
- 1浅谈阿里 Node 框架 Midway 在企业产品中的应用实践
- 2debezium系列之:理解database.server.name和database.history.kafka.topic
- 3SQL语言的组成_sql中列和行的组成
- 4IPv6 基本首部、地址和过渡_ipv6首部
- 5sql学习之:mysql里关于update from_mysql update from
- 6申请Adobe Firefly权限保姆级教程_adobe firefly is not available in your region.
- 7C++实现大津二值化算法_c++ 二值化图片
- 8JMeter--后置处理器--正则表达式提取器
- 9SSDP_ssdp 协议中,tcp 1900
- 10SQL难点对比分析:IN 和 EXISTS 的用法对比_sql in 和 exsit的差别
通用大模型向左,角色大模型向右
赞
踩


引言:角色大模型,更像栩栩如生的人
以 ChatGPT、GPT-4 为代表的通用大模型正涌现出人工智能模型前所未有的智能水平,为最终构建通用人工智能(AGI)奠定了坚实的基础,让我们无限憧憬奇点时刻的到来。同时,在大模型技术的激涌潮流中,基于角色大模型的类人智能体技术(Humanoid Agent)的崛起也引起了广泛的关注 [1] [2]。
相较于通用大模型对智商的追求,角色大模型的研究者们专注于打造更加拟人化、具备强大共情力的角色智能体。这些智能体不再仅仅是冰冷的数据处理工具和问答机器人,而是各有人设、栩栩如生,宛如一位位良师益友。它们具备与用户建立深厚而长久连接的能力,为用户提供更加个性化、沉浸式的体验。

▲ Character.AI的“Books”类目中为用户提供了赫敏、哈利波特等耳熟能详的角色,和书中之人交谈不再是梦。
大模型技术的颠覆性发展使得角色深度个性化定制成为可能,正在为社交、游戏、影视等泛娱乐行业带来深刻的变革。在游戏领域,智能 NPC 的崛起使得游戏体验更加丰富,玩家可以与更智能、更具自主意识的虚拟角色进行更深层次的互动。
而在影视和网络文学行业,扮演 IP 角色的智能体使得用户心爱的角色摆脱原有情节的框架,在用户自定义的新场景中为其提供新鲜体验和持久陪伴。一些行业探索者,如 Character.AI [3] 和通义星尘 [4] 等,已经成功开发出初具规模的角色大模型定制平台。这些平台不仅提供数百个预定义的人设,还支持用户自定义全新的角色,给用户提供了更个性化、丰富多彩的虚拟互动体验,为下一代 UGC 社交内容平台的形态提供了丰富的想象空间。
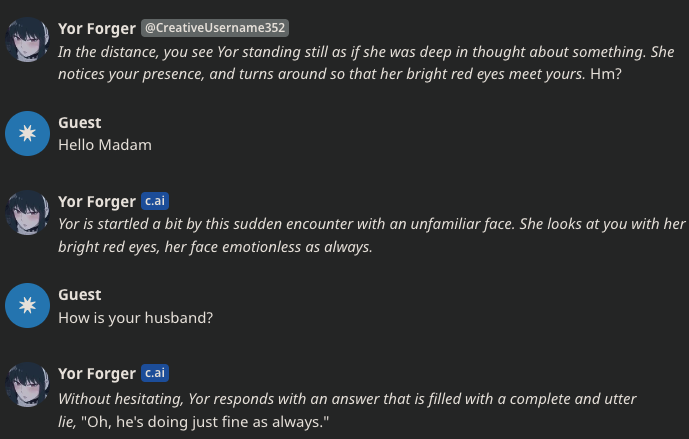
▲ 大热番剧《间谍过家家》的女主约尔太太,在Character.AI上对新用户还是像在剧里当刺客时一样高冷。
与强调问答的准确性、安全性,旨在构建“高智商通用助手”的通用大模型研发不同,角色大模型的研究更注重让模型“像栩栩如生的人”,立得住人设、陪得了用户。这要求模型不仅具备深厚的角色知识,保持一致的对话风格,还能够生动演绎角色的魅力,为用户提供充满新鲜感和情感价值的互动体验。对于角色模型所需的这些能力,国内甚至全球范围内尚缺乏系统、全面的评测基准。因此,角色大模型在训练和评测技术上面临着与通用大模型领域不同的独特挑战。
近日,在模型训练方面,百川智能的 Baichuan-NPC 和智谱的 CharacterGLM [5] 等在角色扮演领域的大模型研究工作,为业界带来了新的对齐技术;而在性能评测方面,RoleEval [6]、CharaceterEval [7] 等基准数据集的发布为系统评估角色大模型的角色一致性、吸引力、对话能力和性格测试等细粒度属性提供了丰富的资源。
本文将详细探讨这些角色大模型研究的最新进展,并通过在 RoleEval 与 CharacterEval 这两个基准上的评测结果,全面比较前沿大模型在角色扮演领域的性能。
值得注意的是,我们发现百川智能最新发布的 Baichuan-NPC 角色大模型,在其独特的“角色增强底座+角色思维链对齐”技术支撑下,在多个评测维度上表现出色,其中文角色扮演能力显著优于通用大模型的翘楚 OpenAI GPT-4 以及 MiniMAX、通义星尘等其他角色大模型,成为中文角色扮演领域的领先者。
据悉,百川智能不仅发布了角色大模型,还推出了包括角色创建平台、搜索增强知识库等配套生态体系,支持用户以零代码的方式轻松调试和部署角色大模型,为角色大模型的基础技术发展和产业应用做出了开创性的贡献。
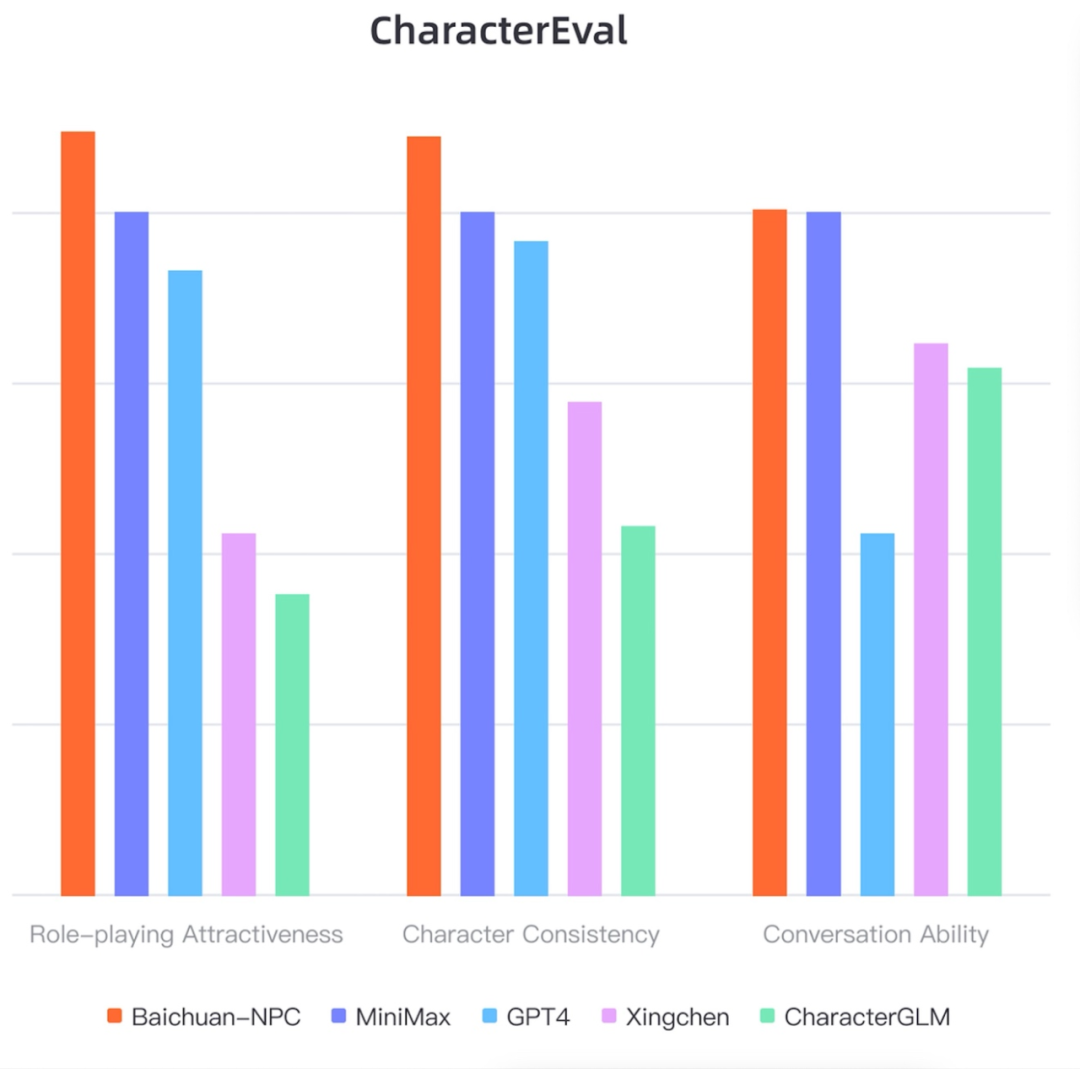
▲ 在开始正文之前,首先感受一下Baichuan-NPC作为最强中文角色模型的显著优势:在CharacterEval的对话能力、角色一致性、扮演吸引力三个维度都稳稳胜过GPT-4。

背景:角色大模型方兴未艾,急需评测基准与基础模型
在学术层面上,基于大模型的对话智能体(dialogue agent)可以被视为单个角色或多个角色的组合,采用角色扮演(role-play)的概念框架描述对话智能体的行为,有助于我们更精确地刻画、理解这些类人智能体的行为,并更好地开发挖掘它们的潜力 [1] [8]。
在应用层面上,角色大模型(role LLMs)指的是利用大模型模拟具有鲜明个性和对话风格的人物或角色,从而为用户提供比通用大模型更个性化、沉浸式的陪伴体验 [2] [9]。

▲ 角色大模型服务旨在满足用户定制需求,让模型做到“千人千面”,为每个用户扮演独特的角色。图片来自[2]。
在以 GPT 系列为代表的大模型崛起之前,AI 角色扮演已经引起广泛关注,微软的小冰机器人和 Replika 虚拟 AI 聊天软件等基于传统技术(规则系统和小型语言模型)的应用曾掀起过热潮。然而,由于当时语言模型的能力受限,这些类人智能体的对话流畅度不够,对角色人设的一致性保持也无法达到理想水平。
如今,得益于大语言模型涌现出的强大对话与推理能力,角色大模型(role LLMs)已经成为该领域的新技术基石,支撑了一批初露头角的个性化 AI 角色聊天平台。
例如,Replika 放弃了传统的规则系统,转而使用了 GPT-3 模型;Character.AI 由 Transformer 作者 Noam Shazeer 发起,自研角色对话大模型;通义星尘平台则基于通义系列大模型。这些平台都在该领域中进行了令人瞩目的探索,利用强大的大模型技术,提供了更流畅、更一致、更个性化的角色对话体验。
然而,与通用大模型领域相比,角色大模型的研发一直面临两个痛点:
1. 缺乏系统、全面的评测基准:通用大模型领域拥有多样的基准数据集,如 MMLU、BigBench、HumanEval 和 C-Eval,用于综合评估模型的各个方面能力。相较之下,角色大模型的能力评测一直缺乏系统、全面的公开基准数据集,这导致模型之间的比较缺乏明确的标准,也限制了快速优化和迭代的进程;
2. 缺乏专为角色扮演垂域优化的对齐技术和基础模型:通用大模型领域国外有 Llama 2 与 Mistral,国内有 Baichuan2-7B/13B 这样公开训练技术和模型权重的开源工作,然而,在角色大模型领域,尚未涌现出专门为该领域进行优化的公开对齐技术和基础模型。行业代表者 Character.AI 并未开放官方 API 和模型权重,而开源的 RoleLLM [2] 和 CharacterGLM [5] 主要是通过收集垂域数据对现有模型进行指令微调,缺乏解决根本问题(角色扮演一致性和吸引力)的新技术。

▲ 通用大模型的技术报告通常都有这种的雷达图“秀肌肉”,通过各个benchmark上的表现全方面展示模型能力(图片来自刚刚出炉的DeepSeek LLM的技术报告 [10]),而角色大模型领域尚缺乏这样全面、系统的基准数据集用于评测。
幸运的是,在我们所处的 2023 年底、2024 年初这个时间点,一些出色的工作填补了角色大模型领域的空白,为技术研究和产业应用提供了有力支持:
1. 在评测基准方面,2023 年 12 月发布的 RoleEval [5] 和 2024 年 1 月最新发布的 CharacterEval [6] 填补了角色大模型领域系统性基准测试集的空白,为全面评价角色大模型的能力以及后续迭代优化提供了方向和依据;
2. 在对齐技术与基础模型方面,百川智能于 2024 年 1 月 9 日发布了 Baichuan-NPC 角色模型。该模型在 Baichuan2-Turbo 优秀通用能力基础上,重点强化了“角色知识”和“角色能力”。针对角色扮演领域专门研发了对齐技术,如角色思维链对齐、强多轮对齐等。同时,百川智能还发布了配套的角色创建平台、搜索增强角色知识库等生态套件,为角色大模型领域奠定了坚实的生态基础。
在接下来的内容中,我们将分别介绍上述评测基准和 Baichuan-NPC 模型背后的前沿技术。最后,我们将以 RoleEval 和 CharacterEval 上的测试结果为基准,检视 Baichuan-NPC、MiniMAX、通义星尘、CharacterGLM、GPT-4 等大模型在角色扮演任务上的表现,并展望角色大模型未来的发展之路。

角色大模型哪家强:最新评测基准RoleEval与CharacterEval
在新近发布的 RoleEval [6] 和 CharacterEval [7] 之前,角色大模型领域首个较为全面的基准数据集是 2023 年 10 月发布的 RoleBench [2]。它的总体思路如下:
1. 指令收集:收集、清洗出一批高质量的角色扮演指令作为模型输入;
2. 自动生成回复作为标签:使用 GPT-3.5 或 GPT-4 API 对上述指令生成回复,将这些生成的回复作为 ground truth 标签;
3. 性能评估:对于要评估的新模型,使用其生成的回复与 GPT 生成的回复进行相似度比较,以衡量模型在角色扮演能力方面的表现。
然而,这种性能评估方法存在两个问题:
1. 模型带来的偏差:GPT 生成的回复不一定能很好地满足角色扮演场景的需求,越像 GPT 的回复不一定性能越好;
2. 缺乏细粒度属性的评估:该方法只能衡量整体上和 GPT 回复的相似度,无法充分评估角色一致性、吸引力等角色扮演领域特有的细粒度属性。
因此,在角色大模型的研发中,我们迫切需要更真实的 ground truth 标签和对细粒度属性的评估方法。RoleEval 和 CharacterEval 的发布填补了这方面的空白,为角色大模型的评估和迭代提供了支持。接下来,我们将详细介绍 RoleEval 和 CharacterEval 如何构建这些资源,以支持对角色大模型的评估和改进。
RoleEval:双语多方面角色大模型评估基准
RoleEval [6] 是天津大学等机构在 2023 年底发布的中英双语角色大模型评估新基准。一般来说,benchmark 类的工作主要包含数据资源、评测指标和对现有模型的系统评测这三方面主要贡献。下面我们来看 RoleEval 在这几方面的贡献。
在数据资源方面,RoleEval 收集了涉及中外 300 多位知名人物的 6000 条中-英平行多选题数据。它在人物类型方面的多样性相当高,覆盖了名人、动漫任务、影视剧角色、游戏角色、科幻角色等多重类型角色。同时,RoleEval 在问题的设计上注重多样性,旨在全面考察模型角色的基础知识和推理能力,具体涉及角色的个人信息、人际关系、能力和经历等多个方面。
下图直观地呈现了 RoleEval 在角色类型、知识类型、推理类型、角色影响范围、语言、问题形式等几个方面的多样性:
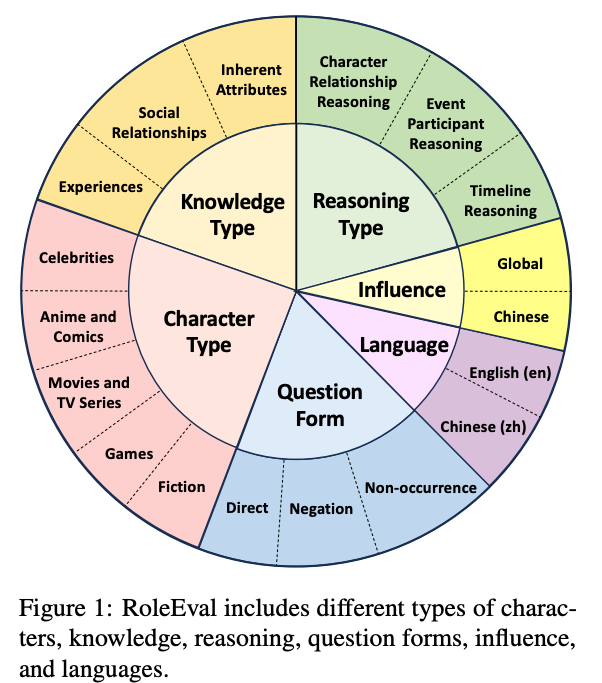
▲ RoleEval包含的角色、问题具有高度的多样性。图片来自[7]。
以下是 RoleEval 中关于达芬奇的一个问题示例:

针对 RoleBench 的 response 部分完全由 GPT 自动生成、可靠性不足的问题,RoleEval 在数据的生成上采用了自动(GPT-3.5 和 GPT-4 APIs)和人工相结合的方式保证问题的质量和数据收集的效率。具体来说,对最后纳入的某个角色 ,设 GPT-4 在和它相关的问题上准确率为 ,GPT-3.5 在和它相关的问题上准确率为 ,则 需要满足:

其中 、 分别表示 GPT-4 的准确率下限和上限(即该角色相关的问题不能太难、也不能太简单), 表示 GPT-3.5 的准确率上限(问题需要有足够的难度), 为 GPT-4 和 GPT-3.5 的 gap 下限(问题要足够有区分度,因为公认 GPT-4 强于 GPT-3.5)。
原文中取 来保证问题的难度和对不同模型的区分度。之后,标注者进一步人工检查了答案和选项以确保其质量。最后整个数据集包括 RoleEval-Global(具有全球影响的角色)和 RoleEval-Chinese(主要在中国具有影响力的角色),统计信息如下:
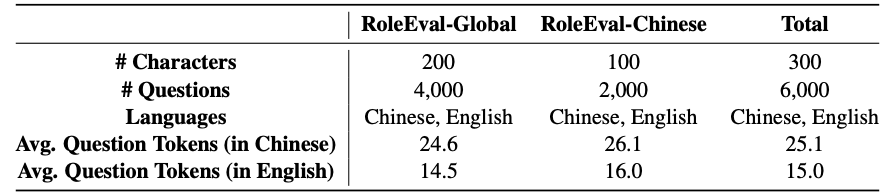
▲ RoleEval的统计信息
既然有了相对可靠的多选题及其答案标签,在评测指标方面,RoleEval 自然使用这些多选题上的 accuracy 作为评测角色大模型能力的指标。
在对现有模型的评估方面,RoleEval 的作者在 zero-shot 和 five-shot 的设定下对一系列中英文通用大模型做了详尽的测评。评估结果显示:
在 RoleEval-Global 上,闭源的 GPT-4 取得了最高的平均准确率,达到 72.38%,优于开源大模型中最优的 Qwen-72B(67.47%);
在 RoleEval-Chinese 上,开源的中文大模型 Qwen-72B 的平均准确率最高,甚至比 GPT-4 高出约 3.5 个百分点(66.20% 对 62.75%),显示出中文预训练数据对中文角色扮演的重要作用。
总体而言,RoleEval 以类似 MMLU 的多选问答形式评估了现有通用大模型在知名人物和虚拟角色方面的知识,具有高度的多样性和广泛的覆盖面,为角色大模型的评估提供了宝贵的资源。然而,RoleEval 也存在一些局限:
它主要采用多选题的方式评估模型,忽略了模型的生成能力;
它以 zero-shot 和 five-shot 的形式进行评估,输入中缺乏对角色的描述。因此,模型主要依赖于自身参数中的知识来回答角色相关的问题,与用户定制个性化角色的需求不符。在现实应用中,用户期望的是模型可以根据自己输入的人设、背景等属性构建属于自己的角色,而不是只能扮演已知的公众角色。
相较于侧重模型自身参数中角色知识储备的 RoleEval,下面介绍的 CharacterEval 更适用于评测角色类模型的扮演能力、表现能力,表现一致性,和 RoleEval 一起形成了完善的角色模型评测体系,为国内乃至世界角色领域大模型技术的发展提供了重要的基础资源。
CharacterEval:中文角色扮演对话细粒度评估基准
CharacterEval [8] 是由人大高瓴人工智能学院等机构在近日发布的中文角色扮演对话评估基准数据集。我们还是从数据资源、评测指标和对现有模型的评测这三方面来看该工作对角色大模型评测的贡献。
在数据资源方面,与 RoleEval 的多选题形式不同,CharacterEval 收集的是角色扮演领域的多轮对话数据,以更好地评测模型的对话生成能力。为了保证数据质量,CharacterEval 采用了 GPT-4 的初步生成并经过人工过滤的半自动模式。数据集中包含了 77 个角色、1785 次多轮对话数据,这些角色是从中文小说和戏剧中选取的。
此外,数据集还附带了每个任务的百度百科介绍,以模拟用户在个性化场景中输入角色设定内容。下图展示了包含《武林外传》中主角佟湘玉和吕秀才的一个例子:

评测指标方面,在考察的维度上,CharacterEval 构建了一个覆盖四个方面、十三种细粒度属性的评测系统,分别是:
对话能力:流利度、连贯性、一致性;
角色一致性:知识曝光率、知识准确率、知识幻觉率、个性行为、个性语气;
角色吸引力:类人度、沟通技巧、表达多样性、共情度;
个性测验:MBTI 测试的准确率(标签从网上收集的角色 MBTI 标签而来)。
一图概括如下:
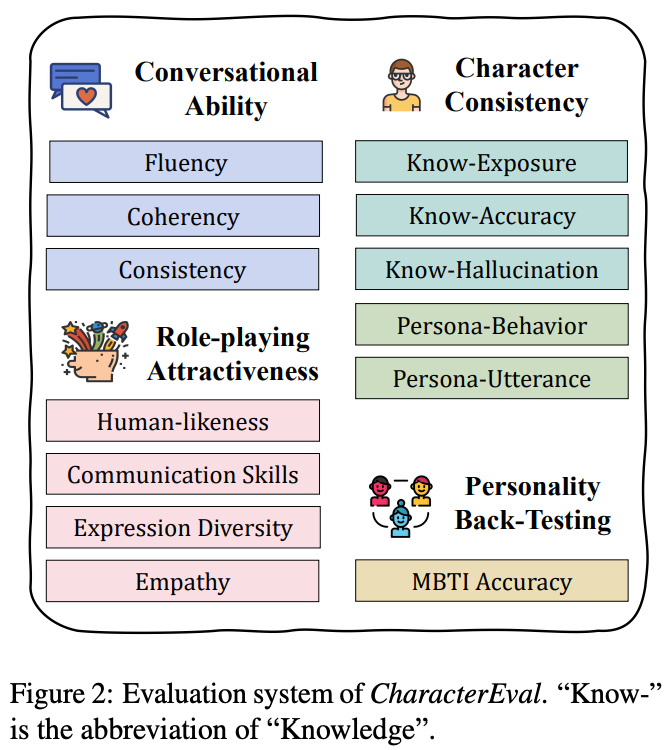
为了便利地评测其中主观性较强的属性,ChracterEval 的作者收集了人类标注的偏好数据,训练了名为 CharacterRM 的奖励模型,用于评测模型性能。实验证明,CharacterRM 的评分与人类标注的相关性比 GPT-4 的评分更高,从而提高了评估结果的准确性。
接下来,在对现有模型的评测上,CharacterEval 评测了三类模型:
开源中文通用大模型:ChatGLM3、XVERSE、Qwen、InternLM、Baichuan2 等;
闭源通用大模型:GPT-3.5、GPT-4;
角色扮演垂域大模型:BC-NPC-Turbo(即 Baichuan2-NPC 的一个主要版本)、CharacterGLM、Xingchen(通义星尘)等。
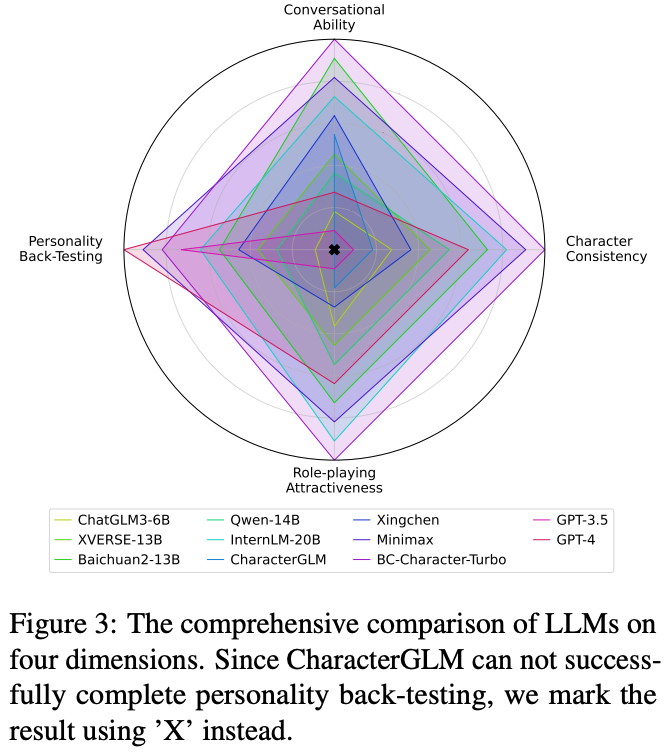
主要结果如下图所示,百川智能的角色大模型 BC-NPC-Turbo 在对话能力、角色一致性、角色吸引力等方面均领先于其他角色大模型和 GPT-4 等通用模型,仅在 MBTI 个性测验上略低于 GPT-4。
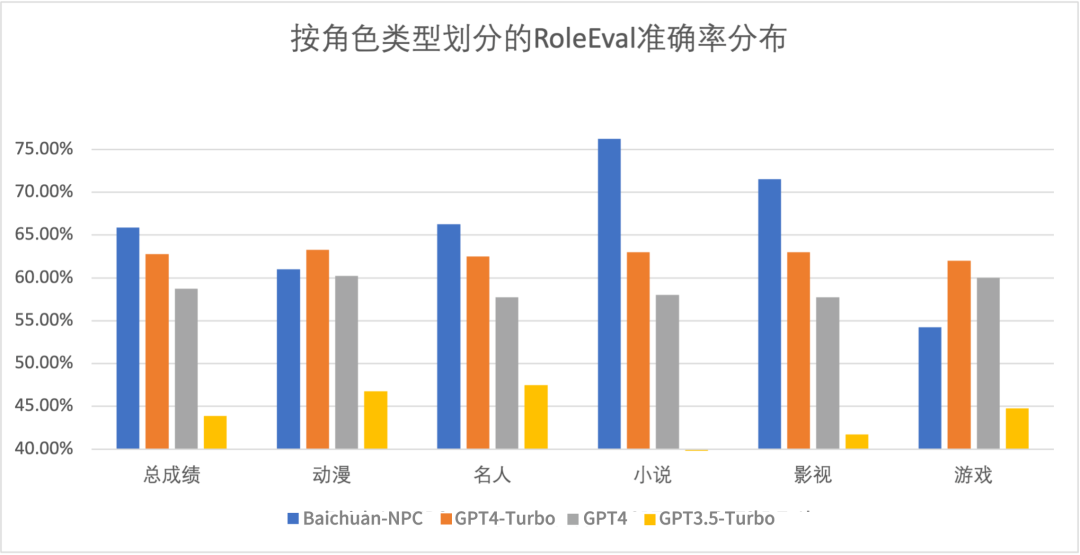
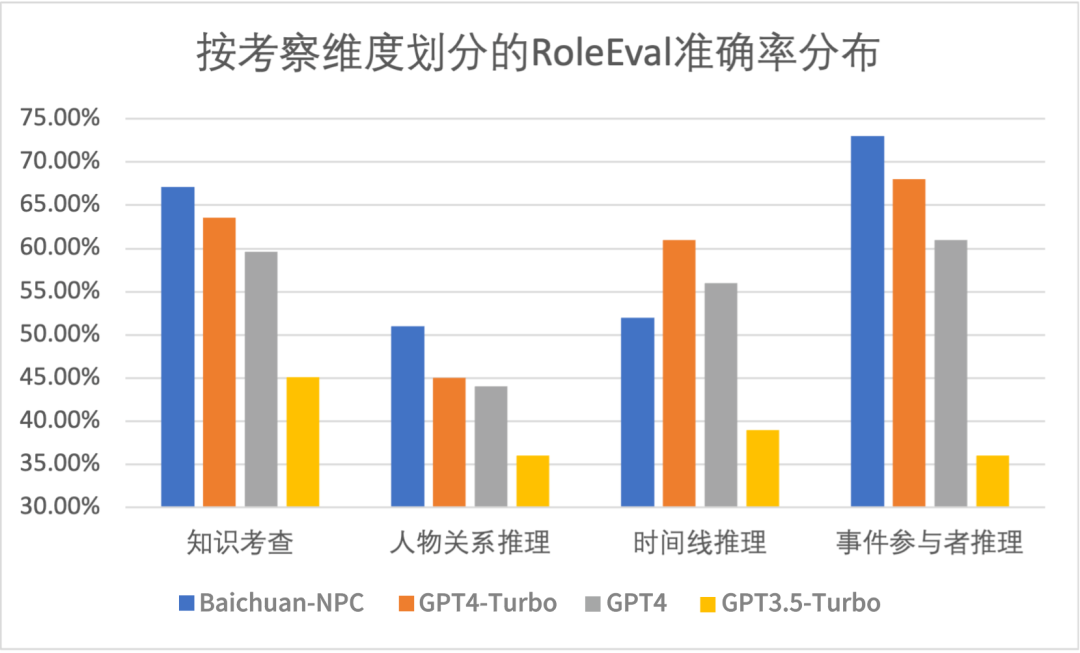
另外,由于 RoleEval 发布时百川角色大模型还未发布,我们也收集了百川角色大模型和 OpenAI GPT 系列在 RoleEval 上的表现,按角色、类型、考察维度进行了划分和可视化。我们发现 Baichuan-NPC 在超过半数的子集上都表现显著优于 GPT 系列,总成绩(平均准确率)比 GPT 系列中最强的 GPT4-Turbo 高了 3.1 个百分点。
综合 RoleEval 和 CharacterEval 的评测结果,我们可以断言,百川智能的 Baichuan-NPC 是目前最强的中文角色扮演大模型,显著优于 CharacterGLM、通义星尘等角色大模型和 GPT-4 这样强大的闭源通用大模型。
那么,百川角色大模型是如何取得这样的出色成绩的呢?据了解,百川智能团队针对角色扮演场景的需求,研发了“角色增强基座”与“角色思维链对齐”等创新技术作为 Baichuan-NPC 大模型的技术支撑,请见下文介绍。

百川角色大模型:融合"角色增强基座"与"角色思维链对齐",专为深度角色扮演精心打造
在百川角色大模型发布之前,有公开技术路线的 CharacterGLM [5]、RoleLLM [2] 等角色扮演垂域大模型主要侧重于数据方面的领域适应。它们将角色扮演视为一个普通的应用领域,在新收集的角色扮演指令数据集上直接对通用大模型如 ChatGLM、Llama 等进行微调。
然而,这些现有工作存在两个主要问题:一是所收集的角色扮演领域数据量相对有限,二是忽略了角色扮演领域特有的“身份扮演一致性”(角色言行不能偏离原有设定)等问题,仅进行简单的 SFT(有监督微调),过分简化了问题。
因此,百川角色大模型的研发者从通用大模型 Baichuan2-Turbo 基座出发,在基座模型预训练和对齐方面分别做了针对性的优化,大幅提升了模型的角色知识、对话能力、情节演绎能力和逻辑能力。
此外,百川的研发团队还基于 Baichuan-NPC 角色大模型构建了一个生态体系,包括模型 API、角色定制平台和搜索增强知识库套件等,为用户提供便捷的模型推理服务。这一全面而有力的组合,使得角色大模型能够更好地服务用户,真正实现生根落地。
基座模型优化:领域预训练+课程学习
鉴于基座模型预训练所用的通用领域数据可能未充分覆盖角色扮演相关知识,百川智能在预训练阶段从多个维度对底座模型进行了全方位的优化:
数据方面,研究员们搜集了大量来自行业网站、优质书籍和高质剧本的数据,对 Baichuan-NPC 进行了超过 3T Tokens 的领域知识预训练。此外,百川团队创新性地使用多方法模型合成数据进行知识增强,巧妙缓解了大模型潜在的 Reversal Curse 问题 [11],大幅度提升 Token 利用效率。相比 Baichuan2-Turbo 底座模型,这些优化使模型的角色知识能力提升 30%;
训练方面,为了解决领域继续预训可能导致模型基础能力损失的问题,百川智能提出了关注能力平衡的课程学习方法。该方法通过自适应地动态调控不同阶段的数据分布,精准控制通用领域和角色扮演领域的数据集比例,确保模型在基础能力和专业能力之间取得平衡。在经过该方法的优化后,Baichuan-NPC 相较于 Baichuan2-Turbo 底座模型,对话能力提升了 34%,情节演绎能力提升了 45%。
角色思维链对齐解决”身份一致性“问题
除了基座模型的能力之外,角色大模型在实际推理应用时面临“身份扮演一致性”的挑战。通用大模型往往容易在角色知识、背景常识、行为习惯、语气风格等方面出现 OOC(Out of Character,即行为偏离原有设定,如古代角色谈论现代事务)问题,跳出角色设定变回通用的“智能助手”人设或做出不符合角色人设的言行。百川智能的研究员们发现 OOC 现象主要来源于两方面因素:
1. 对齐目标不一致:大模型的 SFT 和 RLHF 等对齐过程往往以担任合格助手而非扮演特定“角色”为对齐目标,在推理过程中容易出现“助手思维”战胜“角色思维”的情况,即使经过角色指令数据微调,该问题依然存在。同时,由于不同角色领域跨度大、OOC 问题涉及维度广,传统对齐方法解决 OOC 问题容易带来模型效果的大幅度下降。
2. 模型思考能力不足,无法像人类的优秀演员一样真正“入戏”,把自己代入角色设定。
为了解决这些问题,受 Chain of Thought [12] 、ReAct [13] 等大模型推理相关工作的启发,百川智能首创将思维链对齐技术引入到角色模型对齐中。使用带有思维链的数据构造方式和带有思维链对齐的强化对齐方法,双管齐下让模型的思考过程和思考之后的行动表现更接近人类,大幅提升了角色一致性,显著增强模型的基础对话能力和角色演绎能力。
百川角色平台+搜索增强生成+强多轮对齐,零代码解决99%角色定制需求
得益于强大的领域预训练基座和思维链对齐技术,Baichuan-NPC 具备了丰富的角色知识和卓越的角色扮演能力,以霸榜 RoleEval 和 Character 的亮眼成绩拿下了中文角色大模型的桂冠。在学术评测之外,百川智能为用户提供了调用 Baichuan-NPC 进行角色创建的 API,并发布了一整套生态工具,包括角色创建平台和搜索增强(RAG)知识库。这为用户提供了高自由度、低成本、零代码的个性化解决方案。
此外,为提高角色定义自由度,百川智能还自研了强多轮对齐技术,强化了角色创建平台 System Prompt 在对话 Session 中的特殊地位,以保证模型生成的角色言行能够符合用户在 System Prompt 中定义的人设。

▲ 百川智能角色创建平台官网,提供大量官方优质角色,也支持用户零代码自定义和调试、部署个性化角色。
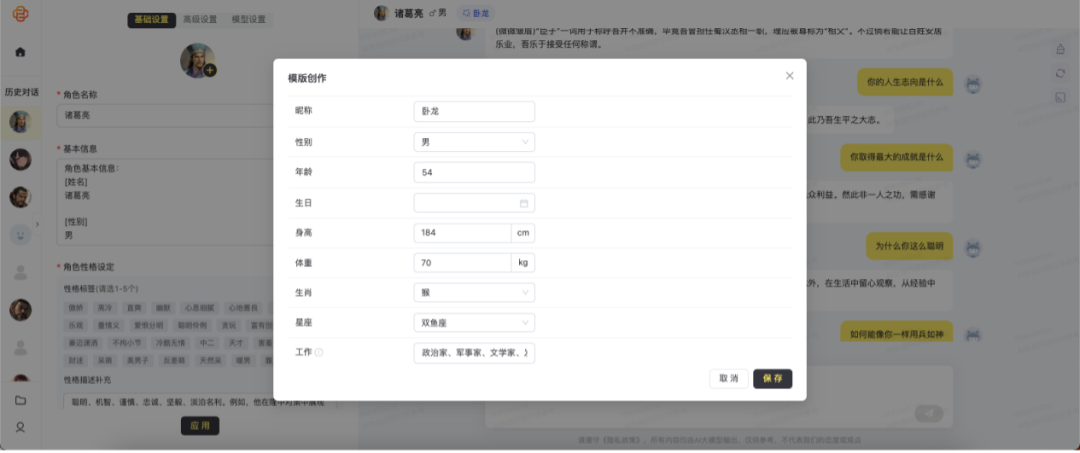
▲ 仅需简单的文字指令,用户就可以在百川角色创建平台上零代码创建角色,并进行调试和部署。
据悉,百川智能已经与众多泛娱乐行业的优秀品牌展开了深度合作,特别是在基于角色大模型的 AIGC 创作领域取得了显著进展。百川角色大模型已经在创梦天地、完美世界、爱奇艺等企业客户的场景中成功落地,其生成效果和响应速度都充分满足了业务需求,在大模型的产业落地上迈出了坚实的步伐。

总结与展望
角色大模型领域正风起云涌,Baichuan-NPC、通义星尘、CharacterGLM 等角色垂域大模型近日纷纷亮相,为下一代 UGC 内容平台的发展提供了广阔的创新空间。
面对“角色大模型哪家强”的问题,我们梳理了 RoleEval 和 CharaterEval 这两个较为全面、系统的基准数据集,发现百川智能的 Baichuan-NPC 大模型已经在中文角色扮演领域确立了领先地位。更令人振奋的是,该模型已经成功落地,将为国内游戏、影视等泛娱乐产业场景提供强有力的支持。
Baichuan-NPC的卓越表现源自其强大的预训练基座和专为角色扮演任务而精心研发的思维链对齐等全新技术。这不仅体现了百川智能在研发领域的卓越能力,也展现了他们在行业大模型落地方面的丰富经验。我们有理由相信,以 Baichuan-NPC 为代表的角色大模型将持续为各行各业需要个性化对话的应用赋能,为用户打造千人千面、栩栩如生的对话伙伴,为数字娱乐领域带来更为丰富、有趣且个性化的交互体验,创造更大的社会价值。

参考文献
[1] Shanahan, Murray, Kyle McDonell, and Laria Reynolds. "Role play with large language models." Nature (2023): 1-6.
[2] Wang, Zekun Moore, et al. "Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language models." arXiv preprint arXiv:2310.00746 (2023).
[3] https://beta.character.ai/
[4] https://xingchen.aliyun.com/xingchen/
[5] Zhou, Jinfeng, et al. "CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models." arXiv preprint arXiv:2311.16832 (2023).
[6] Shen, Tianhao, Sun Li, and Deyi Xiong. "RoleEval: A Bilingual Role Evaluation Benchmark for Large Language Models." arXiv preprint arXiv:2312.16132 (2023).
[7] Tu, Quan, et al. "CharacterEval: A Chinese Benchmark for Role-Playing Conversational Agent Evaluation." arXiv preprint arXiv:2401.01275 (2024)
[8] Shanahan, Murray. "Talking about large language models." arXiv preprint arXiv:2212.03551 (2022).
[9] Wang, Zekun, et al. "Interactive natural language processing." arXiv preprint arXiv:2305.13246 (2023).
[10] https://mp.weixin.qq.com/s/-I1a9du2pJBgJJ8ws6OxCg
[11]Berglund, Lukas, et al. "The Reversal Curse: LLMs trained on" A is B" fail to learn" B is A"." arXiv preprint arXiv:2309.12288 (2023).
[12] Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Advances in Neural Information Processing Systems 35 (2022): 24824-24837.
[13] Yao, Shunyu, et al. "ReAct: Synergizing Reasoning and Acting in Language Models." The Eleventh International Conference on Learning Representations. 2022.
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

