
- 1【Linux更新驱动、cuda和cuda toolkit】_linux系统如何更新主机的cuda版本
- 2新能源汽车2022智能化,感知方案的终极答案是?
- 3使用rust学习基本算法(四)
- 4C# Stopwatch计时器 记录方法执行时间_stopwatch stopwatch = new stopwatch();
- 5blinker小白入门学习_esp32_#include
- 6每个私域运营者都必须掌握的 5 大关键流量运营核心打法!
- 7精准测试:代码覆盖率与测试覆盖率
- 8像素与分辨率_像素与分辨率对照表
- 9「iOS」怎么修改去掉Navigation Bar上的返回按钮文本颜色,箭头颜色以及导航栏按钮的颜色_消除颜色type_navigation_bar
- 10如何快速开发一个自己的微信小程序_小程序怎么开发
字节的java面经_字节java工程师面经
赞
踩
多态时会出现类型擦除,什么是类型擦除?
多态是同一种方法的不同表现形式,具体的实现方式有继承,接口和泛型
类型擦除是对于泛型来说的,java泛型是在编辑器层次实现的,在生成字节码的时候不带有类型信息,使用泛型时加上类型参数,编译时又去掉,这个过程叫做类型擦除。
Java内存模型是什么
Java内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了Java程序在各种平台下对内存的访问都能保证效果一致的机制及规范。
所有的变量都存储在主内存,每个线程都拥有自己的内存,存储着从主存拷贝的自己需要的变量,不同线程之间不能访问别人的内存空间,也不能直接访问主存,而JVM负责线程内存和主存之间的联系。
什么是线程死锁?线程死锁怎么避免?
这个我根据以前的理解,线程死锁就是类似于X和Y两个变量,两个线程各枷锁了一个,导致互相等待,死锁避免的方法是二阶段加锁和解锁。
那几个修饰符关键字
volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
synchronized 关键字声明的方法同一时间只能被一个线程访问。
线程通信方式?
wait/notify 等待
线程A执行到lock.wait()时,会释放锁,并将当前线程状态设置为WAITING状态,线程B获得锁,当执行到lock.notify()时,会通知所有等待队列中的线程,然后继续执行lock.notify()之后的代码,执行完成之后释放锁。
Volatile 内存共享
CountDownLatch 并发工具
CyclicBarrier 并发工具
具体参考https://www.cnblogs.com/linyufeng/p/9671844.html
类加载的过程?
类加载器就是寻找类或接口字节码文件进行解析并构造JVM内部对象表示的组件,在java中类装载器把一个类装入JVM,经过以下步骤:
1、加载:查找和导入Class文件
2、链接:其中解析步骤是可以选择的 (a)检查:检查载入的class文件数据的正确性 (b)准备:给类的静态变量分配存储空间 (c)解析:将符号引用转成直接引用
3、初始化:对静态变量,静态代码块执行初始化工作
进程调度算法?
先来先服务
短进程优先
最短剩余时间优先(SRT是针对SPN增加了抢占机制的版本,就好比例子中B运行时间非常长,在这期间其他所有的进程都在等待,如果将其中断,先处理所需时间少的,运行效率会有显著提升。一定要先明确SRT是抢占的。)
优先权调度
基于时间片的轮转法(进程会被丢到队列里,当用过时间片之后就排到队尾)
多级反馈队列调度(存在多个队列,优先级从高到低,时间片从大到小,在高优先级队列执行完之后加入低优先级队列)
Treeset Treemap的底层实现
treeset底层是红黑树实现的,利用自然排序或比较器实现排序。
treemap底层是基于key进行compartor接口的比较函数实现的,内部是红黑树。
SQL里where having分别是做什么的
where可以使用数据库里所有的字段,having使用的是选择投影出来的属性,并且having不能使用and和or连接条件。
MySQL索引类别
这个感觉各个地方讲的都不一样,我按我老师讲的,关系型数据库索引分为树索引和哈希索引。
可以说说两种索引的区别
树索引具体是使用B+TREE

此外有主索引和二级索引的访问方式。
DNS协议相关
DNS(Domain Name System)协议为互联网提供域名和IP地址对应的相互映射查询服务。而DNS服务器作为存储域名IP对应信息的分布式数据库为整个互联网提供基础服务。
DNS请求报文和响应报文
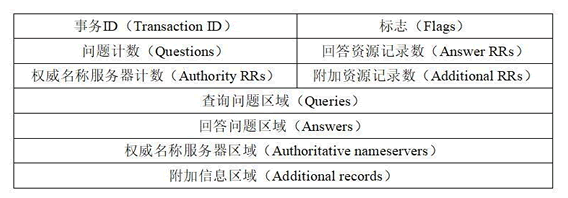
dns = DNS(id=1, qr=0, opcode=0, tc=0, rd=1, qdcount=1, ancount=0, nscount=0, arcount=1)
dns.qd = DNSQR(qname=qdname, qtype=255, qclass=1)
dns.ar = DNSRROPT(type='OPT', rclass=4096)
- 1
- 2
- 3
对于标志位:
根据我构造的dns数据包可以看出
QR:查询请求/响应的标志信息。查询请求时,值为 0;响应时,值为 1。
opcode:操作码。4个比特位用来设置查询的种类,应答的时候会带相同值,
0 标准查询 (QUERY)
1 反向查询 (IQUERY)
2 服务器状态查询 (STATUS)
3 无
4 为通知 (Notify)
5 为更新 (Update)
6-15 保留值,暂时未使用
AA(Authoritative):授权应答,该字段在响应报文中有效(因此在我构造的请求报文中没有AA字段)。值为 1 时,表示名称服务器是权威服务器;值为 0 时,表示不是权威服务器。
TC表示是否被截断,dns最多只能回应512字节的包(我这里设置是不截断)。
RD表示是否期望递归,
0 为不期望进行递归查询
1 为期望进行递归查询 (从域名服务器进行递归查询)
RA(Recursion Available):可用递归。该字段只出现在响应报文中。当值为 1 时,表示服务器支持递归查询。
rcode:应答码(Response code)。
这里太多了,,,记不住,我就记三个,0是没错误,1是报文格式错误,2是服务器失败。
0 正常,没有差错。 1 报文格式错误(Format error) - NS服务器不能解析请求的报文。 2 服务器失败(Server failure) - 因为服务器的原因导致没办法处理这个请求。 3 名字差错(Name Error) - 只有对授权域名解析服务器有意义,指出解析的域名不存在(请求中的地址并不存在)。 4 没有实现(Not Implemented) - NS域名服务器不支持查询类型。 5 拒绝(Refused) - 服务器由于设置的策略拒绝给出应答。比如,服务器不希望对某些请求者给出应答,或者服务器不希望进行某些操作(比如区域传送zone transfer)。 6 为域名出现了但是他不该出现 7 为集合 RR 存在但是他不该存在 8 为集合 RR 不存在但是他应该存在 9 为服务器并不是这个区域的权威服务器 10 为该名称并不包含在区域中 11-15 保留值,暂时未使用。 16 为错误的 OPT 版本或者 TSIG 签名无效 17 为无法识别的密钥 18 为签名不在时间范围内 19 为错误的 TKEY 模式 20 为重复的密钥名称 21 为该算法不支持 22 为错误的截断 23 - 3840 保留 3841 - 4095 私人使用 4096 - 65534 保留 65535 RFC 6195

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
最后多余的几个字段是

我在构造数据包的时候没有每个字段都填充,因为有的东西会默认填充,因此会看着少一些东西。
对于dns查询包,回答记录数,权威数和附加数都是0;
对于查询正文
Queries:
DNSQR(qname=qdname, qtype=255, qclass=1)
- 1
这部分只有三个内容,分别是查询名、查询类型和查询类
其中qname一般是域名,qtype是多个值,0表示查询对应的IPV4地址,255表示查询所有信息,15是邮件记录,28是IPV6地址,12表示是IP对应的域名反向查询。
此外由于DNS回应最大只有512字节,超过的就用TCP传输,于是就出现了EDNS,通过修改附加记录数为1,再增加附加内容。使得dns数据包增加了OPT RR字段,成为EDNS包。
dns.ar = DNSRROPT(type='OPT', rclass=4096)
- 1
EDNS包含如下:
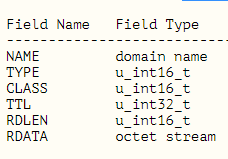
TYPE固定是OPT,CLASS是回应数据包的最大字节数,TTL包含三个字段
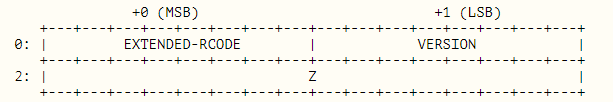
(因为电脑配置渣渣,打开一次太慢,就不抓包截图了)
说说Object类,作用,有什么方法,都是用来干什么的
Object类是类层次结构的根类。是对象工具类,它里面的的方法都是用来操作对象的。每个类都使用 Object 作为超类。每个类都继承Object类的方法。
作用:传递任何数据类型的类供使用;
方法:
1.1 getClass();
该方法是final的,返回此 Object 的运行时类。
1.2 hashCode();
返回该对象的哈希码值。默认情况下,该方法会根据对象的地址来计算。
1.3 equals();
比较两个对象是否相等,默认比较的是对象的引用是否相同。实际上都会重写该方法去比较属性等。
1.4 clone();
方法是protect类型,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
深浅克隆的区别就是对于克隆对象中的非静态引用类型的处理: 浅克隆不会新增引用对象, 而深克隆则会连引用对象都会克隆一份;


1.5 toString();
返回该对象的字符串表示,该字符串内容就是对象类型+@+内存地址值,该方法一般都会被重写。
容器的种类,分别都继承了哪些接口


其中比较特殊的三个

还有上边说的TreeMap。
队列详解:
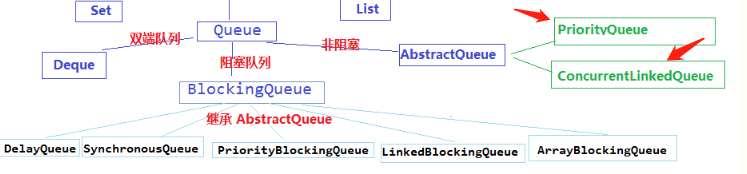
我用过的只有两种非阻塞队列,priorityqueue和linkedlist。
五个队列所提供的各有不同:
* ArrayBlockingQueue :一个由数组支持的有界队列。
* LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
* PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
* DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
* SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。
- 1
- 2
- 3
- 4
- 5
- 6
- 依赖pom.xml
com.alibaba [详细] 赞
踩

