
- 1Android 蓝牙开发(二) --手机与蓝牙音箱配对,并播放音频_android 蓝牙耳机接受音频
- 2【链表经典面试题保姆级题解】什么?这八个最基本的链表面试题你还没有掌握?最短的时间内教会你!_链表为空怎么解决
- 3绕过Cloudflare五秒盾,穿云API抓取网页不再等待_五秒盾会检测ip吗
- 4UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd2 in position 422: invalid continuation byte_syntaxerror: (unicode error) 'utf-8' codec can't d
- 5基于yolov5的苹果成熟度检测系统,可进行图像目标检测,也可进行视屏和摄像检测(pytorch框架)【python源码+UI界面+功能源码详解】_基于yolo的苹果成熟度识别
- 6第18届全国大学生智能汽车竞赛四轮车开源讲解【12】--写在最后_江科大智能小车
- 7什么是Kafka?有什么主要用途?_kafka作用
- 8java审批流创建及代码流程
- 9【记录】pip install git+https://github.com/XXX/XXX 报错
- 10整型提升和算术转换<C语言>
Kafka面试题_kafka消费阻塞
赞
踩
1. Apache Kafka是什么?
Apach Kafka是一款分布式流处理平台,用于实时构建流处理应用。它有一个核心的功能广为人知,即作为企业级的消息引擎被广泛使用(通常也会称之为消息总线message bus)。
2. Kafka 的设计是什么样的?
Kafka 将消息以 topic 为单位进行归纳
将向 Kafka topic 发布消息的程序成为 producers.
将预订 topics 并消费消息的程序成为 consumer.
Kafka 以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个 broker.
producers 通过网络将消息发送到 Kafka 集群,集群向消费者提供消息
3. Kafka 如何保证高可用?
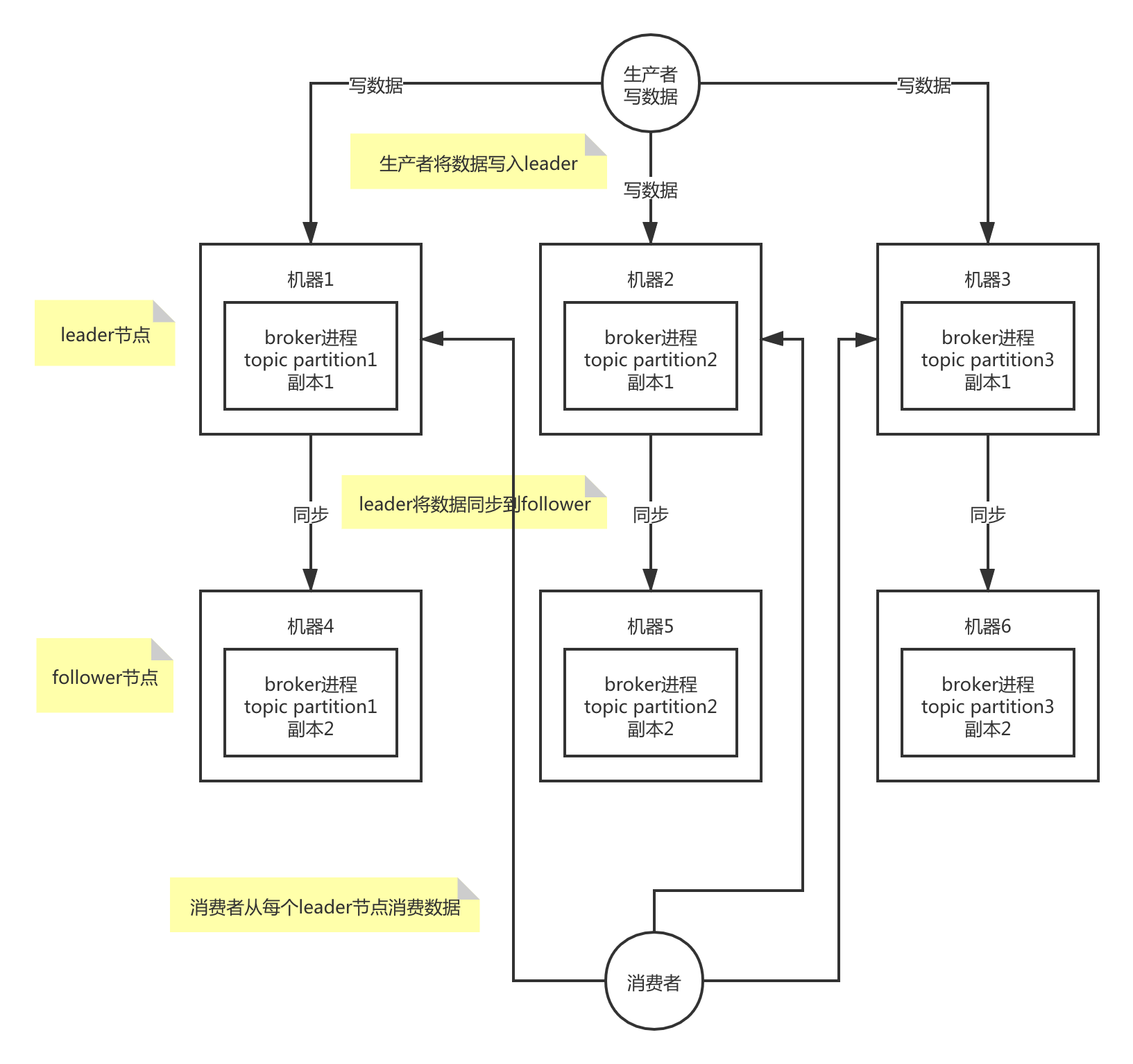
Kafka 的基本架构组成是:由多个 broker 组成一个集群,每个 broker 是一个节点;当创建一个 topic 时,这个 topic 会被划分为多个 partition,每个 partition 可以存在于不同的 broker 上,每个 partition 只存放一部分数据。
这就是天然的分布式消息队列,就是说一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
在 Kafka 0.8 版本之前,是没有 HA 机制的,当任何一个 broker 所在节点宕机了,这个 broker 上的 partition 就无法提供读写服务,所以这个版本之前,Kafka 没有什么高可用性可言。
在 Kafka 0.8 以后,提供了 HA 机制,就是 replica 副本机制。每个 partition 上的数据都会同步到其它机器,形成自己的多个 replica 副本。所有 replica 会选举一个 leader 出来,消息的生产者和消费者都跟这个 leader 打交道,其他 replica 作为 follower。写的时候,leader 会负责把数据同步到所有 follower 上去,读的时候就直接读 leader 上的数据即可。Kafka 负责均匀的将一个 partition 的所有 replica 分布在不同的机器上,这样才可以提高容错性。
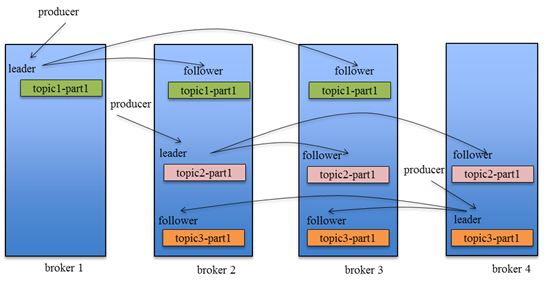
拥有了 replica 副本机制,如果某个 broker 宕机了,这个 broker 上的 partition 在其他机器上还存在副本。如果这个宕机的 broker 上面有某个 partition 的 leader,那么此时会从其 follower 中重新选举一个新的 leader 出来,这个新的 leader 会继续提供读写服务,这就有达到了所谓的高可用性。
写数据的时候,生产者只将数据写入 leader 节点,leader 会将数据写入本地磁盘,接着其他 follower 会主动从 leader 来拉取数据,follower 同步好数据了,就会发送 ack 给 leader,leader 收到所有 follower 的 ack 之后,就会返回写成功的消息给生产者。
消费数据的时候,消费者只会从 leader 节点去读取消息,但是只有当一个消息已经被所有 follower 都同步成功返回 ack 的时候,这个消息才会被消费者读到。
4. Kafka 消息是采用 Pull 模式,还是 Push 模式?
生产者使用push模式将消息发布到Broker,消费者使用pull模式从Broker订阅消息。
push模式很难适应消费速率不同的消费者,如果push的速度太快,容易造成消费者拒绝

