
- 1SQL Server 2019安装教程(非常详细),从零基础入门到精通,看完这一篇就够了(附安装包)_sqlserver2019安装步骤教程
- 2PyTorch与深度学习:探索现代神经网络的魅力
- 3FPGA纯verilog实现UDP通信,三速网自协商仲裁,动态ARP和Ping功能,提供工程源码和技术支持_xilinx udp实现原理
- 4Springboot项目中出现Redis-Unable to connect to 127.0.0.1:6379
- 5hadoop+zookeeper高可用性集群出现两个namenode均为standby状态原因及解决方法_hdfs 高可用之后两个几点都是备用节点
- 6Git版本管理(02)patch操作和分支操作整理_git patch
- 7WebRTC源码研究(23)WebRTC网络传输基本知识_esp32 webrtc
- 8免费的 ChatGPT、GPTs、AI绘画(国内版)_免费的chatgpt
- 9LeetCode热题100道_leetcode热门100题
- 10GitHub搜索指令教程
Apache Doris使用总结_doris中文官网
赞
踩
前提:已有多年大数据经验,熟悉多种架构,与其他框架类比后总结的doris一些特性,新手勿入
1. Doris基础学习
中文官网:https://doris.apache.org/zh-CN/docs/dev/summary/basic-summary/
1.1 doris 简介
Apache Doris 是一个现代化的 MPP(Massively Parallel Processing,即大规模并行处理) 分析型数据库产品
亚秒级响应时间即可获得查询结果
可以支持 10PB 以上的超大数据集
满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式 数据分析和探索式数据分析等

1.2 Doris 架构

Doris 的架构很简洁,只设 FE(Frontend)、BE(Backend)两种角色、两个进程,不依赖于 外部组件,方便部署和运维,FE、BE 都可线性扩展。
-
FE(Frontend):存储、维护集群元数据;负责接收、解析查询请求,规划查询计划, 调度查询执行,返回查询结果。主要有三个角色:
-
Leader 和 Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下, 元数据能够实时地在线恢复,而不影响整个服务。
-
Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力 非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不 参与任何的写入,只参与读取。
-
BE(Backend):负责物理数据的存储和计算;依据 FE 生成的物理计划,分布式地执行查询。
-
数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据 需求动态调整。
-
MySQLClient
Doris 借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC 以及 MySQL 的客户
端,都可以直接访问 Doris。
-
Broker
Broker 为一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统 中文件的能力,包括 HDFS,S3,BOS 等。
1.3 基本概念
doris因为是mysql协议所以体验上和mysql很相似
-
首先DDL和DML语法上基本和mysql相同
-
和 mysql一致,拥有Row & Column & table等概念
不同的是
-
doris的Column分为 Key 和 Value,key有点类似mysql的索引,同时提供索引的快速查询功能
-
doris 的 value 可以根据key自动聚合,也就是doris的数据模型
2. doris 讲解
2.1 数据模型
doris字段分为key和value,key有以下几种方式
| 模型 | 特点 | 优势 | 劣势 | 建表指定 |
| aggregate模型 | 按照key进行预聚合 目前有四种聚合方式:
| 降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景 | 对count()查询很不友好 固定了聚合方式 例:已经设置了max聚合,表取数对该字段min求最小值就会出现不一致问题 不保留明细数据,只有聚合后的数据 解决:key加上时间戳 | AGGREGATE KEY(`user_id`, `date`) |
| uniq模型 | 唯一Key,同一key数据自动覆盖,本质上是聚合模型的replace | 保证 Key 的唯一性 | 无法利 用 ROLLUP 等预聚合带来的查询优势 | UNIQUE KEY(`user_id`, `date`) |
| duplicate模型 | 既没有主键,也没有聚合需求时 | 不受聚合模型的约束,可以发挥列模型的优势 | 无法利 用 ROLLUP 等预聚合带来的查询优势 | DUPLICATE KEY(`user_id`, `date`) |
2.2 分区、分桶
doris 也有分区和分桶,但和hive不同
Table是有很多分区Partition的
Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行(不能直接操作Tablet)。
一个 Partition包含多个数据分片Tablet组成,Tablet 包含若干数据行
所以本质上Tablet 是数据移动、复制等操作的最小物理存储单元,一定要设置分桶,可以不设置分区
2.2.1分区
可以设置多列分区,但是分区字段必须为 KEY 列
不会改变已存在分区的范围,也就是删除分区后不会把删除的分区的归类到下个分区,而是出现空洞,除非重建分区,否则这部分数据插入会报找不到分区的错误
-
range分区
-
- #通常为时间列,范围划分分区
- PARTITION BY RANGE(`date`)
- (
- PARTITION `p201701` VALUES LESS THAN ("2017-02-01"),
- PARTITION `p201702` VALUES LESS THAN ("2017-03-01"),
- PARTITION `p201703` VALUES LESS THAN ("2017-04-01")
- )
- #删除分区会出现空洞
- p201701: [MIN_VALUE, 2017-02-01)
- p201702: [2017-02-01, 2017-03-01)
- p201704: [2017-04-01, 2017-05-01)
- 删除p201703: [2017-03-01, 2017-04-01),不会改变已生成的分区,该部分的数据无法导入
默认有3种设置
-
- 1.不做初始化分区,没有任何分区,可以补历史分区或者手动新增分区
- 历史数据需新增分区否则插入数据则会报错
- PARTITION BY RANGE(`date`)()
- 2.和第3种一样,建表后分区也是一样的,底层可能机制相同
- PARTITION BY RANGE(`date`)(PARTITION `p20230101` VALUES LESS THAN ("2023-01-01"))
- 3.指定初始分区,小于2023-01-01数据写入p20230101分区
- PARTITION BY RANGE(`date`)( PARTITION p20220316 VALUES[ ('0000-01-01'),('2022-03-17')))
-
list分区
<code class="language-plaintext hljs">##直接指定,但是可以命中多个
PARTITION BY LIST(`city`)
(
PARTITION `p_cn` VALUES IN ("Beijing", "Shanghai", "Hong Kong"),
PARTITION `p_usa` VALUES IN ("New York", "San Francisco"),
PARTITION `p_jp` VALUES IN ("Tokyo") )</code>-
不设置分区
其实当不使用partition by建表的时候,系统会自动生成一个和表名同名的,全值范围的partition
-
动态分区
-
- createtable student_dynamic_partition1 (
- id int,
- timedate,
- name varchar(50),
- age int
- )
- duplicate key(id,time)
- PARTITIONBYRANGE(time)()
- DISTRIBUTED BY HASH(id) buckets 10
- PROPERTIES(
- "dynamic_partition.enable" = "true",
- "dynamic_partition.time_unit" = "DAY",
- "dynamic_partition.start" = "-7",
- "dynamic_partition.end" = "3",
- "dynamic_partition.prefix" = "p",
- "dynamic_partition.buckets" = "10",
- "replication_num" = "1"
- );

-
常用的分区方式
一般都是动态range分区,或者数据较少时直接不分区
-
- ENGINE = OLAP UNIQUE KEY(`uid`, `logdate`) COMMENT ""
- PARTITION BY RANGE(`logdate`) (PARTITION `p20230101` VALUES LESS THAN ("2023-01-01"))
- DISTRIBUTED BY HASH(`uid`) BUCKETS 1 PROPERTIES (
- "replication_allocation" = "tag.location.default: 3",
- "dynamic_partition.enable" = "true",
- "dynamic_partition.time_unit" = "DAY",
- "dynamic_partition.time_zone" = "Asia/Shanghai",
- -- 超过这个分区数量则删除,类似生命周期?
- "dynamic_partition.start" = "-1460",
- "dynamic_partition.end" = "1",
- --分区前缀
- "dynamic_partition.prefix" = "p",
- "dynamic_partition.replication_allocation" = "tag.location.default: 3",
- --分桶数,对应上面的 BUCKETS
- "dynamic_partition.buckets" = "1",
- --是否自动创建历史分区
- "dynamic_partition.create_history_partition" = "true",
- --历史分区数量,超过设置的最小分区时,数量实际等于最小分区-今日分区的分区数量
- "dynamic_partition.history_partition_num" = "400",
- "dynamic_partition.hot_partition_num" = "0",
- "dynamic_partition.reserved_history_periods" = "NULL",
- "in_memory" = "false",
- "storage_format" = "V2"
- )
2.2.2 分桶
只支持hash分片
分桶列可以是多列,但必须为 Key 列
-
一个或少数分桶列
对应的点查询可以仅触发一个分桶扫描,当多个点查询并发时,这些查询有较大的概率分别触发不同的分桶扫描,各 个查询之间的 IO 影响较小,适合 高并发的点查询场景
-
多个分桶列
数据分布更均匀,但一个查询条件不包含所有分桶列的等值条件,会触发所有分桶同时扫描,查询吞吐会增加,单个查询的延迟随之降低,适合大吞吐低并发的查询场景
2.2.3 分区分桶数设置
数据较少时,比如聚合后的ads层,可以不分区
单个tablet一般在1-10G内,数据量较小,聚合效果不好,元数据管理压力较大
2.3 ENGINE
一般都是用默认的olap,只有这个 ENGINE 类型是由 Doris 负责数据管理和存储的
ENGINE 类型有mysql、broker、 es 等等,本质上只是对外部其他数据库或系统中的表的映射,以保证 Doris 可以读取这些数据。而 Doris 本身并不创建、管理和存储任何非 olap ENGINE 类型的表和数据
2.4 replication_num
副本机制,一般就用默认的 3
对于一些小,并且更新不频繁的维度表,可以考虑设置更多的副本数。这样在 Join 查询 时,可以有更大的概率进行本地数据 Join
3.4.2 storage_medium & storage_cooldown_time
数据存储目录可以显式的指定为 SSD 或者 HDD,一般也都不怎么在意这个参数
3. doris 进阶语法
3.1 Rollup 上卷
在原表的基础上按照指定粒度预聚合,提高查询效率
Rollup 的数据是基于 Base 表产生的,并且是物理独立存储的,所以有存储成本,且rollup设置较多时base表写入效率会降低
还可以用Rollup调整前缀索引(建表时指定的索引顺序无法改变,可以通过Rollup实现)
-
- ALTER TABLE table1 ADD ROLLUP rollup_city(citycode, pv);
- SHOW ALTER TABLE ROLLUP;
3.2 视图
和Rollup一样,都是建立在Base表上,会自动同步Base表的数据更新等操作
物化视图覆盖了Rollup的全部功能,相当于Rollup的超集,弥补了Rollup无法对明细数据模型进行预聚合的短板。物化视图支持丰富的聚合函数。
Doris目前只支持物化视图的单表创建,不支持表join的方式创建。
3.3 bitmap数据类型
bitmap是一种数据结构-位图,使用每个位表示某种状态,大大节省存储空间,同时位图采用位运算计算效率也很高
适用场景:需要去重,数据较大
注意事项:在数据稀疏的情况下,效率会变得非常低,另外使用bitmap每次操作的行数不宜太多
除了使用位图外,使用上和set集合差不多
3.3 join
doris除了常见的Broadcast和Shuffleliangzhong join还有一些其他的join:
-
Broadcast Join (内存 Hash 表)
-
Shuffle Join(Partitioned Join),按照 Join 的 key 进行 Hash,然后进行分布式的 Join
-
Colocation Join :减少数据在节点上的传输耗时,加速查询
-
Bucket Shuffle Join :0.14版本后的新功能。旨在为某些 Join 查询提供本地性优化,来减少数据在节点间的传输耗时,来加速查询
3.3.1 Colocation Join
Colocation Join 功能,在建表时指定colocate_with="group1"(将一组拥有 CGS 的表组成一个 CG) ,保证有相同CG的不同表对应的数据分 片会落在同一个 be 节点上,那么使得两表再进行 join 的时候,可以通过本地数据进行直接 join,减少数据在节点之间的网络传输时间
两个概念:
Colocation Group(CG):一个 CG 中会包含一张及以上的 Table。在同一个 Group 内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布
Colocation Group Schema(CGS):一个 CG 中会包含一张及以上的 Table。在同一个 Group 内的 Table 有着相同的 Colocation Group Schema,并且有着相同的数据分片分布
建表语句:
-
- CREATE TABLE `tbl1` (
- `k1` date NOT NULL COMMENT "",
- `k2` int(11) NOT NULL COMMENT "",
- `v1` int(11) SUM NOT NULL COMMENT ""
- ) ENGINE=OLAP
- AGGREGATE KEY(`k1`, `k2`)
- PARTITION BY RANGE(`k1`)
- (
- PARTITION p1 VALUES LESS THAN ('2019-05-31'),
- PARTITION p2 VALUES LESS THAN ('2019-06-30')
- )
- DISTRIBUTED BY HASH(`k2`) BUCKETS 8
- PROPERTIES (
- "colocate_with" = "group1"
- );
- CREATE TABLE `tbl2` (
- `k1` datetime NOT NULL COMMENT "",
- `k2` int(11) NOT NULL COMMENT "",
- `v1` double SUM NOT NULL COMMENT ""
- ) ENGINE=OLAP
- AGGREGATE KEY(`k1`, `k2`)
- DISTRIBUTED BY HASH(`k2`) BUCKETS 8
- PROPERTIES (
- "colocate_with" = "group1"
- );
使用时需要注意:
-
建表时两张表的分桶列的类型和数量需要完全一致,并且桶数一致,才能保证多张表的数据分片能够一一对应的进行分布控制。
-
同一个 CG 内所有表的所有分区(Partition)的副本数必须一致。如果不一致,可能出现某一个 Tablet 的某一个副本,在同一个 BE 上没有其他的表分片的副本对应。
-
同一个 CG 内的表,分区的个数、范围以及分区列的类型不要求一致
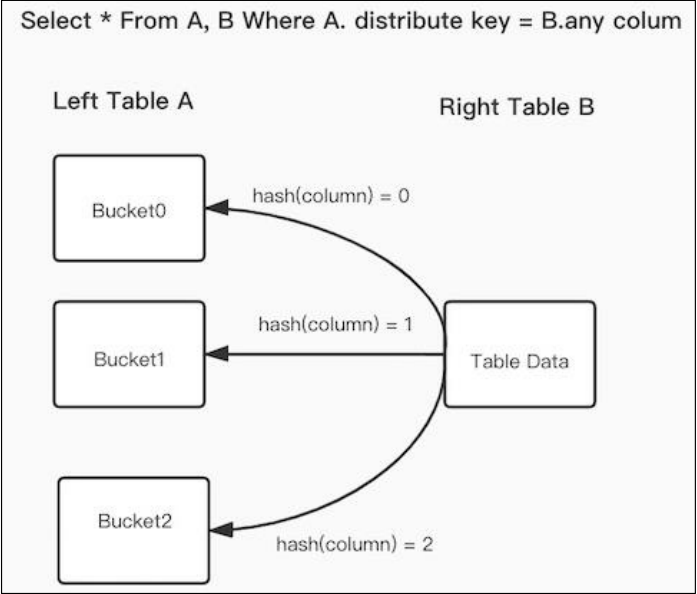
3.3.2 Bucket Shuffle Join
官网描述:Bucket Shuffle Join - Apache Doris
首先当表A join 表B,此时shuffle join 和 broadcast join 开销计算公式如下:
-
broadcast join :如果表A数据分布有3个执行的HashJoinNode,网络开销为 B * N(A的HashJoinNode)=3B,内存开销也是3B
-
shuffle join:Shuffle Join 会将 A,B 两张表的数据根据哈希计算分散到集群的节点之中,所以它的网络开销为 A + B,内存开销为 B。
原理:
doris 觉得这两种方式都可以优化,我能不能A表不动,把B表按照左表A的分布,先进行shuffle,再进行join。这样就可以减少跨节点的数据传输。这时网络和内存开销都是B
3.3.3 runtime-filter
官网描述:Runtime Filter - Apache Doris
功能:
0.15 版本才有的功能,主要用于大表join小表的优化
原理:
在运行时动态生成的过滤条件,即在查询运行时解析join on clause确定过滤表达式,并将表达式广播给正在读取左表的ScanNode,从而减少扫描的数据量,进而减少probe hash table的次数,避免不必要的I/O和网络传输
如果大表T1 join 维度表 T2,显而易见对T2扫描数据要远远快于T1,如果我们主动等待一段时间再扫描T1,等T2将扫描的数据记录交给HashJoinNode后,HashJoinNode根据T2的数据计算出一个过滤条件,比如T2数据的最大和最小值,或者构建一个Bloom Filter,接着将这个过滤条件发给等待扫描T1的ScanNode,后者应用这个过滤条件,将过滤后的数据交给HashJoinNode,从而减少probe hash table的次数和网络开销,这个过滤条件就是Runtime Filter
3.3.4 join优化
官网描述:Doris Join 优化原理 - Apache Doris
有几个用过,官网写的很详细,我一般doris更多用于展示层,较少遇到性能问题
4. 注意事项
除了我遇到的记录的问题,doris官网也总结了很多常见问题:SQL 问题 - Apache Doris
4.1 动态分区
动态分区使用过程中,如果因为一些意外情况导致 dynamic_partition.start 和dynamic_partition.end 之间的某些分区丢失,那么当前时间与 dynamic_partition.end 之间的丢失分区会被重新创建,dynamic_partition.start 与当前时间之间的丢失分区不会重新创建。
4.2 delete 语句
-
delete语句只能针对 Partition 级别进行删除。如果一个表有多个 partition 含有需要删除的数据,则需要执行多次针对不同 Partition 的 delete 语句
-
如果是没有使用Partition 的表,partition 的名称即表名
-
delete数据的真正删除是在 BE 进行数据 Compaction 时进行的。所以执行完 delete 命令后,并不会立即释放磁盘空间
-
如果 delete 只在多数副本上完成了,也会返回用户成功。但是会在后台生成一个异步的 delete job(Async Delete Job),来继续完成对剩余副本的删除操作
4.3 聚合模型
4.3.1 doris聚合3个阶段
-
每一批次数据导入的 ETL 阶段。该阶段会在每一批次导入的数据内部进行聚合
-
底层 BE 进行数据 Compaction 的阶段。该阶段,BE 会对已导入的不同批次的数据进行进一步的聚合
-
数据查询阶段。在数据查询时,对于查询涉及到的数据,会进行对应的聚合。doris自动聚合所有数据,我们只需关注最终结果即可
4.3.2 聚合模型的一些注意点
-
Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样
-
Uniq 模型无法使用 ROLLUP
-
聚合模型使用min,max等函数时需特别注意,如果函数与建表模型函数不一致数据易出错
-
聚合模型慎用count(),doris必须扫描所有的aggr key,聚合后才能做count,可以用一个值恒为 1 的&聚合类型为 SUM 的列来模拟 count(*)
4.3.3 replace/uniqe 模型批次内数据无序
在同一批导入数据中,出现了 key 相同但 value 不同的数据,而由于doris默认是无序的replace操作,这会导致,不同副本间,因数据覆盖的先后顺序不确定而产生的结果不一致的问题。
可能会导致数据不是最后一条,或者出现多次查询结果不一致的现象
doris提供了Sequence Column功能,可以保证有序
5.doris在数据湖的应用
我们使用的是其他数据湖,目前国内字节doris应用数据湖,doris的特性和支持的外部存储,以及提供其他计算引擎计算的功能,还支持mysql的binlog,确实也是一个不错的选择,但是成本很高
后续如果有需要再补充


