
- 1Cesium介绍及3DTiles数据加载时添加光照效果对比_cesium光照
- 2RabbitMQ的死信队列详解及实现_获取死信队列中的信息
- 3PeLK:通过周边卷积的参数高效大型卷积神经网络
- 4react 暂存数据持久化_react store 数据持久化
- 5Map集合和Collections(集合工具类)_collections工具类中的binarysearch()方法中的key是map中的键吗
- 6如何解决Git合并分支造成的冲突_git合并出现冲突是如何解决的
- 7jmeter 性能测试结果分析_jmeter结果分析
- 8在Git上放一个静态页面并且可以访问_gitlab 怎么发布静态页面
- 9机械臂视觉抓取总结_机械臂目标定位与抓取
- 10Jupyter 进阶教程
移动互联网大数据助力金融风控(课程精华笔记+PPT)_银行数字化风控ppt
赞
踩

[导读]为了让清华大学大数据能力提升项目的学生在基础学习和科研的基础之上,更好地了解大数据技术行业领域中的应用,清华-青岛数据科学研究院支持开设了金融大数据方向《量化金融信用与风控分析》课程(课号:80470193)。
本课程由清华大学交叉信息研究院助理院长、清华大数据能力提升项目教育指导委员会委员徐葳老师开设,并且聘任加州大学伯克利分校计算机博士黄铃和美国卡内基·梅隆大学高性能计算研究教学中心创始人、联席总监种骥科博士联袂任教。
在讨论课上,同学们会深度接触互联网金融行业中建立信用和风控模型的理论和实践案例,并了解关键学术挑战和应对挑战的解决方案。同学们还将亲手设计实现信用和风控模型,通过讲座了解世界上最先进的信用分析和反欺诈的方法,优秀项目成果还有望投稿一流的学术会议。
本文来自该课程中的第四次讲座内容。

中国信用体系正处于建设完善阶段,大量人群不在覆盖范围内,难以享受信用服务,金融机构对信用用户的人群下探推动了行为大数据在风控过程中的使用。移动互联网用户行为数据作为自然人的指端延展具有数量大、维度多、动态好等特点,正在逐渐成为白户人群的信用信息替代品。本次清华大数据“技术·前沿”讲座,嘉宾陈雷从移动互联网数据的采集、初步加工、特征因子工程、模型与数据评估等方面完整阐述了TalkingData在金融风控领域应用上的数据价值探索与心路历程。

陈雷
TalkingData FinTech总经理
陈雷拥有20多年IT行业的业务及技术咨询和服务经验。现就职于中国最大的独立第三方移动数据服务平台TalkingData,任FinTech总经理,负责金融科技大数据应用产品。
之前陈雷曾经服务于Oracle, IBM, DWL等企业,历任Oracle中国区大数据技术总监,大客户技术总监, IBM 首席架构师等职务,负责电信、金融、零售、物流等多个行业的业务和技术咨询工作。陈雷毕业于浙江大学、约克大学,拥有多项职业技术认证和技术专利。
PPT+课程精华笔记
▼

一、风控、征信、反欺诈行业与业务背景
通过几个报道对整个行业现状做一些了解,我们就可以理解为什么现在风控如此之火,征信、反欺诈为什么尤其重要。
1. 银行业务的下沉

过去银行只在线下发放实体信用卡,而现在中国有很多家的银行都在尝试虚拟信用卡。
虚拟信用卡的推出对市场意味着什么呢?过去我们办理实体卡往往是需要一个线下的过程,而虚拟卡是完全在线上完成。这是银行在攻占整个的消费分期以及往下层的金融市场,我们可以看到很多家银行在进入这个市场。
2. 从投资角度看消费金融的火热

现在很多的VC都在投资消费金融领域的团队,为什么VC如此看好这个领域?因为这里面可以有很多想象的空间。
3. 现金贷遭受严格监管
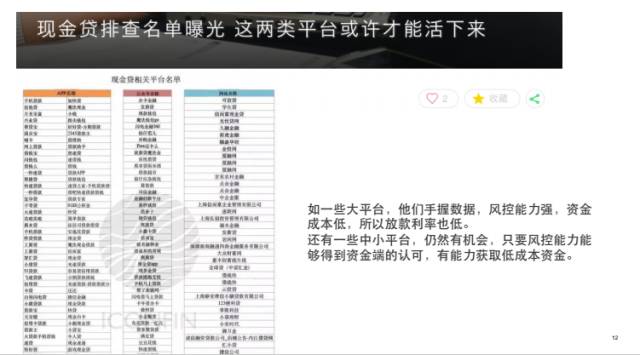
比如说现金贷,年化利率最高可以达到600%。
如此高利率的原因主要有以下几点:
第一,这些现金贷面向的客户群体,质量较低,是属于急需用钱类型的。在这种情况下可能会不择手段,风险系数很高。
第二,这些平台没有足够的风控能力,同时面临着大量的欺诈团伙,造成坏账率高,只能用高利率才能抵消风控不足的成本。
4. 个人征信牌照的暂停
中国目前为何还没有发出征信牌照?央行的解读给所有的征信公司泼了一盆冷水:目前所有的征信公司都没有达到要求,引发行业哗然。
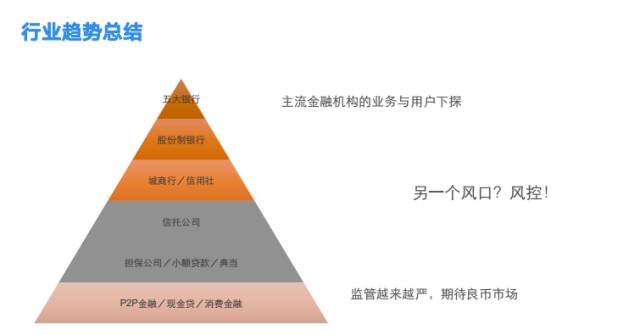
行业趋势总结
中国金融企业的金字塔:顶端是五大行,其次是股份制,再往下是城商行、信用社,之后是信托、担保,最下面的是p2p、现金贷等。最下面的市场监管越来越严,期望能改变劣币驱逐良币的现象,与此同时,主流金融机构的业务与用户正在下探。这些趋势意味着金融企业将会越来越重视风控,这可能是未来的一个风口。
二、机会与挑战 探索隐藏价值
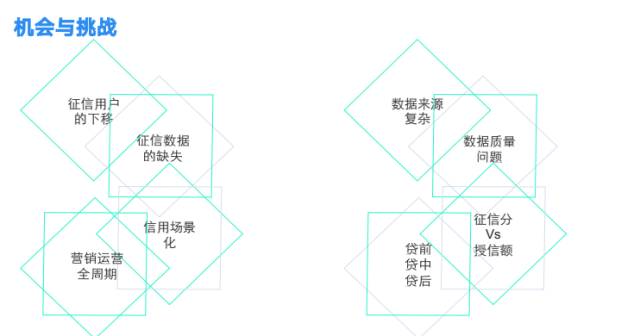
作为大数据行业的从业者,我们看到行业的变化带来了很多挑战与机会。
人行的征信体系,据统计大概4.7亿人有征信记录(银行账户、信用卡等),市场上存在大量的白户人群没有被人行征信覆盖,征信过程中缺少数据的支撑。
信用越来越场景化,需要对古玩论坛用户做精准匹配,而银行交易数据覆盖面窄,回流周期长,在使用时可能已经效果很低。 风控不仅仅是点,需要覆盖到用户的整个生命周期,从用户触达、授信、消费、离开等全流程提供风控支持。
于此同时市场上数据混杂,各种灰产、黑产导致各种数据安全与数据质量问题。6月1日实施的个人隐私保护法规,对数据交换、数据使用的监管更加严格。
诸多的机会与挑战给风控的从业人员与企业提出了更高的要求。
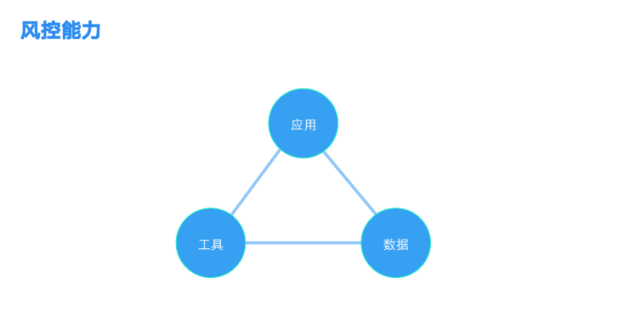
从科技公司角度看风控能力:
第一块是数据,数据是风控的基础,能拿到什么样的数据很重要;
第二块是工具,风控与反欺诈的需求对实时分析与响应提出了很高的要求,提供相应的技术工具的支撑;
第三块是应用,根据不同的商业模式和业务流程,会存在多个应用维度,应用时更是需要将技术与人工相结合,机器学习能解决一些问题;更多时候需要将各种数据集合到一起,让风控专家来看,会得到很多机器学习不能获得的信息与洞察。
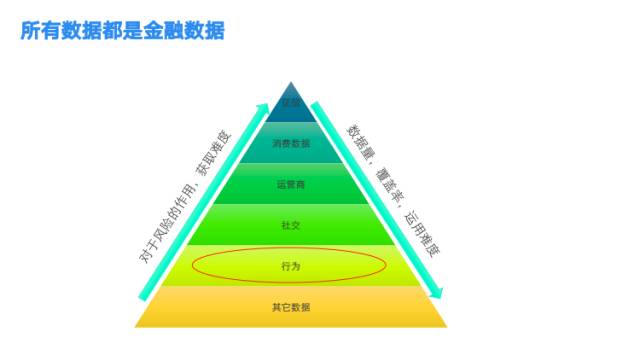
接下来我们看一下对金融数据的理解,在风控领域,数据的使用遵循这样的金字塔结构。
第一行是人行的征信数据。
第二行是消费的数据,代表了消费能力,偿还能力等。
第三行是运营商数据,虽然不一定与金融强相关,但包括多种多样用户的行为数据。运营商数据获取并不容易,需要对接33家运营商机构。(中国移动有31家机构,还有中国联通、电信)
第四行是社交数据,最大的是腾讯,由于BAT体系相对封闭,这部分的数据获取难度也极大。
第五行是行为数据,过去大家认为行为数据与金融是弱相关,但通过实践我们发现这部分数据还是很有意义的。行为数据的覆盖量大, 维度多且复杂,给数据处理的方式与能力提出了新的要求。
用户数据应用的能力正在从传统的扁平化向互联网立体信息转化。过去用户数据是扁平化的标签。现在有了大量立体化的数据采集手段可以更加立体化的描述一个用户的行为。比如大家使用的手机在应用过程中都会产生大量的应用数据,这些数据会被收集用于分析,随身设备中的传感器,比如手机里的陀螺仪,记录了大家的行走、运动行为。同时线下也有大量的数据收集技术,比如商场里的wifi流量探针,判断商场人流量。有很多这样的数据孤岛,如果打通了,就可以形成线上线下行为的立体化认知。
数据是每家公司一项很重要的资产,TalkingData提出了数据三重门的数据经营理念。 帮助我们的客户全方面理解自己的数据潜能,把传统交易数据的采集推进到交互门的数据采集。建立自有数据与公开市场门数据的交换能力, 真正把企业数据当作重要资产经营起来。
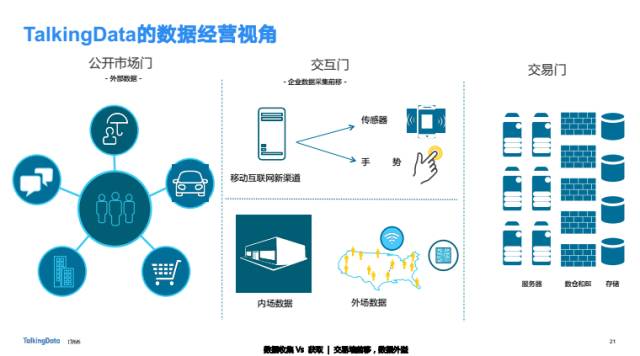
TalkingData也正在依托过去五年多时间通过运营积累的大量的数据,与我们的用户合作共同探索数据价值,同时依托自己在大数据领域的影响力,建立起大数据的生态圈,在合理合法的前提下,结合生态数据源加工、处理并利用数据,发掘数据价值。
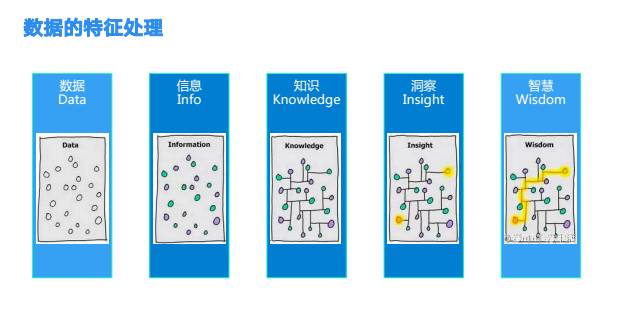
数据的处理的5个级别:
基础数据,数据初步加工后的信息,信息经过整合联接,形成知识,知识之上形成洞察,最后成为智慧。数据的特征加工就是这5个层次的数据应用过程。
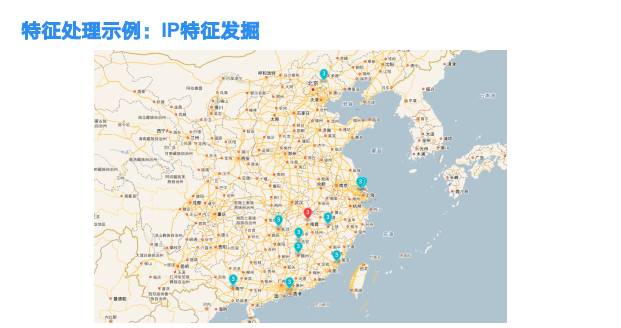
数据特征处理示例:
手机的出口IP,可以通过归因与地理位置匹配,形成一个用户的漫游情况。IP更可以使用时间来形成更复杂的认知。 例如一个晚间WI-FI IP出口可能是一个家庭, 白天则可能是个工作场所。
设备与IP的关系通过时间与空间的交叉关联,可以帮助我们发现两个设备之间的逻辑关系。下图中,我们看到两台设备在同一时间在两个相距甚远的两个地方同时出现,我们猜测这两台设备可能属于同一个人。下图为设备时空特征关联的知识图谱。
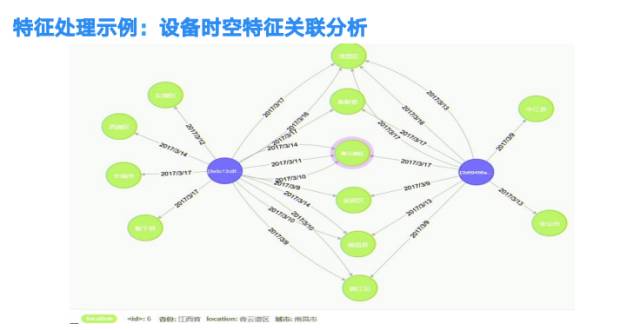
三、基于数据之上的风控应用
1. 营销反欺诈
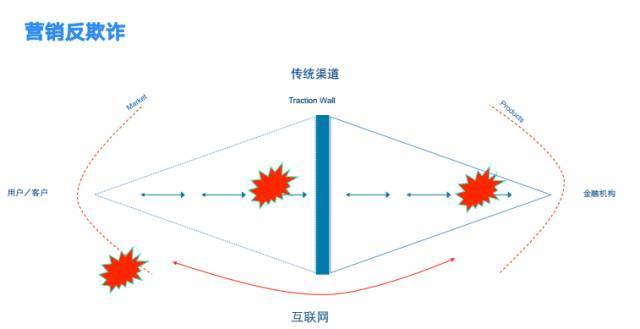
这是一张很经典的图,最左边是用户,最右边是金融机构,中间有两个括号,一个是市场(market),一个是产品(products)。金融公司制定的产品(product),通过市场(market)触达及转化目标用户,通过自己的渠道为用户服务,实现目标用户向客户的转化。
在这个中间过程中,就存在很多欺诈的可能,比如流量作假,骗取公司的市场费用;假app流量及活跃度,欺诈投资人的投资;产品推广及运营则会吸引团伙来薅羊毛,骗取公司的运营费用和经营成本。
下图展示了一个营销反欺诈能力的框架。
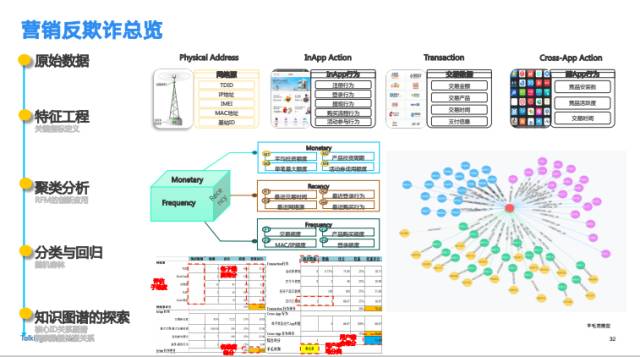
首先需要整合多维度的数据,包括:物理地址、app信息、交易信息和跨app信息等;接着抽取特征,做特征工程方面的工作;在此之上做聚类分析,识别出数据样本的特征模型, 最后通过分类与回归算法对样本用户进行分类与预测。知识图谱技术作为一个高效的互动工具,辅助业务人员进行数据探索,实现人与人工智能的高效结合。
2. 用户反欺诈
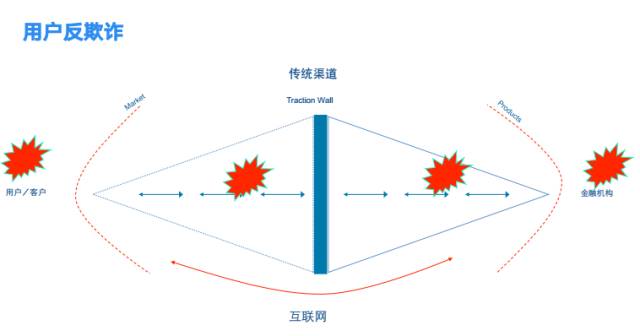
用户欺诈主要是针对信贷类产品,对用户欺诈的防治可以发生在用户的获取、授信、 交易,及贷后的每一个核心环节。用户反欺诈,希望能做到风控前置,在用户进来之时,就能识别欺诈。根绝欺诈很难,有效的方式是提高欺诈集团的欺诈成本,让其无利可图。
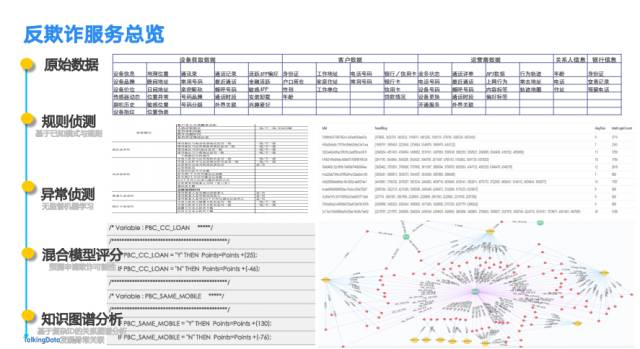
反欺诈服务完全是数据驱动,需要获取很多的信息,包括:设备数据、客户数据、运营商数据、关系人信息、银行信息等。
典型的欺诈异常包括:设备异常、账号异常、行为异常和交易异常等。
反欺诈系统是一个典型的规则驱动的系统, 已知规则形成规则集,直接使用,比如三要素验证、OCR人脸识别、验证银行卡、运营商等等。
更多的欺诈特征因子, 通过使用非监督机器学习技术做异常检测,并形成对欺诈行为的综合评判。图数据作为重要的社交图谱能力及技术帮助业务人员发现更加复杂的信息关联。
3. 用户授信辅助
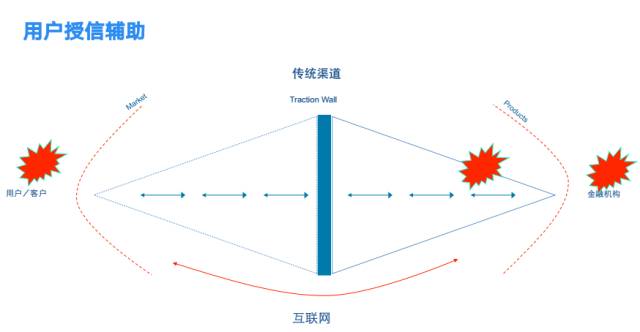
用户授信辅助主要发生在金融产品的营销环节、贷前审批环节及贷后管理环节。授信能力的前置,可以有效判断用户的信用能力,对用户实现精准营销推送,提升转化率。
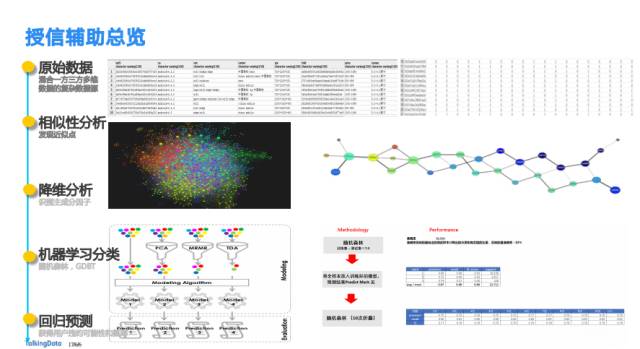
TalkingData深度发掘自有移动互联网行为数据,通过多种特征工程,机器学习等技术,形成了一个稳定的行为数据机器学习模型, 达到了很好的行为评分结果。这些能力已经投入实用,为用户的授信提供辅助决策支持。
目前大数据人才,尤其是数据科学家非常短缺,这类人才既要懂编码,还要懂数据分析之道,对行业知识也要有深刻的洞察力,为此,TalkingData推出“数据科学经营夏令营” 活动,包吃包住,还有硅谷游学机会,欢迎各位同学参加,点击文末“阅读原文”了解入营细节。

问答精选
Q:金融行业,比如银行要求可解释性,这块你们是如何处理的?
A:在模型中我们应用了近千个行为数据因子,由于因子过多,饱和度参差不齐,我们首先对特征因子进行了降维处理,筛选了两百多个因子入模型。同时我们输出了对Y值影响较高的数据因子供业务专家判读。这些因子的数据表征与专家认知基本匹配,为金融行业的客户提供可解释性。

