
- 1mysql系列之-根据月份查询数据_mysql按月份查询并汇总
- 2Ubuntu22.04与深度学习配置(已搭建三台服务器)_深度学习是用ubantu20好还是用ubantu22比较好
- 3vscode 远程开发golang_vscode ssh 远程开发怎么启动golang项目
- 4网络安全CTF夺旗赛入门到入狱-入门介绍篇_ctf夺旗赛找flag
- 5nvm安装步骤及使用方法_nvm使用教程
- 6linux 完全卸载docker_linux完全卸载docker
- 7基于hadoop或docker环境下,Kafka+flink+mysql+datav的实时数据大屏展示_flink 实时大屏
- 8springboot--跨域_springboot什么是跨域问题
- 9常见算法在实际项目中的应用_算法在实际开发中有用么
- 10MySQL 10几种索引类型,你都清楚吗?_mysql索引分类
【小沐学AI】智谱AI大模型的一点点学习(Python)_智谱开源大模型源代码
赞
踩
1、简介
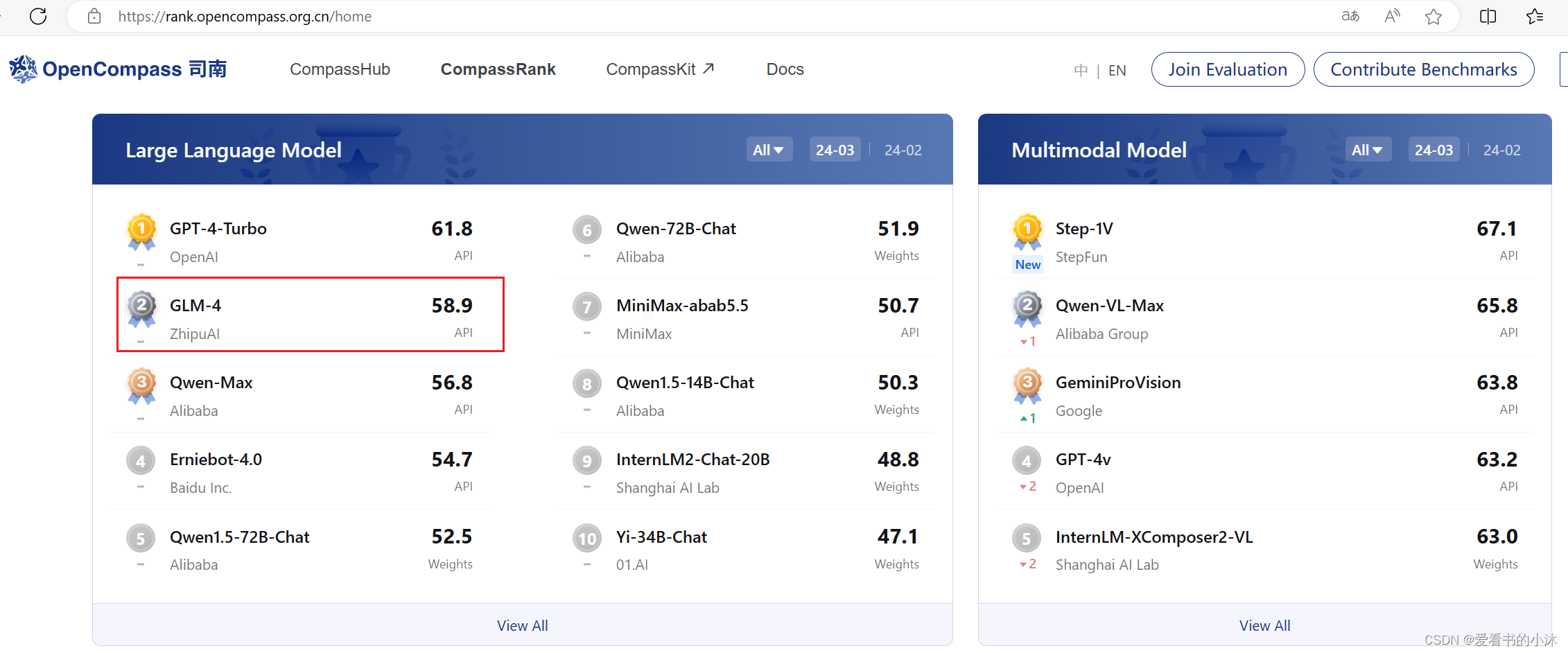
1.1 大模型排行榜
https://rank.opencompass.org.cn/home
202年1月30日,大模型开源开放评测体系司南(OpenCompass2.0)正式发布,旨在为大语言模型、多模态模型等各类模型提供一站式评测服务。
2、智谱AI
https://maas.aminer.cn/
https://open.bigmodel.cn/
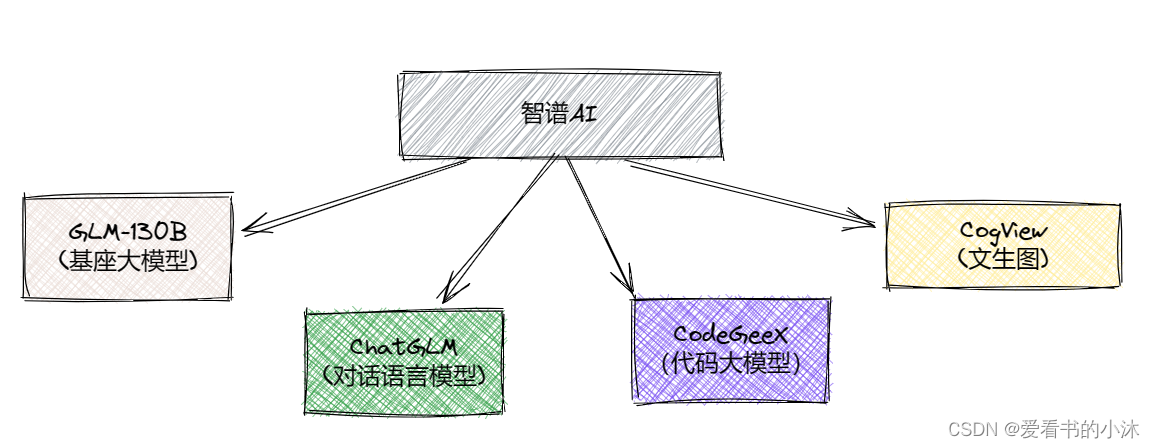
GLM 全名 General Language Model ,是一款基于自回归填空的预训练语言模型。ChatGLM 系列模型,支持相对复杂的自然语言指令,并且能够解决困难的推理类问题。该模型配备了易于使用的 API 接口,允许开发者轻松将其融入各类应用,广泛应用于智能客服、虚拟主播、聊天机器人等诸多领域。
2.1 GLM
基于领先的千亿级多语言、多模态预训练模型,打造高效率、通用化的“模型即服务”AI开发新范式
全面升级的新一代基座大模型GLM-4,整体性能相比GLM3提升60%,支持128K上下文,可根据用户意图自主理解和规划复杂指令、完成复杂任务。
2.1.1 模型简介
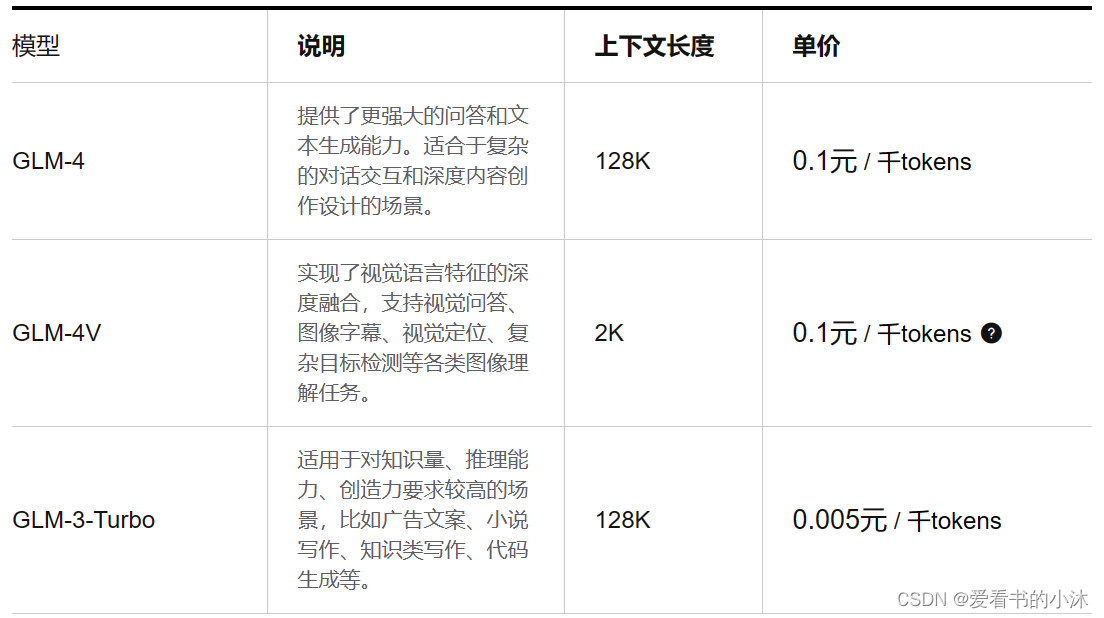
- GLM-4
模型编码:glm-4
根据输入的自然语言指令完成多种语言类任务,推荐使用 SSE 或异步调用方式请求接口
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的slogan"},
{"role": "assistant", "content": "当然,为了创作一个吸引人的slogan,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱AI开放平台"},
{"role": "assistant", "content": "智启未来,谱绘无限一智谱AI,让创新触手可及!"},
{"role": "user", "content": "创造一个更精准、吸引人的slogan"}
],
)
print(response.choices[0].message)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- GLM-4V
模型编码:glm-4v
根据输入的自然语言指令和图像信息完成任务,推荐使用 SSE 或同步调用方式请求接口
from zhipuai import ZhipuAI client = ZhipuAI(api_key="") # 填写您自己的APIKey response = client.chat.completions.create( model="glm-4v", # 填写需要调用的模型名称 messages=[ { "role": "user", "content": [ { "type": "text", "text": "图里有什么" }, { "type": "image_url", "image_url": { "url" : "https://img1.baidu.com/it/u=1369931113,3388870256&fm=253&app=138&size=w931&n=0&f=JPEG&fmt=auto?sec=1703696400&t=f3028c7a1dca43a080aeb8239f09cc2f" } } ] } ] ) print(response.choices[0].message)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- GLM-3-Turbo
模型编码:glm-3-turbo
根据输入的自然语言指令完成多种语言类任务,推荐使用 SSE 或异步调用方式请求接口
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-3-turbo", # 填写需要调用的模型名称
messages=[
{"role": "user", "content": "作为一名营销专家,请为我的产品创作一个吸引人的slogan"},
{"role": "assistant", "content": "当然,为了创作一个吸引人的slogan,请告诉我一些关于您产品的信息"},
{"role": "user", "content": "智谱AI开放平台"},
{"role": "assistant", "content": "智启未来,谱绘无限一智谱AI,让创新触手可及!"},
{"role": "user", "content": "创造一个更精准、吸引人的slogan"}
],
)
print(response.choices[0].message)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.1.2 开源代码
2.1.2.1 GLM-130B
https://github.com/THUDM/GLM
https://models.aminer.cn/glm-130b/
https://github.com/THUDM/GLM-130B
GLM-130B: An Open Bilingual Pre-Trained Model (ICLR 2023)
GLM-130B 是一个开源开放的双语(中文和英文)双向稠密模型,拥有 1300 亿参数,模型架构采用通用语言模型(GLM1)。它旨在支持在一台 A100(40G * 8) 或 V100(32G * 8)服务器上对千亿规模参数的模型进行推理。截至 2022 年 7 月 3 日,GLM-130B 已完成 4000 亿个文本标识符(中文和英文各 2000 亿)的训练。

[2023.03.14] 我们很高兴地推出基于 GLM-130B 的双语对话语言模型 ChatGLM,以及其开源版本 ChatGLM-6B,它只能在 6GB GPU 内存下运行!
2.2 ChatGLM
基于GLM模型开发,支持多轮对话,具备内容创作、信息归纳总结等能力
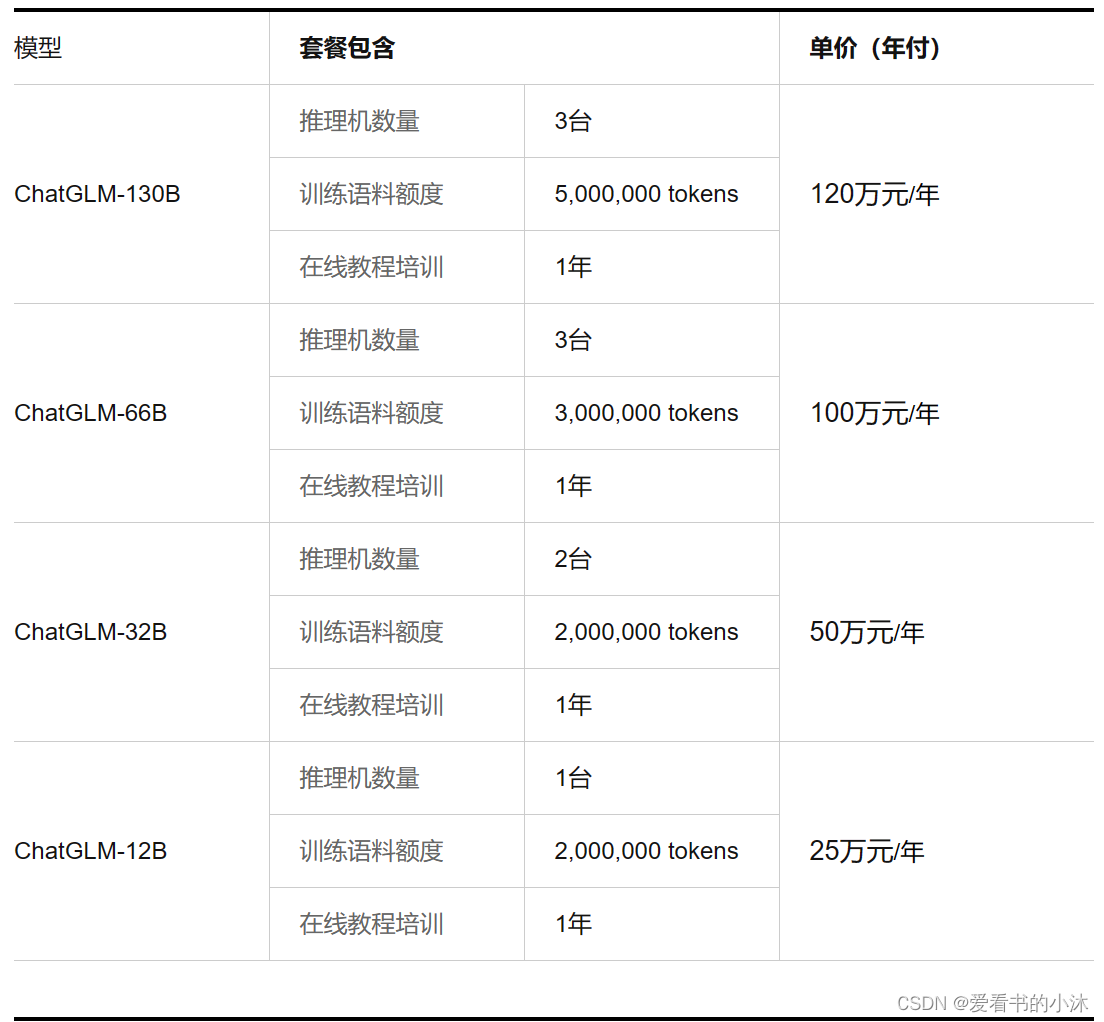
2.2.1 模型简介
2.2.2 开源代码
2.2.2.1 ChatGLM
https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
新一代开源模型 ChatGLM3-6B 已发布,拥有10B以下最强的基础模型,支持工具调用(Function Call)、代码执行(Code Interpreter)、Agent 任务等功能。
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
硬件需求:
| 量化等级 | 最低 GPU 显存(推理) | 最低 GPU 显存(高效参数微调) |
|---|---|---|
| FP16-(无量化) | 13 GB | -14 GB |
| INT8 | 8 GB | 9 GB |
| INT4 | 6 GB | 7 GB |
- ChatGLM-6B
可以通过如下代码调用 ChatGLM-6B 模型来生成对话:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
2.2.2.2 ChatGLM2
https://github.com/THUDM/ChatGLM2-6B
ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
[2023/07/31] 发布 ChatGLM2-6B-32K 模型,提升对于长文本的理解能力。
[2023/07/25] 发布 CodeGeeX2 ,基于 ChatGLM2-6B 的代码生成模型。
[2023/06/25] 发布 ChatGLM2-6B,ChatGLM-6B 的升级版本
- ChatGLM2-6B (base)
- ChatGLM2-6B
- ChatGLM2-12B (base)
- ChatGLM2-12B
可以通过如下代码调用 ChatGLM2-6B 模型来生成对话:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
2.2.2.3 ChatGLM3
https://github.com/THUDM/ChatGLM3
ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上.
- ChatGLM3-6B
- ChatGLM3-6B-Base
- ChatGLM3-6B-32K
- ChatGLM3-6B-128K
可以通过如下代码调用 ChatGLM3 模型来生成对话:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
2.3 CodeGeeX
第二代CodeGeeX模型作为强大的AI编程助手,支持超过100种编程语言,具备代码生成与补全、续写、翻译、智能问答等能力。
2.3.1 模型简介
https://codegeex.cn/zh-CN
https://zhipu-ai.feishu.cn/wiki/CuvxwUDDqiErQUkFO2Tc4walnZY
CodeGeeX支持多种主流IDE,如VS Code、IntelliJ IDEA、PyCharm、Vim等,
同时,支持Python、Java、C++/C、JavaScript、Go等多种语言。

CodeGeeX是一款基于大模型的全能的智能编程助手。它可以实现代码的生成与补全、自动添加注释、代码翻译以及智能问答等功能,能够帮助开发者显著提高工作效率。CodeGeeX支持主流的编程语言,并适配多种主流IDE。
CodeGeeX插件对个人用户完全免费。CodeGeeX面向企业提供CodeGeeX私有化部署服务。
2.3.2 开源代码
https://github.com/THUDM/CodeGeeX2
CodeGeeX2 是多语言代码生成模型 CodeGeeX (KDD’23) 的第二代模型。不同于一代 CodeGeeX(完全在国产华为昇腾芯片平台训练) ,CodeGeeX2 是基于 ChatGLM2 架构加入代码预训练实现。基于 ChatGLM2-6B 基座语言模型,CodeGeeX2-6B 进一步经过了 600B 代码数据预训练。
2.4 CogView
CogView模型,适用多种图像生成和增强任务,通过对用户文字描述快速、精准的理解,让AI的图像表达更加精确和个性化

2.4.1 模型简介
- 使用价格

- Python 调用示例
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 请填写您自己的APIKey
response = client.images.generations(
model="cogview-3", #填写需要调用的模型名称
prompt="一只可爱的小猫咪",
)
print(response.data[0].url)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.4.2 开源代码
https://github.com/THUDM/CogView
https://github.com/THUDM/CogView2
文本到图像生成。NeurIPS 2021 论文“CogView: Mastering Text-to-Image Generation via Transformers”的存储库。

硬件:建议使用配备 Nvidia A100 的 Linux 服务器。
论文 CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers
2.5 CogVideo
2.5.1 模型简介
https://models.aminer.cn/cogvideo/
CogVideo是目前最大的通用领域文本到视频生成预训练模型,含94亿参数。CogVideo将预训练文本到图像生成模型(CogView2)有效地利用到文本到视频生成模型,并使用了多帧率分层训练策略。
2.5.2 开源代码
https://github.com/THUDM/CogVideo
文本到视频生成。ICLR023论文“CogVideo:“CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers”
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!

