
- 1Redis开源协议变更!Garnet:微软开源代替方案?_garnet:.exe 下载
- 2两个ESP8266相互通信_两个esp8266通信
- 3Hist2ST:联合Transformer和图神经网络从组织学图像中进行空间转录组学预测
- 4Oracle 中关键字 ‘exists‘ 与 ‘in’ 详解_oracle exists和in
- 5Redis 可视化客户端工具、fastgithub 加速器_redis客户端工具
- 6构建Python中的分布式日志系统:ELK与Fluentd的结合
- 7IOS 32位调试环境搭建
- 8X86_64 GNU汇编、寄存器、内嵌汇编_clang x86 寄存器
- 9Python 自动识别图片文字—保姆级OCR实战教程_cnocr
- 10历时三个月,外包两年的我成功上岸了,分享一下我的美的集团面经。_美的外包转内部
xgboost算法_回归建模的时代已结束,算法XGBoost统治机器学习世界
赞
踩

作者 | 冯鸥
发布 | ATYUN订阅号

Vishal Morde讲了这样一个故事:十五年前我刚完成研究生课程,并以分析师的身份加入了一家全球投资银行。在我工作的第一天,我试着回忆我学过的一切。与此同时,在内心深处,我想知道我是否能够胜任这份工作。我的老板感觉到我的焦虑,他说:
“别担心!你唯一需要知道的就是回归建模!”
在我了解了回归建、线性和逻辑回归后,我发现我的老板是对的。在我任职期间,我专门建立了基于回归的统计模型。事实上,在那个时候,回归建模是无可争议的预测分析女王。十五年后的今天,回归建模的时代已经结束,而新女王名字很长:XGBoost或Extreme Gradient Boosting!
什么是XGBoost
XGBoost 是一种基于决策树的集成机器学习算法,梯度增强为框架。在涉及非结构化数据(图像,文本等)的预测问题中,人工神经网络往往优于所有其他算法或框架。然而,当涉及到中小型结构化或表格数据时,基于决策树的算法被认为是同类中最佳的。参阅下面的图表了解多年来基于树的算法的发展:
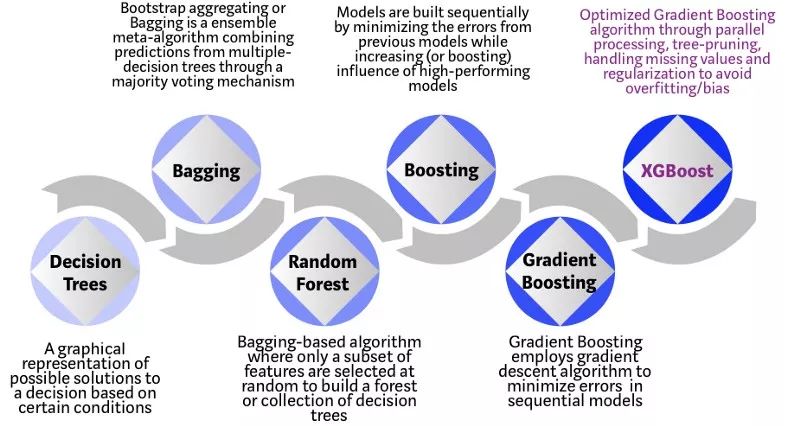
决策树的XGBoost算法演化
XGBoost算法是华盛顿大学的一个研究项目。Tianqi Chen and Carlos Guestrin在2016年的SIGKDD会议上发表了他们的论文,引起了机器学习领域的轰动。自推出以来,该算法不仅赢得了众多Kaggle比赛的胜利,而且还成为几个尖端行业应用的引擎驱动力。因此,有一个强大的数据科学家社区为XGBoost开源项目做出贡献,在GitHub上有大约350个贡献者,3600多条提交。该算法具有以下特性:
广泛的应用:可用于解决回归,分类,排名和用户定义的预测问题。
可移植性:可在Windows,Linux和OS X上顺畅运行。
语言:支持所有主要的编程语言,包括C ++,Python,R,Java,Scala和Julia。
云集成:支持AWS,Azure和Yarn集群,适用于Flink,Spark和其他生态系统。
建立直觉
决策树最简单的形式,是易于可视化和可解释的算法,但为下一代基于树的算法建立直觉可能有点棘手。请参阅下面的简单类比,以更好地了解基于树的算法的演变。
想象一下,你是一名招聘经理,面试几位具有优秀资历的候选人。基于树的算法演变的每一步都可以看作是一个采访。
决策树:每个招聘经理都有一套标准,如教育水平,经验年数,面试表现。决策树类似于招聘经理根据自己的标准面试候选人。
Bagging:现在想象一下,而不是一个面试官,现在有一个面试小组,每个面试官都会投票。Bagging涉及通过民主投票过程,将所有调查员的投票结合起来以做出最终决定。
随机森林:它是一种基于Bagging的算法,具有关键差异,其中仅随机选择特征的子集。换句话说,每个面试官只会根据某些随机选择的资格测试受访者(例如,测试编程技能的技术面试和评估非技术技能的行为面试)。
提升(Boosting):这是一种替代方法,每位面试官根据前一位访调员的反馈改变评估标准。通过部署更加动态的评估流程,提升面试流程的效率。
梯度提升:这是通过梯度下降算法提高误差最小化的特殊情况,例如策略咨询公司利用案例访谈来剔除不太合格的候选人。
XGBoost:将XGBoost视为加强版的梯度增强(因此有人称之为极端梯度提升),它是软件和硬件优化技术的完美结合,可在最短的时间内使用较少的计算资源产生出色的结果。
表现甚佳
XGBoost 和 Gradient Boosting Machines(GBMs)都是集合树方法,它们应用了使用梯度下降架构来提升弱学习者(通常是CART)的原理。但是,XGBoost通过系统优化和算法增强改进了基础GBM框架。
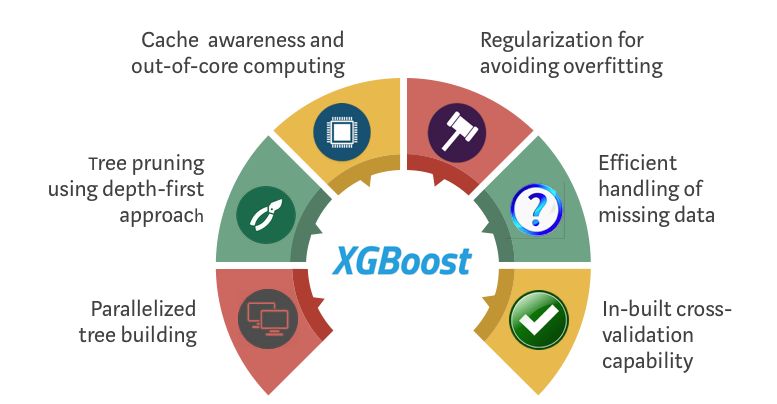
XGBoost优化标准GBM算法
系统优化:
并行化:XGBoost使用并行化实现来处理顺序树构建过程。由于用于构建基础学习者的循环的可互换性,枚举树的叶节点的外部循环,以及计算特征的第二个内部循环,这是可能的。这种循环嵌套限制了并行化,因为没有完成内部循环(对两者的计算要求更高),外部循环无法启动。因此,为了改善运行时间,使用初始化通过所有实例的全局扫描和使用并行线程排序来交换循环的顺序。这样就抵消计算中的任何并行化开销,提高了算法性能。
结构树修剪:GBM框架内树分裂的停止标准本质上是贪婪的,这取决于分裂点的负损失标准。XGBoost首先使用max_depth参数,然后开始向后修剪树。这种深度优先方法显著提高了计算性能。
硬件优化:该算法旨在有效利用硬件资源。这是通过缓存感知实现,即在每个线程中分配内部缓冲区来存储梯度统计信息。诸如“核外”计算等进一步增强功能可优化可用磁盘空间,同时处理不适合内存的大数据帧。
算法增强功能:
正则化:它通过LASSO(L1)和Ridge(L2)正则化来惩罚更复杂的模型,以防止过度拟合。
稀疏性感知:XGBoost通过根据训练损失自动“学习”最佳缺失值,并更有效地处理数据中不同类型的稀疏模式,从而自然地承认输入的稀疏特征。
加权分位数草图:XGBoost采用分布式加权分位数草图算法有效地找到加权数据集中的最优分裂点。
交叉验证:该算法在每次迭代时都带有内置的交叉验证方法,无需显式编程此搜索,以及指定单次运行所需的增强迭代的确切数量。
证据在哪
我们使用 Scikit-learn 的 Make_Classification 数据包创建了一个包含20个特征(2个信息的和2个冗余的)的100万个数据点的随机样本。我们测试了几种算法,如Logistic回归,随机森林,标准梯度提升和XGBoost。
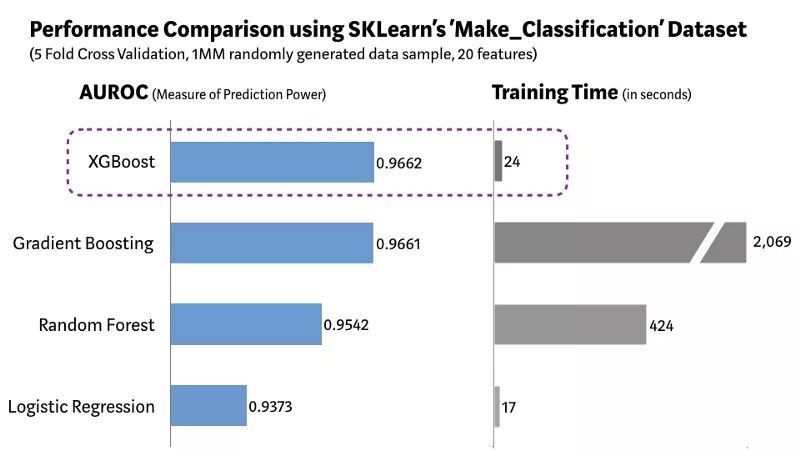
使用SKLearn的Make_Classification数据集的XGBoost与其他ML算法
如上图所示,与其他算法相比,XGBoost模型是预测性能和处理时间的最佳组合。其他严格的基准研究也得到了类似的结果。所以XGBoost在最近的数据科学竞赛中被广泛使用。
机器学习如同生活,没有免费的午餐。作为数据科学家,我们必须测试所有可能的数据算法,以确定冠军算法。此外,选择正确的算法是不够的。我们还必须通过调整超参数为数据集选择正确的算法配置。选择算法还有其他几个考虑因素,例如计算复杂性,可解释性和易于实现性。如此,机器学习开始从科学走向艺术,但老实说,这就是奇迹的开端!
未来何去何从
机器学习是一个非常活跃的研究领域,已经有几种可行的替代XGBoost的方案。微软研究院最近发布了LightGBM框架,用于梯度提升,显示出巨大的潜力。由Yandex Technology开发的CatBoost已经提供了令人印象深刻的基准测试结果。这是一个时间问题,但直到下一个更强大的挑战者出现之前,XGBoost将继续统治机器学习世界!
专注于数据科学领域的知识分享
欢迎在文章下方留言与交流
推荐阅读
程序员如何用Python了解女朋友的情绪变化?
从论文分析,告诉你什么叫 “卡方分箱”?
嫌pandas慢又不想改代码怎么办?来试试Modin
数据分析这碗饭,该怎么吃?
如何在一场面试中展现你对Python的coding能力?
《都挺好》弹幕比剧还精彩?394452条弹幕数据来告诉你答案
重磅!Python官方中文文档正式发布


