
- 1ESP32S3在VScode中使用USB口调试
- 2android 12+从后台启动FGS限制_service.startforeground() not allowed due to bg re
- 3JAVA工程师面试常见问题集锦【转载,实用干货,致谢原作者】
- 4Android 进程间通信,Ashmem共享内存基本使用_android ashmem通信实现
- 5AI吸烟监测识别摄像机
- 6Spring框架从入门到学精(全)_ssm项目
- 7rbac框架java_基于Spring-Security安全框架的RBAC权限管理顶
- 8STM32F1XX实现sin函数PWM输出代码_stm32 sin函数
- 9Vue 报错error:0308010C:digital envelope routines::unsupported_vue error: error:0308010c:digital envelope routine
- 10Weblogic处理流量中的java反序列化数据的流程(CVE-2015-4852、CVE-2016-0638、CVE-2016-3510)_weblogic反序列化流量特征
FPGA纯verilog实现UDP通信,三速网自协商仲裁,动态ARP和Ping功能,提供工程源码和技术支持_xilinx udp实现原理
赞
踩
1、前言
目前网上的fpga实现udp基本生态如下:
1:verilog编写的udp收发器,但不带ping功能,这样的代码功能正常也能用,但不带ping功能基本就是废物,在实际项目中不会用这样的代码,试想,多机互联,出现了问题,你的网卡都不带ping功能,连基本的问题排查机制都不具备,这样的代码谁敢用?
2:带ping功能的udp收发器,代码优秀也好用,但基本不开源,不会提供源码给你,这样的代码也有不足,那就是出了问题不知道怎么排查,毕竟你没有源码,无可奈何;
3:使用了Xilinx的三速网IP实现,这样的代码也很优秀,但还是那个问题,没有源码,且三速网IP需要licence,官方提供的licence有效期只有120天,其实三速网IP仅仅实现了rgmii到gmii再到axis的转换,完全可以不用这个ip;
本设计使用Micrel公司的KSZ9031RNX作为网络PHY芯片,使用verilog代码设计UDP协议,并带有用户接口,使得用户无需关心复杂的UDP协议而只需关心简单的用户接口时序即可操作UDP收发,非常简单,通过一个fifo实现UDP数据的回环收发,并在电脑端使用网络调试助手进行UDP收发验证,在文章末尾有演示效果展示。
免责声明
本工程及其源码即有自己写的一部分,也有网络公开渠道获取的一部分(包括CSDN、Xilinx官网、Altera官网等等),若大佬们觉得有所冒犯,请私信批评教育;基于此,本工程及其源码仅限于读者或粉丝个人学习和研究,禁止用于商业用途,若由于读者或粉丝自身原因用于商业用途所导致的法律问题,与本博客及博主无关,请谨慎使用。。。
2、我这里已有的UDP方案
目前我这里有如下几种UDP方案和应用实例:
1、FPGA实现精简版UDP通信,数据回环例程,提供了Kintex7和Artix7的2套工程,实现了UDP数据回环测试,精简版UDP有ARP,没有ping功能,但资源占用很少,感兴趣的可以参考我之前的文章:点击查看
2、FPGA实现极简版UDP板间视频传输,根据精简版UDP修改而来,去掉了其中的ARP部分,使用网线在两块FPGA开发板之间传输OV5640摄像头视频,感兴趣的可以参考我之前的文章:点击查看
3、使用Xilinx官方的三速网IP实现UDP通信,缺点是需要调用XIlinx的三速网IP,且需要去官网申请licence,优点是数据传输快、传输数据量大,感兴趣的可以参考我之前的文章:点击查看
3、使用Xilinx官方的三速网IP实现UDP视频传输,网线传输采集的OV5640摄像头视频,在电脑端使用QT上位机接收图像并显示,感兴趣的可以参考我之前的文章:点击查看
4、使用Xilinx官方的三速网IP实现UDP视频传输,网线传输采集的SDI视频,在电脑端使用QT上位机接收图像并显示,感兴趣的可以参考我之前的文章:点击查看
5、纯verilog代码实现UDP通信,带ARP和ping功能,提供了Xilinx Kintex7系列FPGA的数据回环例程,感兴趣的可以参考我之前的文章:点击查看
6、纯verilog代码实现UDP通信,带ARP和ping功能,提供了Xilinx Artix7系列FPGA的2套数据回环例程,感兴趣的可以参考我之前的文章:点击查看
3、UDP详细设计方案
本实验以千兆以太网 RGMII 通信为例来设计 verilog 程序,会先发送预设的 UDP 数据到网络,每秒钟发送一次,如果 FPGA 检测网口发来的 UDP 的数据包,会把接收到的数据包存储在 FPGA内部的 RAM 中,再不断的把 RAM 中的数据包通过网口发回到 ethernet 网络。程序分为两部分,分别为发送和接收,实现了 动态ARP,UDP,Ping 和10/100/1000M网速自动协商仲裁功能。以下为原理实现框图:
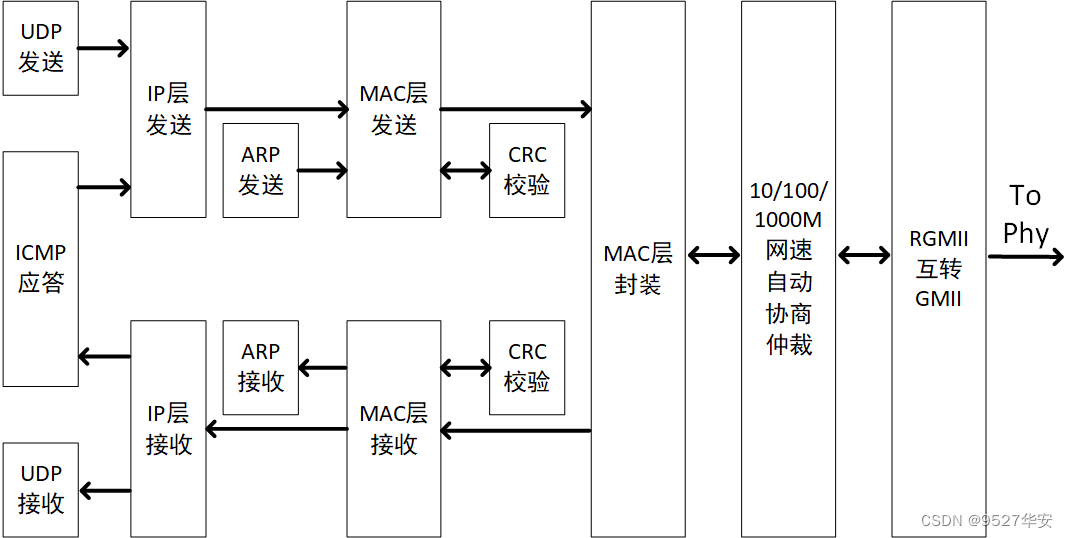
MAC层发送
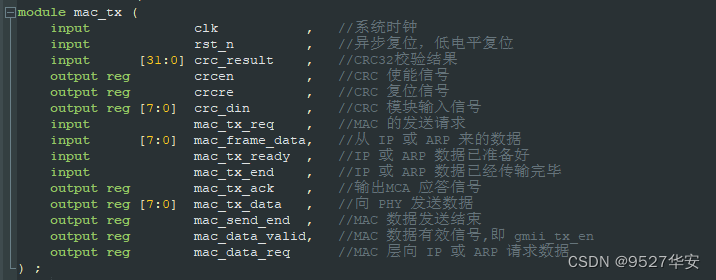
发送部分中, mac_tx.v 为 MAC 层发送模块,首先在 SEND_START 状态,等待 mac_tx_ready
信号,如果有效,表明 IP 或 ARP 的数据已经准备好,可以开始发送。再进入发送前导码状态,结
束时发送 mac_data_req,请求 IP 或 ARP 的数据,之后进入发送数据状态,最后进入发送 CRC 状
态。在发送数据过程中,需要同时进行 CRC 校验。
MAC层发送顶层接口如下:
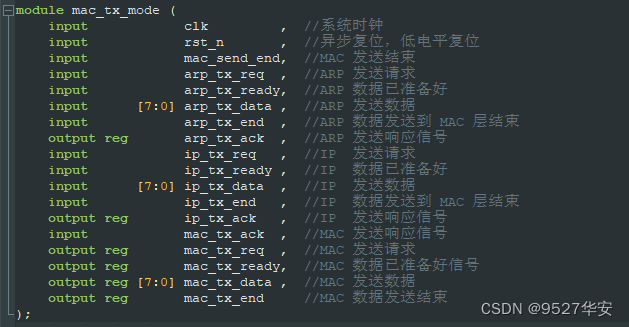
MAC发送模式
工程中的 mac_tx_mode.v 为发送模式选择,根据发送模式是 IP 或 ARP 选择相应的信号与数据。
MAC发送模式顶层接口如下:
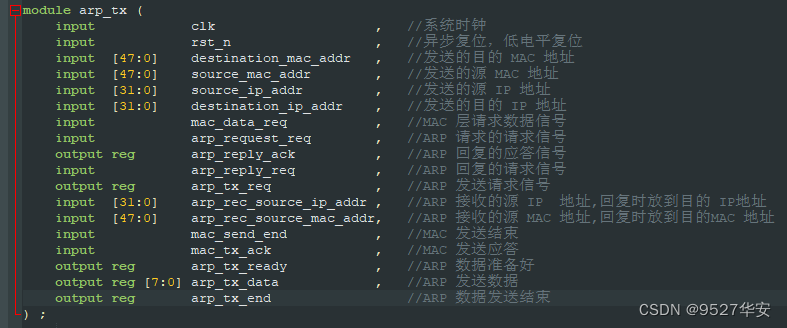
ARP发送
发送部分中,arp_tx.v 为 ARP 发送模块, 在 IDLE 状态下,等待 ARP 发送请求或 ARP 应答请求
信号,之后进入请求或应答等待状态,并通知 MAC 层,数据已经准备好,等待 mac_data_req 信
号,之后进入请求或应答数据发送状态。由于数据不足 46 字节,需要补全 46 字节发送。
ARP发送顶层接口如下:
IP层发送
在发送部分,ip_tx.v 为 IP 层发送模块,在 IDLE 状态下,如果 ip_tx_req 有效,也就是 UDP 或
ICMP 发送请求信号,进入等待发送数据长度状态,之后进入产生校验和状态,校验和是将 IP 首部所有数据以 16 位相加,最后将进位再与低 16 位相加,直到进入为 0,再将低 16 位取反,得出校验和结果。此程序中校验和以树型加法结构,并插入流水线,能有效降低加法部分的延迟,但缺点是会消耗较多逻辑资源。如下图 ABCD 四个输入,A 与 B 相加,结果为 E,C 与 D 相加,结果为 F,再将 E 与 F 相加,结果为 G,在每个相加结果之后都有寄存器。
设计框图如下:
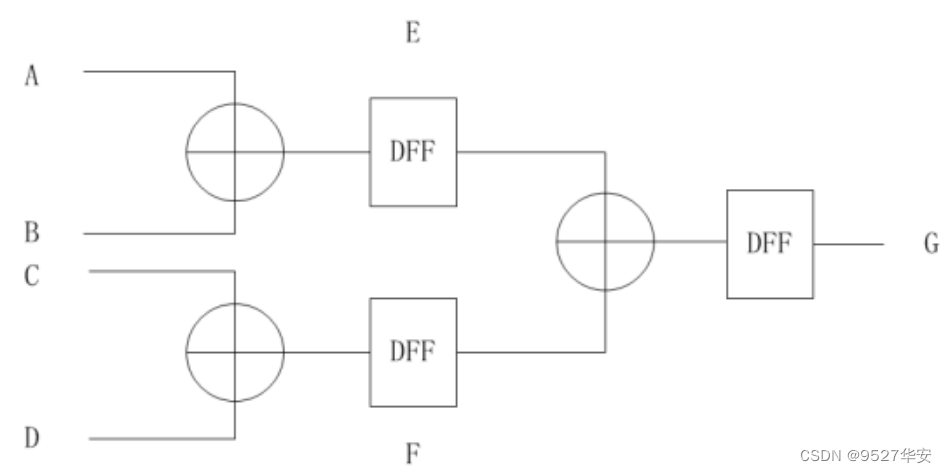
在生成校验和之后,等待 MAC 层数据请求,开始发送数据,并在即将结束发送 IP 首部后请求 UDP 或 ICMP 数据。等发送完,进入 IDLE 状态。
IP层发送顶层接口如下:
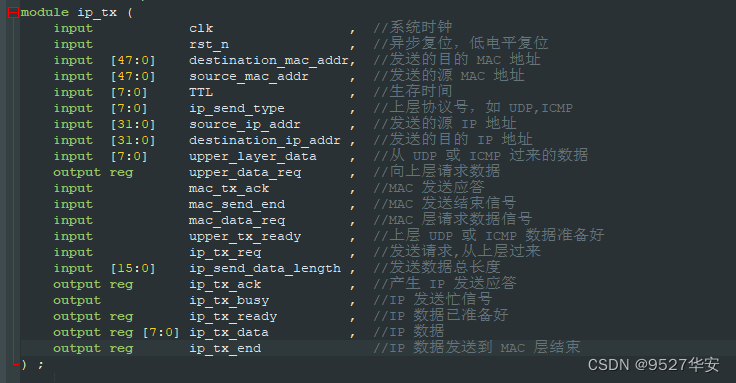
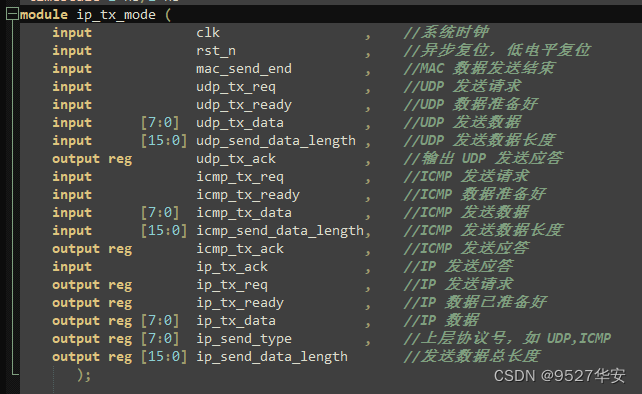
IP发送模式
工程中的 ip_tx_mode.v 为发送模式选择,根据发送模式是 UDP 或 ICMP 选择相应的信号与数据。
IP发送模式顶层接口如下:
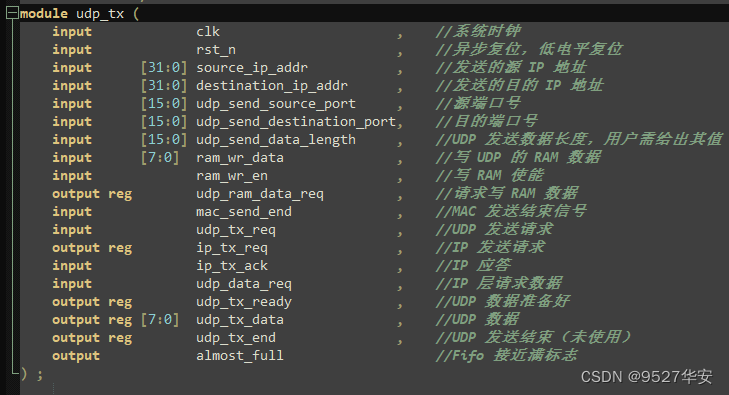
UDP发送
发送部分中,udp_tx.v 为 UDP 发送模块,第一步将数据写入 UDP 发送 RAM,同时计算校验和,第二步将 RAM 中数据发送出去。UDP 校验和与 IP 校验和计算方法一致。在计算时需要将伪首部加上,伪首部包括目的 IP 地址,源 IP 地址,网络类型,UDP 数据长度。
UDP发送顶层接口如下:
MAC层接收
在接收部分,其中 mac_rx.v 为 mac 层接收文件,首先在 IDLE 状态下需要判断 rx_dv 信号是否为高,在 REC_PREAMBLE 前导码状态下,接收前导码。之后进入接收 MAC 头部状态,即目的MAC 地址,源 MAC 地址,类型,将它们缓存起来,并在此状态判断前导码是否正确,错误则进入 REC_ERROR 错误状态,在 REC_IDENTIFY 状态判断类型是 IP(8’h0800)或 ARP(8’h0806)。然后进入接收数据状态,将数据传送到 IP 或 ARP 模块,等待 IP 或 ARP 数据接收完毕,再接收 CRC 数据。并在接收数据的过程中对接收的数据进行 CRC 处理,将结果与接收到的 CRC 数据进行对比,判断数据是否接收正确,正确则结束,错误则进入 ERROR 状态。
MAC层接收顶层接口如下:
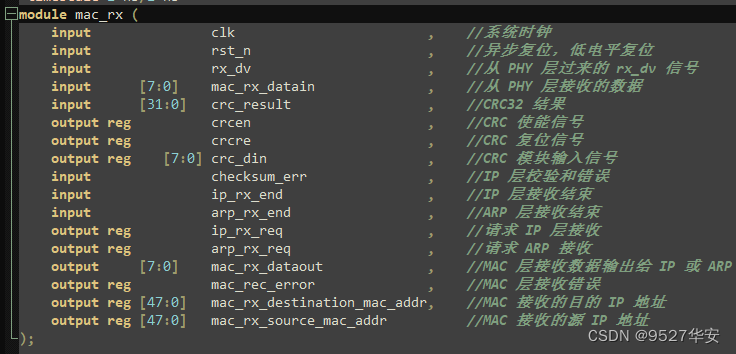
ARP接收
工程中的 arp_rx.v 为 ARP 接收模块,实现 ARP 数据接收,在 IDLE 状态下,接收到从 MAC 层发来的 arp_rx_req 信号,进入 ARP 接收状态,在此状态下,提取出目的 MAC 地址,源 MAC 地址,
目的 IP 地址,源 IP 地址,并判断操作码 OP 是请求还是应答。如果是请求,则判断接收到的目的
IP 地址是否为本机地址,如果是,发送应答请求信号 arp_reply_req,如果不是,则忽略。如果 OP
是应答,则判断接收到的目的 IP 地址及目的 MAC 地址是否与本机一致,如果是,则拉高arp_found 信号,表明接收到了对方的地址。并将对方的 MAC 地址及 IP 地址存入 ARP 缓存中。
ARP接收顶层接口如下:
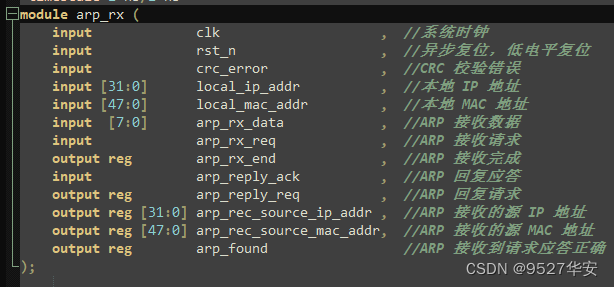
IP层接收
在工程中,ip_rx 为 IP 层接收模块,实现 IP 层的数据接收,信息提取,并进行校验和检查。
首先在 IDLE 状态下,判断从 MAC 层发过来的 ip_rx_req 信号,进入接收 IP 首部状态,先在
REC_HEADER0 提取出首部长度及 IP 总长度,进入 REC_HEADER1 状态,在此状态提取出目的 IP 地址,源 IP 地址,协议类型,根据协议类型发送 udp_rx_req 或 icmp_rx_req。在接收首部的同时进行校验和的检查,将首部接收的所有数据相加,存入 32 位寄存器,再将高 16 位与低 16 位相加,直到高 16 位为 0 ,再将低 16 位取反,判断其是否为 0,如果是 0,则检验正确,否则错误,进入IDLE 状态,丢弃此帧数据,等待下次接收。
IP层接收顶层接口如下:
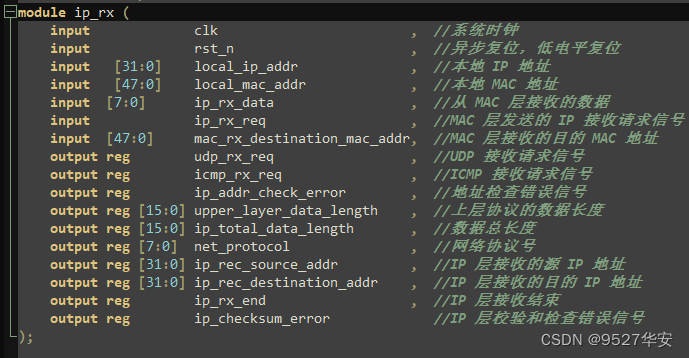
UDP接收
在工程中,udp_rx.v 为 UDP 接收模块,在此模块首先接收 UDP 首部,再接收数据部分,并将数据部分存入 RAM 中,在接收的同时进行 UDP 校验和检查,如果 UDP 数据是奇数个字节,在计算校验和时,在最后一个字节后加上 8’h00,并进行校验和计算。校验方法与 IP 校验和一样,如果校验正确,将拉高 udp_rec_data_valid 信号,表明接收的 UDP 数据有效,否则无效,等待下次接收。
UDP接收顶层接口如下:
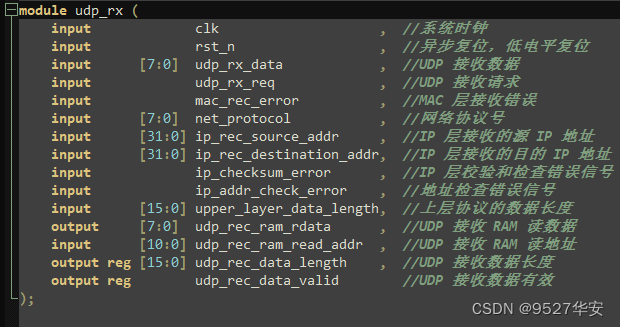
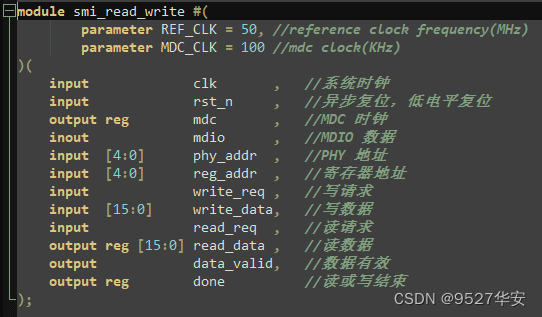
SMI读写控制
smi_read_write.v 文件用于 SMI 接口的读写控制,在 IDLE 状态下根据写请求或读请求到相应的状态,再根据 SMI 时序实现 MDC 和 MDIO 的控制,一般情况下网络PHY不需要配置,在原理图设计时进行匹配电阻上下拉即可实现phy正常工作,一般会让其工作在延时模式,但本设计为了实现10/100/1000M网速的自适应和仲裁,需要读取phy当前和连接网卡的速度,所以设计了MDIO的模块,另外,读者也可以借机学习一下MDIO的知识。
SMI读写控制顶层接口如下:
SMI配置
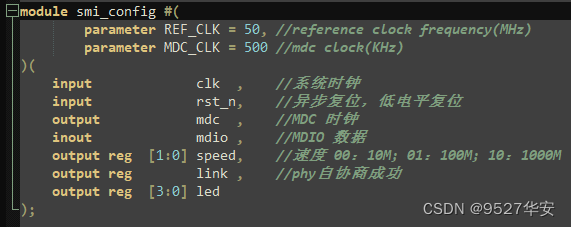
smi_config.v 文件读取寄存器 0x11 的 bit10 和 bit[15:14]来判断以太网是否已经连接和当前的以太网速度,默认状态下,PHY 芯片是自动协商速度,根据对方的速度做匹配。bit 10 为 1 则 link成功,否则失败,bit[15:14]为 00 则是 10M,01 为 100M,10 或 11 为 1000M,根据不同的速度点亮 LED 灯,没有 link 都不亮,10M 亮一个灯,100M 亮两个灯,1000M 亮三个灯。
SMI配置顶层接口如下:
10/100/1000M仲裁
由于 10/100M 传输数据时是单边沿采集数据,因此一个周期传输 4bit 数据,而 RGMII 为双边沿采集数据,所以要进行数据的转换,如发送时,要将一周其 8bit 数据转成一周期 4bit 数据,因此要设置数据缓存,读数据速率为写数据的一半。
参考了其他友商的自协商方案,居然还有设置三种时钟的方案,本人直言太LOW。。。
设置一个TX buffer:
gmii_tx_buffer.v 将要发送的 8bit 缓存到 eth_data_fifo 中,同时将数据长度缓存到 len_fifo 中,在状态机中判断长度 FIFO 中的数据是否大于 0,是则表明已经缓存了数据,之后进入读 FIFO 数据状态,每两个周期读一次数据,此功能不好理解,最好用 signaltap 抓取信号帮助理解。
设置一个RX buffer:
gmii_rx_buffer.v 将接收的 10/100M 数据缓存到 eth_data_fifo 中,同时将数据长度缓存到len_fifo 中,在状态机中判断长度 FIFO 中的数据是否大于 0,是则表明已经缓存了数据,之后进入读 FIFO 数据状态,每两个周期读一次数据,最好用 signaltap 抓取信号帮助理解。
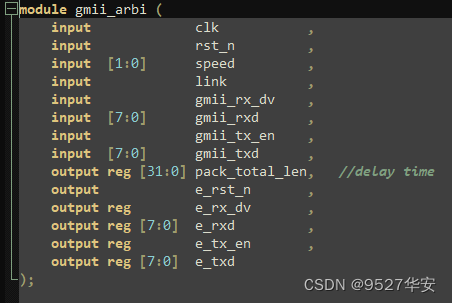
仲裁:gmii_arbi.v 用于三种速度的仲裁,同时设定了发送的间隔都为 1S。
10/100/1000M仲裁顶层接口如下:
ICMP应答 (ping)
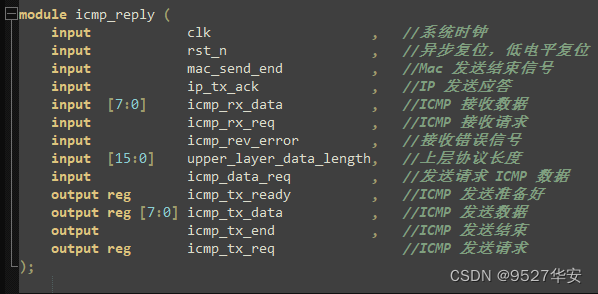
在工程中,icmp_reply.v 实现 ping 功能,首先接收其他设备发过来的 icmp 数据,判断类型是否是回送请求(ECHO REQUEST),如果是,将数据存入 RAM,并计算校验和,判断校验和是否正确,如果正确则进入发送状态,将数据发送出去。
ICMP应答 (ping)顶层接口如下:
ARP缓存
在工程中,arp_cache.v 为 arp 缓存模块,将接收到的其他设备 IP 地址和 MAC 地址缓存,在发送数据之前,查询目的地址是否存在,如果不存在,则向目的地址发送 ARP 请求,等待应答。在设计文件中,只做了一个缓存空间,如果有需要,可扩展。
ARP缓存顶层接口如下:
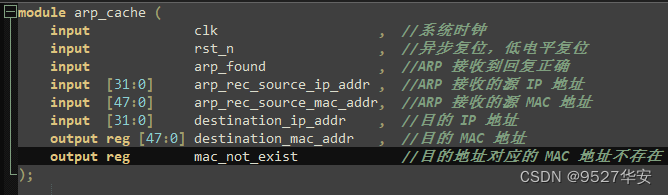
CRC校验
一个 IP 数据包的 CRC32 校验是在目标 MAC 地址开始计算的,一直计算到一个包的最后一个数据为止。以太网的 CRC32 的 verilog 的算法和多项式可以在以下网站中直接生成:
http://www.easics.com/webtools/crctool
以太网测试模块
mac_test.v。测试模块实现数据流的控制,首先在按下按键后发送 ARP 请求信号,直到对方回应,进入发送 UDP 数据状态,如果在 WAIT 状态时发现 UDP 接收数据有效,则将接收的数据发送出去。循环1 秒发送,在每次发送前需要检查目的 IP 地址是否能在 ARP 缓存里找到,如果没有,则发送 ARP请求。
以太网测试模块顶层接口如下:
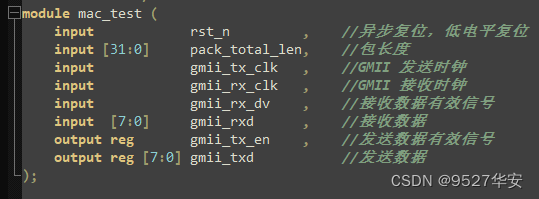
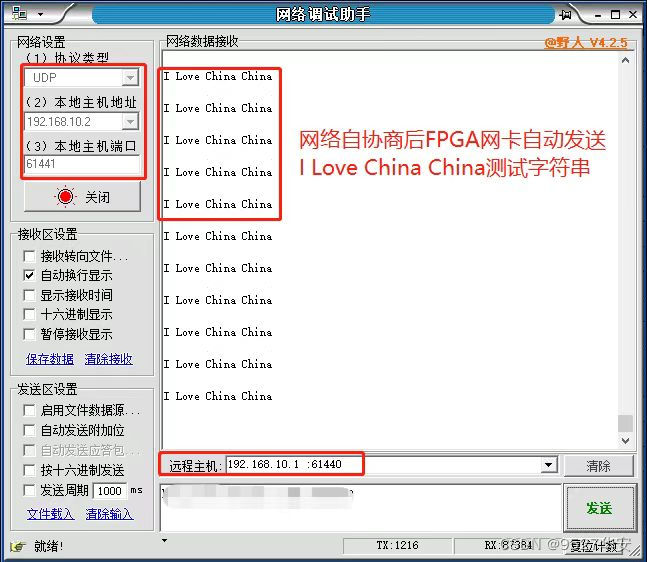
此模块设置了网卡连接成功后自动向外发送的测试字符串,代码位置如下,可自由修改字符串内容,比如改为爱你女朋与的名字。。。

RGMII转GMII模块
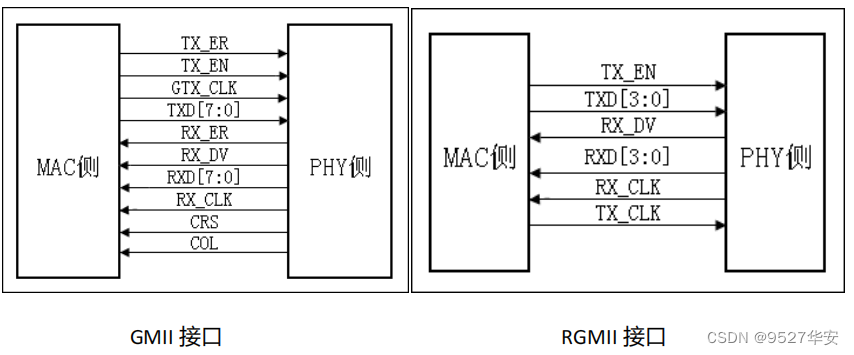
util_gmii_to_rgmii.v 文件是将 RGMII 与 GMII 转换,提取出控制信号与数据信号。与 PHY 连接是 RGMII 接口。
RGMII 接口是 GMII 接口的简化版,在时钟的上升沿及下降沿都采样数据,上升沿发送
TXD[3:0]/RXD[3:0],下降沿发送 TXD[7:4]/RXD[7:4],TX_EN 传送 TX_EN(上升沿)和 TX_ER(下降沿)两种信息,RX_DV 传送 RX_DV(上升沿)和 RX_ER(下降沿)两种信息。
RGMII转GMII模块设计框图如下:
4、vivado工程详解
工程介绍:
开发板:Xilinx Artix7开发板;
开发环境:vivado2019.1;
网络PHY:KSZ9031;
输入输出:UDP环出;
工程代码架构如下:

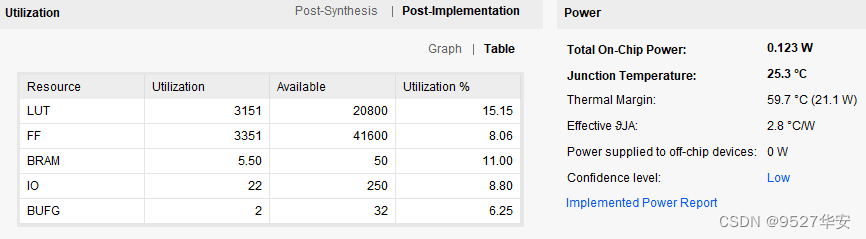
FPGA资源消耗和功耗预估如下:
5、上板调试验证并演示
板子上电下载bit后,先测试ping功能,如下:
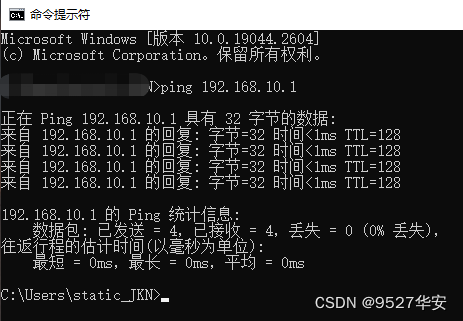
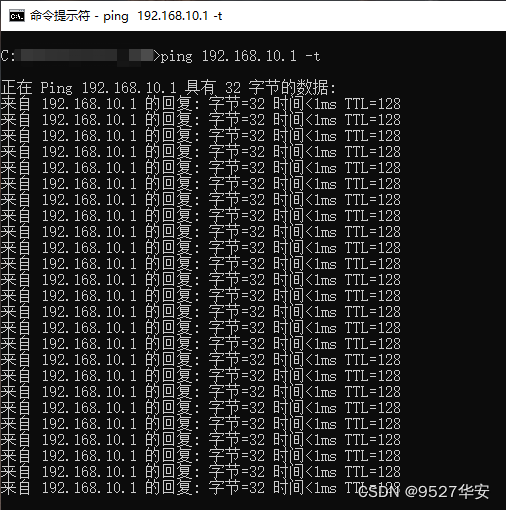
单次ping还不够,直接上连续ping,如下:
然后是用网络调试助手进行数据收发测试,网卡连接成功后网络调试助手会收到FPGA发来的测试字符串,1s发一次,如下:
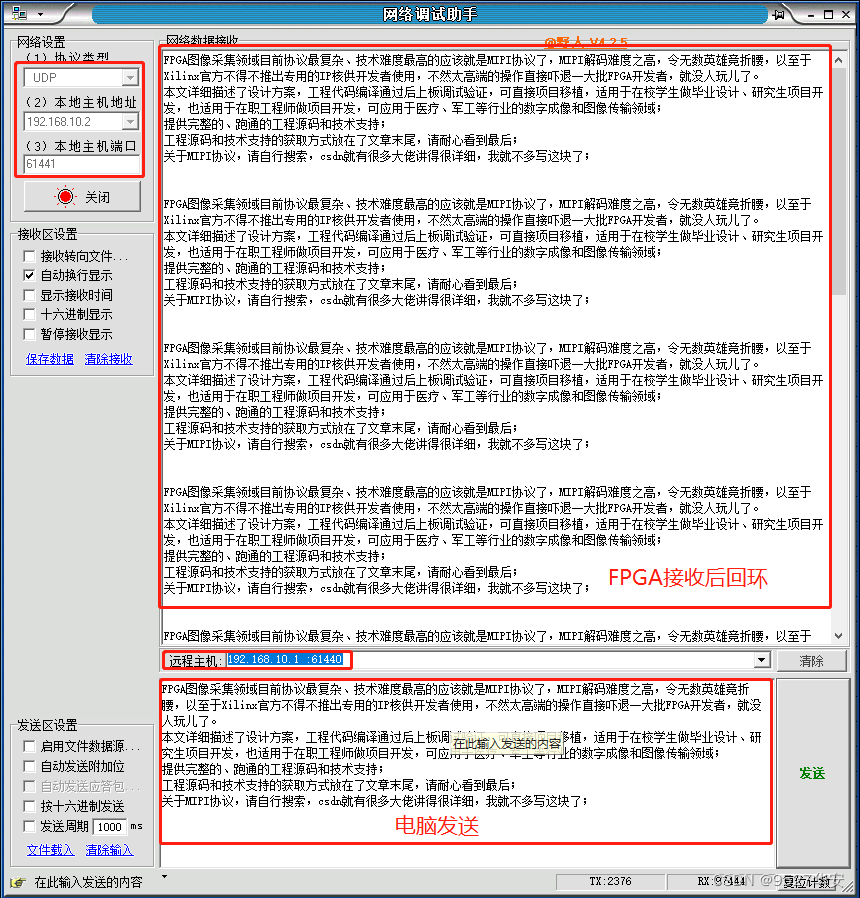
然后发送大批量数据进行测试,测试结果如下:
三速网自协商仲裁测试:
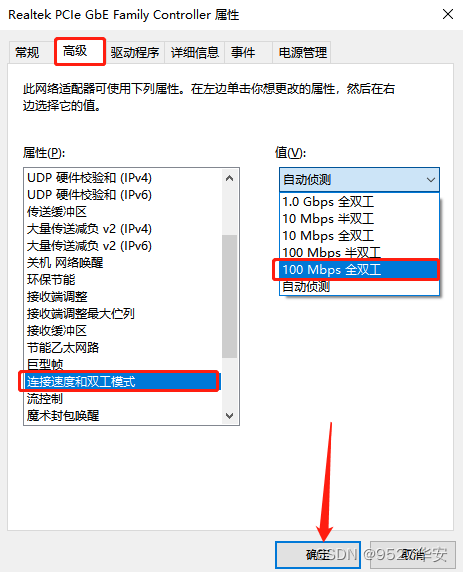
将电脑网卡速度改为100M,如下步骤:
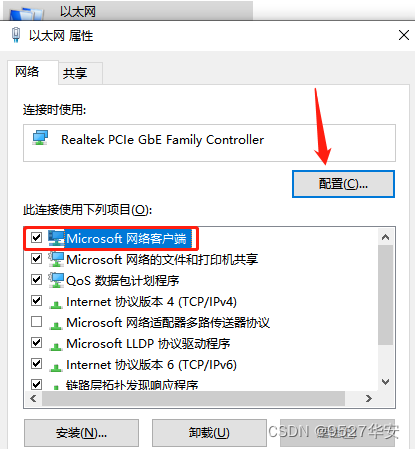
鼠标右击以太网点击属性,然后点图中的配置;
然后关闭网络调试助手后重新打开,再发字符串测试,如下:
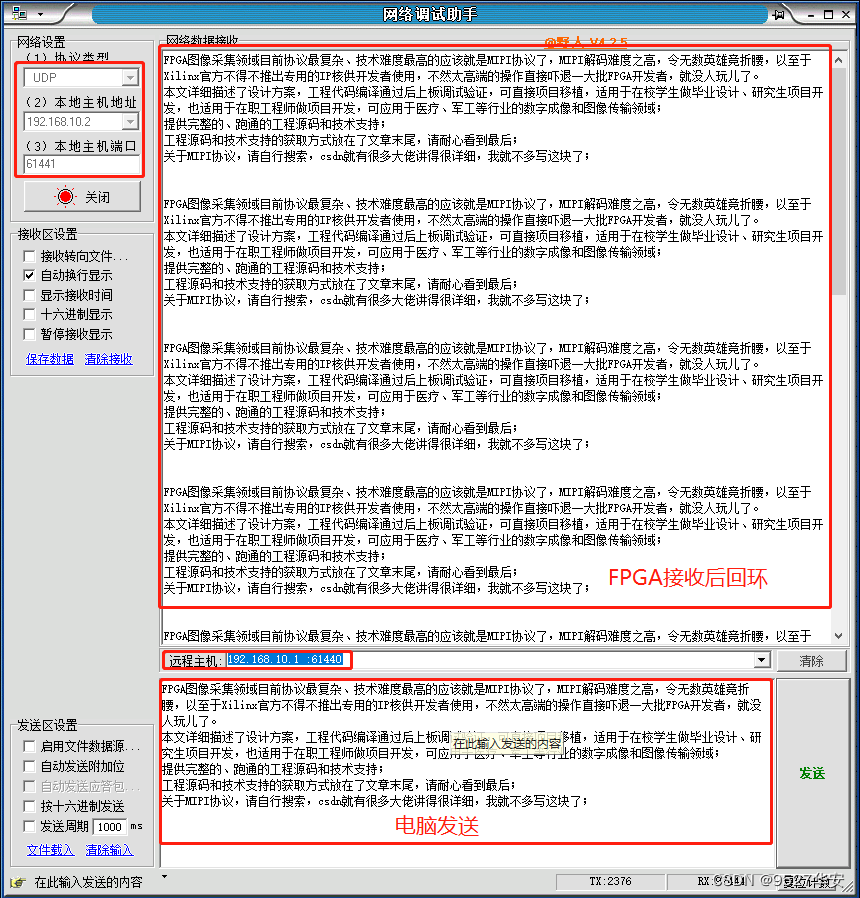
可以看到改为100M后FPGA依然能与电脑网卡通信,说明FPGA设计的网卡具有三速网自协商功能,还可以把电脑网卡改为10M测试,不过10M基本在项目中无用,所以并未测试,才跑10M,我用UDP干啥,哈哈。。。
6、福利:工程代码的获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料获取方式:私,或者文章末尾的V名片。
网盘资料如下:


