
- 1C语言数据结构——二叉树_二叉树结构体定义c语言
- 2操作系统进程调度实验报告_操作系统进程调度实验报告 系统要求用户先输入进程的数量,然后依次输入每个进程的
- 3YoloV5的学习与使用
- 4专业创新实践报告--YOLO v3算法详解以及和Faster-RCNN的比较_yolo算法流程图
- 5点击劫持漏洞原理和复现_点击劫持漏洞复现
- 6轻松搭建分布式对象存储:Spring Boot整合MinIO的快速指南_开源 对象存储搭建
- 7前端代码规范常见错误 一
- 8git clone时出现的两种报错及解决办法_autodl 不能git_git无法 clone
- 9开源大模型Llama 3来了:Meta才是真正的“OpenAI“_meta-llama-3 只是文本模型,不支持多模态
- 10虚拟机配置yum源_虚拟机sr0
7月7日!GLM大模型技术前沿与应用探索 | 2023世界人工智能大会
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
随着AIGC时代的到来,大型语言模型逐渐成为学术界和工业界的关注焦点。近期,各种大语言模型的涌现给自然语言处理领域的研究带来了诸多挑战,也逐渐对计算机视觉和计算机生物等领域产生了重要影响。强大的语言理解能力、生成能力、逻辑推理能力……大语言模型的魅力如此之大,未来究竟会怎样改变人类的生活呢?
世界人工智能大会KEG专场论坛将于7月7日下午14:00在上海世博中心正式召开,本期论坛由清华大学KEG实验室主办、AI TIME承办、东浩兰生(集团)有限公司协办。本次论坛将重点关注大语言模型前沿研究,聚焦GLM、CodeGeeX等具体大模型,来自各知名高校、研究院的专家将深入探讨其背后的研究难点、关键技术、拓展方向,从技术、产品、应用场景多维度分析讨论未来大模型的发展之路。
论坛亮点
”
1.千亿对话模型ChatGLM——推动行业智能化
ChatGLM:团队于2022年推出千亿模型GLM-130B,在斯坦福大学基础模型中心的评测中,GLM-130B在准确性和公平性指标上与GPT-3 175B (davinci) 接近或持平,鲁棒性、校准误差和无偏性优于GPT-3 175B。千亿对话模型ChatGLM在GLM-130B 基础上通过有监督微调等技术实现人类意图对齐。开源的62亿参数ChatGLM-6B模型初具理解人类指令意图的能力,并支持在单张 2080Ti 上进行推理使用。截至五月底,其全球下载量超过200万次,持续两周位列 Huggingface 全球模型趋势榜榜首。科技部在23年中关村论坛上发布的《中国人工智能大模型地图研究报告》显示ChatGLM-6B位列大模型开源影响力第一名。
2.辅助编程工具CodeGeeX——助力编程高效化
CodeGeeX:CodeGeeX是一个基于AI大模型的辅助编程工具,拥有130亿参数,支持23种编程语言。CodeGeeX可以根据自然语言或代码片段生成完整的代码,可以自动为你的代码逐行添加注释,也可以将一种编程语言准确的翻译成另一种编程语言。特别是“Ask CodeGeeX”功能可以在IDE中,通过对话的方式直接操作代码,开发者普遍认为使用CodeGeeX,编程效率提升50%以上。CodeGeeX是完全开源和免费的,在VS Code和JetBrains IDEAs的插件市场免费提供下载安装使用,目前全球安装使用的用户量超过100,000+,每天为开发者生成数百万行代码。
3.凝聚青年合力—— 推进研究前沿化
实验室长期承担国家级项目、国际合作项目以及部委和企事业单位合作项目,包括863计划项目、国家重点研发计划项目、自然科学基金重点项目、北京市科技计划项目、欧盟合作框架项目、中英牛顿高级学者基金项目,以及与工程院、新华社、华为、腾讯、阿里、美团、滴滴、OPPO的合作项目等。在国际顶级会议和期刊发表论文400余篇,授权发明专利50余项。实验室代表性研究成果“智能型科技情报挖掘和知识服务关键技术及其规模化应用”获得国家科技进步二等奖,核心技术获得第六届北京市发明专利一等奖。此外,还获得数据挖掘顶级国际会议KDD2020的Test-of-Time Award(十年最佳论文)、2017年北京市科技进步一等奖、2013年中国人工智能学会科技进步一等奖等。
实验室重视队伍培养,共培养博士、硕士毕业生160余人,博士后20人。其中人工智能领域杰青2人,高校教师13人(其中2人在美国任教),人工智能上市公司创始人2人(旷视唐文斌、杨沐),多人获得校优秀毕业论文、优秀毕业生以及北京市优秀毕业生和CFF优秀大学生。此外,实验室多年来努力探索交叉学科群体的队伍、基地和制度建设,在国际上和图灵奖得主John Hopcroft教授、美国科学院院士Jon Kleinberg教授和英国皇家科学院院士Wendy Hall教授等人保持长期合作,在国内和心理学、认知学、社会学等领域专家一直保持紧密合作。
论坛内容
7月7日 14:00—17:45
14:00-14:05
何芸
主持人开场
14:05-14:30
东昱晓
ChatGLM:预训练大模型探索与实践
14:30-14:50
张静
GLM-Dialog:噪声容忍的知识增强对话预训练模型
14:50-15:10
赖瀚宇
WebGLM:检索增强的大规模预训练模型
15:10-15:30
丁铭
VisualGLM-6B的原理与实践
15:30-15:50
陈波
xTrimoPGLM:面向统一的蛋白质千亿模型
15:50-16:10
郑勤锴
CodeGeeX:多语言代码生成模型与最佳实践
16:10-17:10
AI Debate
大模型是机器学习的未来吗?
17:10-17:30
互动交流
现场嘉宾 Q&A
嘉宾介绍

东昱晓
清华大学计算机系助理教授,知识工程实验室(KEG)成员,曾工作于脸书人工智能和微软总部研究院。研究方向为数据挖掘、图机器学习和预训练基础模型,相关成果应用于十亿级社交网络和知识图谱。入选IJCAI 22 Early Career Spotlight,获2017年ACM SIGKDD博士论文提名奖和2022年ACM SIGKDD新星奖。

张静
中国人民大学信息学院计算机系副教授。主要研究方向是基于预训练语言模型和知识图谱做神经符号推理。发表论文60余篇,包括KDD、ACL、SIGIR、WWW、EMNLP、WSDM等领域内国际顶级会议以及国际顶级期刊TKDE、TOIS论文。
Google引用次数6000余次。荣获2020年SIGKDD时间检验奖、2017年北京市科技进步一等奖(第四完成人),入选百度2023年AI华人女性青年学者榜(全球80人)。近年来担任WWW'23、IJCAI'21与PKDD/ECML'21/23程序委员会高级委员。任IEEE Transactions on Big Data、AI Open期刊编委 (Associate Editor)。

郑勤锴
清华大学知识工程实验室研究助理,本科及硕士毕业于上海交通大学,并取得巴黎高等电信学校工程师学位,研究领域是基于预训练模型的代码生成。在SIGKDD,NeurIPS等国际会议上发表多篇论文,曾获KDD Cup 2020数据挖掘竞赛第一名。

丁铭
本科、博士毕业于清华大学计算机系,师从唐杰教授。曾在Facebook AI Research、阿里达摩院、智源研究院等地从事科研工作。博士期间发表顶会论文20余篇,第一作者10篇,谷歌学术2800余次。在智谱VisualGLM项目中担任Project Lead。

陈波
清华大学知识工程实验室博士生,本科及硕士毕业于中国人民大学信息学院,研究领域是大型蛋白质语言模型,在SIGKDD、TKDE等国际顶级会议和期刊上发表多篇论文。

赖瀚宇
清华大学知识工程实验室研究生,研究领域是检索增强的大规模预训练模型。
报名流程

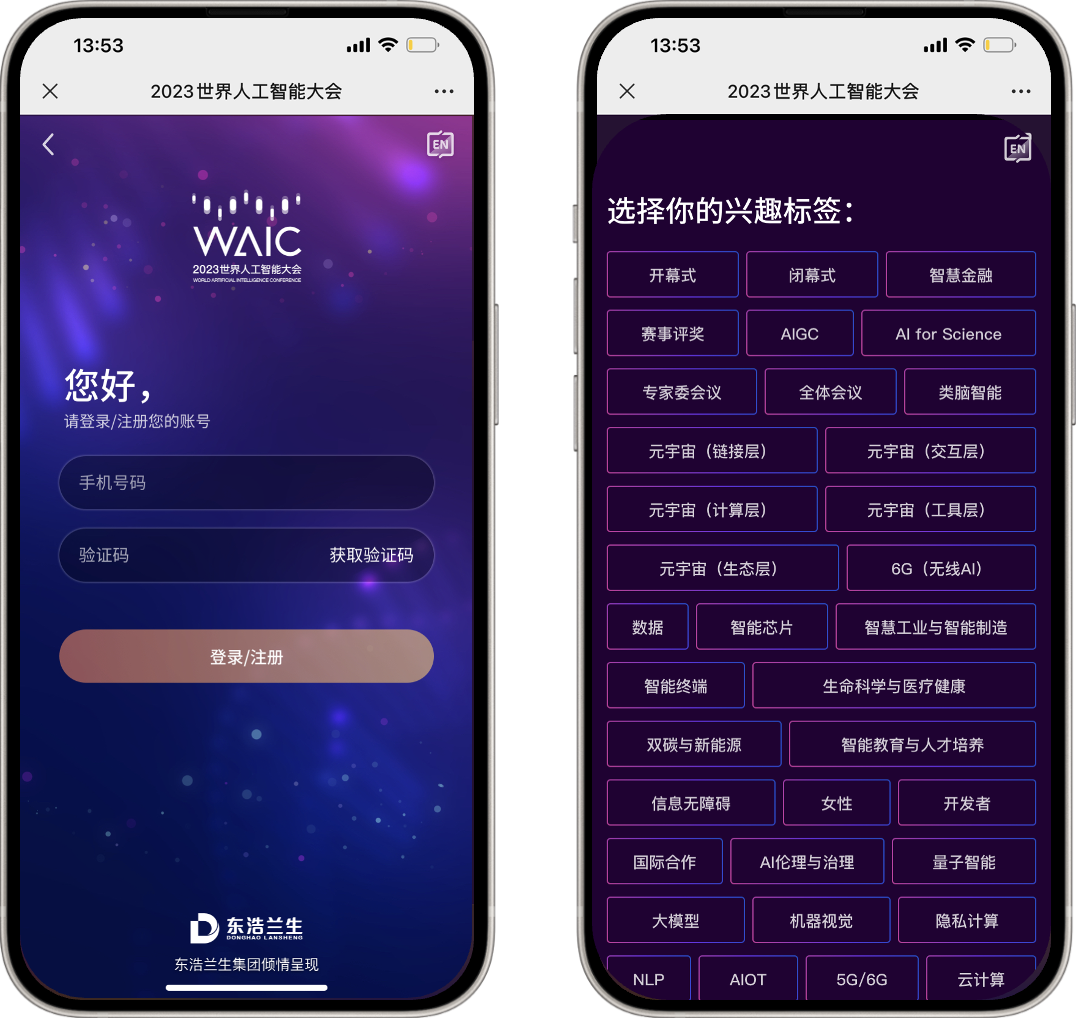
点开链接
注册登录
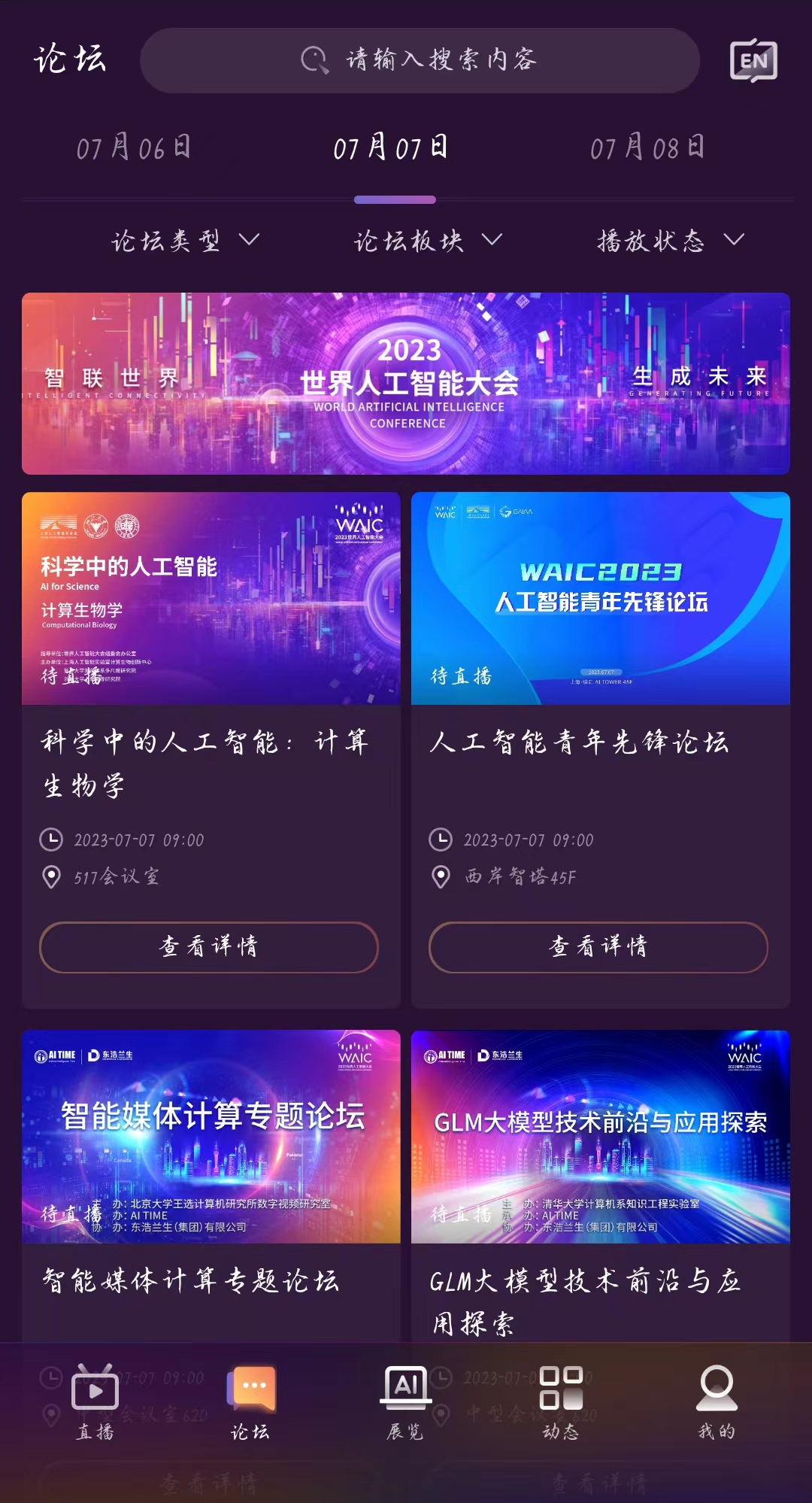
点击“论坛”
选择7月7日
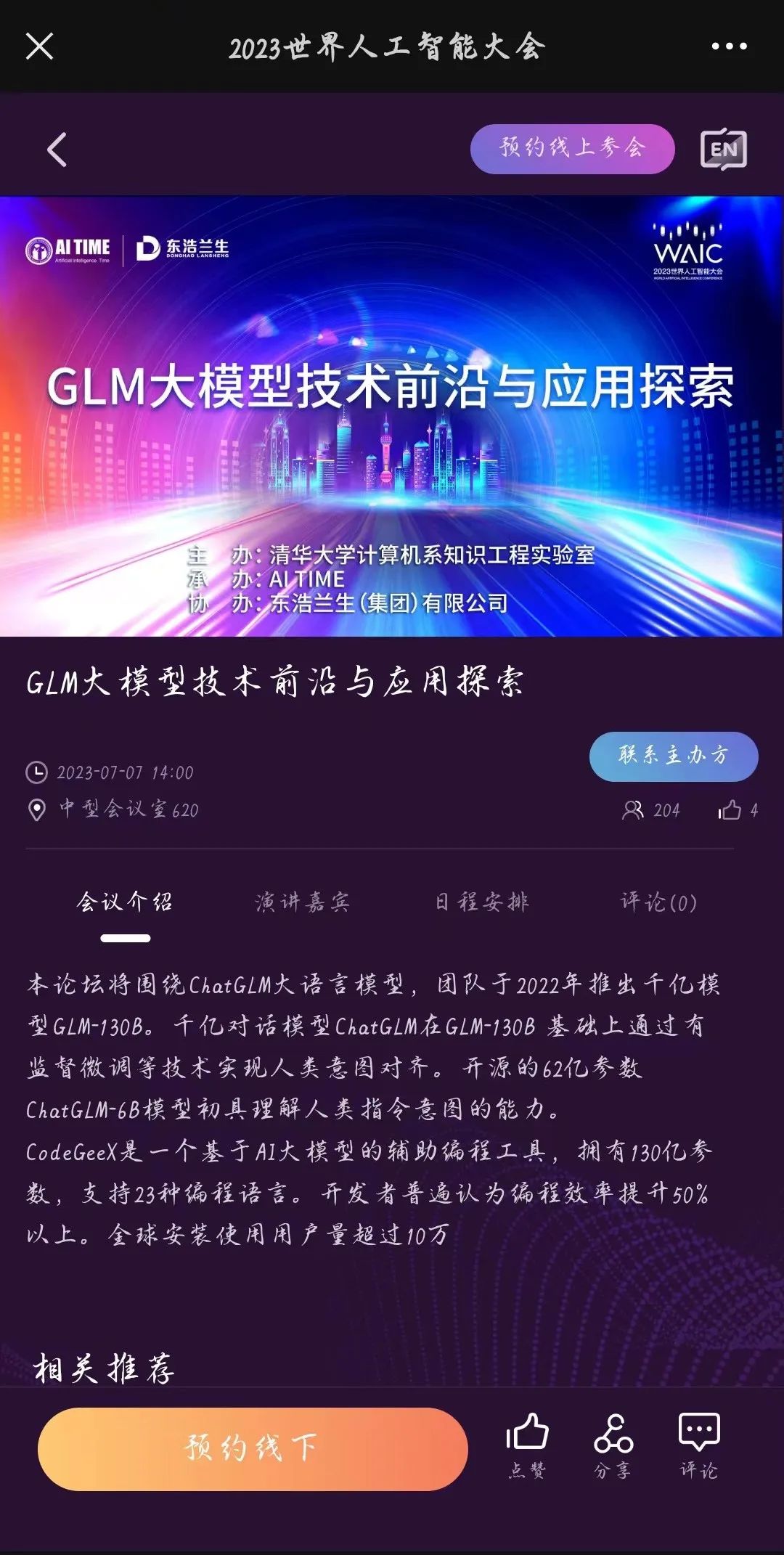
选择“GLM
大模型技术
前沿与
应用探索”
点击左下角
预约线下
或右上角预约
线上参会
即可完成报名
- 关注我们,记得星标 -
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1100多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 进行报名!

