
- 1网络安全防范:如何防范内部安全威胁?_网传内参防范风险
- 2开源模型应用落地-解锁大语言模型的无限潜能,50家大厂面试万字精华总结
- 3关于H3C交换机使用时的一些常用的配置命令_arp max-learning-num 0
- 4STM32循迹小车系列教程(三)—— 使用灰度传感器循迹_灰度循迹小车单片机
- 5基于Spring Boot的二手交易平台
- 62亿数据量PostgreSQL 10.4查询调优思路分享_postgres 亿级统计如何做
- 7【c语言】归并排序_归并排序c语言
- 8SpringBoot2整合MyBatis_springboot2 mybatis
- 9CNN、LeNet_lenet和cnn的区别
- 10戴尔笔记本电脑Dell G7 15 7590原装出厂Win10系统恢复原厂OEM专用预装系统_戴尔原厂oem系统
OpenSearch向量检索和大模型方案深度解读_文档切片+向量检索+大模型生成答案
赞
踩
大家好,我叫邢少敏,目前负责阿里云开放搜索OpenSearch的研发,很高兴在此跟大家分享OpenSearch在向量检索和大模型方面做的一些工作。
基于向量检索的分布式智能搜索引擎
通常,数据大致可以分为结构化数据和非结构化数据两种类型。结构化数据的搜索问题我们一般用数据库来解决,非结构化数据的搜索,通常把它转化成向量检索的问题,例如图片搜索、视频搜索、语音搜索。首先把这些非结构化数据转化成向量,然后用向量检索的方式做搜索。还有一种情况,文本搜索也对应两种形式,可以用倒排索引的方式搜索,也可以用向量的方式搜索。

在大模型出现以后,越来越多的人开始使用向量检索的方式做文本搜索。所以现在来说的话,如果我们要做向量检索,通常把它作为大模型方案里面的一个知识记忆。OpenSearch在向量检索方面做的工作,也是以大模型的知识记忆为主要场景。
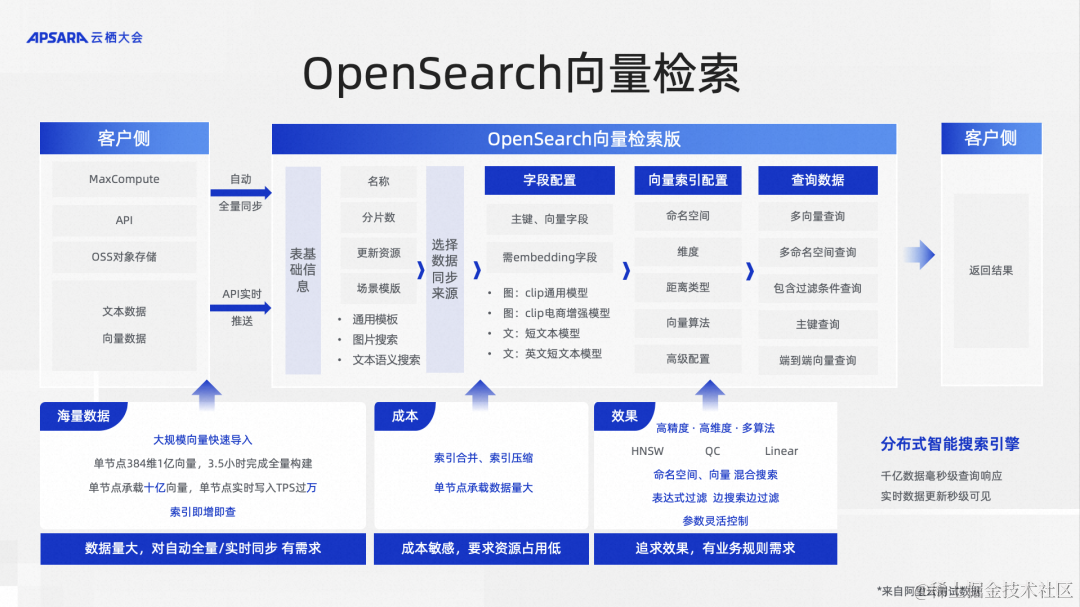
接下来我们看一下OpenSearch的向量检索大致流程,我们可以通过数据源或者API的方式把数据同步到OpenSearch,这个数据源可以是MaxCompute,可以是OSS,如果没有这种数据源,可以用API做数据推送,然后OpenSearch可以实时构建向量索引,构建完成以后,就可以进行向量检索。
我们支持几种算法,有图算法、聚类算法、线性算法(即暴力搜索的算法)。图算法的召回率比较高,性能也比较好,是最常用的。聚类算法通常用在海量数据的高性能检索方面,但是它的召回率比图算法会稍微低一些。还有就是线性算法,通常用来做一些少量向量的测试,或者如果生产环境向量很少的时候,也可以使用线性算法。
关于OpenSearch向量检索的性能,有几个数据可以看一下。第一个,它可以在一个4C32G的单节点上,支持10亿128维的向量检索。另外,在一个单节点上可以支持实时的上万TPS的写入。在索引构建方面,它可以在三个半小时左右的时间去构建1亿384维的向量索引。可以从这些具体的数据看出OpenSearch在向量检索方面的性能优势。
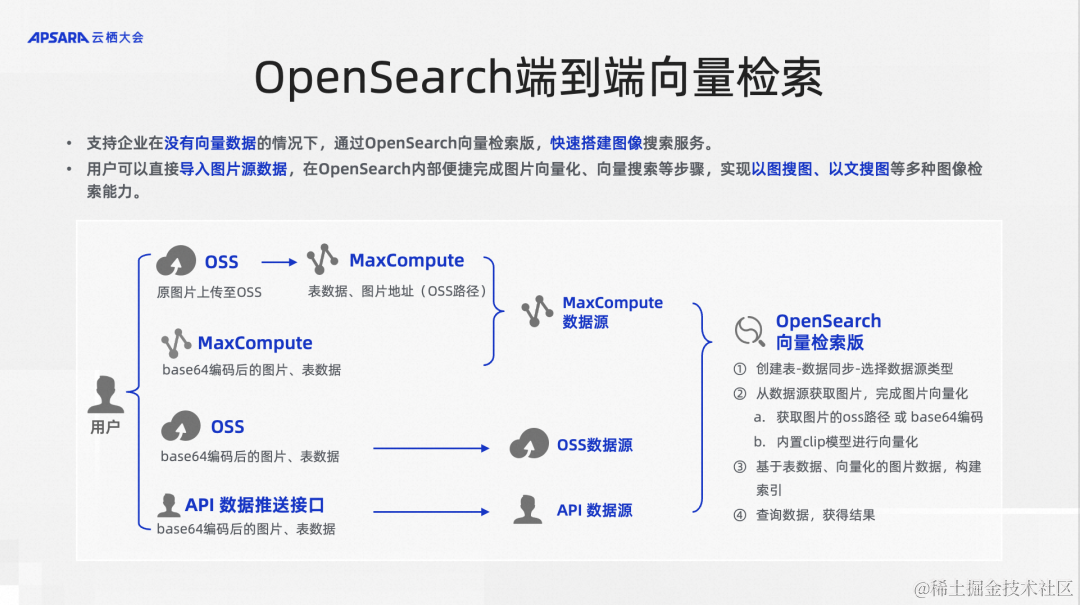
另外OpenSearch的向量检索是一个端到端的向量检索。因为通常情况下,我们用一种向量数据库做向量检索的时候,需要把数据在外部做向量化,比如在外部用模型把文本、图片做向量化以后,推送到向量检索的产品里面,在查询的时候也要把查询串做向量化。OpenSearch内置了向量化的模型,包括文本和图片的。用户可以把原始的文本和图片直接推送进来,由产品来帮助做向量化这一步,省去了客户的很多麻烦,是一个一站式端到端的向量检索产品。当然也可以选择在外部向量化,然后推送进来,这也是没有问题的。
工程、算法层面优化带来显著的性能优势
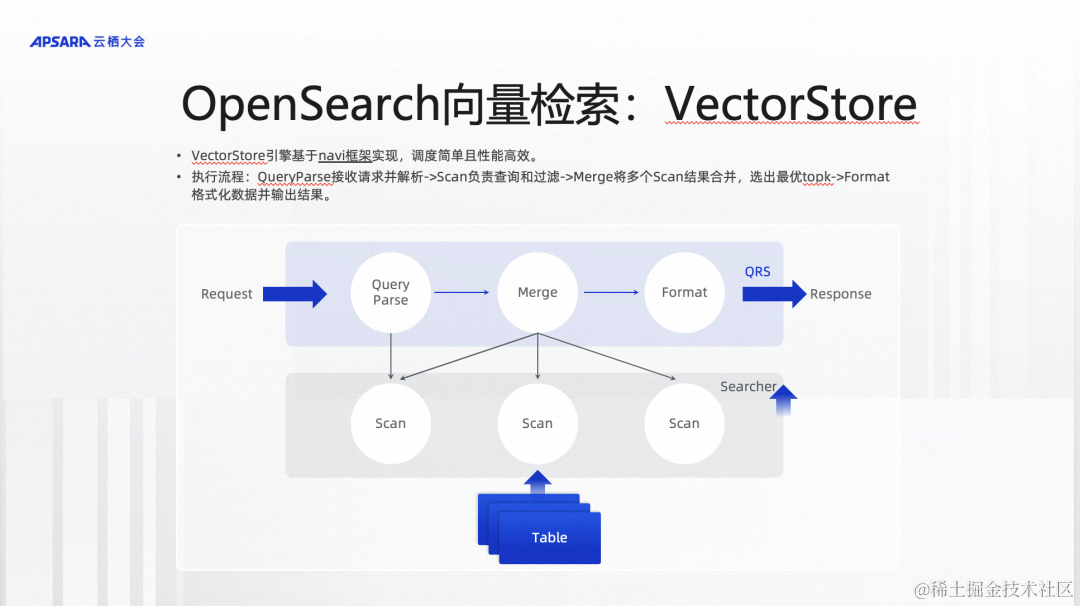
前面我们已经发布了VectorStore,它奠定了OpenSearch在向量检索方面的性能优势。那为什么会有这些性能优势呢?其实是由很多因素组成的,我在这里大概讲几点,一个点是在工程层面的优化,另外一个点是在算法层面的优化。
我们先看一下工程层面的优化。最近半年,我们对上一代OpenSearch的向量引擎进行了工程上的重构,主要做的事情是把原来很复杂的工程链路进行了简化,并且基于新的框架进行实现。另外还做了稀疏向量替代倒排索引的事情,因为我们之前做向量检索的时候,如果是做文本检索的话,实际上是离不开文本的倒排索引的。以前的时候,产品里面有文本的倒排索引,还有向量索引,需要合在一起做混合查询。现在,我们把文本的倒排索引彻底去掉了,然后用稀疏向量的方式来代替。这样的话,我们在内部实现的时候,只需要构建向量索引,不需要构建文本的倒排索引,整个内部的实现效率有一个很大的提升,在查询的时候,也有很大提升,主要是得益于工程框架的重构和优化。
在算法方面,也做了一些优化,刚才我们提到了三种算法,其中一个就是图算法的优化。图算法实际上是一种分层小世界图的检索方法,OpenSearch也是基于HNSW来实现的,我们主要从两个方面做了优化,一个是图的构建,另外一个是图的检索。从图的构建方面,是让图的构建的入度和出度更加均衡,有利于做检索。从图的检索方面做的优化,是用预测方法,减少在检索过程中需要遍历的节点个数来达到性能的优化。

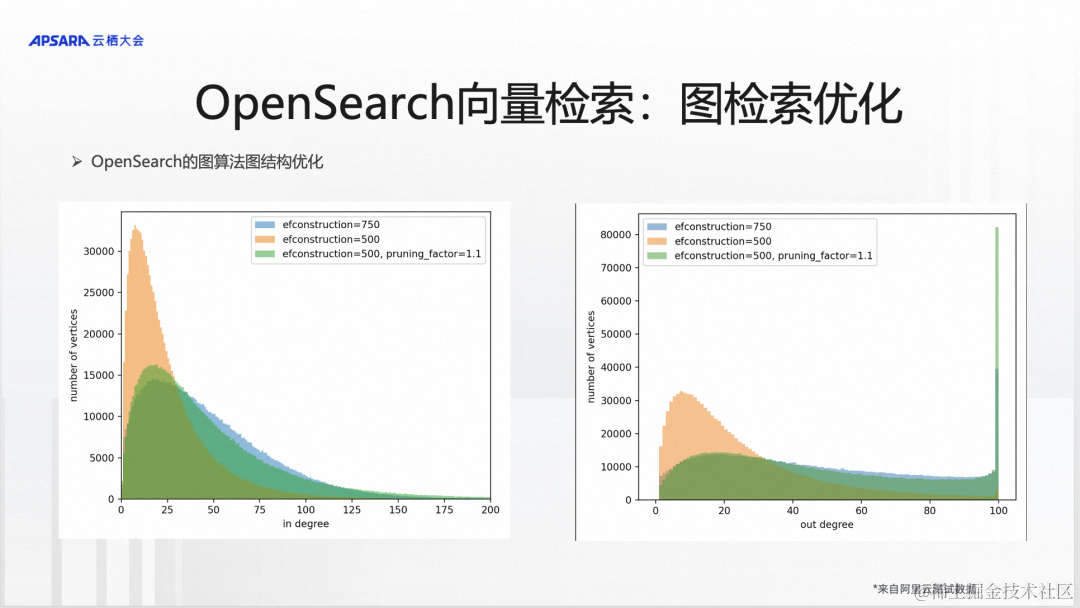
接下来我们具体看一下这两块的优化。第一块是图结构的优化,我们可以看到在图算法有一个ef construction的参数,这个参数是在建图索引的时候,需要去查看和参考附近多少个节点,这个可以简单的认为它是图的复杂度的一种衡量。当看的节点数量越多,建出来的图索引的质量越高,理论上,可以不断地提高这个参数的值,让图的质量越来越高。但是,这里面有一个问题,建索引的时候,要查看的节点数越多,建索引的成本就越高,索引构建速度就越慢,计算开销就越大。
所以我们引入了一种图裁剪的方式。这种裁剪策略进来以后,可以做到在不提升图的复杂度的情况下,仍然能够做到跟提高这个参数,达到相同的图质量的要求。我们可以看到,在这个参数值是500的时候,它是粉红色的,这种的话就是说它的图的入度和出度是不均匀的。这样的话,当我们检索的时候,它的效率是比较低的,如果把它的入度和出度做的均匀一些,就需要提高参数。但是引入了裁剪策略以后,不需要提高图的复杂度参数的情况下,能够做到和提高后(提升到750)差不多的能力,这样的话就会对整个图检索的性能有很大的优化。
另一个方面是在检索的过程中,去预测随机游走需要遍历哪些节点,不遍历哪些节点。经过预测以后会跳过很多节点,跳过了这些节点以后,检索效率会有大的提升。这块在两个数据集上做了一些测试,当然还有其他更多的数据集,因为有些数据集是内部的数据集,不方便展示出来。在Gist数据集上,可以有90%多的提升,在Sift数据集有20%多的提升,多个场景平均来看,整体性能提升大概能达到百分之七八十以上。
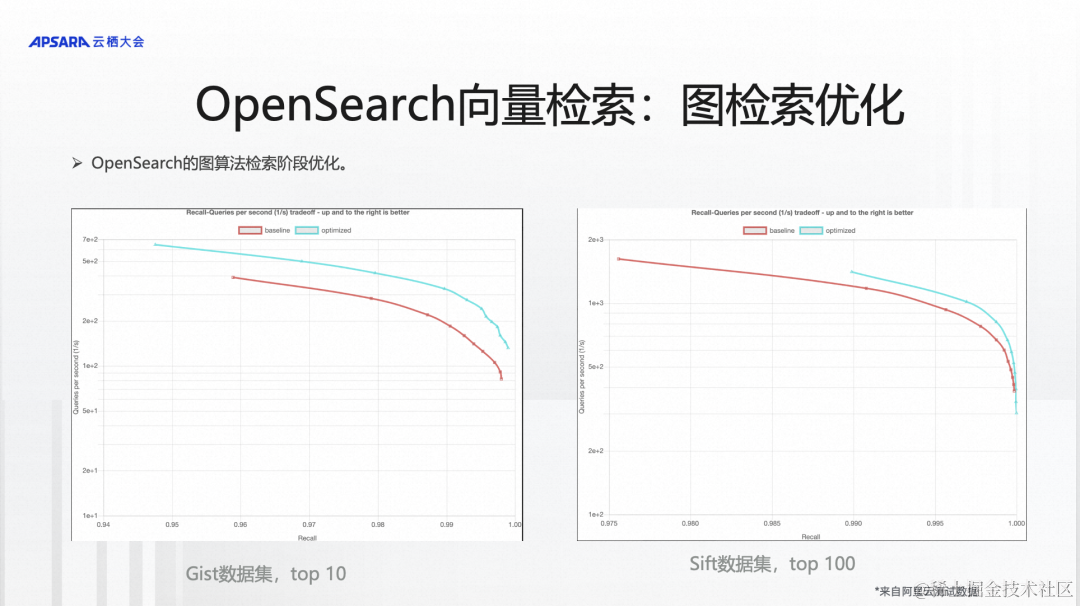
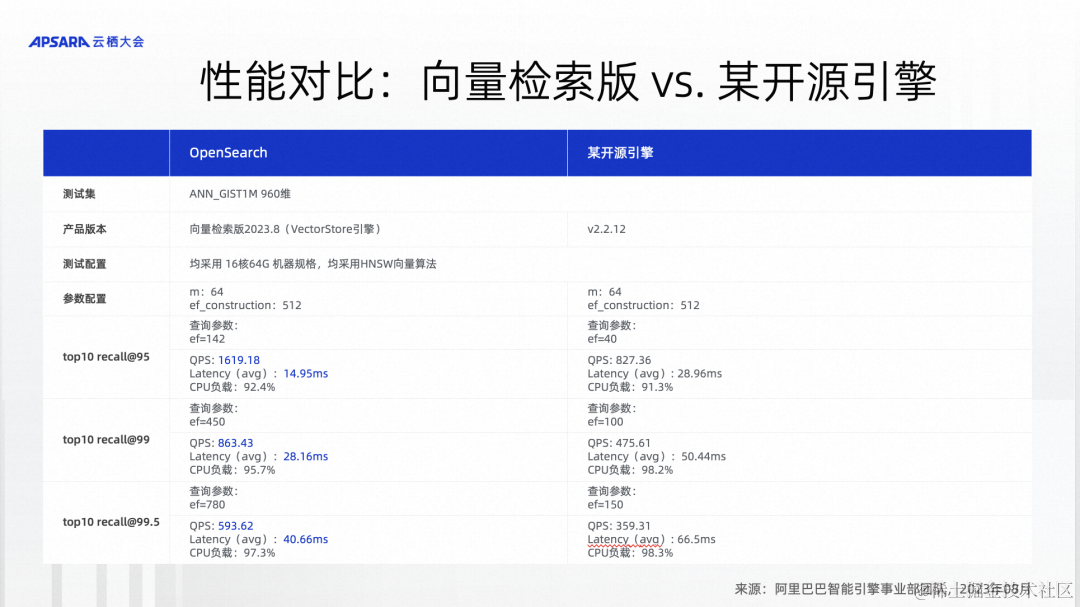
做了工程层面、算法层面的优化以后,我们也跟业界主流的开源引擎做了一些对比。在一个标准的数据集上进行了测试,设置的参数以及使用的算法都是相近的,可以看到Top10的数据在不同的召回率的情况下,基本可以做到两倍的性能优势。
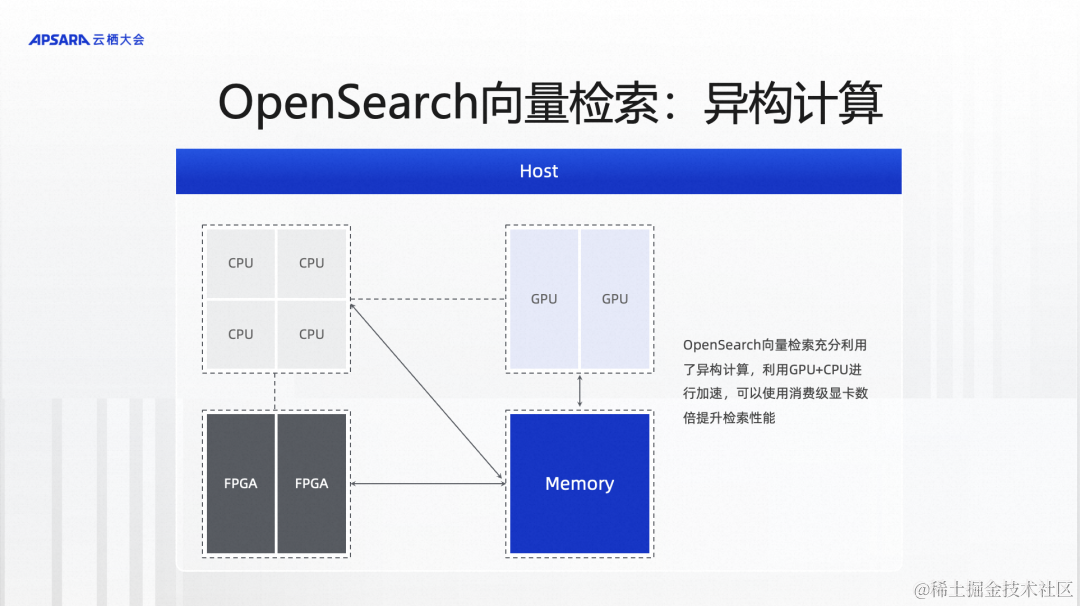
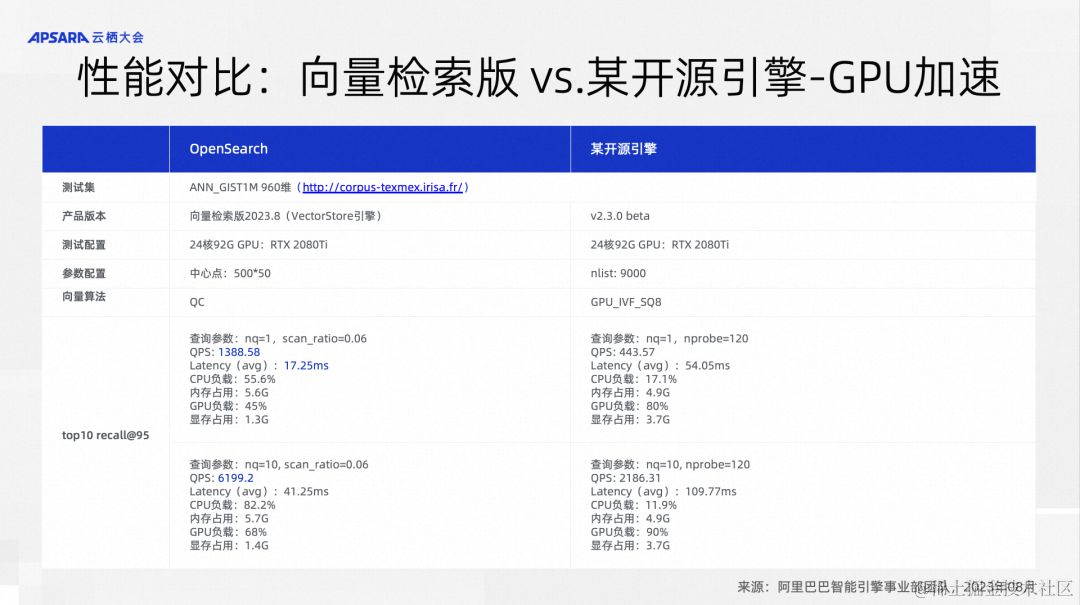
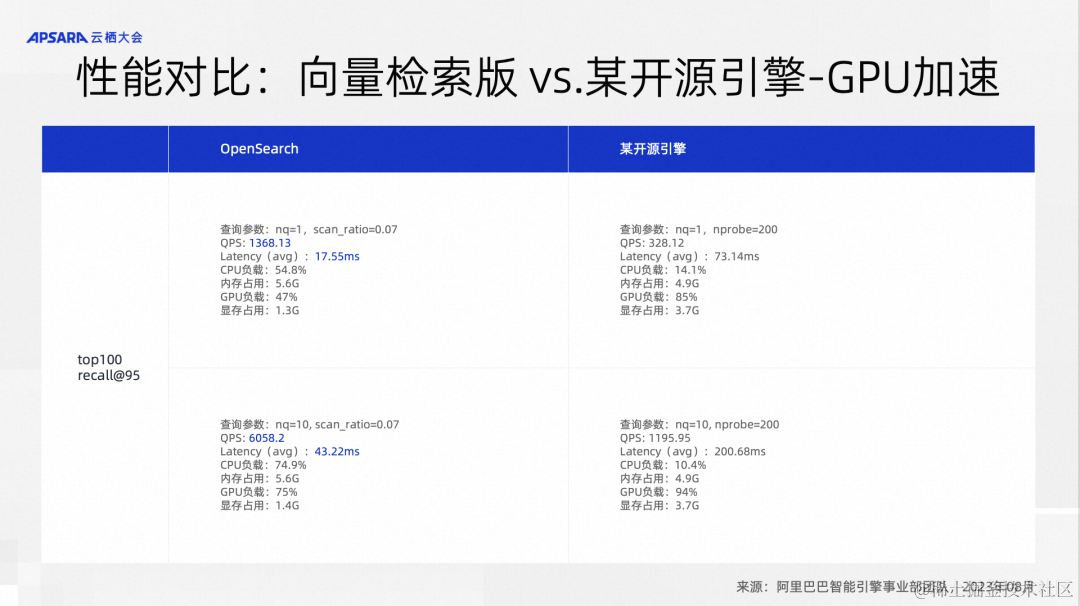
另外一个就是OpenSearch的向量检索在异构计算方面做的一些工作。我们在向量检索的时候,会把需要做的计算相对均衡的分配给CPU和GPU,这样的话就可以充分利用一台机器上的CPU资源和GPU资源,大幅提升向量检索的性能。我们跟主流的向量引擎做了一些对比,都使用同样的消费级显卡进行GPU加速,设置的参数以及使用的算法也是相当的,可以看到Top10的召回,性能指标QPS基本上是三倍左右,Top100的召回,甚至有6倍左右的性能。所以整体上,OpenSearch向量检索版的性能优势是非常明显的。
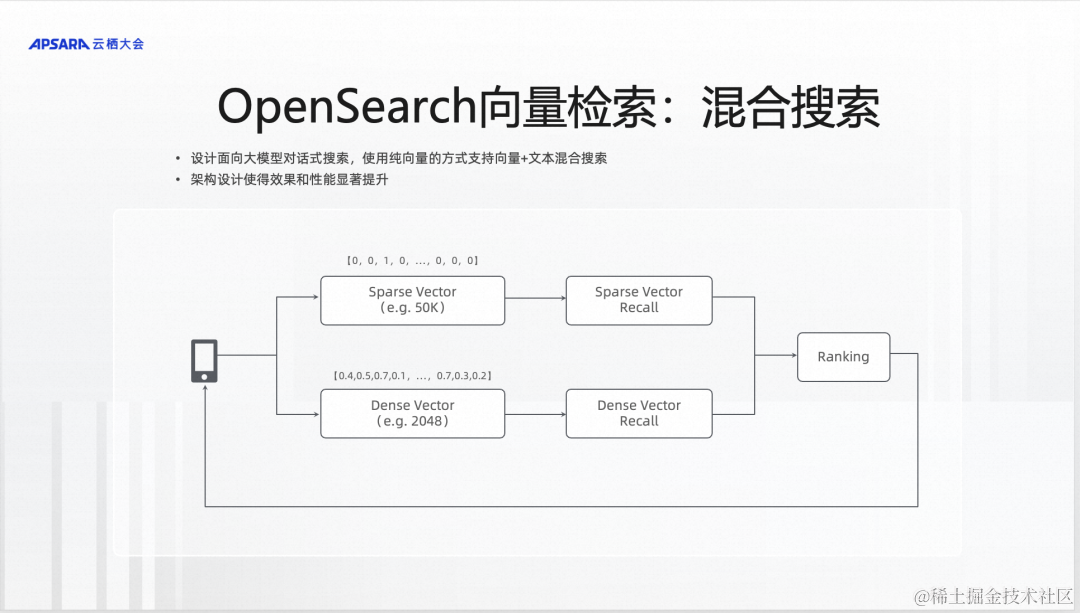
前面也讲到了,我们还有一个很重要的发力点,就是把向量检索作为大模型的知识记忆。我们把稠密向量和稀疏向量作为两路,稠密向量解决语义泛化的问题,稀疏向量解决文本精准匹配的问题,进行两路召回。召回以后,合并在一起给出结果。这块工作,实际上是为了适配大模型方案而做的改变,这块可以做到相比现有方案性能大幅提升,效果也有所提升。
向对话式搜索方向演进
接下来就是OpenSearch在大模型方面的工作。我们知道OpenSearch一直以来都是做搜索的,在大模型出来以后,OpenSearch开始向对话式搜索的方向进行演进。
对话式搜索,就是大家都知道的像New Bing这种用对话聊天的方式去搜索的搜索交互方式。除了前面介绍的一些场景之外,还有电商的咨询导购、内容的推荐、企业内部的知识库问答、教育的解题搜题之类的很多场景都可以使用对话式搜索。

OpenSearch在对话式搜索的落地路径是实现了OpenSearch智能问答版,这就是OpenSearch智能问答版给出来的解决方案。现在已经有像ChatGPT这样很好的大模型,为什么我们还需要一个这样的解决方案?因为像ChatGPT这种大模型,解决的是通用的知识问答的问题,他能拿到的数据都是公开的数据,没有办法拿到企业不公开的数据。当然,我们也可以和ChatGPT合作,把数据给他,定制出模型,然后来做这样的解决方案。但是这可能有一些问题,一是数据安全问题,二是法律法规问题。所以通常情况下,大家给出的解决方案是用像国内的通义这种模型去定制企业专属模型,在这个基础上,把它做成一个产品提供给用户做企业的知识问答。OpenSearch也是采用了这个方案,我们基于通义和开源的大模型做了智能问答的解决方案。

这是OpenSearch智能问答版的产品架构,可以把结构化的数据和非结构化的数据,还有其他的特殊数据,推送给OpenSearch,中间会有一些具体的数据处理。比如非结构化的数据进来以后,可能需要对非结构化数据进行内容提取,提取完了以后进行切片,然后进行向量化。而结构化的数据进来以后,做一些预处理后可能直接入库。入库以后,最终查询的时候,可能直接查出来结果。问答对的数据可能会进入模型的finetune。各种各样的数据进来以后,经过不同流程的处理会存储到系统里面,开始进行查询。之后,我会详细介绍整个技术架构。
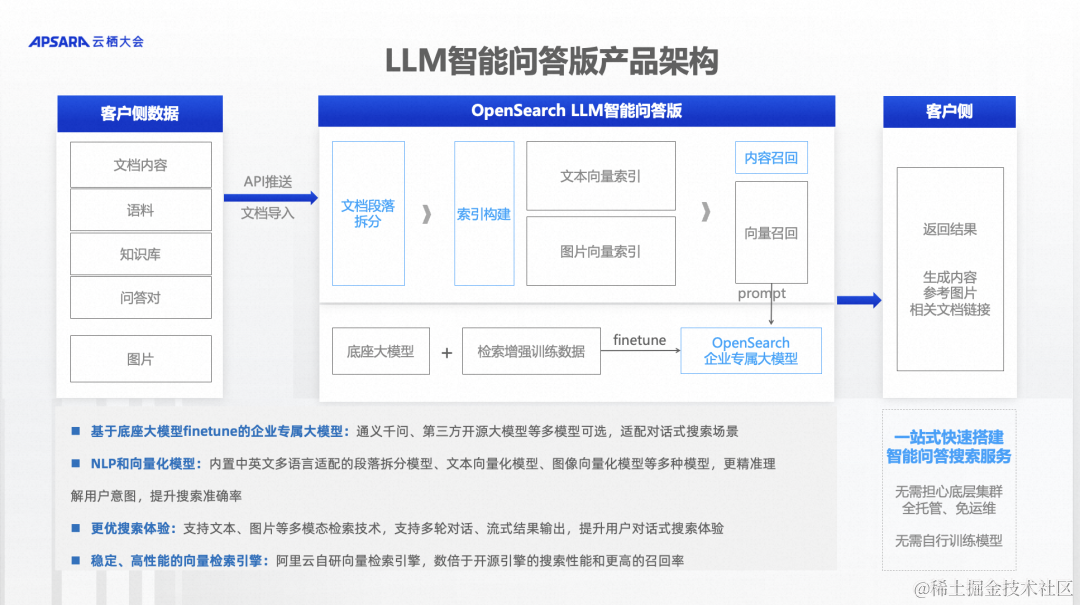
OpenSearch内置了通义和开源的多种大模型,这些模型是预先finetune好的,可以解决开箱即用的问题。如果这些模型满足不了客户的业务需求,比如客户的业务规则相当复杂,预制的模型达不到效果,我们可以用客户的数据做企业专属模型。这个企业专属模型是一个自动化的过程,不需要客户做太多的事情,只需要把数据按照特定的格式推送进来,整个内部流程是全自动化的,到了一定周期以后,这个模型达到了上线效果之后就会切换上来。
这个方案里的知识筛选,也是基于前面介绍的向量检索,使用的向量引擎也是专门为OpenSearch的智能问答对话式搜索的方案而做的,前面所介绍的性能优化都会在这个方案里用到。
接下来从技术架构的角度,详细看一下OpenSearch智能问答版解决的问题,以及技术的逻辑架构。
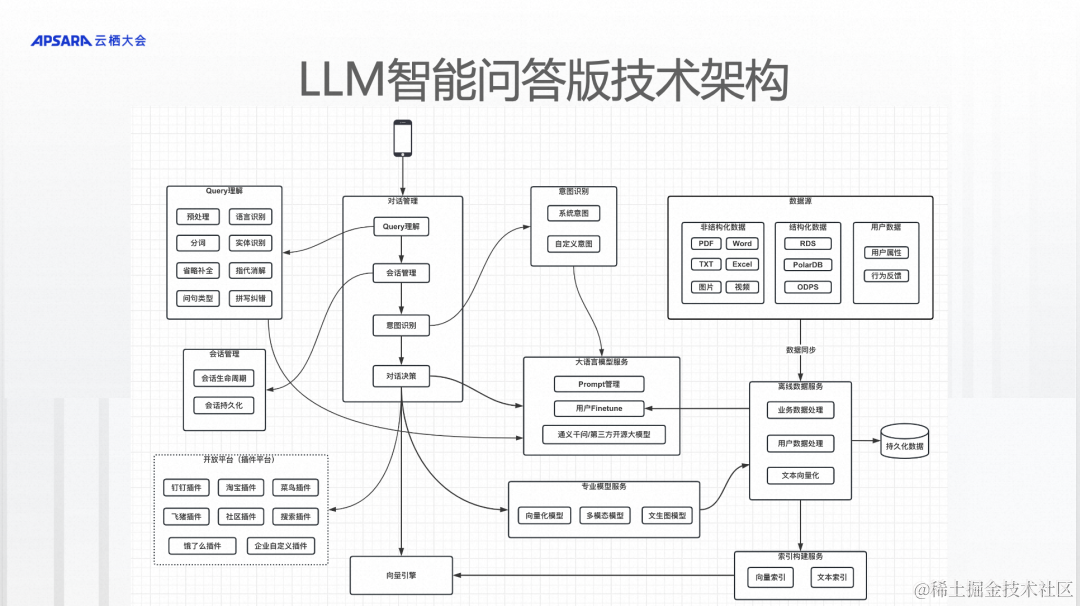
数据分为三大类,一类是非结构化数据,包括像Word、PDF、Excel以及非结构化的文本、图片之类的。第二类是结构化的数据,主要是一些数据库的数据,比如像MaxCompute里的数据。第三类是用户数据,包含两种,一种是用户的profile,我要知道这个用户是谁,因为有些问题回答的时候,需要根据用户的不同给出不同的答案。第二种是用户的行为数据,是用户对答案的反馈数据,比如给出一个答案或者搜索结果,用户觉得把这个答的好或者答的不好,或者用户给出的他认为的正确答案。
这三类数据进了系统之后,首先进入离线系统进行处理,非结构化数据先从PDF提取文本。如果是图片,需要OCR提取文本,提取出来以后,针对文本比较大的数据,需要按照逻辑结构进行切分,切分完后进行向量化,然后构建向量索引,这是非结构化数据的处理,其实就是非结构化文档的问答。结构化数据进来以后会做一些处理,处理完后直接入库,这是处理结构化数据。因为我们不知道用户要用什么,所以不同的数据做不同的处理,在查询的时候也会有不同的判断。用户的数据进来以后,像用户的行为数据和用户的profile,会和之前历史对话的pv log进行拼接,拼接完后形成完整的可用来训练模型的数据,用在用户专属模型的finetune上。
接下来是查询链路。当用户的问题来了,会做常规的query理解之类的工作,用大模型的方式来做,比如预处理、分词、纠错、改写、问题类型识别等。处理完后,需要保存获取这个问题的上下文,事先会把整个会话记录保存下来,这个会话表示了正在进行的主题是什么。之后做意图识别,比如用户当前的问题要用中文、英文还是用德文回答,问题是单轮的还是多轮的,这些做的是系统级别的意图识别。意图识别除了系统级别的之外,还有一些自定义的意图。因为需要把用户的问题进行分类,这些可能跟业务相关,比如客服场景,会分售前问题和售后问题,也可以分得更细。在分类完后,会做对话决策,针对不同的问题,会走不同的处理流程,如果问题是一个知识问答类的问题,那可能会直接做向量检索,从非结构化文档里寻找具体的切片,获取切片后走大模型的生成方式。如果问题类似刚才发布的SmartArXiv产品,问的是最近三年某个人在大模型方面的论文,会把它判断成需要从结构化数据库获取数据,把自然语言转成SQL后,从数据库把数据查询出来。返回结果的时候,可能需要生成一些图表。还有一种情况,有些问题过来以后,不需要经过大模型,而需要经过别的模型,比如多模态模型、文生图模型,那么对话决策就可以调用其他模型。
查询还有另外一个问题,如果解决知识问答的问题,这些流程就足够了,但是还有一类问题,就是企业自己的问题怎么解,比如要在企业内部做员工方面的问答,员工问我今年的年假还剩几天这类问题,这类数据没有办法从这个系统拿到,需要对接企业自己的系统。这块是用一个插件平台实现的,比如查物流的时候需要对接菜鸟,查商品,做商品推荐的时候要对接淘宝。企业可以对接自己的HR系统,当用户问我还剩几天年假的时候,如果系统知道这个用户是谁,就可以去HR系统查询,查询出结果后,经过大模型生成一个可读的答案。我们把这种能力直接开放给客户使用,客户可以把自己的业务系统对接过来,就能做企业内部业务场景,对接外部系统可以让使用场景从知识问答的领域拓展出去,可以做各种各样不同的场景。
OpenSearch智能问答版,首先默认情况下是一个端到端的产品,可以把企业自己的数据推送进来做企业的知识问答,其次,可以用高级功能在OpenSearch智能问答版定制出属于企业自己的产品。比如刚才发布的SmartArXiv论文工具,它类似Chat PDF,可以搜索推荐论文、读论文,这个工具就是完全在OpenSearch智能问答版上设计出来的。
我们可以看一下SmartArXiv,这个工具是怎么做的呢?他首先在OpenSearch申请一个实例,然后把ArXiv论文数据库直接对接到OpenSearch上,但不会把数据同步进来,只是有一个接口要对接上就可以调到ArXiv。用户的问题来了以后,就会在OpenSearch做分析,比如要查最近几年哪方面的论文,就会转换成SQL做查询,查询完后就会出论文的列表,经过一些处理,在设计的网页上用API对接,在网页上展示出来。还有一种情况是问论文里面讲了什么,这时就不会把它转成SQL,而是针对论文做大模型的总结,然后把答案直接返回给用户。
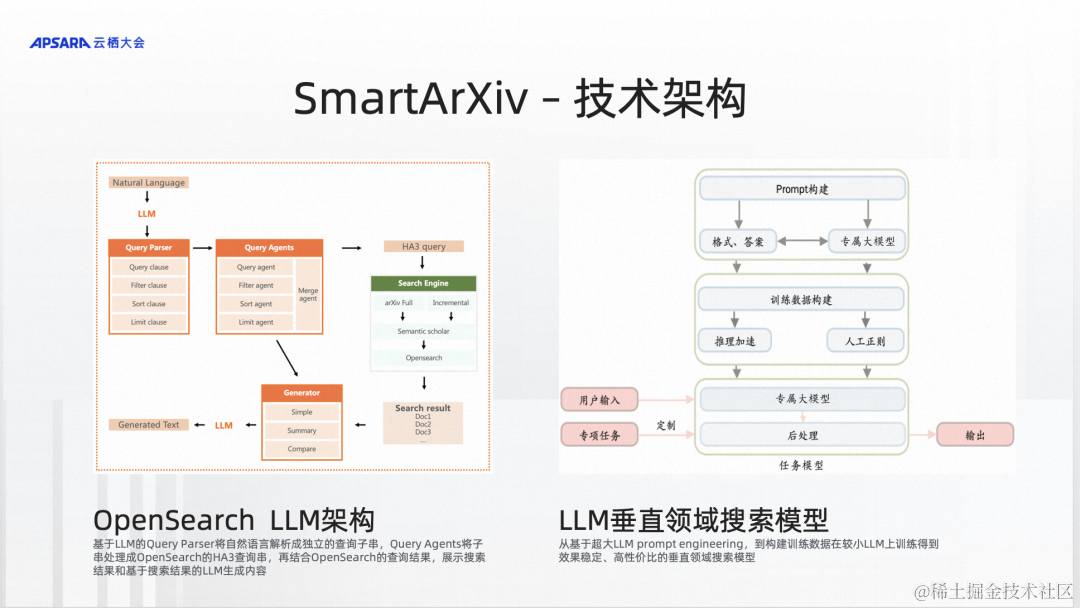
所以当一个问题来了以后,到底需要做什么样的处理,这完全是基于OpenSearch的意图识别来分清楚它的意图,然后做不同的处理。而这些流程是怎么做的,是SmartArXiv在OpenSearch里设计和配置出来的。
我们在做端到端的产品的同时,也在做一种对话式搜索的生态,希望不同的客户都能在这个平台上设计自己的对话流,定制自己的模型,把自己的数据传上来后做各种处理,用这个平台打造出属于自己的对话式搜索产品或企业内部知识问答产品。最后非常希望客户能够参与进来,和我们一起共建对话式搜索的生态。

