
- 1LayIm结合原生WebSocket实现即时通讯
- 2帝国cms自适应html5古诗词历史名句书籍文章资讯网站源码整站模板sinfo插件带采集会员中心
- 3达梦关键字(如:XML,EXCHANGE,DOMAIN,link等)配置忽略
- 4neo4j数据库与java_Java图形数据库Neo4j入门
- 5欧拉角转四元数转换公式_1.04+0.4*cosw怎么变成
- 6AIoT人工智能物联网之AI 实战
- 7Android证书生成(android studio)_androidstudio生成证书
- 8Python绘制爱心代码,书写爱情故事_python画爱心代码
- 9探索未来学术:ChatGPT如何引领论文写作革命
- 1004-Linux之Linux软件安装、三剑客和Shell编程_linux安装tcsh
[CUDA 学习笔记] 如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志
赞
踩
如何优化 CUDA 矩阵乘内核以获得类似 cuBLAS 的性能: 工作日志
- 注: 本文主要是对博文 “How to Optimize a CUDA Matmul Kernel for cuBLAS-like Performance: a Worklog - SIBOEHM” 的翻译, 并进行了一定的备注和补充
在这篇文章中, 我将迭代优化用 CUDA 编写的矩阵乘法的实现. 我的目标不是构建一个 cuBLAS 替代品, 而是深入了解用于现代深度学习的 GPU 的最重要的性能特征. 这包括合并全局内存访问、共享内存缓存和占用优化等1 2.
GPU 上的矩阵乘法可能是目前存在的最重要的算法, 因为它在训练和推理大型深度学习模型时占据了几乎所有的浮点运算(FLOPs). 那么, 从头开始编写一个高性能的 CUDA SGEMM3 需要多少工作呢? 我将从一个简单的内核开始, 并逐步应用优化, 直到我们达到了 cuBLAS (NVIDIA 的官方矩阵库) 性能的 95% (在好的情况下) :4
| 内核 | GFLOPs/s | 相对于 cuBLAS 的性能 |
|---|---|---|
| 1: 朴素实现 (Naive) | 309.0 | 1.3% |
| 2: 全局内存合并 (GMEM Coalescing) | 1986.5 | 8.5% |
| 3: 共享内存缓存 (SMEM Caching) | 2980.3 | 12.8% |
| 4: 一维块分片 (1D Blocktiling) | 8474.7 | 36.5% |
| 5: 二维块分片 (2D Blocktiling) | 15971.7 | 68.7% |
| 6: 序列化内存访问 (Vectorized Mem Access) | 18237.3 | 78.4% |
| 9: 自动调整 (Autotuning) | 19721.0 | 84.8% |
| 10: warp 分片 (Warptiling) | 21779.3 | 93.7% |
| 0: cuBLAS | 23249.6 | 100.0% |
Kernel 1: 朴素实现
在 CUDA 编程模型中, 计算按照三级层次进行排序. CUDA 内核的每次调用都会创建一个新的网格(grid), 该网格由多个线程块(block)组成. 每个线程块最多由 1024 个单独的线程(thread)组成.5 同一线程块中的线程可以访问同一共享内存区域(SMEM).
一个线程块中的线程数可以使用一个通常称为 blockDim 的变量来配置, 该变量是一个由三个 int 组成的向量. 该向量的条目指定了 blockDim.x、blockDim.y 和 blockDim.z 的大小, 如下所示:
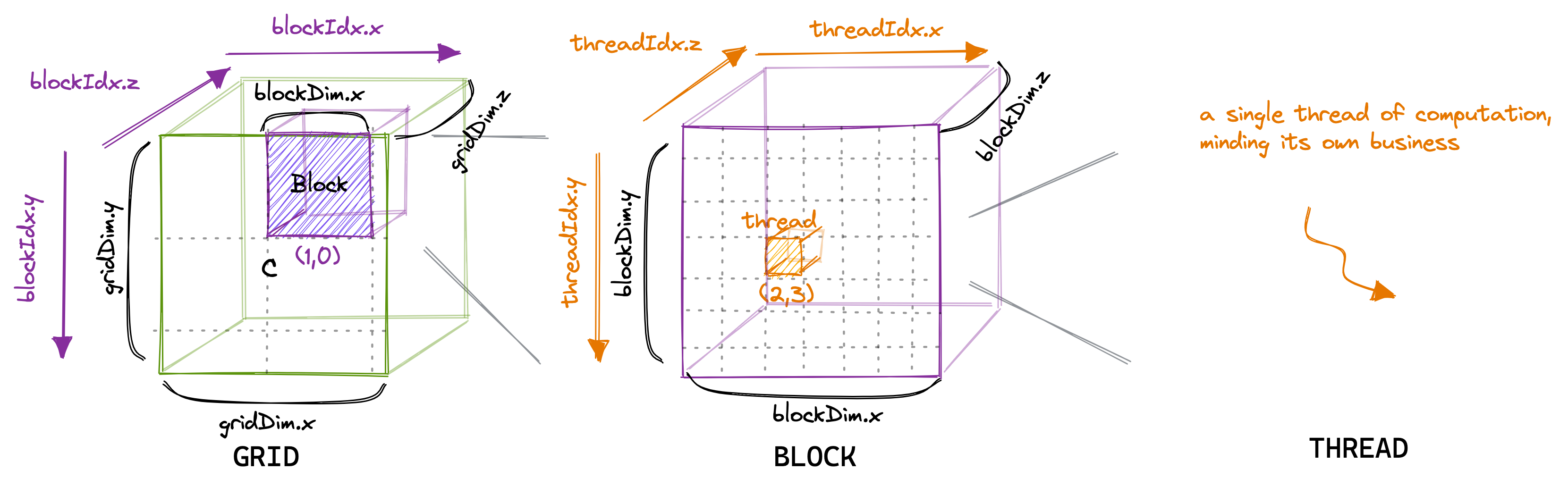
类似地, 网格中的线程块数可以使用 gridDim 变量进行配置. 当我们从主机6启动一个新内核时, 它会创建一个单独的网格, 包含指定的线程块和线程7. 重要的是要记住, 我们刚才讨论的线程层次结构主要关注程序的正确性. 对于程序性能, 正如我们稍后将看到的, 将同一线程块中的所有线程等同看待并不是一个好主意.
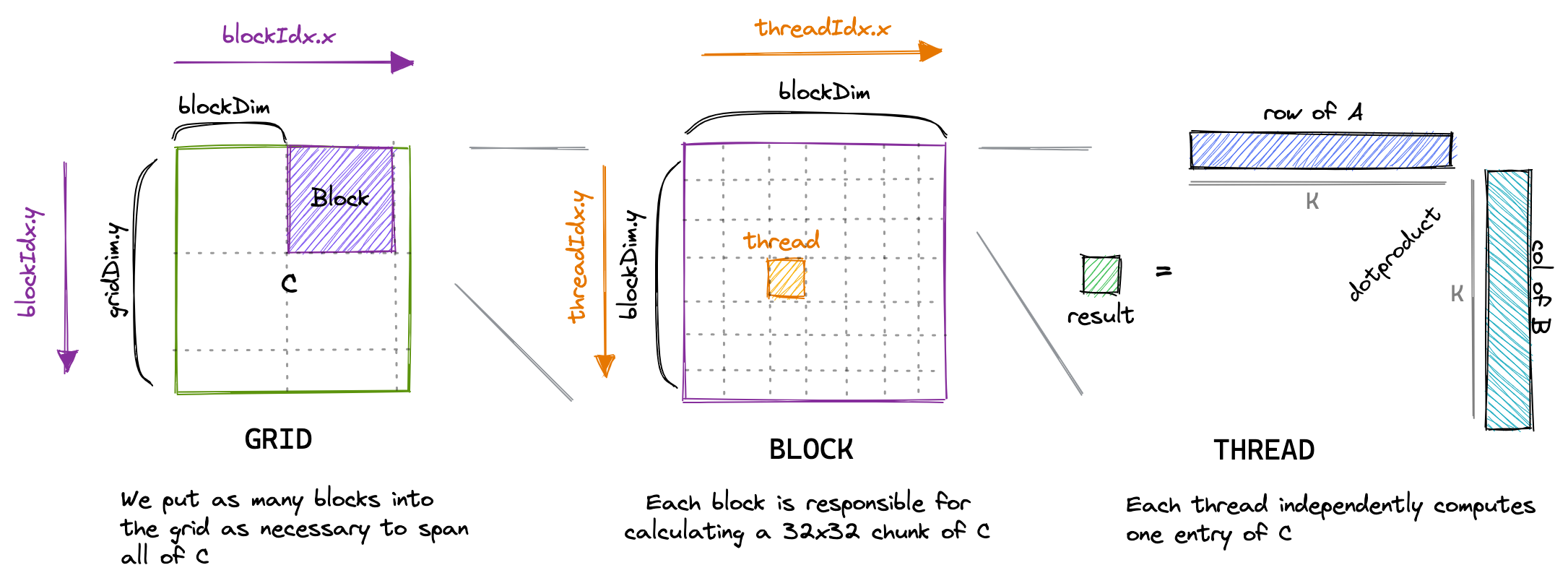
对于我们的第一个内核, 我们将使用网格、线程块和线程的层次结构, 为每个线程分配结果矩阵 C 中的一个唯一条目. 然后, 该线程将计算矩阵 A 对应行和矩阵 B 对应列的点积, 并将结果写入矩阵 C. 由于矩阵 C 的每个位置只由一个线程写入, 因此我们不需要进行同步操作. 我们将这样启动内核:
// create as many blocks as necessary to map all of C
dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32), 1);
// 32 * 32 = 1024 thread per block
dim3 blockDim(32, 32, 1);
// launch the asynchronous execution of the kernel on the device
// The function call returns immediately on the host
sgemm_naive<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
CUDA 代码是从单线程的角度编写的. 在内核代码中, 我们访问 blockIdx 和 threadIdx 内置变量. 这些将包含基于访问它们的线程返回的不同值. 8 9
__global__ void sgemm_naive(int M, int N, int K, float alpha, const float *A, const float *B, float beta, float *C) { // compute position in C that this thread is responsible for const uint x = blockIdx.x * blockDim.x + threadIdx.x; const uint y = blockIdx.y * blockDim.y + threadIdx.y; // `if` condition is necessary for when M or N aren't multiples of 32. if (x < M && y < N) { float tmp = 0.0; for (int i = 0; i < K; ++i) { tmp += A[x * K + i] * B[i * N + y]; } // C = α*(A@B)+β*C C[x * N + y] = alpha * tmp + beta * C[x * N + y]; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这个简单内核的可视化:10
这个内核在我的 A6000 GPU 上处理三个 40922 的 fp32 矩阵大约需要 0.5 秒. 让我们进行一些非特定于实现的计算:
最快运行时的下限
对于两个 40922 的矩阵的矩阵相乘, 然后再加上一个 40922 的矩阵 (以构成 GEMM):
- 总 FLOPS:11: 2 * 40923 + 40922 = 137 GFLOPS
- 总读取数据(最少!): 3 * 40922 * 4B = 201MB
- 总存储数据: 40922 * 4B = 67MB
假设具有足够大的缓存12, 那么 268MB 是任何实现从/到全局 GPU 内存13必须传输的绝对最小内存量. 让我们对内核性能进行一些上界计算. GPU 宣传具有 30TFLOPs/s 的 FP32 计算吞吐量和 768GB/s 的全局内存带宽. 如果我们到达了这些数据指标14 15, 那么计算需要 4.5ms, 内存传输需要 0.34ms. 因此, 在我们的草稿计算中, 计算时间约为内存访问时间的约 10 倍. 这意味着只要我们需要传输的内存量小于绝对最小值 278MB 的 10 倍, 我们的最终优化的内核将受到计算限制(compute-bound). 16
既然我们已经为 fp32 GEMM 计算计算出了一些下限, 让我们回到手头的内核, 看看为什么它比实际速度慢得多.
朴素内核的内存访问模式
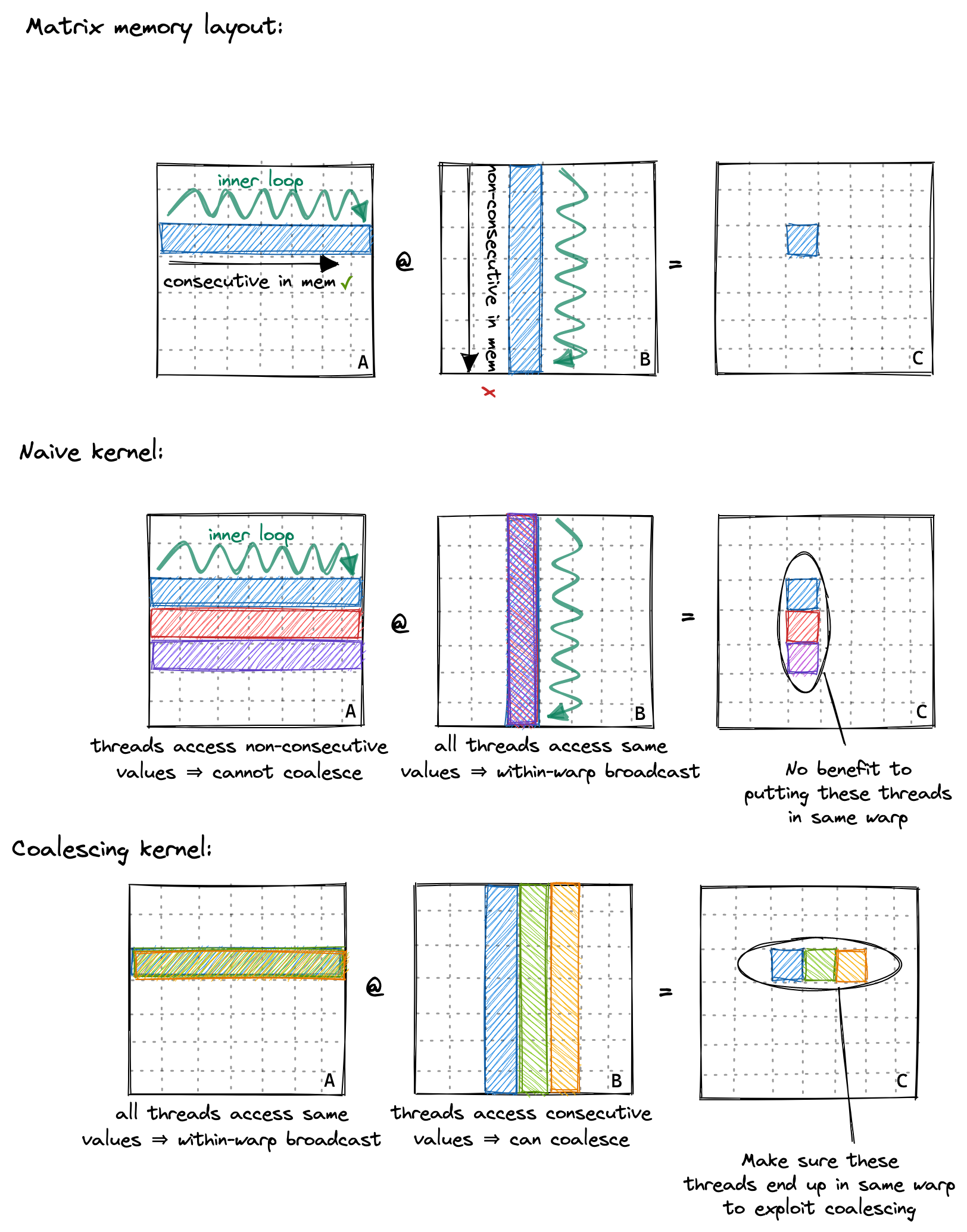
在我们的内核中, 具有 ThreadId (0,0) 和 (0,1) 的同一线程块中的两个线程将加载 B 的同一列但 A 的不同行. 如果我们假设零缓存是最坏的情况, 那么每个线程必须从全局内存加载 2*4092+1 个浮点. 由于我们总共有 40922 个线程, 这将导致 548GB 的内存流量.
以下是我们朴素内核的内存访问模式的可视化, 以两个线程 A(红色) 和 B(绿色) 为例:
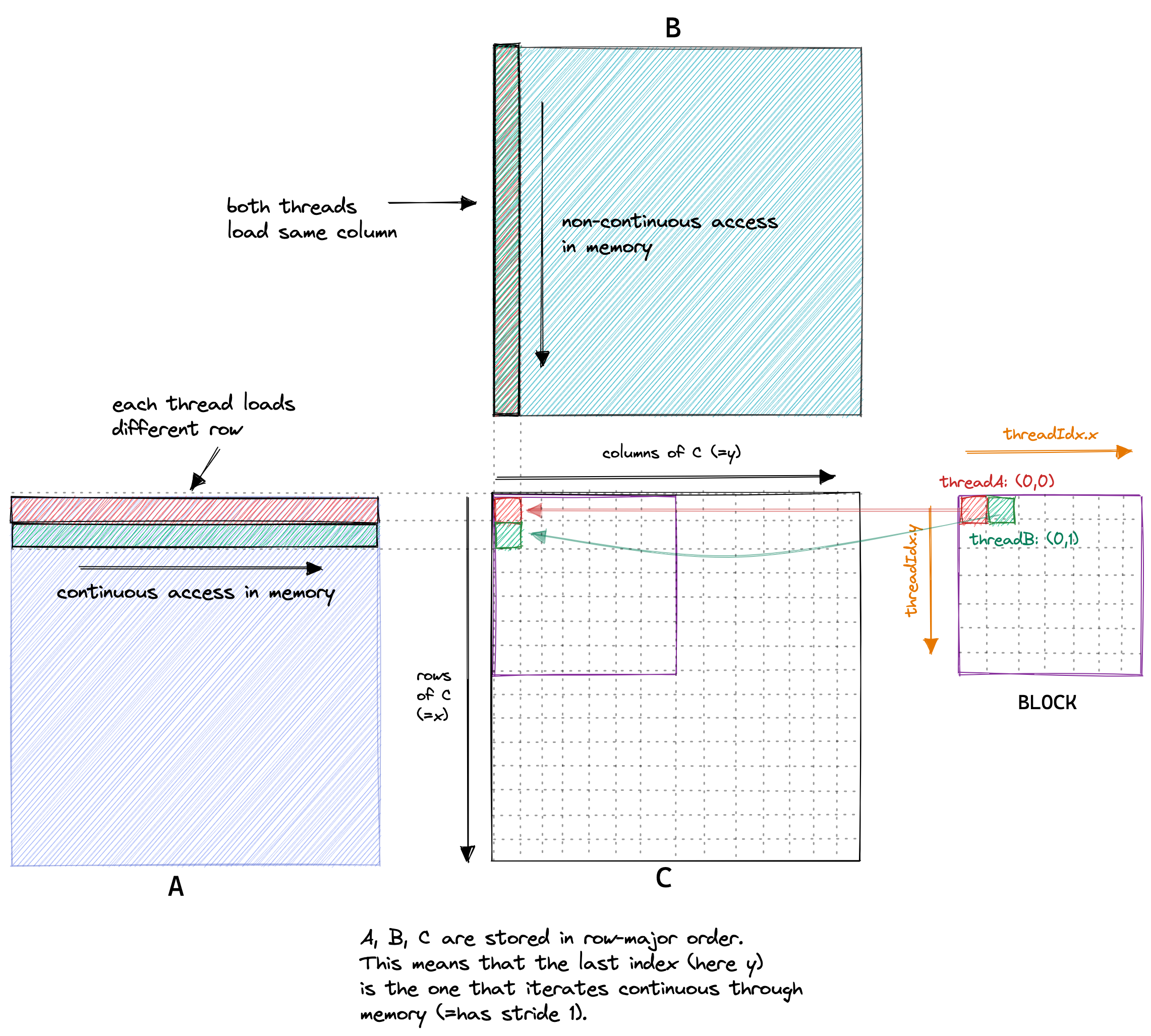
因此, 概括一下, 当我在 A6000 GPU 上运行这个内核时, 当乘以两个 4092x4092 float32 的矩阵时, 它达到了约 300 GFLOP. 考虑到 A6000 被宣传为能够实现近 30 TFLOP, 这相当糟糕.17 那么, 我们如何开始才能让其更快呢? 一种方法是优化内核的内存访问模式, 使全局内存访问可以合并(coalesced) (=combined) 为更少的访问.
Kernel 2: 全局内存合并
在我们进入全局内存合并之前, 我们需要了解 warp 的概念. 为了便于执行, 线程块的线程被分组为由 32 个线程组成的所谓的 warp. 然后一个 warp 被分配给 warp 调度器, 该调度器是执行指令的物理核心.18 每个多处理器(multiprocessor)有四个 warp 调度器. 分组为 warp 是基于连续的 threadId 进行的. 如果我们将 blockDim 设置为多维, 那么 threadId 的计算如下:
threadId = threadIdx.x+blockDim.x*(threadIdx.y+blockDim.y*threadIdx.z)
- 1
然后, 具有相邻 threadId 的线程成为同一 warp 的一部分. 下面我试着用 8 线程的小“warp”来说明这一点(真正的 warp 总是包含 32 个线程): 19
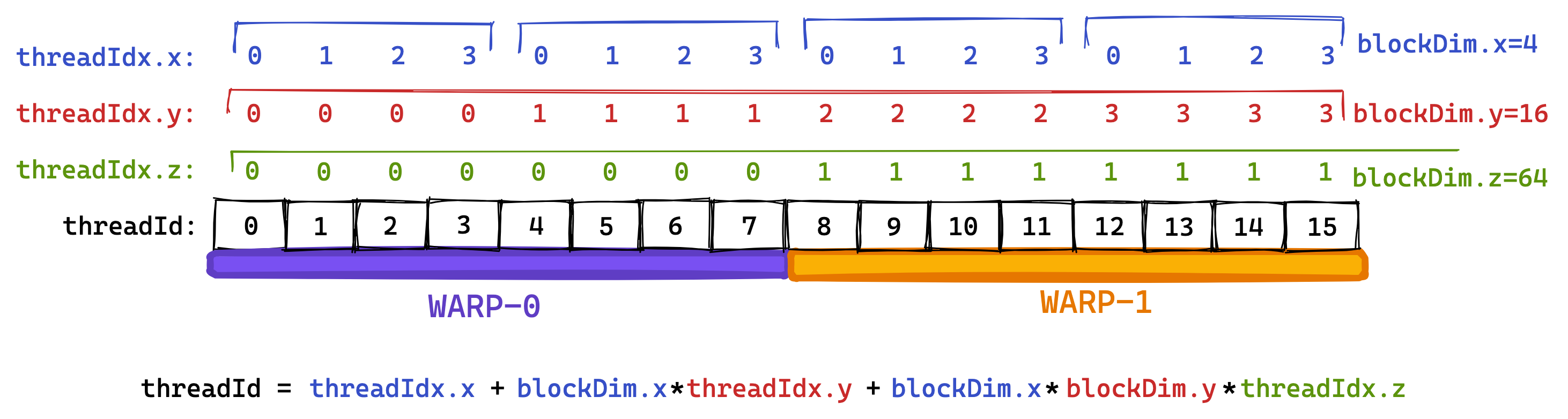
warp 的概念与第二个内核相关, 因为属于同一 warp 的线程的顺序内存访问可以被组合并作为一个整体执行. 这被称为全局内存合并. . 这是在优化内核的全局内存(GMEM)访问以达到峰值带宽时最重要的事情.
以下是一个示例, 其中对同一 warp 中线程的连续内存访问进行分组, 允许每个 warp 仅使用 2 个 32B 负载执行 8 次内存访问:
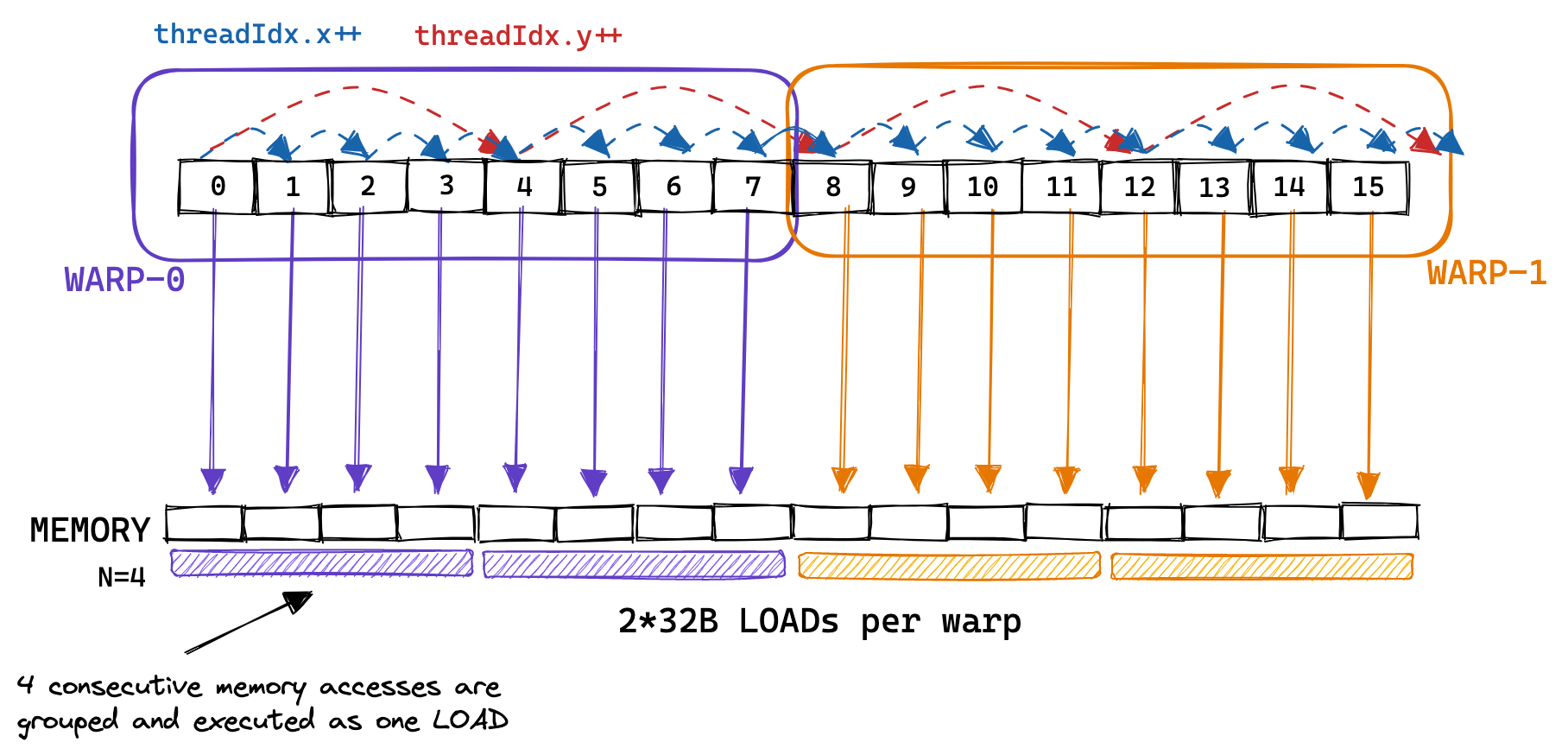
实际上, GPU 支持 32B、64B 和 128B 的内存访问. 因此, 如果每个线程都从全局内存加载一个 32 位浮点, 那么 warp 调度器(可能是MIO)可以将这个 32*4B=128B 的加载合并到一个事务中. 只有当加载的浮点数在内存中是连续的, 并且访问是对齐的时候, 这才有可能.20 如果不满足, 或者由于其他原因无法合并访问, 那么 GPU 将执行尽可能多的 32B 负载来获取所有浮点, 从而导致大量带宽浪费. 通过分析我们的朴素内核, 我们可以观察到非合并访问的不利影响, 因为我们只实现了 15GB/s 的 GMEM 吞吐量.
回顾以前的内核, 我们为线程分配了矩阵 C 的条目, 如下所示:
const uint x = blockIdx.x * blockDim.x + threadIdx.x;
const uint y = blockIdx.y * blockDim.y + threadIdx.y;
- 1
- 2
因此, 相同 warp 的线程(具有连续 threadIdx.x 的线程)从内存中非连续地加载 A 的行. 朴素内核访问 A 内存的模式看起来更像这样:
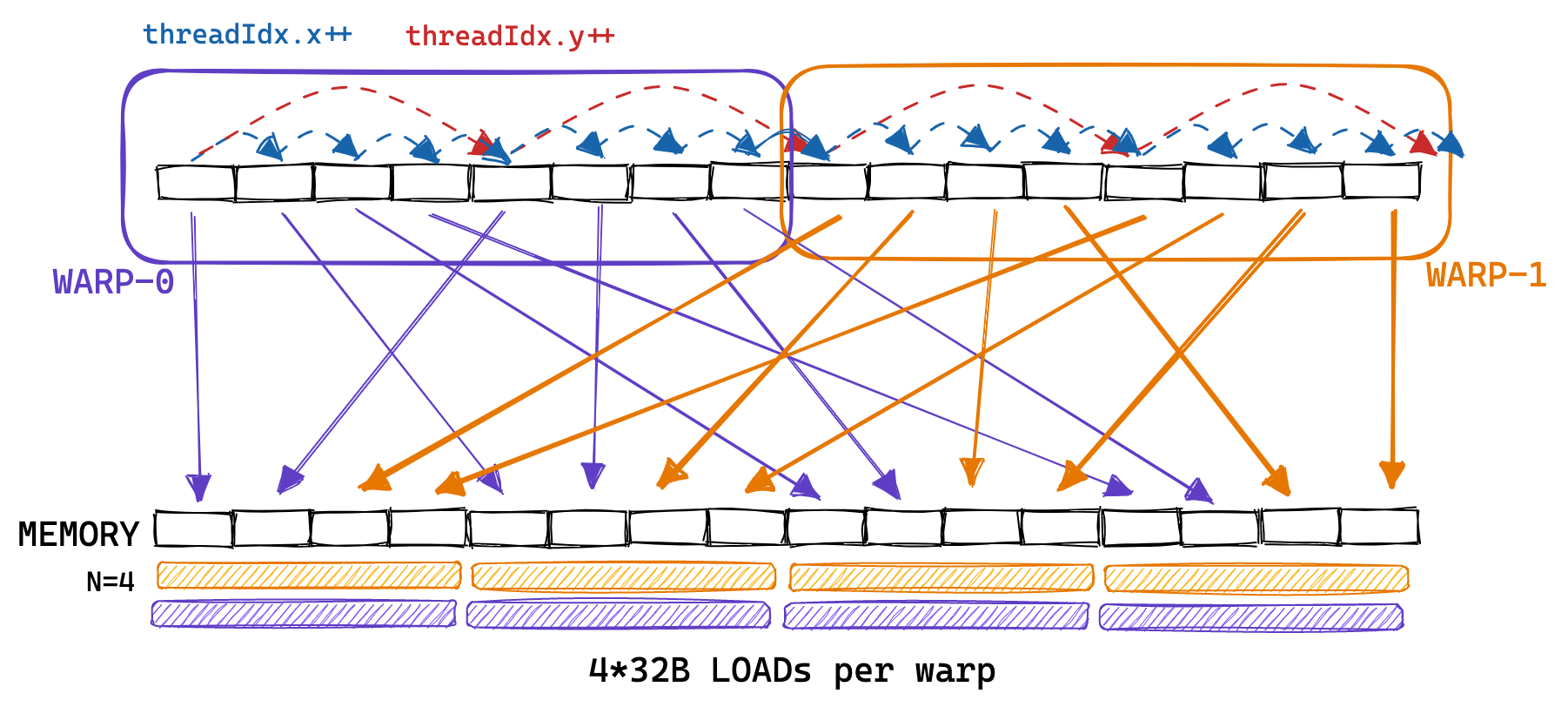
为了实现合并, 我们可以改变结果矩阵 C 分配给线程的位置的方式. 全局内存访问模式的这种变化如下所示:
要实现这一点, 我们只需要更改前两行:
const int x = blockIdx.x * BLOCKSIZE + (threadIdx.x / BLOCKSIZE);
const int y = blockIdx.y * BLOCKSIZE + (threadIdx.x % BLOCKSIZE);
if (x < M && y < N) {
float tmp = 0.0;
for (int i = 0; i < K; ++i) {
tmp += A[x * K + i] * B[i * N + y];
}
C[x * N + y] = alpha * tmp + beta * C[x * N + y];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
我们这样调用它:21
// gridDim stays the same
dim3 gridDim(CEIL_DIV(M, 32), CEIL_DIV(N, 32));
// make blockDim 1-dimensional, but don't change number of threads
dim3 blockDim(32 * 32);
sgemm_coalescing<<<gridDim, blockDim>>>(M, N, K, alpha, A, B, beta, C);
- 1
- 2
- 3
- 4
- 5
- 译者注: 在上述代码中,
BLOCKSIZE为线程块的宽度32. 如果将 Kernel 1 朴素内核的blockDim同样平铺为一维, 则x和y的代码如下. 可以看到, 前后二者的区别在于%和/的互换.const uint x = blockIdx.x * BLOCKSIZE + (threadIdx.x % BLOCKSIZE); const uint y = blockIdx.y * BLOCKSIZE + (threadIdx.y / BLOCKSIZE);- 1
- 2
x相同, 从而访问矩阵 A 的同一行; 而y彼此不同但内存连续.
而 Kernel 1 中, 连续的 32 个线程内y相同, 而x连续, 但造成访问矩阵 A 的不同行.
全局内存合并将内存吞吐量从 15GB/s 提高到 110GB/s. 性能达到 2000 GFLOPS, 与第一个朴素内核的 300 GFLOPS 相比有了很大的改进. 对于下一个内核, 我们将使用 GPU 的快速片上内存, 称为共享内存(shared memory), 来缓存将被重复使用的数据.
Kernel 3: 共享内存缓存分块
在较大的全局内存旁边, GPU 有一个小得多的内存区域, 物理上位于芯片上, 称为共享内存(SMEM). 在物理上, 每个 SM 有一个共享内存.22 从逻辑上讲, 这个共享内存是在线程块之间划分的. 这意味着线程可以通过共享内存块与其线程块中的其他线程进行通信. 在我的 A6000 GPU 上, 每个线程块最多可以访问 48KB 的共享内存.23
由于共享内存位于片上, 因此它比全局内存具有更低的延迟和更高的带宽. 我找不到 Ampere 架构的一个好的基准测试结果, 但对于 Volta 架构(2017 年发布), 这篇论文中进行的的基准测试报告了 750GiB/s 的全局内存带宽和 12080GiB/s 的共享内存带宽.24
因此, 对于下一个内核, 我们将从全局内存中加载 A 的一个分块和 B 的一个分块到共享内存中. 然后, 我们将在这两个分块上执行尽可能多的工作, 每个线程仍被分配一个 C 条目. 我们将沿着 A 的列和 B 的行移动分块, 对 C 执行部分求和, 直到计算出结果.
如下所示:
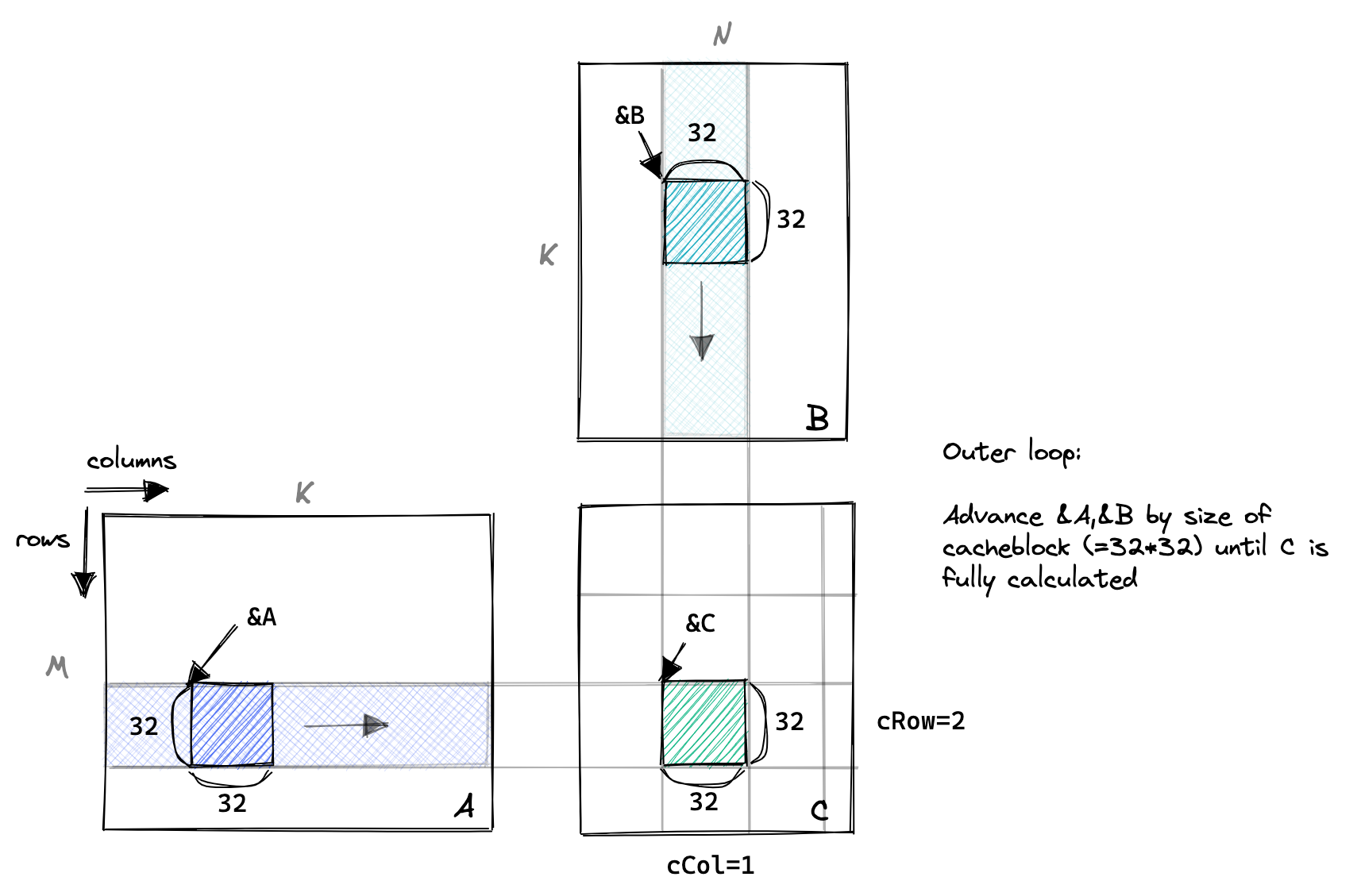
代码的重要部分如下, 变量名称与上图相对应:25:
// advance pointers to the starting positions A += cRow * BLOCKSIZE * K; // row=cRow, col=0 B += cCol * BLOCKSIZE; // row=0, col=cCol C += cRow * BLOCKSIZE * N + cCol * BLOCKSIZE; // row=cRow, col=cCol float tmp = 0.0; // the outer loop advances A along the columns and B along // the rows until we have fully calculated the result in C. for (int bkIdx = 0; bkIdx < K; bkIdx += BLOCKSIZE) { // Have each thread load one of the elements in A & B from // global memory into shared memory. // Make the threadCol (=threadIdx.x) the consecutive index // to allow global memory access coalescing As[threadRow * BLOCKSIZE + threadCol] = A[threadRow * K + threadCol]; Bs[threadRow * BLOCKSIZE + threadCol] = B[threadRow * N + threadCol]; // block threads in this block until cache is fully populated __syncthreads(); // advance pointers onto next chunk A += BLOCKSIZE; B += BLOCKSIZE * N; // execute the dotproduct on the currently cached block for (int dotIdx = 0; dotIdx < BLOCKSIZE; ++dotIdx) { tmp += As[threadRow * BLOCKSIZE + dotIdx] * Bs[dotIdx * BLOCKSIZE + threadCol]; } // need to sync again at the end, to avoid faster threads // fetching the next block into the cache before slower threads are done __syncthreads(); } C[threadRow * N + threadCol] = alpha * tmp + beta * C[threadRow * N + threadCol];
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 译者注: 结合完整的 kernel 3 代码可知:
cRow = blockIdx.x,cCol = blockIdx.y. for 循环之前的A,B,C对应的是当前线程块处理的整个部分(上图矩阵的浅色部分)的起始位置(左上角)的索引.- 外层 for 循环则是对线程块处理的部分进行分片迭代, 即 K 维度上的循环迭代. 在每次循环中, 将当前线程块分片加载到共享内存中.
- 内层 for 循环是对当前线程块分片沿 K 维度逐一进行点积(A行×B列), 然后写入矩阵 C 对应位置.
- 由于 kernel 的
blockDim为32*32, 矩阵 C 的线程块分片大小均为32*32, 所以线程块的每个线程恰好处理矩阵 C 的线程块分片对应的一个元素. 从矩阵 A 和 B 来看, 每次内层 for 循环时, 每个线程同时对应 A 分片dotIdx行中一个元素和 B 分片中dotIdx中一个元素.
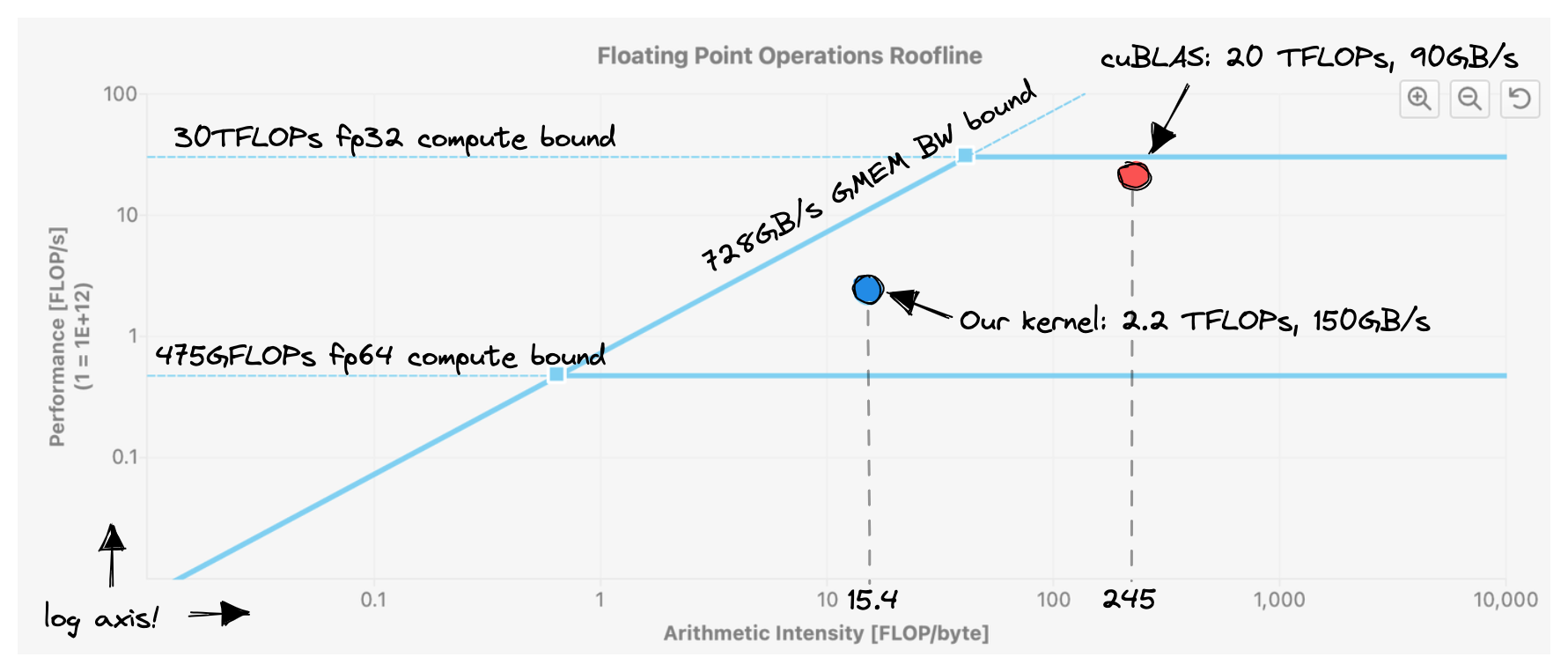
该内核实现了约 2200 GFLOPS, 比上一版本提高了 50%.26 我们离 GPU 所能提供的大约 30 TFLOP 还有很长的路要走. 从下面的屋顶状图中可以明显看出:27
在 CHUNKSIZE 为 32 时, 这将使用 2*32*32*4B=8KB 的共享内存空间.28 我的 A6000 GPU 每个线程块最多有 48KB 的共享内存空间, 所以我们还远远没有达到这个极限. 这不一定是一个问题, 因为增加每个线程块的共享内存使用量会有负面影响. 每个多处理器(SM)最多有 100KB 的 SMEM 可用. 这意味着, 如果我们修改内核以使用完整的 48KB SMEM, 每个 SM 只能同时加载两个线程块. 用 CUDA 的说法, 增加每个线程块的 SMEM 利用率会降低占用率(occupancy). 占用率定义为每个 SM 的激活 warp 数与每个 SM 的最大可能激活 warp 数之间的比值.
高占用率是有用的, 因为它允许我们通过拥有更大的可发布指令池来隐藏操作的高延迟.29 保持更多激活线程块在 SM 上加载有三个主要限制: 寄存器数量、warp 数量和 SMEM 容量. 让我们为我们当前的内核进行一个示例计算.
Kernel 3 的占有率计算
以下是从 cudaGetDeviceProperties API 获得的我的 GPU 的相关硬件统计数据(多处理器是我们之前讨论的 SM):30
| 指标 | 值 |
|---|---|
| 名称 | NVIDIA RTX A6000 |
| 算力 (Compute Capability) | 8.6 |
| 每线程块最大线程数 (max threads per block) | 1024 |
| 每 SM 最大线程数 (max threads per multiprocessor) | 1536 |
| 每 warp 线程数 (threads per warp) | 32 |
| warp 分片粒度 (warp allocation granularity) | 4 |
| 每线程块最多寄存器数 (max regs per block) | 65536 |
| 每 SM 最多寄存器数 (max regs per multiprocessor) | 65536 |
| 寄存器分配单元大小 (reg allocation unit size) | 256 |
| 寄存器分配粒度 (reg allocation granularity) | warp |
| 总全局内存 (total global mem) | 48685 MB |
| 每线程块最大共享内存 (max shared mem per block) | 48 KB |
| CUDA 运行时每线程块共享内存开销 (CUDA runtime shared mem overhead per block) | 1024 B |
| 每 SM 共享内存 (shared mem per multiprocessor) | 102400 B |
| SM 数 (multiprocessor count) | 84 |
| 每 SM 最大 warp 数 (max warps per multiprocessor) | 48 |
以下是我们内核的资源需求:
| 每线程寄存器数 (Registers per Thread) | 37 |
| 每线程块共享内存 (SMEM per Block) | 8192 B |
| 每线程块线程数 (Threads per Block) | 1024 |
工作负载按线程块粒度在 SM 上调度. 每个 SM 将尽可能加载更多的线程块, 只要它有足够的资源来容纳它们. 计算:31
- 共享内存: 8192B/Block + 1024B/Block 用于 CUDA 运行时使用 = 9216B/Block. (每 SM 102400B) / (每线程块 9216B per Block) = 11.11 ⇒ 上限 11 个线程块.
- 线程: 每线程块 1024 个线程, 每个 SM 最多 1536 个线程 ⇒ 上限 1 个线程块.
- 寄存器: 每线程 37 个寄存器 * 每 warp 32 线程 = 每 warp 1184 个寄存器. 寄存器分配粒度在 warp 级别上为 256个寄存器, 因此每个 warp 四舍五入到 1280 个寄存器. 我们有 (1024 线程 / 32) = 每个线程块 32 个 warp, 因此每个 warp 1280 个寄存器 * 每个线程块 32 warp = 每个线程块 40960 个寄存器. 每 SM 最多 65536 个寄存器 ⇒ 上限 1 个线程块.32
因此, 这个内核受到每个线程块的线程数和每个线程的寄存器数的限制. 我们不能为每个 SM 加载一个以上的线程块, 因此最终占用率为 32 个有效 warp/48 个最大有效 warp = 66%.
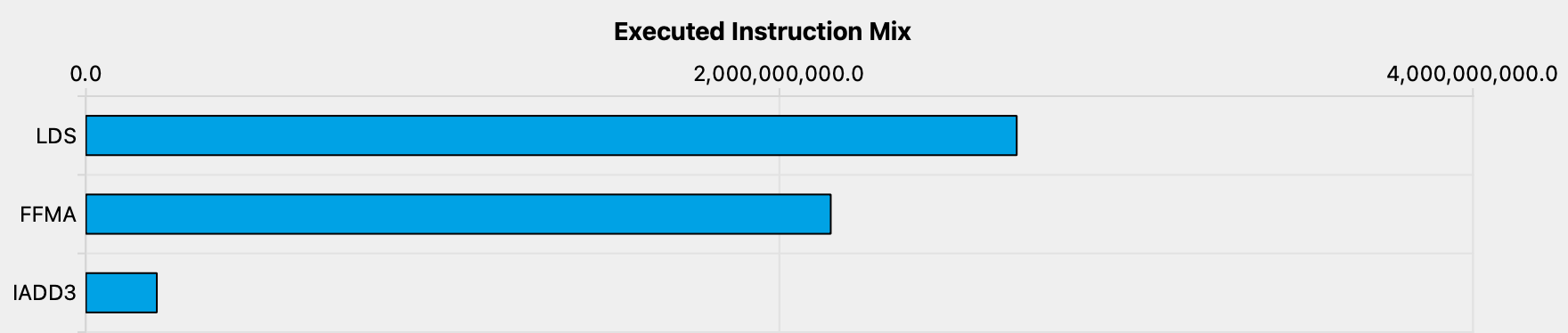
66% 的占用率还不错, 所以这并不能解释为什么我们的内核运行如此缓慢.33 查看监测器(profiler)会给我们一些提示. 首先, 如果我们观察已执行指令的组合, 它们中的大多数都是内存加载:34
我们的内存循环在 PTX(Godbolt 链接)中看起来是这样的:
ld.shared.f32 %f91, [%r8+3456];
ld.shared.f32 %f92, [%r7+108];
fma.rn.f32 %f93, %f92, %f91, %f90;
- 1
- 2
- 3
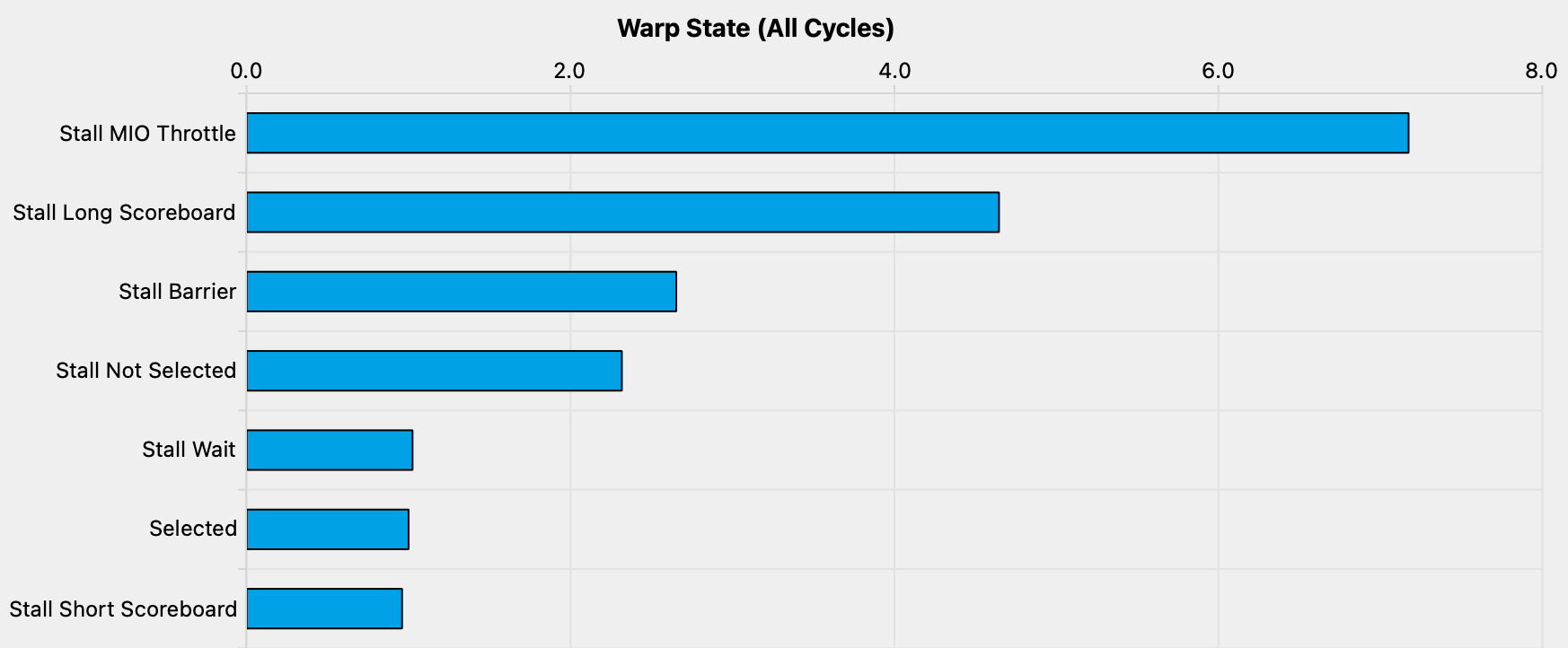
这并不够好, 因为内存负载必然比简单的 FMA 具有更高的延迟, 并且我们知道我们的内核应该是计算受限的. 我们在查看 profiler 对 warp 状态的采样时会看到这种效果. 这量化了每个执行指令在每个状态下花费的时钟周期数:35
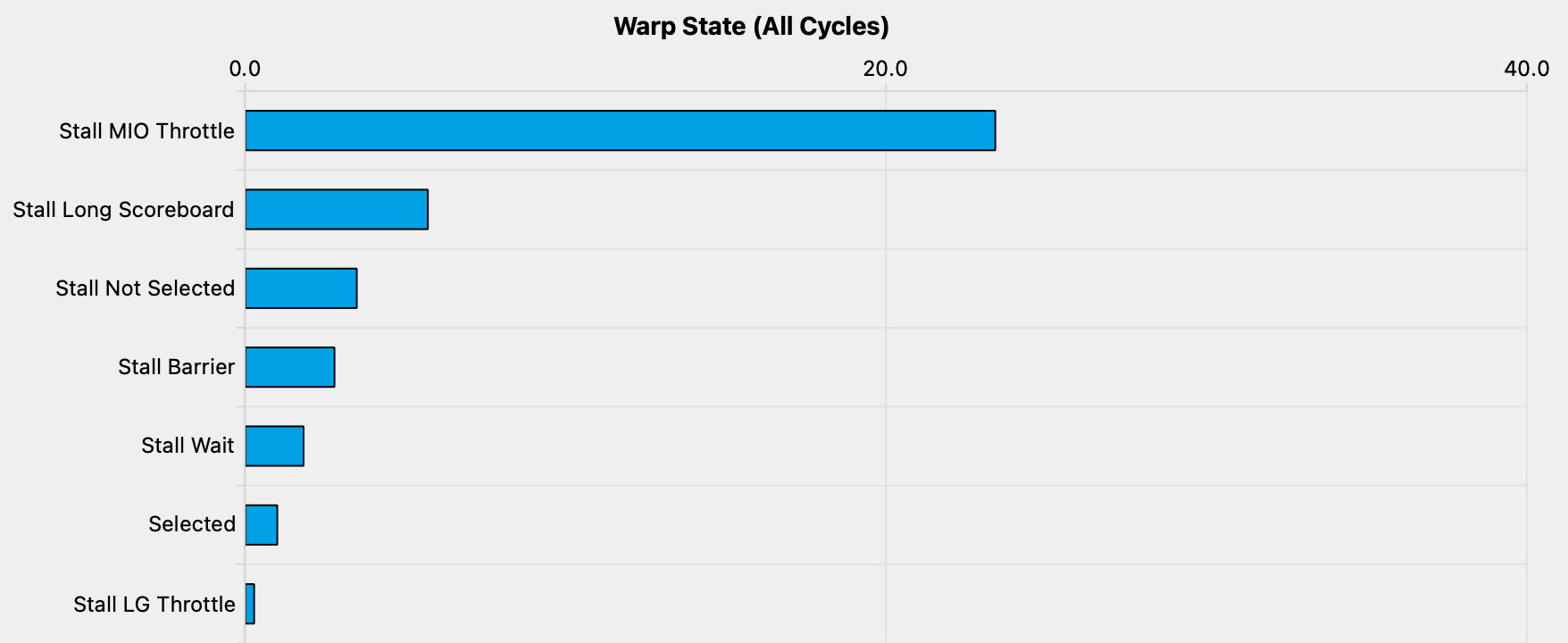
状态的含义在《内核评测指南》中有详细说明. 对于 Stall MIO Throttle, 它显示为:
warp 在等待 MIO(memory input/output, 内存输入/输出)指令队列未满时被阻塞. 这种阻塞原因在极端利用 MIO 流水线的情况下很高, 其中包括特殊的数学指令、动态分支以及共享内存指令.
- 1
我们没有使用特殊的数学指令, 也没有使用动态分支, 所以很明显, 我们正在等待 SMEM 访问返回. 那么, 我们如何使内核发出更少的 SMEM 指令呢? 一种方法是让每个线程计算一个以上的输出元素, 这使我们能够在寄存器中执行更多的工作, 并减少对 SMEM 的依赖.
Kernel 4: 用于计算每个线程的多个结果的一维块分片
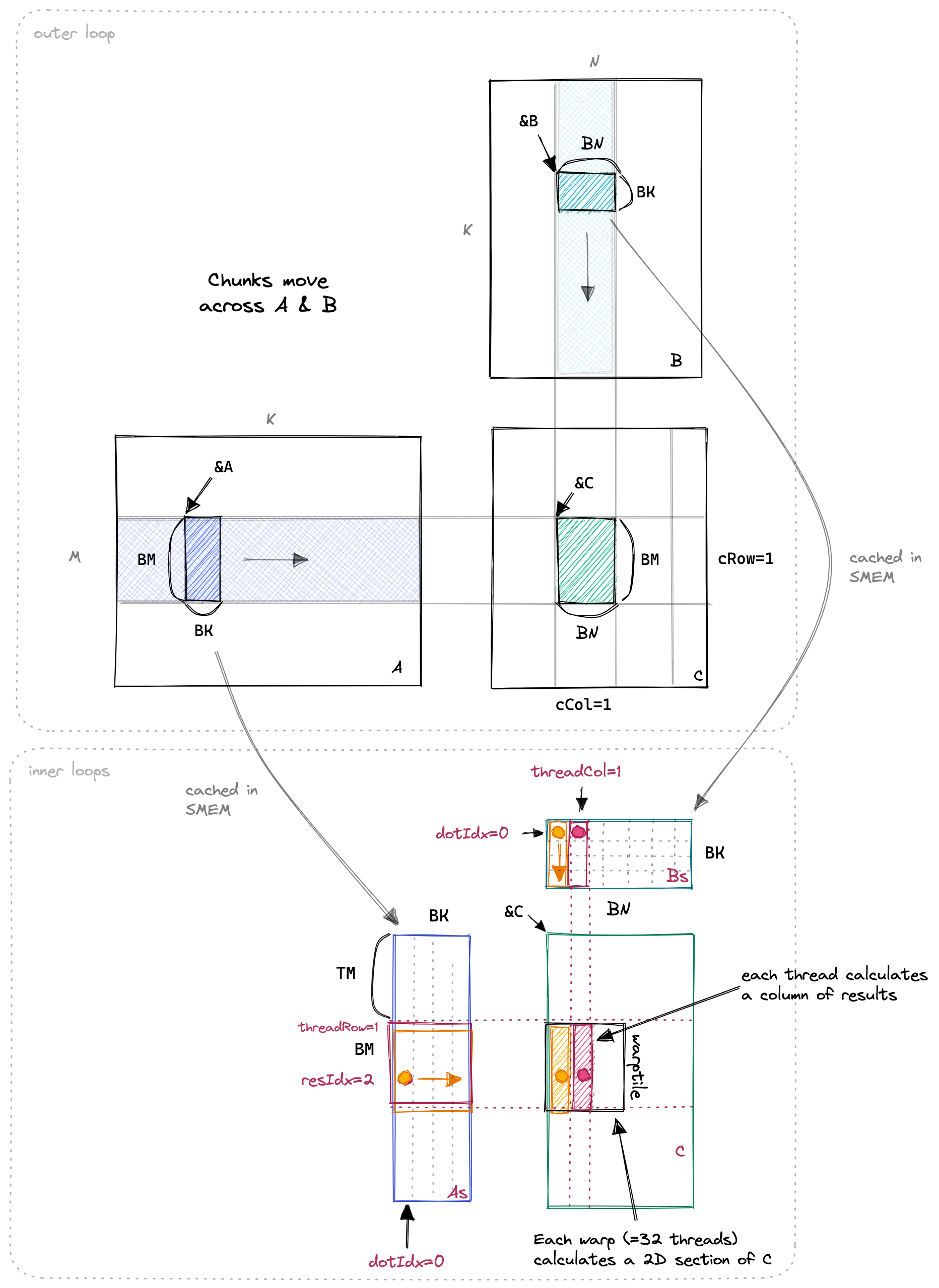
因此, 下一个内核的工作方式与上一个内核类似, 但添加了一个新的内部循环, 用于计算每个线程的多个 C 条目. 我们现在使用 SMEM 缓存 BM*BK+BN*BK=64*8+64*8=1024 个浮点数大小, 每个线程块总共 4KB. 可视化如下所示. 我已经用橙色和红色突出显示了其中的两个线程以及它们在内部循环中访问的值.
这个内核的所有重要更改都发生在内部循环中. GMEM 到 SMEM 的负载与以前基本相同. 让我们看看:36
// allocate thread-local cache for results in registerfile float threadResults[TM] = {0.0}; // outer loop over block tiles for (uint bkIdx = 0; bkIdx < K; bkIdx += BK) { // populate the SMEM caches (same as before) As[innerRowA * BK + innerColA] = A[innerRowA * K + innerColA]; Bs[innerRowB * BN + innerColB] = B[innerRowB * N + innerColB]; __syncthreads(); // advance blocktile for outer loop A += BK; B += BK * N; // calculate per-thread results for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) { // we make the dotproduct loop the outside loop, which facilitates // reuse of the Bs entry, which we can cache in a tmp var. float Btmp = Bs[dotIdx * BN + threadCol]; for (uint resIdx = 0; resIdx < TM; ++resIdx) { threadResults[resIdx] += As[(threadRow * TM + resIdx) * BK + dotIdx] * Btmp; } } __syncthreads(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 译者注: 结合完整的 kernel 4 代码可知:
BM=BN=64,BK=8,TM=8,blockDim=(BM*BN)/TM=64*64/8.TM=8为每个线程在一次 K 维度迭代中计算的元素个数, 之前 Kernel 3 中相当于TM=1.innerColA = threadIdx.x % BK,innerRowA = threadIdx.x / BK,innerColB = threadIdx.x % BN,innerRowB = threadIdx.x / BN; 且满足BM * BK == blockDim.x和BN * BK == blockDim.x.
即这四个变量将线程块中的线程映射到矩阵 A 和 B 的线程块分片(上图矩阵中的深色部分)的每个元素(由于满足等式关系, 线程块的线程可以恰好铺满矩阵 A 和 B 的分片), 用于将数据从全局内存拷贝到共享内存.- 由于矩阵 C 的分片大小为
BM*BN, 实际大小为线程块中线程数的TM倍. 从另一个角度也证明了每个线程需要处理TM个元素, 需要threadResults大小为TM. - 内层
for dotIdx循环仍然是沿 A 和 B 分片的 K 维逐一计算, 即每次 As 处理一列, Bs 处理一行. 在这里实际上矩阵乘法由之前的矩阵内积变为了外积. - 最内层
for resIdx循环用于线程内部迭代处理中TM个元素.
由于threadCol = threadIdx.x % BN,threadRow = threadIdx.x / BN. 即相邻线程对应 B 分片的不同列, A 分片的同一行分块(因为每个线程处理TM个元素), 与 Kernel 3 相同.
值得一提的是, 由于除数是BN, 所以在一次内部循环迭代中, Bs 分片的dotIdx行的不同列元素(BN个)都会被缓存到Btmp中; 而 As 分片一次只能处理dotIdx列的blockDim/BN行个元素.
根据threadResults[resIdx] += As[(threadRow * TM + resIdx) * BK + dotIdx] * Btmp;可知, 这里每个线程处理的TM个元素在 A 分片的dotIdx列中是连续的. 即最内层循环可以理解为将 As 分片沿BM维度再分成了BM/TM个小分片(线程分片), 每个小分片由 1 个线程处理(一个小分片对应多个线程, 它们拿 A 分片相同行元素, B 分片不同列元素).
这个内核实现了约 8600 GFLOP, 比我们以前的内核快 2.2 倍. 让我们计算一下在我们前一个内核中每个线程执行的内存访问次数, 其中每个线程计算一个结果:
- GMEM: 外部循环 K/32 次迭代 * 2 次加载
- SMEM: 外部循环 K/32 次迭代 * BLOCKSIZE(=32) * 2 次加载 (译者注: 这里的 “BLOCKSIZE” 是线程块分片 K 维度)
- 每个结果的内存访问: K/16 GMEM, K*2 SMEM
对于我们的新内核, 每个线程计算八个结果:
- GMEM: 外部循环 K/8 次迭代 * 2 次加载
- SMEM: 外部循环 K/8 次迭代 * BK(=8) * (1 + TM(=8)) (译者注: B 分片 1 次, A 分片 TM 次)
- 每个结果的内存访问: K/32 GMEM, K * 9/8 MEM (译者注: 这里是上面两个计算结果再除以每个线程处理的
TM=8个元素得到的每个结果的内存访问均摊结果)
正如预期的那样, 由于内存压力, 我们现在每次指令停滞所花费的时钟周期要少得多:37
编译优化侧记
在上面, 我们明确地将 B 的条目缓存到 Btmp 中, 并为了提高效率对两个内部循环进行了重新排序. 如果我们不这样做, 那么代码看起来是这样的:
for (uint resIdx = 0; resIdx < TM; ++resIdx) {
for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) {
threadResults[resIdx] +=
As[(threadRow * TM + resIdx) * BK + dotIdx] * Bs[dotIdx * BN + threadCol];
}
}
- 1
- 2
- 3
- 4
- 5
- 6
有趣的是, 这对性能没有负面影响. 这是令人惊讶的, 因为我们的内部两个循环现在产生 BK(=8) * TM(=8) = 128 次 SMEM 访问, 而非之前的 72 次. 看看汇编(Godbolt 链接)就知道答案了:
// first inner-most loop ld.shared.f32 %f45, [%r9]; ld.shared.f32 %f46, [%r8]; fma.rn.f32 %f47, %f46, %f45, %f212; ld.shared.f32 %f48, [%r9+256]; ld.shared.f32 %f49, [%r8+4]; fma.rn.f32 %f50, %f49, %f48, %f47; ld.shared.f32 %f51, [%r9+512]; ld.shared.f32 %f52, [%r8+8]; fma.rn.f32 %f53, %f52, %f51, %f50; ld.shared.f32 %f54, [%r9+768]; ld.shared.f32 %f55, [%r8+12]; fma.rn.f32 %f56, %f55, %f54, %f53; ld.shared.f32 %f57, [%r9+1024]; ld.shared.f32 %f58, [%r8+16]; fma.rn.f32 %f59, %f58, %f57, %f56; ld.shared.f32 %f60, [%r9+1280]; ld.shared.f32 %f61, [%r8+20]; fma.rn.f32 %f62, %f61, %f60, %f59; ld.shared.f32 %f63, [%r9+1536]; ld.shared.f32 %f64, [%r8+24]; fma.rn.f32 %f65, %f64, %f63, %f62; ld.shared.f32 %f66, [%r9+1792]; ld.shared.f32 %f67, [%r8+28]; fma.rn.f32 %f212, %f67, %f66, %f65; // second inner-most loop ld.shared.f32 %f68, [%r8+32]; fma.rn.f32 %f69, %f68, %f45, %f211; ld.shared.f32 %f70, [%r8+36]; fma.rn.f32 %f71, %f70, %f48, %f69; ld.shared.f32 %f72, [%r8+40]; fma.rn.f32 %f73, %f72, %f51, %f71; ld.shared.f32 %f74, [%r8+44]; fma.rn.f32 %f75, %f74, %f54, %f73; ld.shared.f32 %f76, [%r8+48]; fma.rn.f32 %f77, %f76, %f57, %f75; ld.shared.f32 %f78, [%r8+52]; fma.rn.f32 %f79, %f78, %f60, %f77; ld.shared.f32 %f80, [%r8+56]; fma.rn.f32 %f81, %f80, %f63, %f79; ld.shared.f32 %f82, [%r8+60]; fma.rn.f32 %f211, %f82, %f66, %f81; // ... continues like this for inner-loops 3-8 ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
编译器展开两个循环38, 然后消除 Bs 条目的重复 SMEM 加载, 因此我们最终获得的 SMEM 访问量与优化的 CUDA 代码相同.
当 PTX 被编译为 SASS 时, 来自 Bs 的 SMEM 加载被向量化:39
LDS R26, [R35.X4+0x800] // a 32b load from As
LDS.128 R8, [R2] // a 128b load from Bs
LDS.128 R12, [R2+0x20]
LDS R24, [R35.X4+0x900]
LDS.128 R20, [R2+0x60]
LDS R36, [R35.X4+0xb00]
LDS.128 R16, [R2+0x40]
LDS.128 R4, [R2+0x80]
LDS R38, [R35.X4+0xd00]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
改进方面: 计算强度 (Arithmetic Intensity)
我们当前的内核仍然存在与 Kernel 3 相同的内存停滞(stalling-for-memory)问题, 只是程度较低. 因此, 我们将再次应用相同的优化: 让每个线程计算更多的结果. 使我们的内核运行得更快的主要原因是它增加了计算强度.40 下面, 我试图更清楚地说明为什么每个线程计算更多的结果会提高运算强度:41

总之, 我们所有的内核执行相同数量的 FLOP, 但我们可以通过每个线程计算更多的结果来减少 GMEM 访问的数量. 只要我们仍然是内存限制的(memory bound), 我们就会继续优化计算强度.
Kernel 5: 通过二维块分片增加计算强度
Kernel 5 的基本思想是每个线程计算 C 的 8 * 8 个元素的网格. 内核的第一阶段是让所有线程一起工作来填充 SMEM 缓存. 我们将让每个线程加载多个元素. 此代码如下所示:42
for (uint loadOffset = 0; loadOffset < BM; loadOffset += strideA) {
As[(innerRowA + loadOffset) * BK + innerColA] =
A[(innerRowA + loadOffset) * K + innerColA];
}
for (uint loadOffset = 0; loadOffset < BK; loadOffset += strideB) {
Bs[(innerRowB + loadOffset) * BN + innerColB] =
B[(innerRowB + loadOffset) * N + innerColB];
}
__syncthreads();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
现在 SMEM 缓存已经填充完毕, 我们让每个线程将其相关的 SMEM 条目相乘, 并将结果累积到本地寄存器中. 下面我展示了沿着输入矩阵的(没有改变)外层循环, 以及点积和 TN 和 TM 维度的三个内层循环:
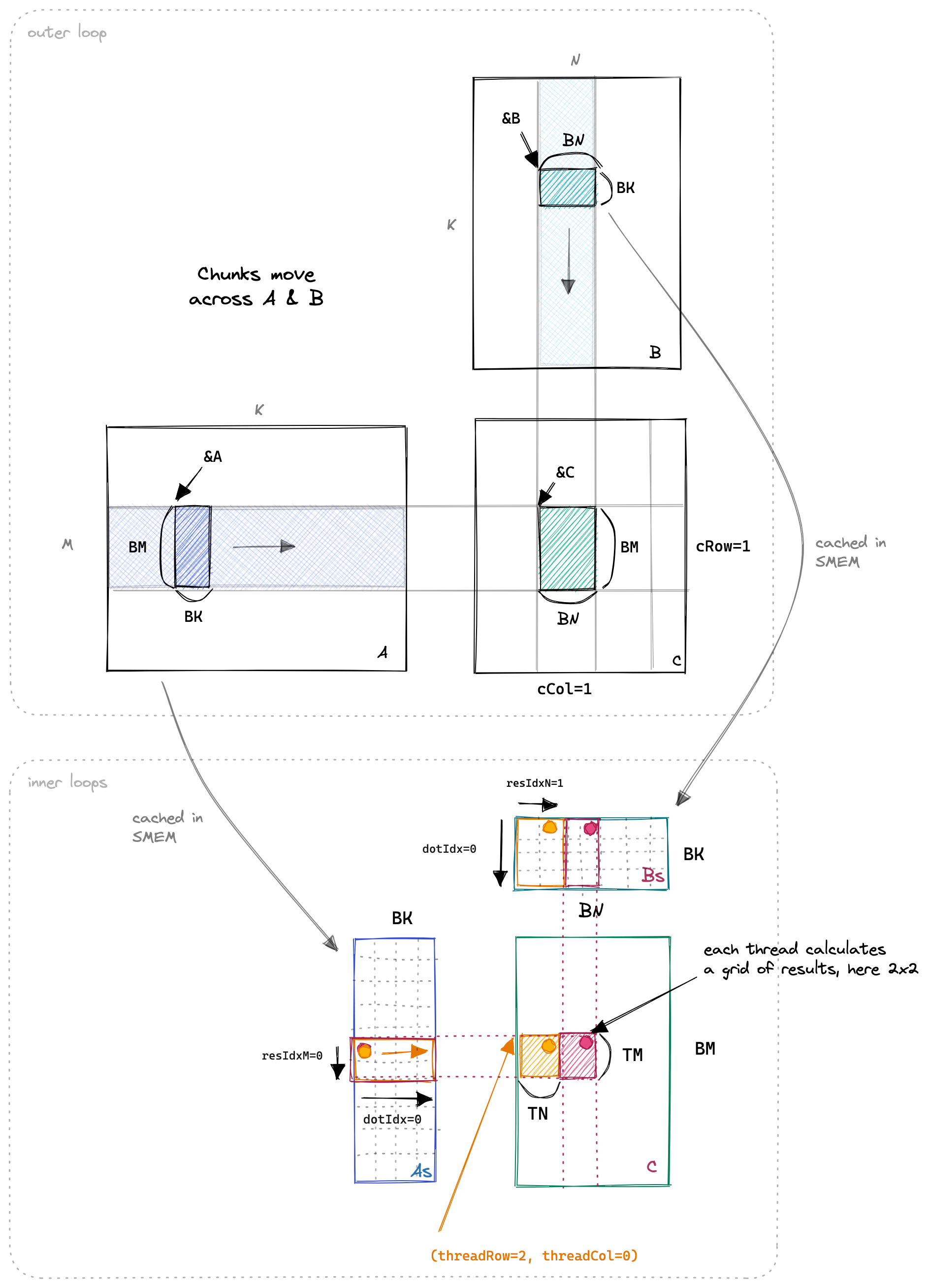
代码中有趣的部分如下所示:43
// allocate thread-local cache for results in registerfile float threadResults[TM * TN] = {0.0}; // register caches for As and Bs float regM[TM] = {0.0}; float regN[TN] = {0.0}; // outer-most loop over block tiles for (uint bkIdx = 0; bkIdx < K; bkIdx += BK) { // populate the SMEM caches for (uint loadOffset = 0; loadOffset < BM; loadOffset += strideA) { As[(innerRowA + loadOffset) * BK + innerColA] = A[(innerRowA + loadOffset) * K + innerColA]; } for (uint loadOffset = 0; loadOffset < BK; loadOffset += strideB) { Bs[(innerRowB + loadOffset) * BN + innerColB] = B[(innerRowB + loadOffset) * N + innerColB]; } __syncthreads(); // advance blocktile A += BK; // move BK columns to right B += BK * N; // move BK rows down // calculate per-thread results for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) { // load relevant As & Bs entries into registers for (uint i = 0; i < TM; ++i) { regM[i] = As[(threadRow * TM + i) * BK + dotIdx]; } for (uint i = 0; i < TN; ++i) { regN[i] = Bs[dotIdx * BN + threadCol * TN + i]; } // perform outer product on register cache, accumulate // into threadResults for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) { for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) { threadResults[resIdxM * TN + resIdxN] += regM[resIdxM] * regN[resIdxN]; } } } __syncthreads(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 译者注: Kernel 5 和 Kernel 4 的整体思路一致, 核心在于将一维分片改成了二维分片. 换句话说, 从 “仅将 As 的线程块分片进一步划分为线程分片” 到 “As 和 Bs 的线程块分片均进一步划分为线程分片”.
根据完整的 Kernel 5 代码可知:- 由于每个线程现在处理
TM*TN个元素, 因此 As 分片和 Bs 分片需要多次加载才能将其元素加载至共享内存. - 由于
threadCol = threadIdx.x % (BN / TN),threadRow = threadIdx.x / (BN / TN). 即相邻线程对应 Bs 分片的不同列线程分片、As 分片的同一行线程分块, 与先前 Kernel 的思路是一致的. for dotIdx循环仍然是线程块分片沿 K 维度逐一计算, 即每次 As 处理一列, Bs 处理一行.- 两个
for i循环将重复使用的线程分片元素加载至寄存器. 因为 Kernel 4 是一维块分片, 相当于TN=1, 这样regN就退化为了 Kernel 4 中的Btmp, 而由于TN=1, As 的线程分片不会被重复利用, 因此就没有regM. - 内层
for resIdxM和for resIdxN循环计算线程块分片的结果. 即依次迭代 As 分片dotIdx列的TM个元素和 Bs 分片dotIdx行的TN个元素, 计算总共TM*TN个值.
- 由于每个线程现在处理
在内层循环中, 我们可以通过将 dotIdx 作为外层循环, 并将两个内层循环所需的值显式加载到寄存器中, 来减少对 SMEM 的访问次数. 以下是随时间推移的 dotIdx 循环的图, 以直观地显示在每个步骤中哪些 SMEM 条目加载到线程本地寄存器中:44
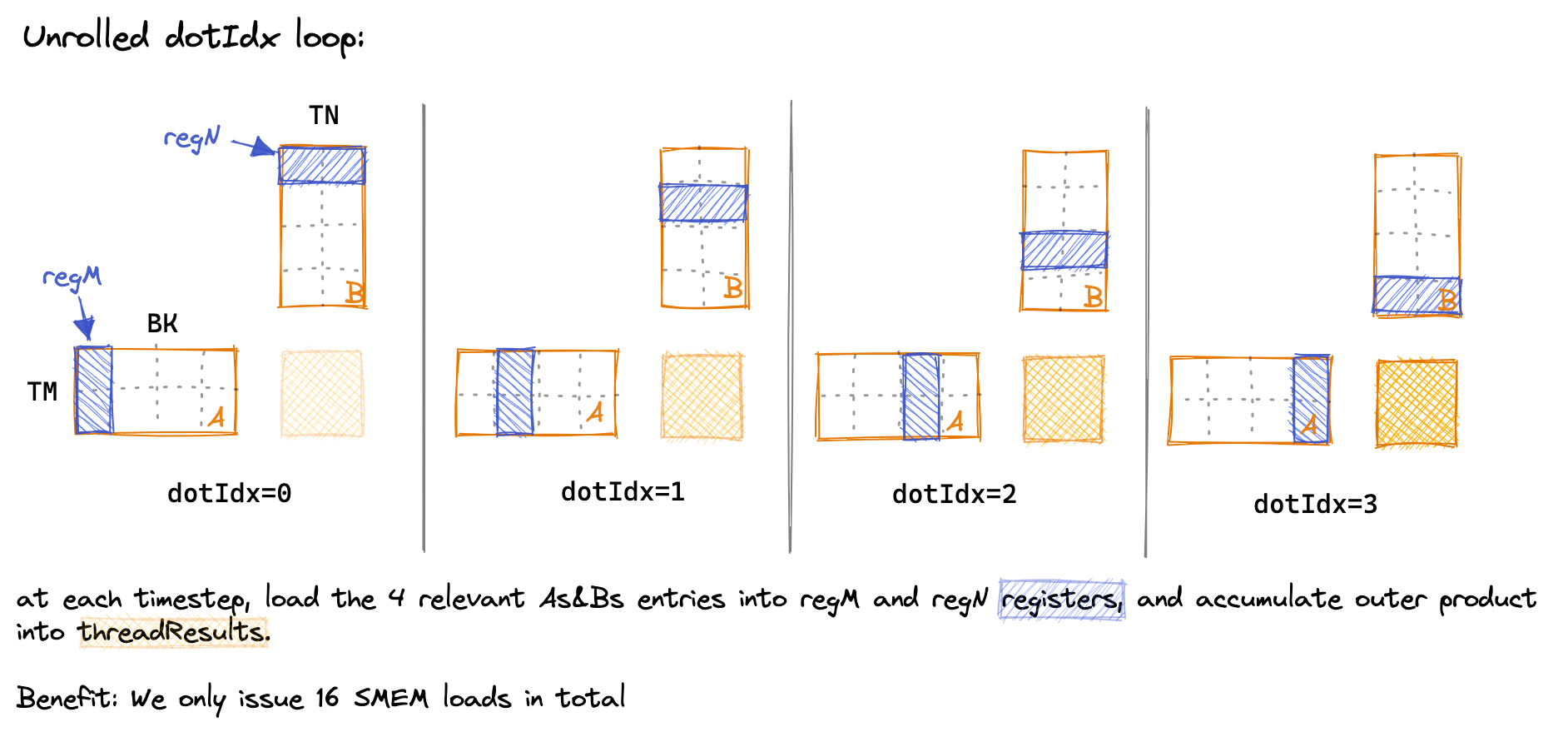
最终性能: 16TFLOP, 又提高了 2 倍. 让我们重复内存访问的计算. 我们现在每个线程计算 TM*TN=8*8=64 个结果.
- GMEM: K/8 (外层循环迭代) * 2 (A+B) * 1024/256 (sizeSMEM/numThreads) 次加载 (译者注: 每个线程块分片的 SMEM 大小为
BM*BK = BN*BK = 128*8 = 1024, 线程块大小为(BM*BN)/(TM*TN) = (128*128)/(8*8)=256) - SMEM: K/8 (外层循环迭代) * 8 (dotIdx) * 2 (A+B) * 8 次加载 (译者注: 8 次是因为每个线程对应 A 和 B 的线程分片大小的
TM = TN = 8) - 每个结果的内存访问: K/64 GMEM, K/4 SMEM (译者注: 上面两个计算结果再除以每个线程处理的
TM*TN=8*8=64个元素)
性能慢慢地达到了可以接受的水平, 但是, 由于内存流水线(memory pipeline)拥塞而导致的 warp 停滞仍然过于频繁. 对于 Kernel 6, 我们将采取两种措施来尝试改进这一点: 转置 As 以实现 SMEM 加载的自动向量化, 以及向编译器承诺在 GMEM 访问时的内存对齐.
Kernel 6: 向量化 SMEM 和 GMEM 访问
第一个优化是我之前已经暗示的转置 As. 这将允许我们从 As 加载时使用向量化 SMEM 加载(SASS 中的 LDS.128). 下面是与 Kernel 5 相同的三个内部循环的可视化, 但现在在内存中转置了 As:
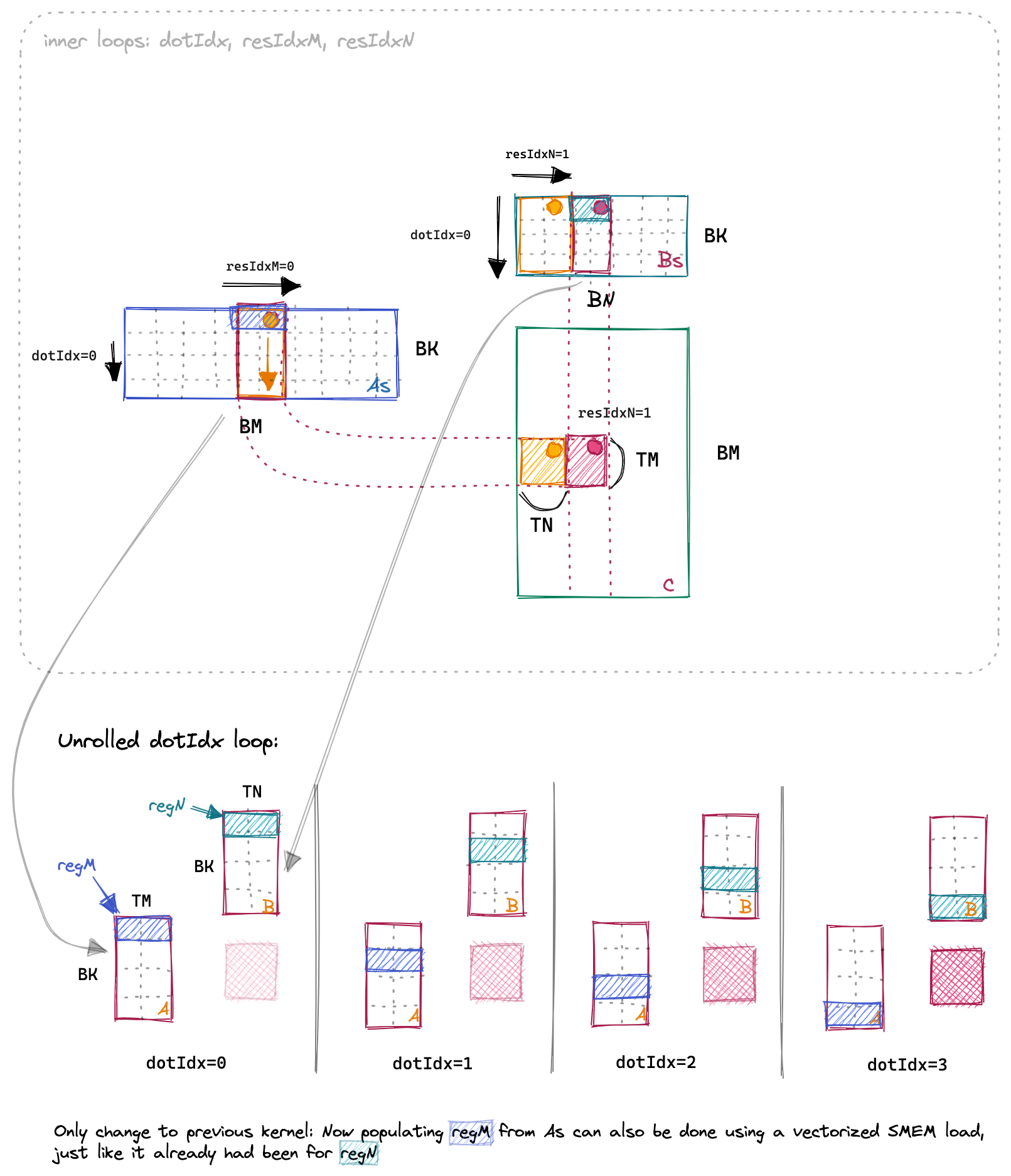
查看汇编45我们可以看到, 将 As 加载到寄存器过去是用的 32b 的 LDS 加载负载, 而现在是使用 128b 的 LDS.128 加载, 就像之前对 Bs 加载一样. 这使我们的速度提高了 500GFLOP, 或约 3%.
接下来, 我们将使用向量数据类型(即 float4)对 GMEM 的所有加载和存储进行向量化.
代码如下所示:46
float4 tmp =
reinterpret_cast<float4 *>(&A[innerRowA * K + innerColA * 4])[0];
// transpose A during the GMEM to SMEM transfer
As[(innerColA * 4 + 0) * BM + innerRowA] = tmp.x;
As[(innerColA * 4 + 1) * BM + innerRowA] = tmp.y;
As[(innerColA * 4 + 2) * BM + innerRowA] = tmp.z;
As[(innerColA * 4 + 3) * BM + innerRowA] = tmp.w;
reinterpret_cast<float4 *>(&Bs[innerRowB * BN + innerColB * 4])[0] =
reinterpret_cast<float4 *>(&B[innerRowB * N + innerColB * 4])[0];
__syncthreads();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这导致 32b GMEM 加载指令( LDG.E 和 STG.E)被 128b 对应指令(LDG.E.128 和 STG.E.128)所取代. 起初, 我很困惑为什么要运行此指令:
reinterpret_cast<float4 *>(&Bs[innerRowB * BN + innerColB * 4])[0] =
reinterpret_cast<float4 *>(&B[innerRowB * N + innerColB * 4])[0];
- 1
- 2
这将比只手动展开访问(或使用 pragma unroll)快吗:
Bs[innerRowB * BN + innerColB * 4 + 0] = B[innerRowB * N + innerColB * 4 + 0];
Bs[innerRowB * BN + innerColB * 4 + 1] = B[innerRowB * N + innerColB * 4 + 1];
Bs[innerRowB * BN + innerColB * 4 + 2] = B[innerRowB * N + innerColB * 4 + 2];
Bs[innerRowB * BN + innerColB * 4 + 3] = B[innerRowB * N + innerColB * 4 + 3];
- 1
- 2
- 3
- 4
难道编译器不应该只合并第二个版本并生成 128b 负载吗? 我认为原因是编译器无法验证传递给内核的 float* B指针是否与 128b 对齐, 这是使用 LDG.E.128 的要求. 因此, interpret_cast 的唯一目的是向编译器承诺 float* B指针是对齐的.47
Kernel 6 实现了 19TFLOP. profiler 仍然显示了一系列问题领域和优化机会: 我们遇到了共享内存的 bank 冲突 (bank conflict)(cuBLAS 避免了这一点), 我们的占用率高于必要水平, 而且我们还没有实现任何双缓冲(CUTRASS 文档似乎认为这非常有用).
但在我们讨论这些之前, 让我们讨论一些悬而未决的问题: 自动调整内核的参数.
Kernel 7: 通过线性化解决 bank conflict (译者补充)
在原作者的 Kernel 7 中, 通过对矩阵 B 的线程块分片加载到 SMEM 时进行了 swizzle 操作, 避免了从 Bs 加载到 regN 时的 bank conflict. (实际上只解决了读取共享内存的 bank conflict, 写入共享内存的 bank conflict 仍然存在.)
代码的核心变动为以下两处:
首先是 Bs 加载时:
float4 tmp =
reinterpret_cast<float4 *>(&A[innerRowA * K + innerColA * 4])[0];
As[(innerColA * 4 + 0) * BM + innerRowA] = tmp.x;
As[(innerColA * 4 + 1) * BM + innerRowA] = tmp.y;
As[(innerColA * 4 + 2) * BM + innerRowA] = tmp.z;
As[(innerColA * 4 + 3) * BM + innerRowA] = tmp.w;
reinterpret_cast<float4 *>(&Bs[innerRowB * BN + innerColB * 4])[0] =
reinterpret_cast<float4 *>(&B[innerRowB * N + innerColB * 4])[0];
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
改为:
// populate the SMEM caches
// transpose A while loading it
float4 tmp =
reinterpret_cast<float4 *>(&A[innerRowA * K + innerColA * 4])[0];
As[(innerColA * 4 + 0) * BM + innerRowA] = tmp.x;
As[(innerColA * 4 + 1) * BM + innerRowA] = tmp.y;
As[(innerColA * 4 + 2) * BM + innerRowA] = tmp.z;
As[(innerColA * 4 + 3) * BM + innerRowA] = tmp.w;
// "linearize" Bs while storing it
tmp = reinterpret_cast<float4 *>(&B[innerRowB * N + innerColB * 4])[0];
Bs[((innerColB % 2) * 4 + innerRowB * 8 + 0) * 16 + innerColB / 2] = tmp.x;
Bs[((innerColB % 2) * 4 + innerRowB * 8 + 1) * 16 + innerColB / 2] = tmp.y;
Bs[((innerColB % 2) * 4 + innerRowB * 8 + 2) * 16 + innerColB / 2] = tmp.z;
Bs[((innerColB % 2) * 4 + innerRowB * 8 + 3) * 16 + innerColB / 2] = tmp.w;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
然后:
// block into registers
for (uint i = 0; i < TM; ++i) {
regM[i] = As[dotIdx * BM + threadRow * TM + i];
}
for (uint i = 0; i < TN; ++i) {
regN[i] = Bs[dotIdx * BN + threadCol * TN + i];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
改为:
// block into registers
for (uint i = 0; i < TM; ++i) {
regM[i] = As[dotIdx * BM + threadRow * TM + i];
}
for (uint i = 0; i < TN; ++i) {
regN[i] = Bs[(dotIdx * 8 + i) * 16 + threadCol];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在此之前, 分析一下为什么读取共享内存时 Bs 会有 bank conflict 而 As 没有.
关键在于以下两个变量:
const int threadCol = threadIdx.x % (BN / TN);
const int threadRow = threadIdx.x / (BN / TN);
- 1
- 2
由于 BN/TN = 128/8 = 16, 所以在一个 warp 中的 32 个线程中, 每 16 个线程有相同的 threadRow 和不同的 threadCol.
- 对于 Kernel 6 的
As[dotIdx * BM + threadRow * TM + i]读取, 在dotIdx和i固定时, warp 中前 16 个线程访问同一地址, 后 16 个线程访问另一相同的地址, 两个地址间差TM即 8 个元素, 也就是 8 个 bank, 因此会通过广播机制使得没有 bank conflict 发生. - 对于 Kernel 6 的
Bs[dotIdx * BN + threadCol * TN + i]读取, 情况则不同, 对于 warp 的前 16 个线程, 由于threadCol彼此不同, 所以每个相邻线程访问的元素地址差TN, 即 8 个 bank. 这样导致threadIdx差 4 的线程访问的元素彼此相差 32, 从而造成了 bank conflict.
作者做出的改动即对原本的 Bs 线程块分片进行了 ROW=8, COL=16 的 swizzle, 可视化如下图所示:
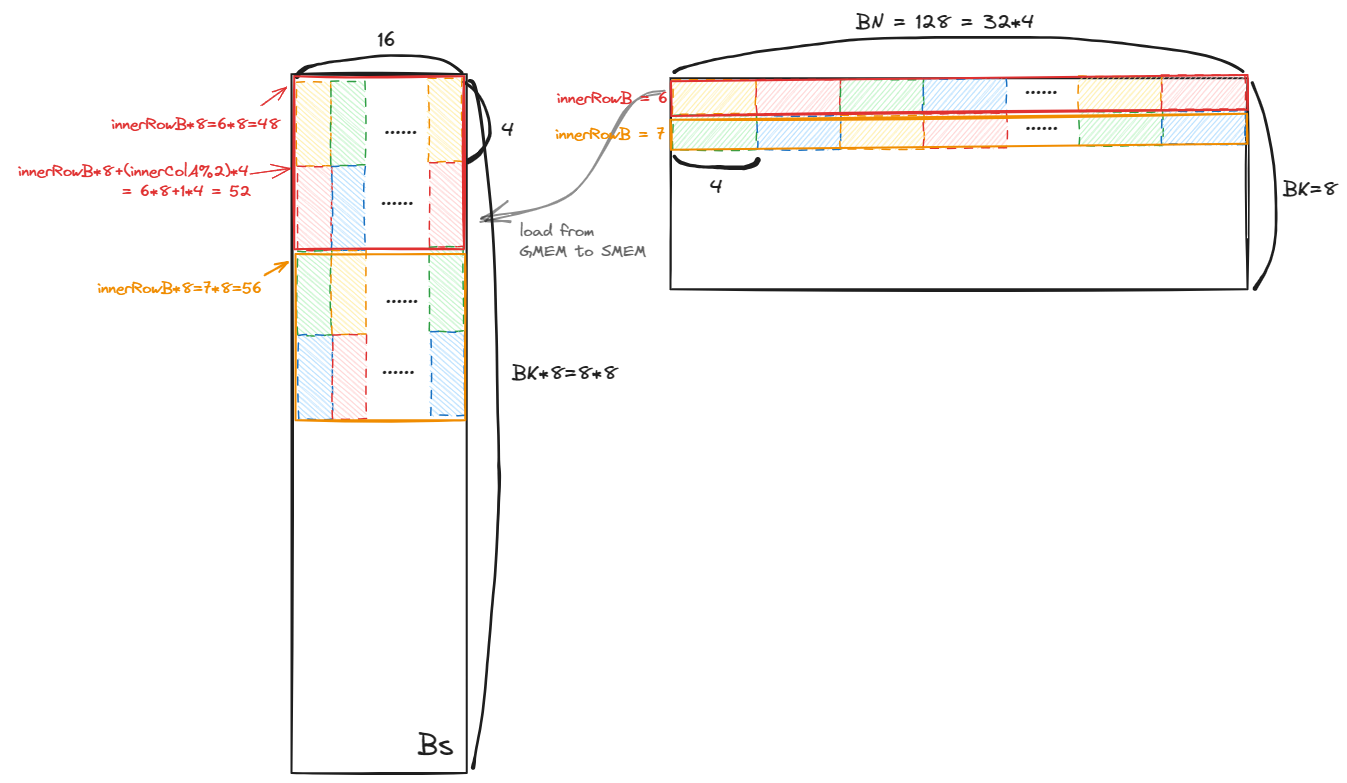
图中, 每个小颜色块对应一个线程, 每次从 GMEM 读取 4 个元素到 SMEM. 红色和橙色方框对应线程块分片的一行(在后续计算时, 有相同的 dotIdx). 所有尺寸的单位是 1 个元素即 float, 对应 32 字节 1 个 bank.
修改后, 读取 Bs 变为了 Bs[(dotIdx * 8 + i) * 16 + threadCol], 在同一 warp 中, 前 16 个线程读取的元素彼此差 1, 即对应 16 个不同的 bank. 而后 16 个线程与前 16 个线程访问的地址相同. 因此, 解决了 bank conflict. (在上图, 16 个线程读取的 Bs 分别对应 ROW=8, COL=16 的 swizzle 分块的每一列的 8 个元素, 即之前两个线程读取的元素, 对应一列的两个颜色块.)
这里选择 ROW=8, COL= 16 的原因是:
在 Bs 的读取阶段, 每个线程读取 8 个元素, 每 BN/TN=128/8=16 个线程读取相同的 128 个元素. 在上图中, ROW 恰好对应连续的两个小颜色块(即之前两个相邻线程读取)的元素. COL=16 使得在计算的时候, 相邻线程访存的元素是相邻的.
(理论上, COL 为 16 的倍数均可以避免 bank conflict, 因为 16 个线程每次迭代至多访问 16 个元素对应 16 bank, 但 COL 增大等会导致 ROW 减小, 致使相邻线程访问的元素不连续, 影响性能.)
值得一提的是, 作者在这里并没有解决 tmp 到 As 和 Bs 即共享内存读取时的 bank conflict:
- 对于
As[(innerColA * 4 + 0) * BM + innerRowA]写入, 同一 warp 中相邻的两个线程innerRowA相同,innerColA差 1, 访问的元素差4*BM=4*128=512, 对应同一个 bank. 这样同一 warp 中 32 个线程访问 16 个 bank 每个都有 1 个 bank conflict. - 对于 kernel 6 的
einterpret_cast<float4 *>(&Bs[innerRowB * BN + innerColB * 4])[0]向量化写入, 同一 warp 中 32 个线程innerRowB相同,innerColB彼此差 1, 因此threadIdx差 8 的线程访问元素差 32 个.
这里看似有 bank conflict, 但是并没有! 这里译者通过把As写入的部分注释掉再用 NVProf 检测发现的.
但如果去掉向量化写入改为Bs[innerRowB * BN + innerColB * 4] = B[innerRowB * N + innerColB * 4], 便会检测出 bank conflict.
笔者推断应该是 CUDA 对向量化访问进行了一定的优化, 避免了 bank conflict. (我猜测是因为如果没有额外优化, 向量化读取数据到共享内存必然会产生 bank conflict: 一个线程读 4 个大小为 4 字节的元素, 那么threadIdx差 8 的线程向量化的首元素差 32, 必然有 bank conflict, 所以 CUDA 对此进行了优化.) - 对于 kernel 7 的
Bs[((innerColB % 2) * 4 + innerRowB * 8 + 0) * 16 + innerColB / 2]写入,threadIdx差 1 的线程访问元素差4*16=64个, 有 bank conflict.
以下是 kernel 6 和 kernel 7 使用 nvprof 检测得到的 bank conflict 次数, 可以看到读取的 bank conflict 最少的情况下减少到 0; 而写入的 bank conflict 由于 Bs 写入操作的改变增加了 bank conflict.
但是相比与读取 conflict 的大幅减少, 读取增加的 conflict 相对更少, 整体上是正收益, 因此性能有一定提升.
Invocations Event Name Min Max Avg Total
Device "Tesla V100-SXM2-32GB (1)"
Kernel: void sgemmVectorize<int=128, int=128, int=8, int=8, int=8>(int, int, int, float, float*, float*, float, float*)
255 shared_ld_bank_conflict 8192 33609822 7680052 1958413308
255 shared_st_bank_conflict 540 2384733 539888 137671629
- 1
- 2
- 3
- 4
- 5
Invocations Event Name Min Max Avg Total
Device "Tesla V100-SXM2-32GB (1)"
Kernel: void sgemmResolveBankConflicts<int=128, int=128, int=8, int=8, int=8>(int, int, int, float, float*, float*, float, float*)
255 shared_ld_bank_conflict 0 33181 5656 1442492
255 shared_st_bank_conflict 1172 4731245 1079426 275253689
- 1
- 2
- 3
- 4
- 5
Kernel 8: 通过偏移解决 bank conflict (译者补充)
Kernel 8 相比 kernel 6 的变化也是两个地方:
const int extraCols = 5;
__shared__ float Bs[BK * (BN + extraCols)];
// ...
tmp = reinterpret_cast<float4 *>(&B[innerRowB * N + innerColB * 4])[0];
Bs[innerRowB * (BN + extraCols) + innerColB * 4 + 0] = tmp.x;
Bs[innerRowB * (BN + extraCols) + innerColB * 4 + 1] = tmp.y;
Bs[innerRowB * (BN + extraCols) + innerColB * 4 + 2] = tmp.z;
Bs[innerRowB * (BN + extraCols) + innerColB * 4 + 3] = tmp.w;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
for (uint i = 0; i < TN; ++i) {
regN[i] = Bs[dotIdx * (BN + extraCols) + threadCol * TN + i];
}
- 1
- 2
- 3
代码的核心是线程块分片 Bs 的宽度从 BN 变为了 BN+extraCols. 译者猜测应该属于通过 Padding 避免 bank conflict 的一种思路.
不过笔者并不是很理解这种方法, 因为从代码上来看, Bs[dotIdx * (BN + extraCols) + threadCol * TN + i] 在同一 warp 中仍然存在 threadIdx 差 4 的线程存在 bank conflict 的问题. 而且在从 GMEM 加载到 SMEM 时, 由于 extraCols 的引入使得字节不对齐而不能向量化加载, 又进一步增加了写入 Bs 的 bank conflict. (Kernel 7 时提到过, 写入 Bs 时 threadIdx 差 8 的线程存在 bank conflict, 但 Kernel 7 的向量化访存避免了这一点, 在此处则无法避免了.)
以下分别是 kernel 6 和 kernel 8 使用 nvprof 检测得到的 bank conflict 次数, 可以看到, 实际上 SMEM 读取和写入的 bank conflict 次数都有增加.
Invocations Event Name Min Max Avg Total
Device "Tesla V100-SXM2-32GB (0)"
Kernel: void sgemmVectorize<int=128, int=128, int=8, int=8, int=8>(int, int, int, float, float*, float*, float, float*)
255 shared_ld_bank_conflict 8192 33601588 7675626 1957284759
255 shared_st_bank_conflict 549 2444397 549564 140139007
- 1
- 2
- 3
- 4
- 5
Invocations Event Name Min Max Avg Total
Device "Tesla V100-SXM2-32GB (0)"
Kernel: void sgemmResolveBankExtraCol<int=128, int=128, int=8, int=8, int=8>(int, int, int, float, float*, float*, float, float*)
255 shared_ld_bank_conflict 11776 48292001 11033844 2813630341
255 shared_st_bank_conflict 2226 8829639 2016935 514318658
- 1
- 2
- 3
- 4
- 5
Kernel 9: 自动调整 (Autotuning)48
我们总共累积了五个模板参数:
BM、BN和BK, 它们指定了我们从 GMEM 缓存到 SMEM 的数据量.TM和TN, 它们指定了我们从 SMEM 缓存到寄存器中的数据量.
对于 Kernel 6, 这些设置为 BM=BN=128 和 BK=TM=TN=8. 我写了一个 bash 脚本, 它搜索所有合理的组合, 并对它们的运行时进行基准测试. 这要求我确保:
- 我知道哪些参数组合是合理的, 跳过那些不合理的.49
- Kernel 实现对于保留的大约 400 个不同的超参数设置是正确的.
对代码的必要修改最终花了相当长的时间来实现.
结果表明, 根据 GPU 模型的不同, 最佳参数变化很大.50 在我的 A6000 上, BM=BN=128 BK=16 TM=TN=8 将性能从 19 提升到 20 TFLOP, 提高了 5%. 在 A100 SMX4 40GB 上, 相同的配置达到了 12 TFLOP, 比自动调整器发现的最佳设置(BM=BN=64 BK=16 TM=TN=4)差6%, 后者达到了 12.6 TFLOPs.51
我无法解释为什么这些特定的参数最终会产生最佳性能. 自动调整是可行的, 每个高性能库都使用它, 但它也让人感到非常不满意.52
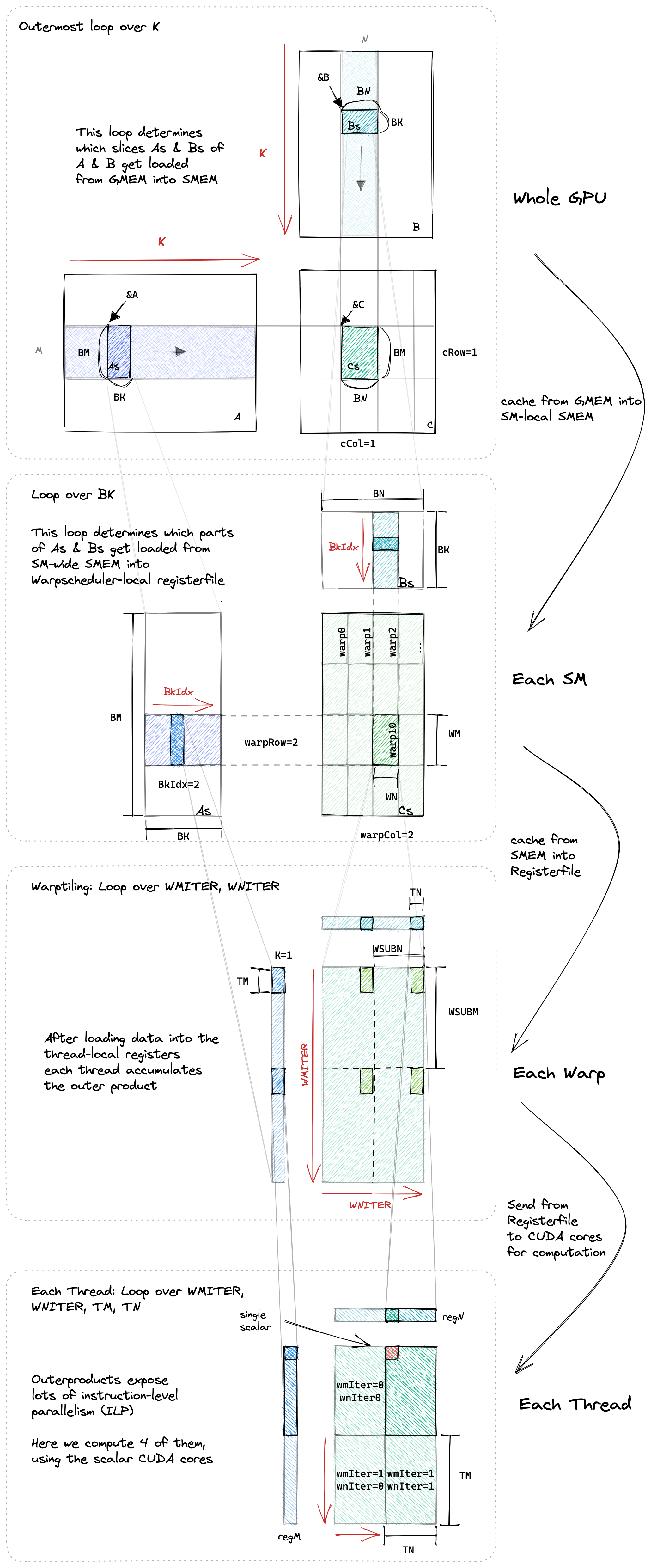
Kernel 10: warp 分片 (Warptiling)
目前, 我们的循环结构如下:

现在, 我们将在块分片和线程分片的循环之间添加另一个分片层次: warp 分片. warp 分片最初有点令人困惑, 因为与线程块和线程不同, warp 不会显式显示在 CUDA 代码中的任何位置. 它们是在标量 CUDA 软件世界中没有直接模拟的硬件功能. 我们可以将给定线程的 warpId 计算为 warpId=threadIdx.x % warpSize, 其中 warpSize 是一个内置变量, 在我使用过的任何 CUDA GPU 上都等于 32.
warp 与性能相关, 因为(除其他原因外):
- warp 是映射到作为 SM 一部分的 warp 调度器的调度单元.53
- 共享内存 bank 冲突(我将在未来的文章中介绍这些冲突)只发生在同一 warp 中的线程之间.
- 最近的 GPU 上有一个寄存器缓存, 更紧密的线程划分为我们提供了更多的寄存器缓存位置.
warp 分片是优雅的, 因为我们现在明确了所有层次的并行性:
- 线程块分片(blocktiling): 不同的线程块可以在不同的 SM 上并行执行.
- warp 分片(warptiling): 不同的 warp 可以在不同的 warp 调度器上并行执行, 也可以在同一个 warp 调度器上并发执行.
- 线程分片(threadtiling): (数量非常有限的)指令可以在相同的 CUDA 内核上并行执行(=指令级并行, instruction-level parallelism, 即 ILP).
warp 分片的 CUDA 代码如下所示:54
// dotIdx loops over contents of SMEM for (uint dotIdx = 0; dotIdx < BK; ++dotIdx) { // populate registers for this thread's part of the warptile for (uint wSubRowIdx = 0; wSubRowIdx < WMITER; ++wSubRowIdx) { for (uint i = 0; i < TM; ++i) { regM[wSubRowIdx * TM + i] = As[(dotIdx * BM) + warpRow * WM + wSubRowIdx * WSUBM + threadRowInWarp * TM + i]; } } for (uint wSubColIdx = 0; wSubColIdx < WNITER; ++wSubColIdx) { for (uint i = 0; i < TN; ++i) { regN[wSubColIdx * TN + i] = Bs[(dotIdx * BN) + warpCol * WN + wSubColIdx * WSUBN + threadColInWarp * TN + i]; } } // execute warptile matmul. Later this will map well to // warp-wide matrix instructions, executed on tensor cores. for (uint wSubRowIdx = 0; wSubRowIdx < WMITER; ++wSubRowIdx) { for (uint wSubColIdx = 0; wSubColIdx < WNITER; ++wSubColIdx) { // calculate per-thread results with register-cache locality for (uint resIdxM = 0; resIdxM < TM; ++resIdxM) { for (uint resIdxN = 0; resIdxN < TN; ++resIdxN) { threadResults[(wSubRowIdx * TM + resIdxM) * (WNITER * TN) + (wSubColIdx * TN) + resIdxN] += regM[wSubRowIdx * TM + resIdxM] * regN[wSubColIdx * TN + resIdxN]; } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 译者注: 根据 Kernel 10 完整代码可知:
WN = 64,WM = 32, 表示矩阵 C warp 分片 M 和 N 维的元素个数, 即 warp 分片大小;
warpIdx = threadIdx.x / WARPSIZE,,warpRow = warpIdx / (BN / WN),warpCol = warpIdx % (BN / WN), 分片表示线程所在 warp 的 ID, 以及 warp 在线程块分片的行列索引;
WNITER = 2,WMITER = (WM * WN) / (WARPSIZE * TM * TN * WNITER), 分别表示 warp M 和 N 维度需要在 warp 分片内迭代的次数.
WSUBM = WM / WMITER(32/2 = 16),WSUBN = WN / WNITER(64/2 = 32), 分别表示 warp 每次迭代时, M 和 N 维度需要处理的元素数
regM[WMITER * TM] = {0.0},regN[WNITER * TN] = {0.0}. 表示每个线程缓存的线程分片. 与 Kernel 5 不同的是, 数组大小分别乘以了WMITER和WNITER, 因为 warp 分片在 M 和 N 维度上仍需要循环迭代, 而之前可以理解为WMITER和WNITER均为 1. 同样的, 这也致使每个线程计算的矩阵 C 的结果数多了WMITER * WNITER倍, 因此threadResults[WMITER * TM * WNITER * TN] = {0.0}.
threadIdxInWarp = threadIdx.x % WARPSIZE,threadColInWarp = threadIdxInWarp % (WSUBN / TN)(i%(32/4) ),threadRowInWarp = threadIdxInWarp / (WSUBN / TN)(i/8), 分别表示 warp 内每个线程的 lane id, 以及在 warp 中的行列索引.- 外层
for dotIdx仍然是沿 A 和 B 线程块分片的 K 维逐一计算, 即每次 As 处理一列, Bs 处理一行. for wSubRowIdx循环和for wSubColIdx循环分别将 warp 分片包含的元素从共享内存中的 As 和 Bs 分片的列和行加载到寄存器中.
以 As 线程块分片为例, 每次 warp 迭代每个线程仍读取TM个元素到寄存器数组regM. 读取的 As 线程块分片的索引为(dotIdx * BM) + warpRow * WM + wSubRowIdx * WSUBM + threadRowInWarp * TM + i, 要注意, As 分片在加载时数据进行了转置, 可以理解为此时数据排布为列主序,
(dotIdx * BM)表示 As 分片的第dotIdx列;
warpRow * WM表示当前 warp 需要处理的元素的起始索引(同一 warp 在 M 维度迭代的WMITER次读取的数据是连续排布的, 构成一个 warp 分片的数据, 大小为WM, 即下图中第 2 部分到第 3 部分的转换);
wSubRowIdx * WSUBM表示 warp 在当前wSubRowIdx次迭代时处理元素的起始索引(每次迭代 warp 处理WSUBM个元素);
threadRowInWarp * TM表示 warp 中当前线程处理的TM个元素的起始索引;’
i表示TM个元素中的第i个.
相比于 Kernel 5, 此处 warptiling 带来的变化主要有两点: 一是以 warp 角度进行索引(实际上代表了将元素映射到唯一的 warp 上); 二是需要 warp 迭代WMITER次.
Bs 线程块分片与此相同, 在此不再赘述.- 接下来的四层嵌套循环用于执行 warp 分片粒度的矩阵乘, 相比 Kernel 5, 多了外面
for wSubRowIdx和for wSubColIdx两层循环, 分别进行 warp 在 M 和 N 维度的迭代. - 关于 warp 分片的理解:
对于只进行线程块分片和线程分片的 kernel 5, 在处理线程块分片As的dotIdx列和Bs的dotIdx行时, 是将整行和整列映射到所有线程上, 具体来说, 每 16 个相邻线程对应Bs的整行元素和As的列中的TM个元素, 不同的 16 个线程对应As列中的不同元素.
而在 Kernel 10 中,As的dotIdx列的每BM个元素对应 1 个 warp,Bs的dotIdx行中的每BN个元素对应 1 个 warp. 在这个大小为BM*BN的分片中, warp 的 32 个线程 1 次迭代处理WSUBM*WSUBN大小的小分片, 这个小分片的处理方式就和 Kernel 5 中处理BM*BN大小的线程分块一样了, 后续再进行线程分片.
译者个人对进行 warp 分片处理的理解是: 在这之前, 每个 warp 都会读取Bs整行的数据和As的2*TM个数据, 不同 warp 间在Bs的读取上重复性太高, warp 内As上读取的重复性太高, 像是两个极端; 而进行了 warp 分片之后,Bs只有一部分分给该 warp ,As分给该 warp 的数据变多, 缓和了上面的问题, 使得 warp 数据的利用更集中, 同时引入 warp 层次可以更好地解决 bank conflict. (译者个人猜测, 不代表正确).
尽管结构变得非常复杂, 但我还是尽了最大的努力将所有三个层次的分片都进行了可视化.55 每个 warp 将计算大小为 (WSUBN * WNITER) X (WSUBM * WMITER) 的块. 每个线程计算 WNITER * WMITER 次大小为 TM*TN 的分块.
- 译者注:
- Kernel 10 关于从 GMEM 加载线程块分片到 SMEM 也有一些变化:
for (uint offset = 0; offset + rowStrideA <= BM; offset += rowStrideA) { const float4 tmp = reinterpret_cast<const float4 *>( &A[(innerRowA + offset) * K + innerColA * 4])[0]; As[(innerColA * 4 + 0) * BM + innerRowA + offset] = tmp.x; As[(innerColA * 4 + 1) * BM + innerRowA + offset] = tmp.y; As[(innerColA * 4 + 2) * BM + innerRowA + offset] = tmp.z; As[(innerColA * 4 + 3) * BM + innerRowA + offset] = tmp.w; } for (uint offset = 0; offset + rowStrideB <= BK; offset += rowStrideB) { reinterpret_cast<float4 *>( &Bs[(innerRowB + offset) * BN + innerColB * 4])[0] = reinterpret_cast<const float4 *>( &B[(innerRowB + offset) * N + innerColB * 4])[0]; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
offset的循环. 其中rowStrideA = (NUM_THREADS * 4) / BK,rowStrideB = NUM_THREADS / (BN / 4), 即增加了行步幅偏移量: 对于线程块分片As, 行步幅为整个线程块读取的元素数NUM_THREADS * 4除以线程块分片宽度BK; 对于线程块分片Bs, 行步幅同理(分子分母同乘 4). 这样做是考虑到线程块一次读取的元素数(NUM_THREADS * 4)小于线程块分片大小(BM*BK=128*16)的情况, 将线程块分片的元素按行步幅, 分次加载, 更具有通用性. Kernel 6 及之前是因为线程块一次读取的元素与线程块分片大小是恰好相等的, 所以无需循环. - 关于 bank conflict:
- 从 GMEM 加载到 SMEM: 这里的代码虽然添加了步幅, 但与 kernel 6 的代码基本是一致的. 即:
对于As,threadIdx差 1 的线程innerColA差 1, 访问的元素差4*BM=4*128=512, 对应同一个 bank, 有 bank conflict;
对于Bs由于向量化合并写入而没有 bank conflict. - 从 SMEM 加载到寄存器:
对于As[(dotIdx * BM) + warpRow * WM + wSubRowIdx * WSUBM + threadRowInWarp * TM + i], warp 中每 4 个线程对应同一个threadRowInWarp(取值范围 0 ~7), 因此i一定时,threadRowInWarp相同的 4 个线程对应访问相同的 4 个元素, 8 组恰好对应 32 个元素 32 个 bank, 没有 bank conflict.
对于Bs[(dotIdx * BN) + warpCol * WN + wSubColIdx * WSUBN + threadColInWarp * TN + i], warp 中每 4 个线程对应threadColInWarp的 0~3, 因此, 共访问4*TN=4*4=16个元素, 对应 16 个 bank, 也没有 bank conflict.
- 从 GMEM 加载到 SMEM: 这里的代码虽然添加了步幅, 但与 kernel 6 的代码基本是一致的. 即:
- Kernel 10 关于从 GMEM 加载线程块分片到 SMEM 也有一些变化:
在自动调整参数后, A100 的性能从 19.7 TFLOP 提高到了 21.7 TFLOP. 下图展示了在不断增加的矩阵大小下, 我们的 warp 内核与 cuBLAS 的比较:56
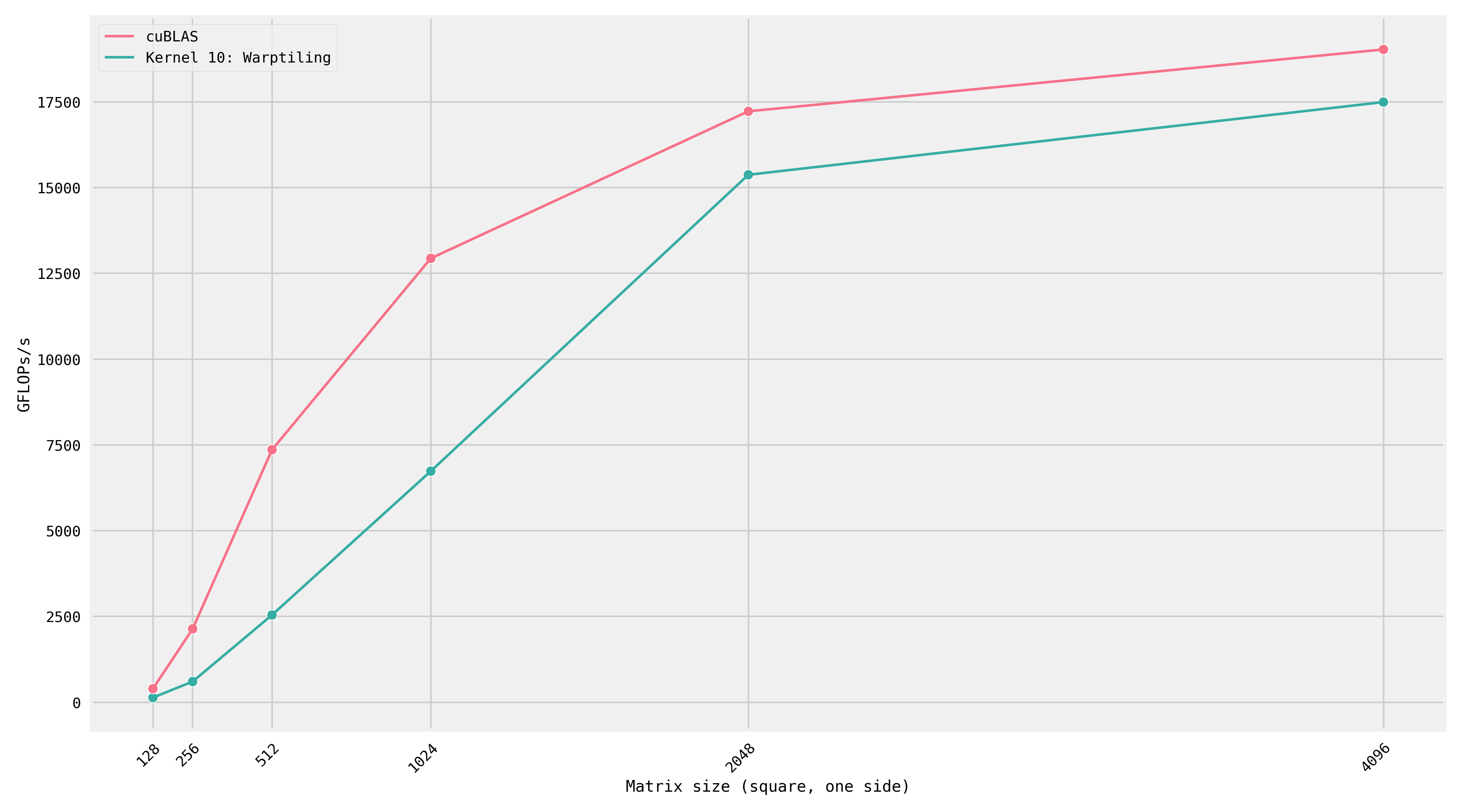
在 2048 和 4096 维度上, 我们测量的 FLOP 仅比 cuBLAS 慢几个百分点. 然而, 对于较小的矩阵, 与英伟达的库相比, 我们做得很差! 之所以会出现这种情况, 是因为 cuBLAS 不只包含了 SGEMM 的一个实现, 而是包含了数百个实现.57 在运行时, cuBLAS 将根据维度选择运行哪个内核.58 我跟踪了 cuBLAS 调用, 以下是它在每个大小下调用的内核:59
| Matrix size | Name | Duration |
|---|---|---|
| 128 | ampere_sgemm_32x32_sliced1x4_nn | 15.295 μs |
| 256 | ampere_sgemm_64x32_sliced1x4_nn followed by splitKreduce_kernel | 12.416 μs + 6.912 μs |
| 512 | ampere_sgemm_32x32_sliced1x4_nn | 41.728 μs |
| 1024 | ampere_sgemm_128x64_nn | 165.953 μs |
| 2048 | ampere_sgemm_128x64_nn | 1.247 ms |
| 4096 | ampere_sgemm_128x64_nn | 9.290 ms |
在 256 维时, 它调用两个内核: 一个矩阵乘内核, 后面跟着一个归约内核.60 因此, 如果我们试图编写一个适用于所有形状和大小的高性能库, 我们将针对不同的形状进行特化, 并在运行时选择最适合的内核进行调度.
我还想报告一个负面的结果: 对于这个内核, 我额外实现了一个名为线程交错(thread swizzling)的优化. 该技术假设线程块是按照增加 blockIdx 的顺序启动的, 并优化 blockIdx 到 C 的分块的映射的方式来增加 L2 局部性.61 这篇 Nvidia 的帖子有更多的信息和可视化. 它并没有提高性能, 大概是因为 L2 的命中率已经相当高, 达到了 80%, 所以我最终删除了令人眼花缭乱的代码.62
将 BK 循环移到外部是有道理的, 因为它符合我们的原则: “加载一些数据, 然后在该数据上尽可能多地进行工作”. 这进一步意味着在 BK 循环内部发生的所有计算都是独立的, 可以并行化处理(例如使用 ILP).
我们现在也可以开始预取下一次循环迭代所需的数据, 这是一种称为双缓冲(double buffering)的技术.
正在进行的工作: Kernel 11
如果我重新回到这篇文章的工作, 下面是我接下来要看的内容:
- 双缓冲, 用于更好地交错计算和内存加载. 现在, 请参见 CUTLASS 流水线. 在 CUTLASS 中, 双重缓冲在两个级别上完成: GMEM ⇒ SMEM 和 SMEM ⇒ 寄存器文件.
- 在 Hopper 架构中, 为 warp 特化引入了新的指令, 例如让一些 warp 比其他 warp 使用更少的寄存器. 这与特殊指令相结合, 可以从 GMEM 直接加载到 SMEM 而无需首先通过寄存器, 可用于降低寄存器压力.
- 消除 SMEM bank conflict. 这可以通过优化 SMEM 中的数据布局来实现.
- 通过查看生成的 PTX, 更好地理解在 Triton 中实现的 GEMM 内核.
Kernel 11: 双缓冲 doubleBufferIdx 实现 (译者补充)
原文作者在其 GitHub 中更新了后续使用双缓冲从全局内存加载数据到共享内存的 kernel 11 实现.
在 kernel 11 中, 关键是通过变量 bool doubleBufferIdx = threadIdx.x >= (NUM_THREADS / 2); 将线程块中的线程前后分为两部分, 每一部分分别加载一个线程块分片(包括 As 和 Bs), 然后分别计算每个线程块分片的一部分. 下图是一个简单的可视化:
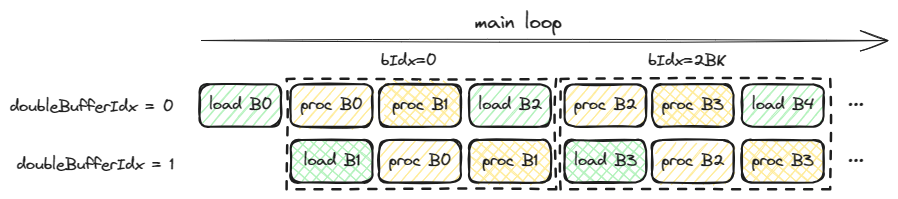
在图中, 每个分块分别用绿色代表一个 load (从 GMEM 加载线程块分片到 SMEM) 操作, 用黄色代表一个 process (对线程块分片进行矩阵乘) 操作. 同一个分片用同一种背景纹路表示. 虚线框表示 for bIdx 循环(即最外层沿 K 维度遍历线程块分片的循环)的一次迭代.
在图中可以看到, doubleBufferIdx 为 0 和 为 1 的两部分线程分别加载一个线程块分片, 比如 B0 和 B1. 然后两部分线程分别再处理 B0 和 B1 线程块分片的矩阵乘计算. 这里每个线程块分片被两部分线程都计算的原因是, 在计算矩阵乘时, 作者的实现中每个线程还是和 Kernel 10 一样按照线程所在的 warp 拿取数据并计算, 换句话说, 线程块内每部分线程完成计算到每个线程块分片的一半计算; 而不像加载时, 每部分线程是可以将一整个完整线程块分片从 GMEM 读取的.
值得一提的是, 译者对双缓冲的实现存在疑问, 不是很清楚读取与计算间的同步关系是如何保证的(比如, doubleBufferIdx=0 的线程处理 B1 时如何保证 doubleBufferIdx=1 的线程已经加载 B1 完毕). 可能是通过 __syncthreads() 函数保证的? 但是在 CUDA C++ 编程指南 中提到, “__syncthreads() is allowed in conditional code but only if the conditional evaluates identically across the entire thread block, otherwise the code execution is likely to hang or produce unintended side effects”, 即 __syncthreads() 只有在线程块的所有线程计算结果相同时才被允许用于条件分支, 而在作者的代码中显然不满足, 因此实现上这里应该是存在一定问题的. 但是代码确实可以通过编译且正常运行.
根据 README 来看 Kernel 11 的实际性能并不很理想, 但在译者 V100 上进行测试, 性能与 kernel 10 是相当的, 差距不大.
Kernel 12: 双缓冲 cuda::memcpy_async 实现 (译者补充)
原文作者在其 GitHub 中更新了后续使用双缓冲从全局内存加载数据到共享内存的 kernel 12 实现.
在 kernel 12 中, 作者使用了 CUDA 异步操作的一些 API, 包括 cuda::barrier, cuda::memcpy_async() 等, 来异步的从 GMEM 加载数据到 SMEM, 从而达到加载到 SMEM 和进行矩阵乘计算的 overlap. 相比于 kernel 11, 译者认为这应该是更正确的实现方式.
Kernel 12 的整体思路与 kernel 11 是一致的, 代替 doubleBufferIdx 的是由 frontBarrierPtr 和 backBarrierPtr 指向的两个 cuda::barrier. 下图是一个简单的可视化:
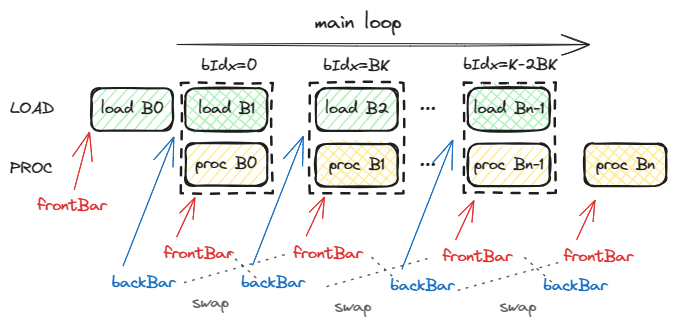
在迭代过程中, 一个 barrier 负责异步从 GMEM 加载一个线程块分片到 SMEM, 另一个 barrier 负责计算上一个加载的线程块分片的矩阵乘结果, 在最后通过交换两个 barrier 的指针, 达到双缓冲的目的.
进一步来说, 在迭代线程块分片前 frontBarrierPtr 加载一个线程块分片 B0; 进入迭代后, 由 backBarrierPtr 异步加载写一个分片; 而 frontBarrierPtr 通过 arrive_and_wait() 函数等待上一个分片加载完毕, 然后指向后面的矩阵乘计算; 计算结束后, 交换两个 barrier 的指针, 这样下一个迭代时, 计算的 barrier 是上一次迭代时加载数据的 barrier, 保证了线程块分片加载后才被计算. 在循环迭代后, 最后一个加载的线程块分片单独计算.
与 kernel 11 不同的是, kernel 12 的加载与计算的 overlap 不需要对线程块中的线程进行划分, 用 CUDA C++ 编程指南中的话来说, 异步操作就像是另一个线程异步执行的一样, 因此在这里加载和计算都是整个线程块线程对一个线程块分片进行的.
额外一提, 异步操作需要 7.0 及其以上算力的 GPU 设备, 且在 8.0 及其以上的设备上会有硬件加速.
译者在 V100(7.0 算力) 上测试 kernel 12, 发现性能并不理想, 且又出现了 memory bound 的情况(随着计算强度的增加, 在 kernel 5 之后内核变为了 compute bound), 性能甚至不如 kernel 4, 译者推测异步操作可能需要 8.0 以上硬件加速的情况下才能取得较好的性能(比如, cuda::memcpy_async() 在 8.0 即以上算力的设备上可以直接从GMEM 拷贝数据到 SMEM 而无需寄存器过渡). 由于译者没有 8.0 以上算力的 GPU, 此处还待验证.
总结
写这篇文章的经历与我上一篇关于优化 CPU 上的 SGEMM 的文章类似: 迭代优化 SGEMM 是深入了解硬件性能特征的最佳方法之一. 对于编写 CUDA 程序, 我感到惊讶的是, 一旦我对希望的内核工作方式进行很好地可视化后, 实现代码变得十分容易.
此外: 幂律定律无处不在. 我花了两个周末的时间写了前 6 个内核, 它们达到了峰值 FLOP 的 80%, 然后又花了 4 个周末进行了自动调整和 warp 分片, 达到了 94%. 我在写这段代码时学到的东西也越来越少, 所以我把寻找最后 6% 的东西推迟到未来的某个时候.
我所有的代码都可以在 Github 上找到.
最后, 非常感谢 Godbolt.org (查看 PTX 和 SASS 汇编) 和 Excalidraw (绘制 Kernel) 的创建者! 这两种工具使用起来都很愉快, 帮助我更快地学习.
其他资源和参考资料
- 我之所以开始写这篇文章, 是因为我偶然发现了 wangzyon 的 Github 仓库, 我首先尝试了他的内核, 然后从头开始重写所有内容. 同样相关的还有这篇关于 CUTLASS 库的英伟达博客文章.
- 必备参考资料: 官方的 CUDA 工具包编程指南和 CUDA 最佳实践指南. 内核性能分析指南还包含有关低级硬件细节(如缓存和流水线)以及可收集的各种指标的更多信息.
- Onur Mutlu 是 ETH 的教授, 他将自己的讲座上传到 Youtube 上. 与这篇文章特别相关的是计算机体系结构和异构系统的加速.
- 理解 GPU 上的延迟隐藏(Understanding Latency Hiding on GPUs,), 这是一篇深入研究如何设计工作负载以充分利用内存带宽和计算的博士论文. 它来自 2016 年, 因此只涵盖较旧的 GPU 架构. 关于 warp 同步编程的章节已经过时, 请参阅使用 CUDA warp 级原语.
- 毛磊(英伟达的工程师)在他的博客上有很好的 CUDA 内容, 包括正确处理 CUDA 错误.
- 似乎没有任何好的官方资源来理解 SASS. 这是关于 CUDA 二进制实用程序的英伟达文档. 更有用的可能是查看开源 SASS 汇编程序, 比如 Da Yan 的 turingas.
- 我正在收集可读但经过优化的 CUDA 代码示例, 以供学习:
- ONNX Runtime’s CUDA provider, 例如他们对 softmax 的实现.
- 英伟达的开源 CUTLASS 库, 例如他们的 GEMM 实现, 它使用双缓冲来预取最内层的维度, 这在我的内核中仍然缺失.
您可以从 GitHub 下载所有内核的代码. 还可以查看 wangzyon 的仓库, 我从那里复制了基准测试的设置. ↩︎
这篇帖子没有我正常上传的那么细致, 而且包含了更多的旁注. 我把它当作记事本, 用来记录想法, 并在写内核时乱涂乱画. 这就是为什么我称之为工作日志
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/467893
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

