
热门标签
热门文章
- 1传统A*算法与改进A*算法性能对比 改进A*算法融合DWA算法规避未知障碍物仿真_a*算法和dwa算法融合算法
- 2谈谈我的年度最佳面试官——帆软二面面试官
- 3npm install 连接不上github解决办法_npm install 登录github
- 4Hive最常用的函数大全_hive常用函数大全
- 5基于OSAL 实现UART、LED、ADC等基础示例 4
- 6【Android】Android Studio新创项目_最新版本android studio怎么创建java项目
- 7自然语言处理中所有任务的概括_自然语言处理分类任务
- 8触发器和锁存器的概念及FPGA中的使用
- 9Google SGE 正在添加人工智能图像生成器,现已推出:从搜索中的生成式 AI 中获取灵感的新方法
- 10Pycharm切换python环境版本_pycharm更换python
当前位置: article > 正文
神经网络与深度学习课程作业-4-循环神经网络与NLP_关于循环神经网络习题
作者:花生_TL007 | 2024-05-12 05:42:43
赞
踩
关于循环神经网络习题
此贴仅做课程作业使用!!!按自己的理解对上课内容进行总结
1 一些预备
1.1 序列模型
分类问题与预测问题的区别
图像分类问题:当前输入->当前输出
时间序列预测问题:当前+过去输入->当前输出
在预测的过程中保留一些对过去的观察总结,并且同时更新预测
与总结
,构成序列模型。
![]()
![]()
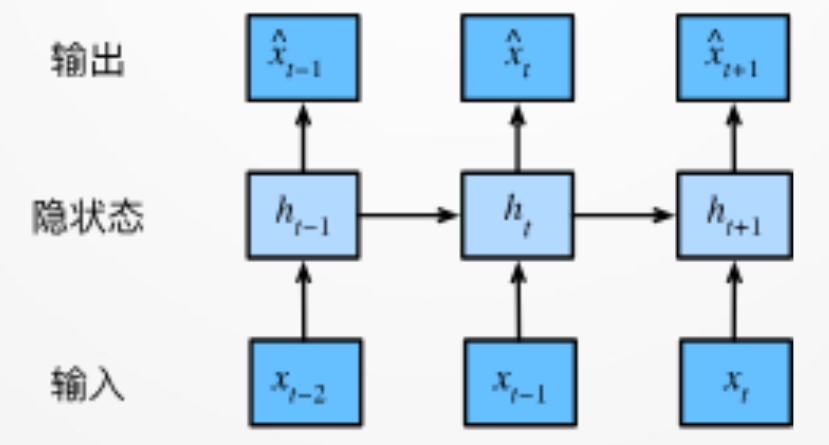
1.2 数据预处理
(1)特征编码
特征编码是将原始数据转换成机器学习算法可以处理的特征表示形式的过程。在特征编码中,原始数据的各种属性或特征被映射到数值化的形式,以便机器学习算法能够对其进行有效的处理和分析。常见的编码方式有:
独热编码:将分类变量转换为二进制向量的形式,其中每个可能的类别对应一个二进制位,只有属于某个类别的位被设置为1,其余位被设置为0。
标签编码:将分类变量转换为从0到N-1的整数形式,其中N是类别的数量。这种编码适用于某些机器学习算法,如决策树和随机森林。
(2)文本处理
文本处理是对文本数据进行预处理、分析、理解和转换的过程。它是自然语言处理(NLP)的一个重要组成部分,涉及到从原始文本中提取信息、进行文本挖掘、文本分类、文本生成等各种任务。常见的处理方式有:
按字母处理:

按单词处理:

1.3 文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将解析文本的常见预处理步骤。 这些步骤通常包括:
- 将文本作为字符串加载到内存中。
- 将字符串切分为词元(如单词和字符)。
- 建立一个字典,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
1.4 词嵌入
词嵌入是一种词的类型表示,具有相似意义的词具有相似的表示,是将词汇映射到实数向量的方法总称。将词映射为向量比较直接的想法是使用独热向量:
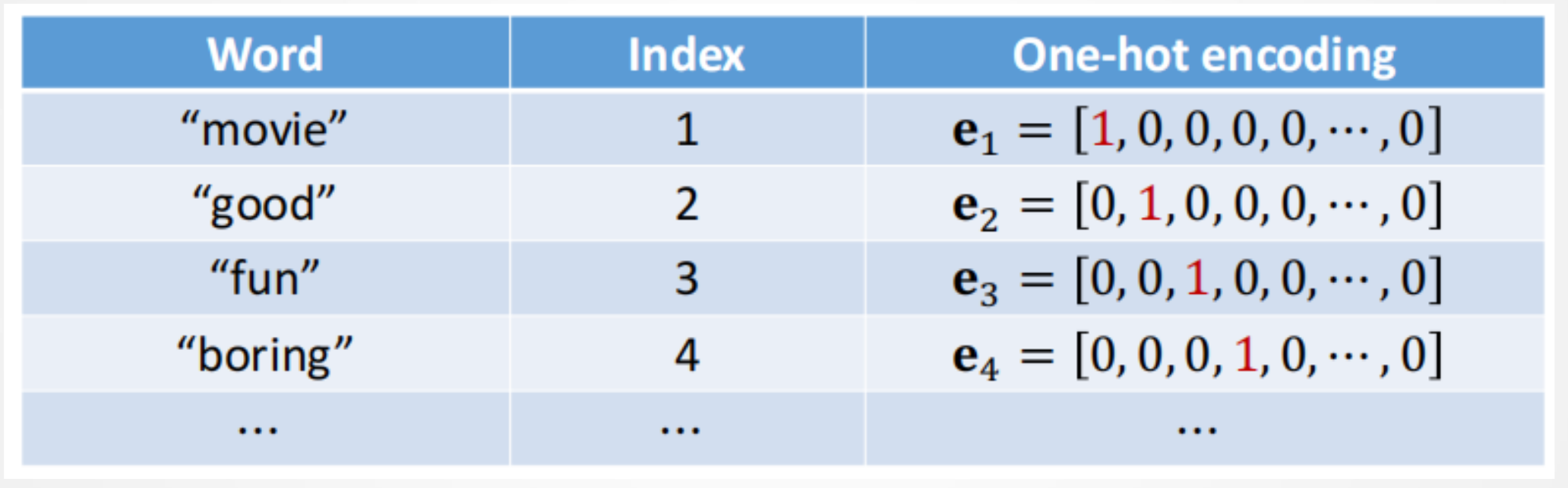
但是这样的编码维数过高,因此可以将独热向量映射为低维向量:
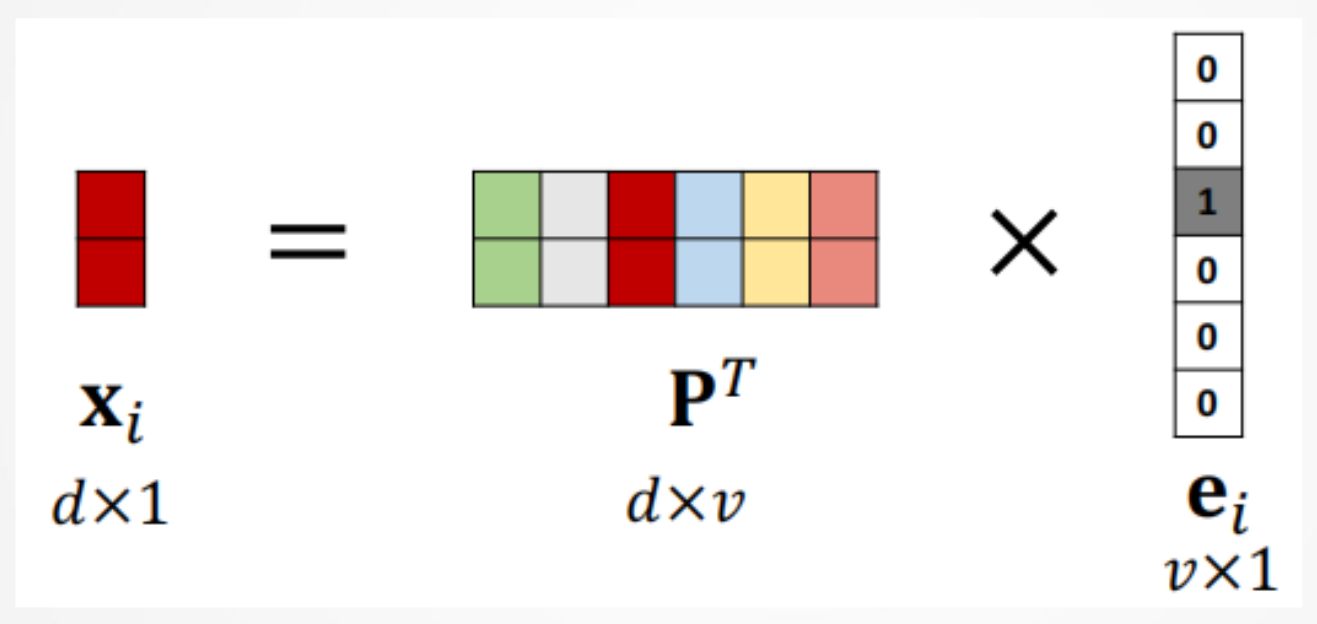
原始向量:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/557809
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

