主旨。
可以说“文字云”是“关键词”的一种可视化呈现方式。
案例

和形状没什么太大关系。
喋血案:

我们一眼看过去一眼就可以看出效果。字最大表示出现频率最高
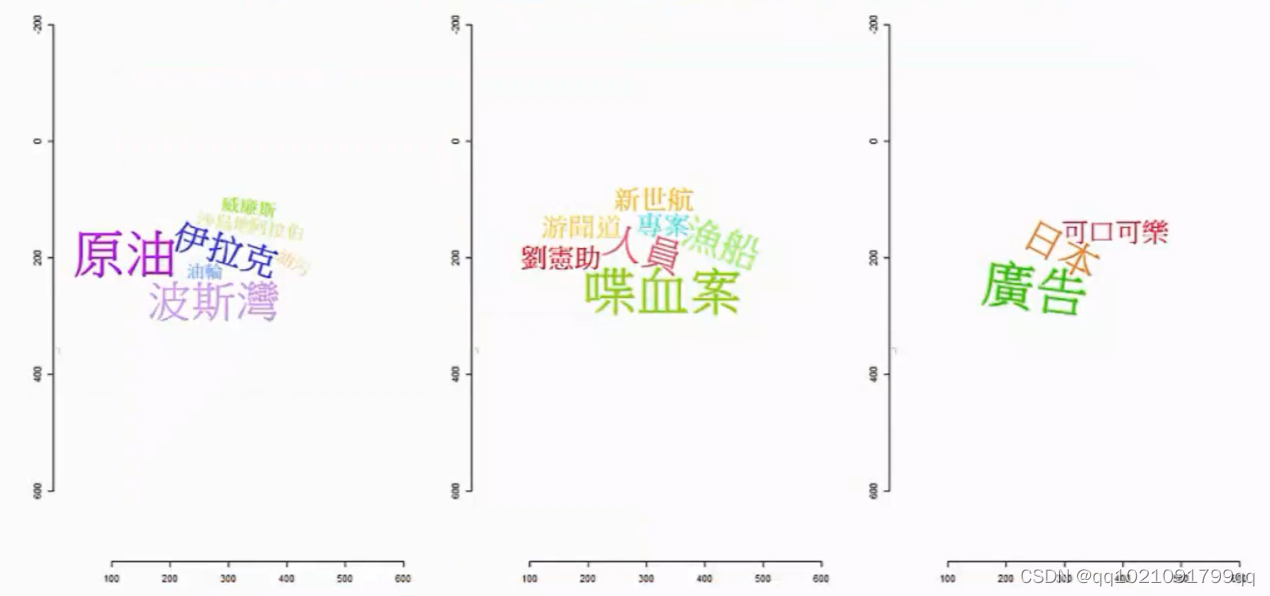
之前的文章作文字云图的效果。
文件分类:
用计算机对文本集按照一定的分类体现或标准进行自动分类标记的过程
案例:现在有100篇新闻,20篇是关于娱乐活动,20篇是关于国家新闻,60篇是关于社会新闻。我们就让计算机对它进行分类
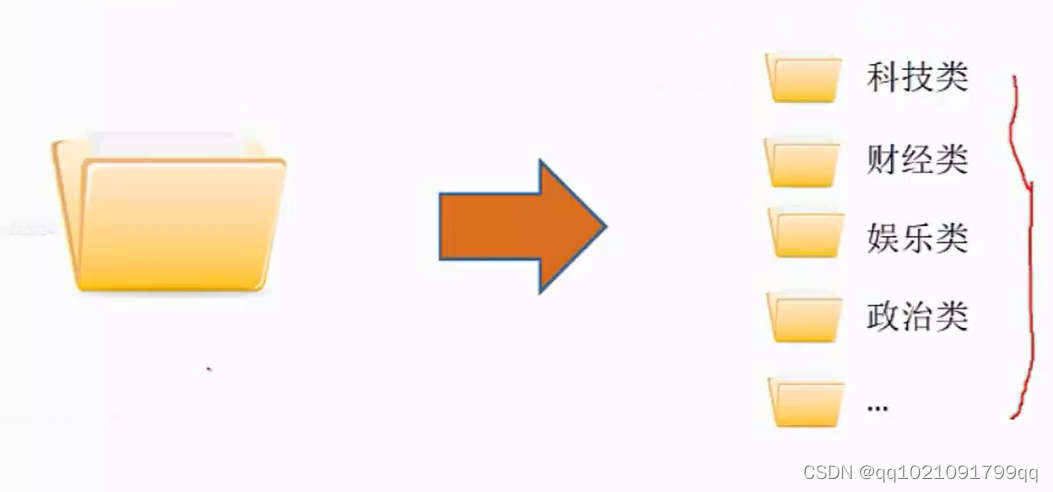
如果模型已经训练好,就可以直接进行慢慢的加以规律。
比较常见的就是做新闻的归类
有些人也会用这个进行垃圾邮件清理。
我们举例的都是新闻文本分类,但是其实也可以用到其他地方
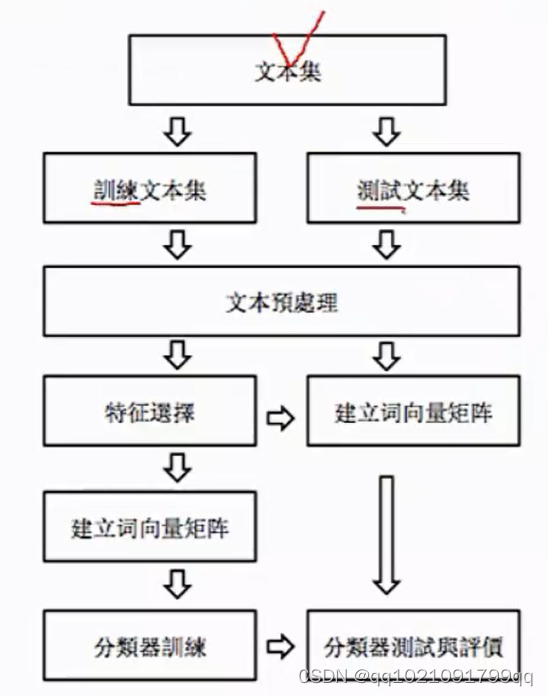
出现文本集,要分训练文本集和测试文本集,然后进行文本预处理(分词,词根转化。词性定义,词语同义,一般化等等,就是上面说到的。)
训练文本集要进行特征选择:因为字段,词太多了。把重要的词筛选出来。建立词向量矩阵,(对非结构化的数据变为结构化。)然后进行分类器训练。得到分类器
测试文本集也要建立词向量矩阵,然后按之前训练的模型得到的分类器进行测试,看看效果如何。就可以对它进行一个评价
这边只是说明一下框架之后算法的时候会具体说明。
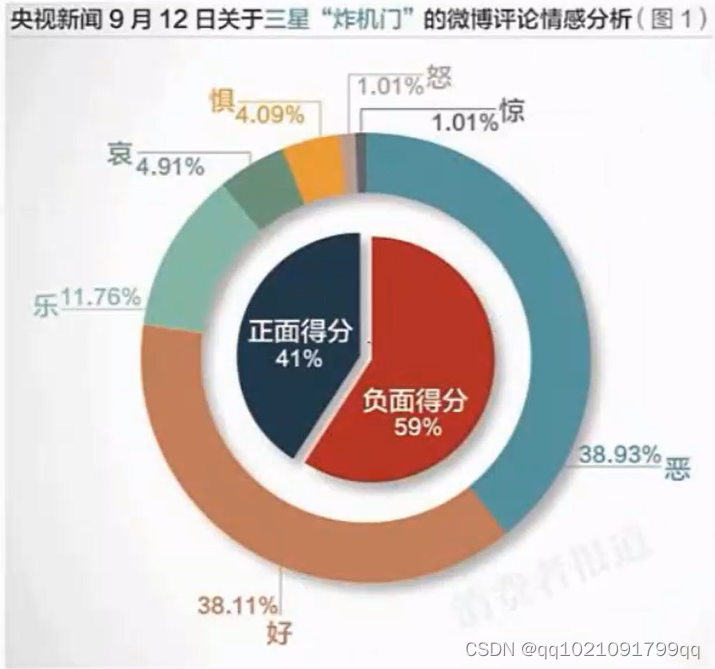
情感分析:
案例:有关三星炸机事件的评论。简单区分的话是可以只分为正面或者负面,但是也可以根据你的需求分的跟细致一些。
情感分类也是文本分析的一种
情感分析需要的输入内容:评价文本,sth
情感分析需要输出的结果:发布观点的人,评价的对象,观点的概括性。情感色彩和倾向性

完整的话是要把观点持有者和评价对象都做出来。但是正常情况做第三个评论观点就行,因为前两者难度也很高
情感分析的两种方法
情感词典(如果我们已经拥有这个词典就可以按照这个进行评分),
案例:
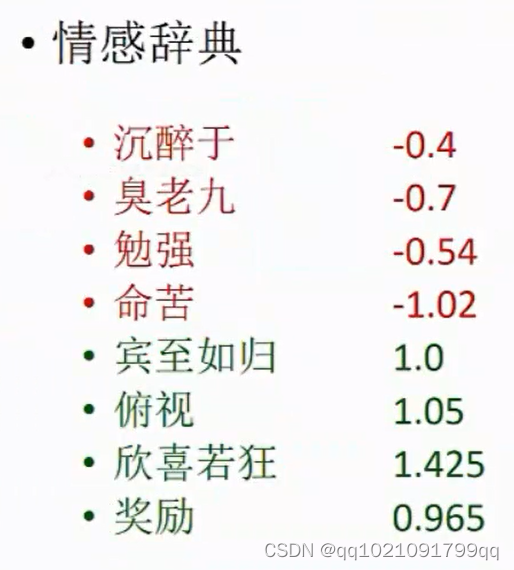
情感分类模型

加权投票,重复出现也得记入
然后显示概率。上面的就可以记入负面投票,概率3/4,也可以二者方法合并
文件聚类:
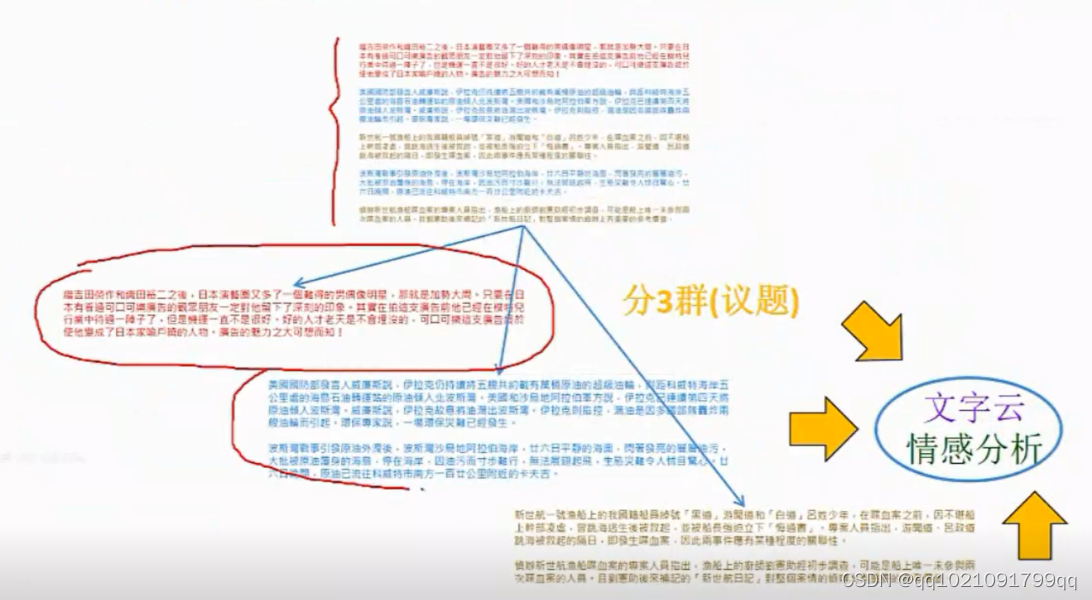
先根据文章的议题进行聚类。代表他们分别讨论的3个议题。根据每个议题,我们都可以对各个议题做文字云。可视化文字云。也可以对他们分别做情感分析。
比如公司今天收到100份投诉,投诉的是4个方向。就可以先聚类在进行
结合文字云,结合情感分析。
文章摘要
可能你文章内容非常多,我们就把文章的主题句(主要内容摘要)
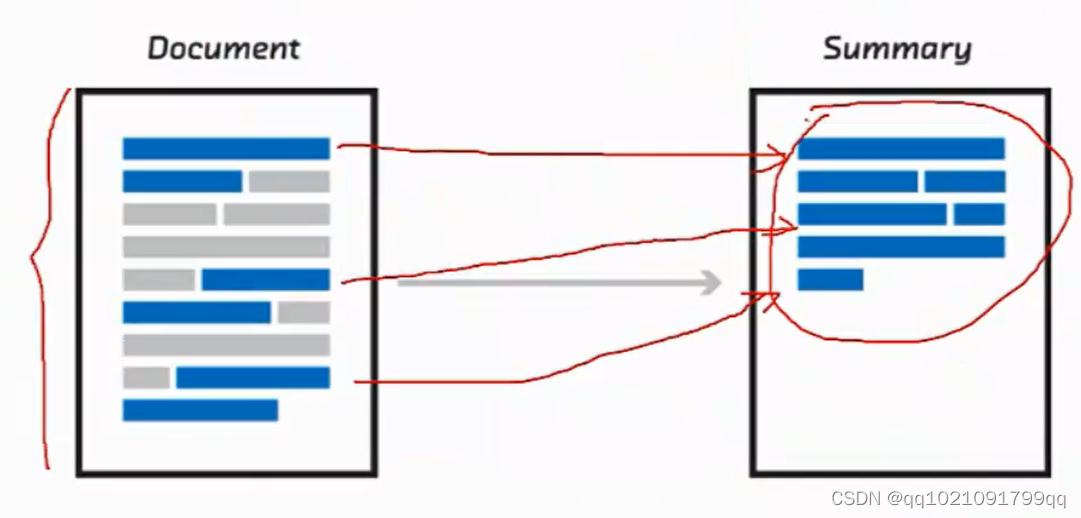
例如:假新闻的分类模型,把文章直接拿进去判断,错误率相对比较高。
如果我们把文章进行一个摘要,在进行分析,对模型的提升还是很大的。
而且因为这种分类模型一般都要用到机器学习,但是一般机器学习是很耗费时间的,所以我们就可以对它进行一个摘要后在进行学习。
时间缩短,准确率提高。
摘要画文字云和直接画文字云前者。会更清晰。
文章再要步骤
句子和文章结构化表示:
模型1:Bag of Words(BoW)不带有语义
模型2:Word Embedding(语义模型)带有语义
模型1到模型2,效果会更好。
文章摘要方法:
方法1:简单的相似度计算:
方法2:利用图论计算:
方法一:
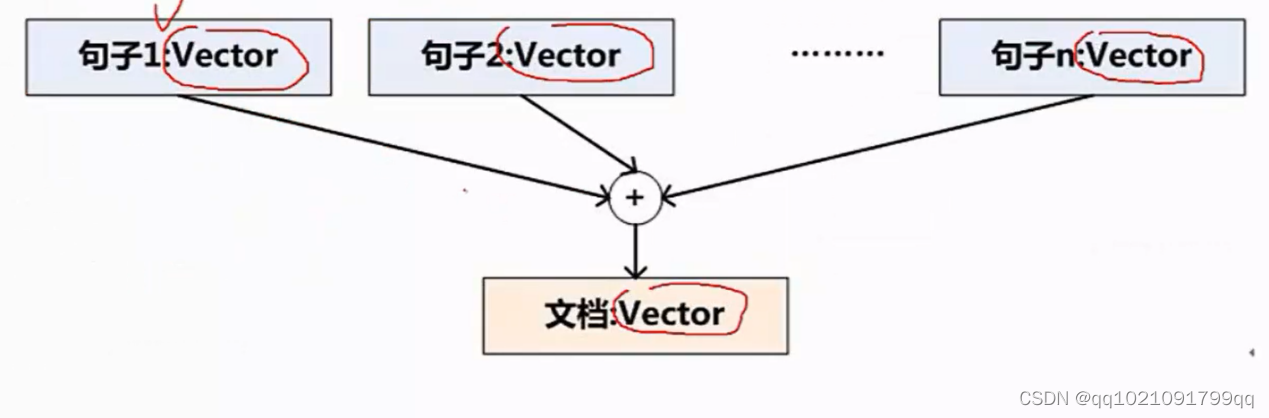
方法一是吧每句话进行结构化,然后把文章也结构化,筛选与文章相似度最高的句子,如果相似度最高那就是需要摘要的句子。
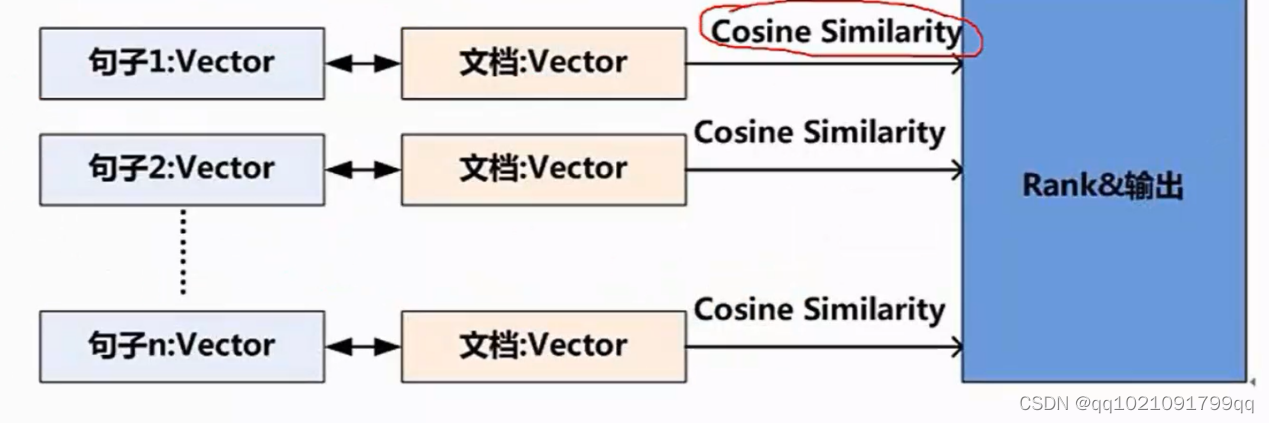
Cosine Similarity 是-1到1之间,越接近1相关性越大,负号代表负相关。
我们肯定要选正面相关。一般都不会有负数。根据句子相似度,进行排序,输出比较重要的几句
方法2:图论
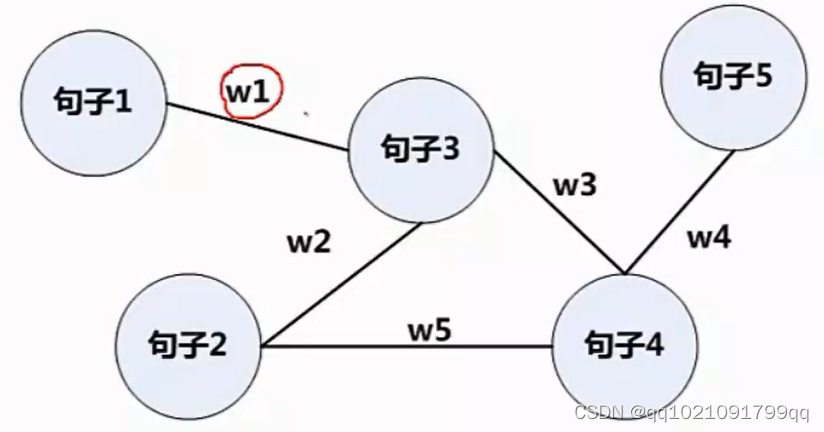
图论是考虑句子和句子之间的相似程度,之间的w代表权重。这个例子会选择句子3和句子4.
我们会用语义模型Word Embedding而不用TFIDF
因为假设计算机和电脑这两个词同时出现,那么TFIDF是不会计算相似性得分,但是按照WE就可以体现这种虽然字面不匹配,但是语义匹配的情况。也就是语义级别的相似性。
谷歌有一个PageRank是用来优化搜索引擎的,但是我们也可以用来提取句子相似性。
-
-
- 自然语言处理的平台
-
BOSON的中文语意平台
Bosonnlp.com(是阿里巴巴的产品了)
可以免费使用它的功能了
它具有利用python和java作为接口,进行分词和标注。的功能

它有22个大类,71个标签

API就可以直接进行词性标注。
也可以进行角色标定。
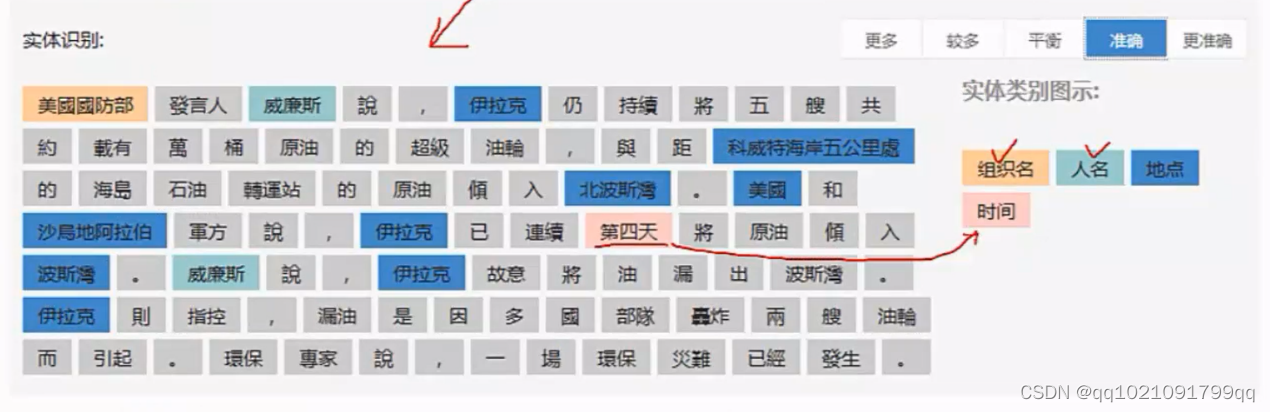
它也可以进行情绪分析
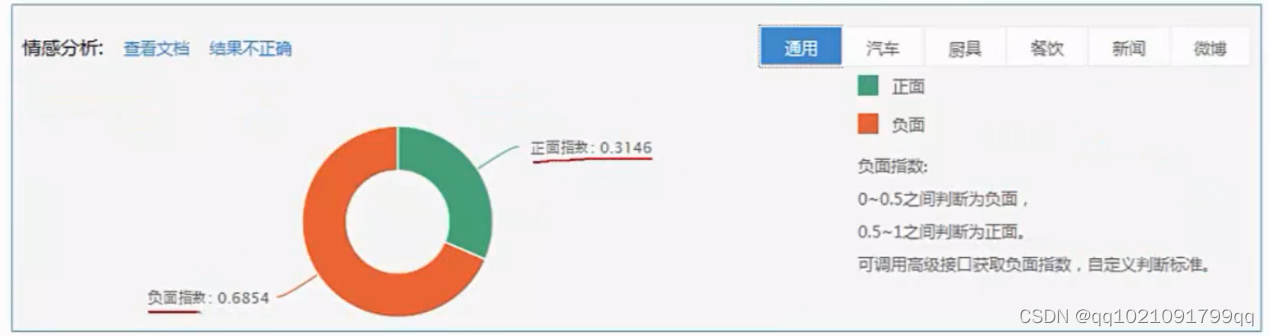
它有写好的情绪分析套件,我们可以直接套用。
文章摘要:

摘要不错。它文本分类也有误判的可能。
它的不一定是百分百准确。
关键词提取也可以做到:
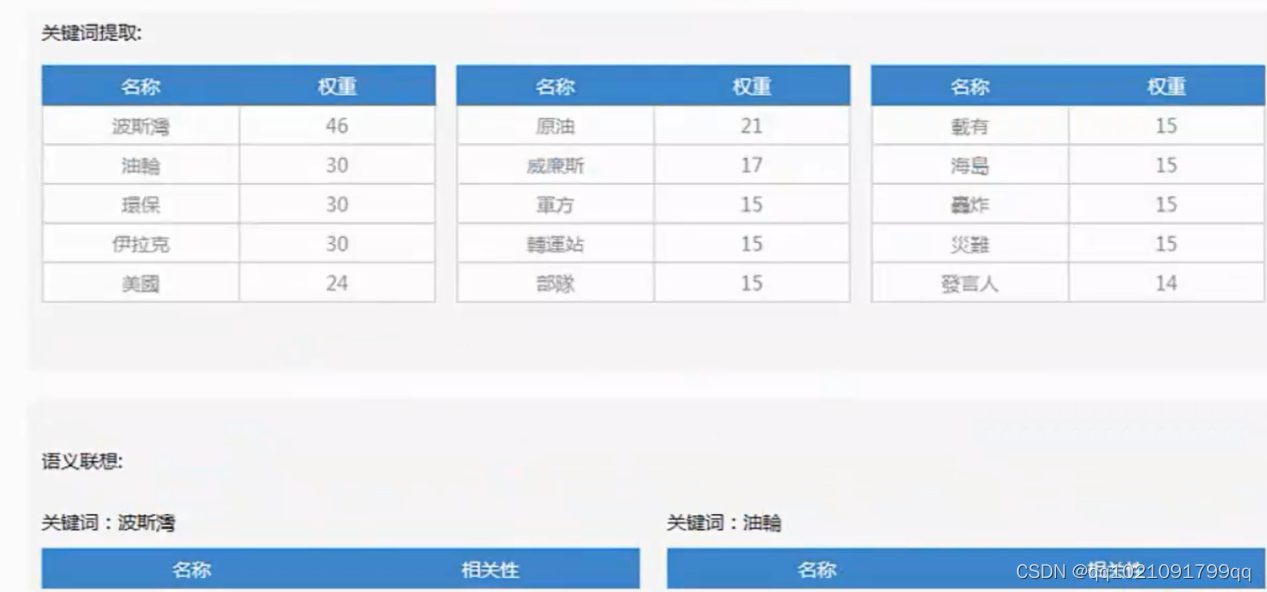
语义联想。
后面我们会说我们自己来做出来的方法,用别人的确实快捷,但是可能不好,我们就不能优化了。
SnowNlp的中文语意套件。
功能:
中文分词
词性标注
情感分析
文本分类
转化为拼音
繁体转简体
提取文本关键字
提取文本摘要
Tf,idf
Tokenization
文本相似性
这个是python的库。

分词效果,有些不太对,可能是因为它没有这个词,需要增加新词。

断句功能

情感分析:并返回正面情绪的概率

也可以直接使用它的结果,就可以少开发一个结果。

转拼音结果,有些繁体不支持

抽取文本的关键词。

年,米,外,宫,就不太好。
后面文章,我们会提到可以自己开发。

摘要结果。不太行。
出现次数,词的权重,文本相似性
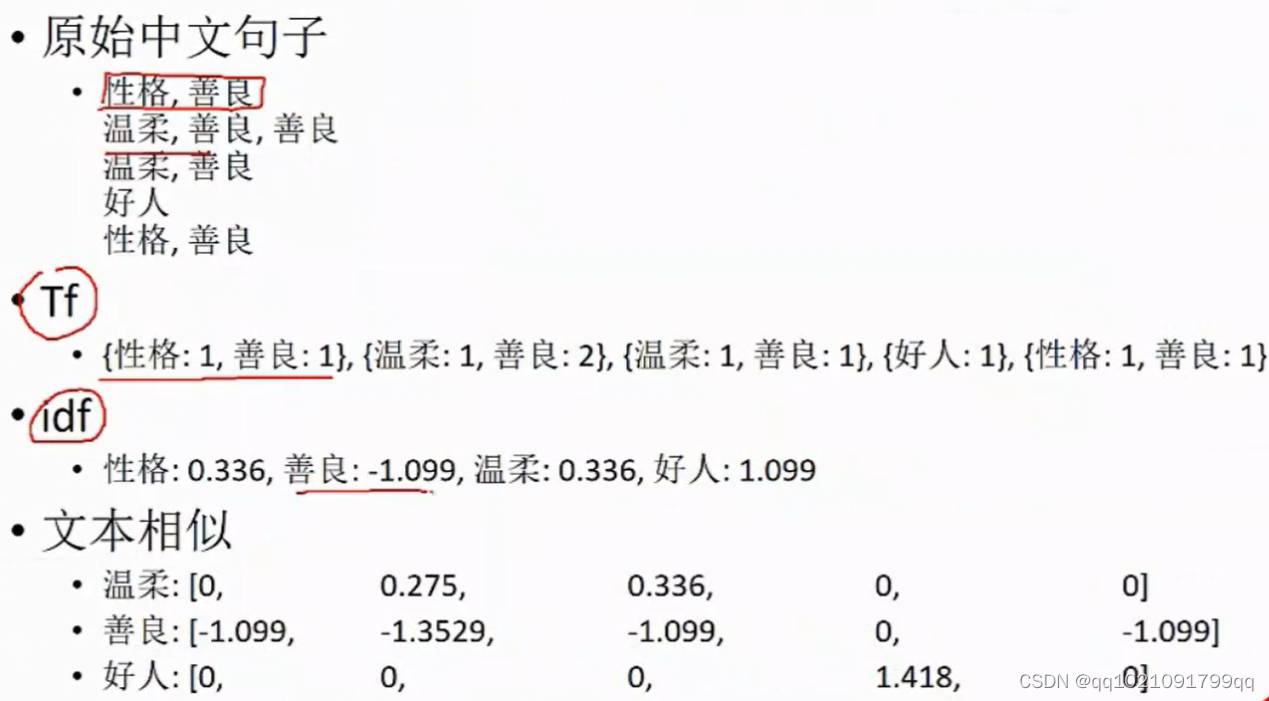
善良出现太多,所以不重要。
文本相似性后面我们也会实际代码制作。


