
热门标签
当前位置: article > 正文
大语言模型系列-GPT-3_gpt3 数据集
作者:花生_TL007 | 2024-04-26 09:41:26
赞
踩
gpt3 数据集
前言
《Language Models are Few-Shot Learners,2020》
前文提到GPT-2进一步提升了模型的zero shot能力,但是在一些任务中仍可能会“胡说”,GTP-3基于此提出了few shot,即预测时给出少量精确案例,提升模型的准确性,同时进一步增大模型。
一、GTP-3的改进
- Larger Model: GPT-3将Transformer堆叠的层数从48层增加到96层,每层有96个注意力头,隐层的维度从1600提升至12888,最大模型参数达到1750 亿(175B)。
- Larger Dataset:GPT-3 使用了多个数据集,其中最大的是 CommonCrawl,原始未处理的数据达到了 45TB,通过数据清洗工作(LR 分类、去重、加入 BERT、GPT、GPT-2 等数据集),最终得到的数据集大小为570G。
- 上下文大小 (context size) :从GPT-2的1024提升到了2048。
- 注意力机制:引入了 Sparse Transformer 中的 sparse attention 模块(稀疏注意力)。
ps:
sparse attention 与传统 self-attention(称为 dense attention) 的区别在于:
- dense attention:每个 token 之间两两计算 attention,复杂度 O(n²)
- sparse attention:每个 token 只与其他 token 的一个子集计算 attention,复杂度 O(n*logn)
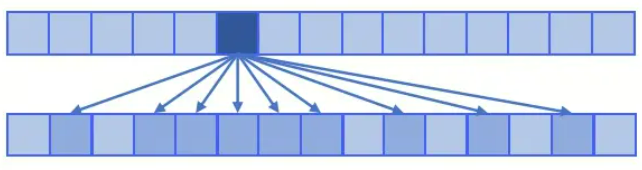
具体来说,sparse attention 除了相对距离不超过 k 以及相对距离为 k,2k,3k,… 的 token,其他所有 token 的注意力都设为 0,k=2的稀疏注意力如下图所示:
使用 sparse attention 的好处主要有以下两点:
- 减少注意力层的计算复杂度,节约显存和耗时,从而能够处理更长的输入序列;
- 具有“局部紧密相关和远程稀疏相关”的特性,对于距离较近的上下文关注更多,对于距离较远的上下文关注较少;
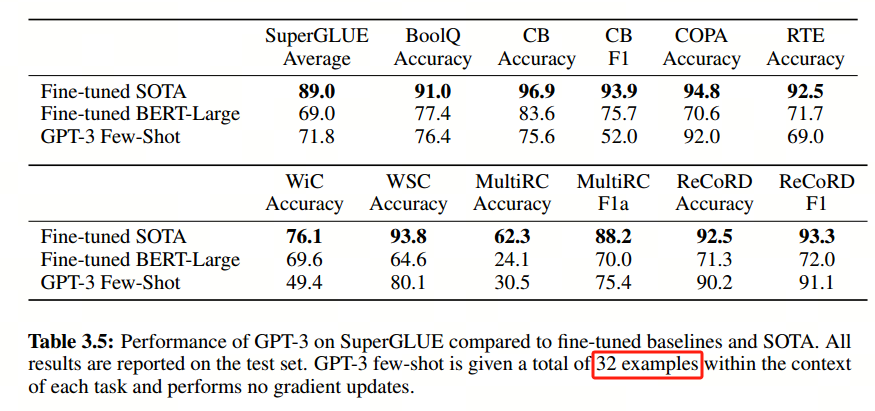
- few-shot:相比于finetune,可以提升模型表现,且无需大数据集和再训练,需要注意的是表现仍远小于SOTA微调技术,见下图。
二、GPT-3的表现
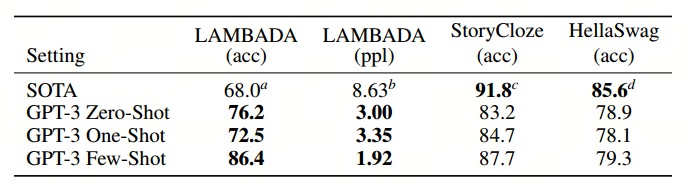
完形填空任务和完成任务:
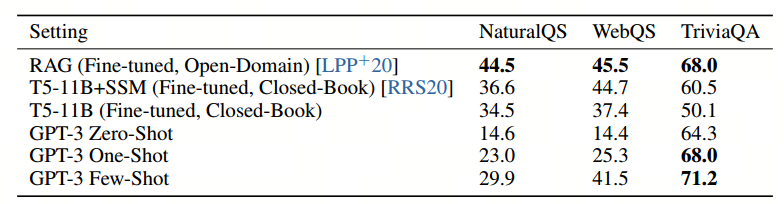
问答(QA)任务:
问答(QA)任务和阅读理解(RC)任务:
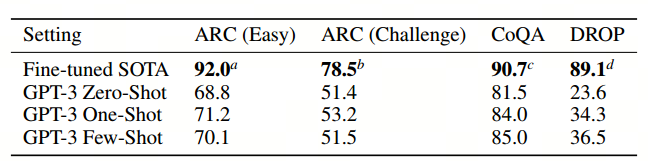
翻译任务:
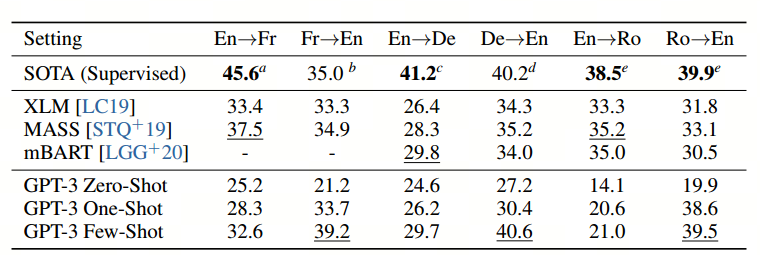
总结
虽然 GPT-3 取得了非常亮眼的效果,但仍存在一些问题:
- 当生成文本长度较长时会出现各种问题,比如重复生成一段话,前后矛盾,逻辑衔接不好等等;
- 模型和结构的局限性,对于某一些任务,比如填空类型的文本任务,使用单向的自回归语言模型确实存在一定的局限性,这时候如果同时考虑上文和下文的话,效果很可能会更好一些;
- 预训练语言模型的通病,在训练时,语料中所有的词都被同等看待,对于一些虚词或无意义的词同样需要花费很多计算量去学习,无法区分学习重点;
- 样本有效性或者利用率过低,训一个模型几乎要把整个互联网上的文本数据全都用起来,这与我们人类学习时所需要的成本存在非常大的差异,这方面也是未来人工智能研究的重点;
- 模型到底是在“学习”还是在“记忆”?
- 训练和使用成本都太大了;
- 不可解释性;
- 模型最终呈现的效果取决于训练数据,这会导致模型会出现各种各样的“偏见”;
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/490264
推荐阅读

相关标签

