
- 1一文了解——大模型在金融行业的应用场景和落地路径_金融行业大模型应用
- 2Linux进程概念
- 3必备年终绩效工作总结模板
- 4绝对干货 | PMP考试知识体系精髓归纳,看完本文考试so easy_pmp体系
- 5Quartus II 15.0波形仿真解决方案_quartus ii15.0波形仿真
- 6[SQL系列] 从头开始学PostgreSQL Union Null 别名 触发器_plpgsql union all
- 7python将电视剧按收视率进行排序_2019电视剧收视率排行榜
- 8基于FPGA的DDS在Modelsim与TD的联合仿真(三)_modelsim怎么添加安路ip库
- 9【毕业设计】微信小程序校园跑腿系统_校园跑腿系统论文
- 102023年第十四届蓝桥杯大赛python组省赛真题(更新中)-最新的_给定 n 个数 ai,问能满足 m! 为∑ni=1(ai!) 的因数的最大的 m 是多少。其中 m!
文本匹配、文本相似度模型之ABCNN
赞
踩
本文是我的匹配模型合集的其中一期,如果你想了解更多的匹配模型,欢迎参阅我的另一篇博文匹配模型合集
所有的模型均采用tensorflow进行了实现,欢迎start,[代码地址]https://github.com/terrifyzhao/text_matching
简介
本文将会介绍以CNN与attention机制做文本匹配的模型即ABCNN,这里给出论文地址ABCNN
在文本任务上,大部分模型均是采用以LSTM为主的结构,本文的作者采用了CNN的结构来提取特征,并用attention机制进行进一步的特征处理,作者一共提出了三种attention的建模方法,下文会详细介绍。
在开始讲解之前,我们简单说明下attention机制,例如我们有两个序列A与B,当我们需要进行相似度比较时,A序列某个时刻的值该和B序列哪个时刻比较最合适呢,而attention机制就是为了解决这个问题的,把B序列的每个时刻的值做了一个加权平均,用加权平均之后的值与A进行比较,说白了attention就是一个加权平均的过程,其中的权重就是BP过程中不断更新得到的,如果你想要了解更多attention的内容,欢迎阅读我的另外一篇博客Attention机制详解
论文中,作者分为了两个部分进行介绍,首先是没有attention仅有CNN的基础模型BCNN,后续又介绍了添加了attention的ABCNN,其中又分别介绍了三种模式,下文也会以该顺序进行讲解。
BCNN
BCNN的结构如下图所示

可以看到BCNN包括四部分,分别是Input Layer、Convolution Layer、Average Pooling Layer、Output Layer,第一层为Input Layer,第二层与第三层为卷积与池化层,最后是用LR作为Output Layer
Input Layer
Input Layer即输入层,该层主要是做词嵌入,论文中作者采用的是word2vec的方法,当然,也可以采用glove,elom等其他方法,或者直接输入one-hot,并添加embedding层,在我的代码中采用的是该方案。作者设置的词向量维度是300维,图中所示,左边序列是5个词维度为[5,300],右边序列是7个词维度为[7,300],注意这里作者输入的维度是不固定的,后续的池化层会将维度处理为一样的,在我的代码里会与这里不同一样,我设置了序列最大长度。
Convolution Layer
Convolution Layer即卷积层,在文本处理中,卷积核的大小通常为[n, embedding_size],n指的是节点的个数,可以理解为n-gram,从而从字/词特征中提取出短语特征,而这里的卷积层和大家平时使用的卷积还不太一样,这里采用了Wide Convolution宽卷积,我们看个图
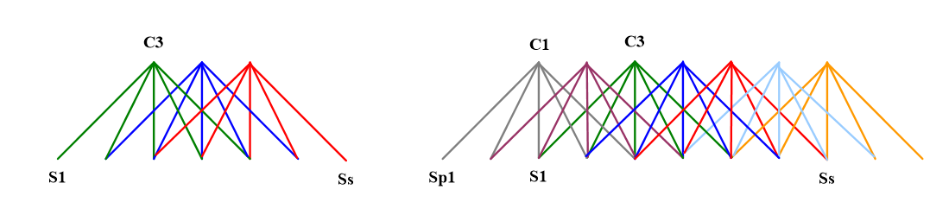
对于左边的图,一共有7个节点,卷积的width是5,进行了三次卷积,即我们上文提到的n这里是3,可以看到
S
1
S_1
S1与
S
S
S_S
SS节点只进行了一次卷积,显然不满足我们上文说的,其特征提取的效果肯定是有一定影响的,而宽卷积会在周围进行padding操作补0,如右图所示,这样就保证了边缘的值进行了多次卷积,考虑一下,如果是采用宽卷积,输出维度是啥, 以作者的图为例,我们的卷积核是3,输入序列长度是5,为了边缘卷积次数为3,我们需要在头和尾添加4个维度的0,输入维度变为9,最终输出维度就是9-3+1=7,设输入序列长度是S,卷积核宽度是W,那么输出维度为:2(n-1)+S-W+1即S-W+2n-1
Average Pooling Layer
Average Pooling Layer即平均池化层,仔细看,图中的第二层和第三层的池化层是不一样的,第二层的池化层是w-ap,第三层是all-ap,有什么区别呢,w-ap的核大小是可以自己定义的即[n, 300],其操作过程类似卷积,只不过是取平均值,而all-ap的核大小是和输入的值的维度相同的,这样也就保证了输出的维度是[1, 300],从而使两个序列在比较的时候的值的维度是相同的。
Output Layer
Output Layer即输出层,很简单的LR做一个二分类,不再赘述。
这就是BCNN的全部内容,接下来我们看加了attention的BCNN即ABCNN
ABCNN
ABCNN作者提出了三种结构,我们分别讲解。
ABCNN-1

第一种attention的方法是对representation进行了处理,首先,针对两个不同的序列,生成attention matrix A,如图中所示,这个矩阵可以保存了序列0与序列1每一个词/字向量的相似度,论文中作者采用的是欧氏距离,其计算过程为 1 1 + ∣ x − y ∣ \frac {1}{1+|x-y|} 1+∣x−y∣1, ∣ x − y |x-y ∣x−y表示的是欧氏距离,还是以图中为例,0序列的长度是5,1序列的长度是7,我们需要计算的是0序列中5个节点分别与1序列的7个节点的相似度的值,所以A最终的维度是[5, 7],这个相似度的值我个人认为还可以采用余弦相似度或者直接两个矩阵相乘(归一化后的值直接相乘就是余弦相似度,所以两个矩阵直接相乘得到的结果理论上来说也可以表示相似度),不过论文中提到欧式距离效果更好一些。
attention matrix生成好后,就能计算attention feature了,计算方法是定义一个权重矩阵W,如图中所示0序列对应的是 W 0 W_0 W0 1序列对应的是 W 1 W_1 W1,W的维度为[d, s],d表示的是词/字向量维度,论文中是300,s表示的是序列长度,然后用这个权重矩阵和attention matrix相乘,所以最终的attention feature为
F 0 , a = W 0 ⋅ A T , F 1 , a = W 1 ⋅ A F_{0,a} = W_0 · A^T,F_{1,a} = W_1 · A F0,a=W0⋅AT,F1,a=W1⋅A
最终得到的attention feature维度和representation feature的维度是相同的。
ABCNN-2

第二种attention是对卷积之后的结果进行操作,attention matrix的生成方法和1的一样,生成完成后,会分别针对列与行进行求和,还是以图中为例,卷积0的维度为[7, 300],卷积1的维度为[9,300],matrix的维度是[7, 9],生成的求和权重为[7, 1]与[1, 9],之后的pooling的操作不是简单的求平均,而是换成了把对应的行和求和的权重进行对位相乘,所以最后池化后的结果维度和输入维度是相同的。
ABCNN1与ABCNN2有三个主要的区别
- 1是对卷积之前的值进行处理,2是对池化之前的值进行处理
- 1需要两个权重矩阵 W 0 W_0 W0与 W 1 W_1 W1,参数多一些,更容易过拟合,2不存在这个问题
- 由于池化是在卷积之后执行的,因此其处理的粒度单元比卷积大,在卷积阶段,获取到的是词/字向量,而池化层获取到的是短语向量,而这个短语向量的维度主要看卷积层的卷积核大小,因此,1和2其实是在不同的粒度上进行了处理。
ABCNN-3

第三种方式相信大家已经明白了,没错就是把第一种和第二种方式结合起来,如图所示,这里不再赘述。

