
- 1Mamba和状态空间模型(SSM)的视觉指南:替代 Transformers 的语言建模方法_mamba能很好处理全局信息吗
- 2AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践_transformers pipeline 的task种类
- 3Eureka 服务端搭建入门与集群搭建_eureka集群部署
- 4Spring Boot启动流程详解_springboot启动流程
- 5将access数据导入到sql server中_vb access导入到sql server数据库
- 6Eclipse配置Android开发环境及项目运行_android eclipse
- 7transformer的pytorch实现(一)_transformer pytorch
- 8程序员必备技能之Git安装与配置_软件配置管理工具git
- 9Mongodb简介_mongodb license
- 10微信小程序-在线音乐播放器及源码_微信小程序音乐播放器源码
大厂面试官:Redis中缓存数据更新策略有哪些?_redis 读写 更新 ttl
赞
踩
缓存是一把双刃剑,在带来性能提升的同时,也会带来一些问题。首先就是缓存一致性的问题,因为我们把数据同时保存在缓存和数据库当中,当我们修改了数据库之后,缓存是无法感知到数据变化的,这个时候缓存中保留的就是旧数据,那么用户来查询的时候查到的就是旧数据。这在很多业务场景下是不被允许的。所以今天咱们就一起讨论一下企业中常用的几种缓存更新策略。
一、内存淘汰(无需编码)
这个机制实际上是Redis用来解决内存不足的问题的,因为Redis是基于内存的,内存是比较珍贵的资源,在使用Redis的时候往往会设置一个内存上限,当Redis中的数据达到这个上限时,会触发Redis的内存淘汰策略。
使用这种方式的好处就是不用自己维护缓存数据,当Redis中缓存数据大小达到我们设置的最大值时,自动淘汰部分数据,下次查询的时候再次更新,这种策略的数据一致性是最差的,因为触发淘汰机制的时机是不可控的,而且就算触发了,也不能保证会淘汰掉要更新的缓存数据。所以用这种方式解决一致性问题完全就是看缘分了。但好处就是代码的维护成本为0,我们只需要修改一下配置文件即可。
二、超时剔除(无需编码)
给缓存数据加上TTL过期时间,到期后自动删除缓存。下次查询更新缓存。
手动给缓存数据加上过期时间,到期后自动删除缓存,下次查询时更新,这种方式也有很大的概率产生数据一致性问题,过期时间是固定的,如果一条缓存数据刚刚存入Redis,这个时候刚好更新了数据库,那么在这个缓存数据过期之前,数据库和缓存中的数据都是不一致的。这种方式比内存淘汰策略好那么一点点,数据一致性问题出现的最大时间就是我们设置的过期时间。如果业务对数据的一致性要求不是很高,那么我们可以设置一个在业务允许范围内的过期时间,用这种方式实现数据最终一致性。
三、主动更新(需要编码)
需要我们手动编写业务逻辑,在修改数据库的同时,更新缓存。主动更新策略有三种
1. Cache Aside Pattern:由缓存的调用者,在更新数据库的同时更新缓存。
2. Read/Write Through Pattern:缓存和数据库整合为一个服务,由服务来维护一致性。调用者调用服务,不用关心一致性问题。
3. Write Behind Caching Pattern:调用者只操作缓存,由其他线程异步的将缓存数据持久化到数据库,最终保持一致。
在企业中使用最多的主动更新策略是 Cache Aside Pattern。也就是我们自己编码来保证数据的一致性。
操作缓存和数据库时有三个问题需要我们考虑:
1. 删除缓存还是更新缓存
1)更新缓存:每次更新数据库都更新缓存,无效写操作比较多。
这种方式的缺点很明显,举个例子:假如我更新了100次数据库,然后又同时更新了100次缓存,但是在更新的时候并没有人来查这个数据,那么我更新这100次缓存好像也没啥用吧,相当于前99次都是无用功,只有最后一次才是有用的。这就是无效写操作过多的原因。
2)删除缓存:更新数据库时让缓存失效,查询时再更新缓存。(延迟加载)一般选择这个方案
这个方案比较合理一点,可以避免过多的无效写操作,缓存删除后,只要没人来查询这条数据,数据就不会被写入缓存,这样就可以避免大量无效的写操作。
2. 如何保证缓存与数据库的操作同时成功或失败
1)单体系统,将缓存与数据库操作放在一个事务中。
2)分布式系统,利用TCC等分布式事务方案。
3. 先操作缓存还是数据库
1. 先删除缓存,再操作数据库
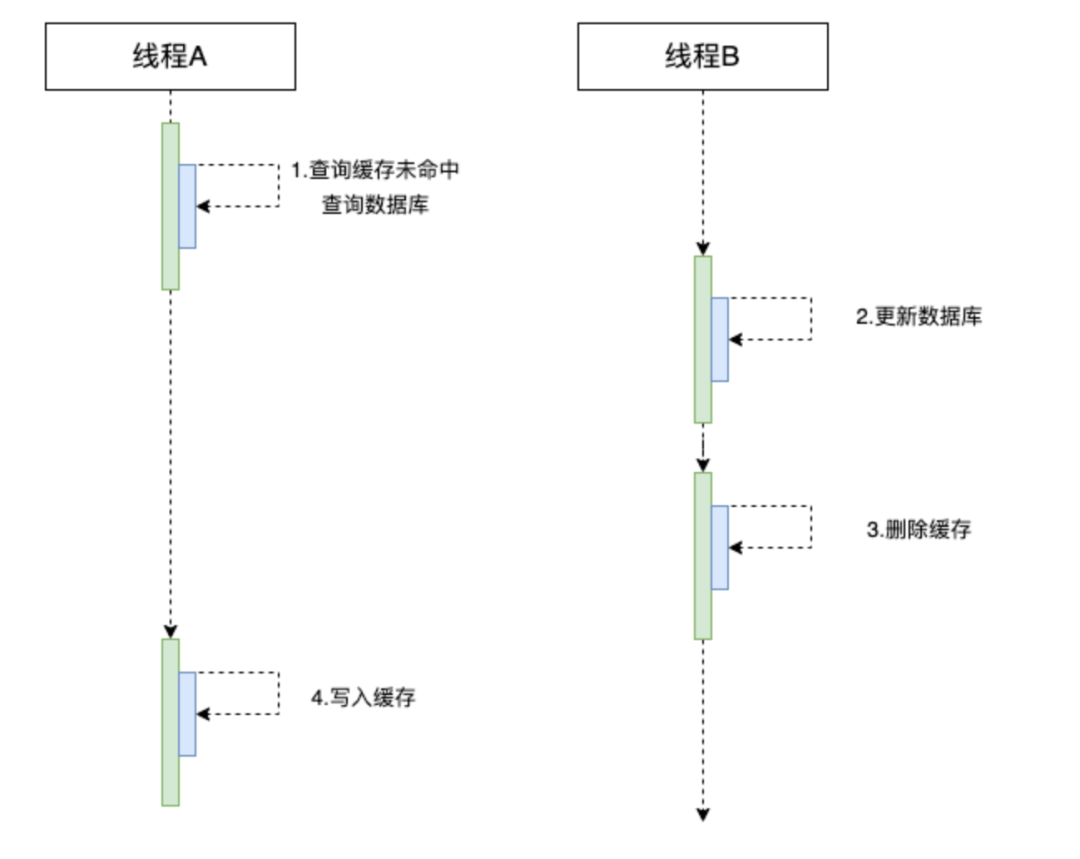
这种方式存在很明显的问题,假设有两个并发操作,线程A更新,线程B查询。线程A先删除缓存,然后还没来得及更新数据库,CPU资源被线程B抢走,线程B查询缓存发现没有命中(因为已经被线程A删除了),查询数据库,然后把结果写入到缓存中。这个时候线程A终于抢到CPU资源了,然后更新数据库,此时就会造成数据不一致问题。

2. 先操作数据库,再删除缓存(使用最多的方式)
这种处理方式使用的频率是最高的,因为出错的概率非常小,只有一种比较极端的情况才会出现数据一致性问题。
同样有两个并发请求,线程A查询、线程B更新,当线程A查询的时候,缓存刚好失效,然后就去查询数据库拿到数据,在准备写入缓存的时候,CPU资源被线程B抢走,线程B开始更新数据库,然后删除缓存(这一步其实等于无用,因为缓存已经过期)。此时线程A再次获取到CPU资源,然后写入缓存,此时写入的是更新前的旧数据,会产生数据一致性问题。
看起来这确实也是一个问题,但是我们仔细分析一下这种情况都需要满足哪些条件:
1. 并发读写操作
2. 读缓存时,缓存刚好失效
3. 写数据库操作要比写缓存快
写数据库是操作磁盘,写缓存是操作内存的,所以不太可能会出现写磁盘的速度快于写内存的。因此使用这种方式出现数据一致性的概率是很小的。
3.延时双删策略
延迟双删策略是分布式系统中数据库存储和缓存数据保持一致性的常用策略,但它不是强一致。其实不管哪种方案,都避免不了Redis存在脏数据的问题,只能减轻这个问题,要想彻底解决,得要用到同步锁和对应的业务逻辑层面解决。
前面两种方案的不足点我们进行了分析,第二种方式的使用频率比较高,但是也有一些小缺陷,虽然说发生的概率很低,但是这个概率到了线上会不会发生也不好说,所以就有了延时双删策略对第二种方式做补充。
所谓延时双删就是先进行缓存清除,再执行数据库操作,最后(延迟N秒)再执行缓存清除。延迟N秒的时间要大于一次写操作的时间,这个延时N秒就是了完善保证第二种策略中不足,可以保证线程A的写缓存和线程B的修改数据库、删除缓存都执行完毕,然后再删除缓存一次,就可以保证后面再来的查询请求可以查询到最新数据。
ps: 一般的延时时间设置为3S左右,具体情况要根据业务场景取最佳值。
总结
1. 内存淘汰:不用自己维护,利用Redis内存淘汰机制,自动删除部分缓存数据,这些被删除的数据在下一次被查询时更新。这种方式一致性最差。
2.超时剔除:给缓存数据加上过期时间 ,到期后自动删除,下次查询时更新,数据一致性问题大概率会出现。维护成本比较低。
3.主动更新:编写业务逻辑,在修改数据库的同时更新缓存,一致性比较好,维护成本比较高。一般采用先操作数据库再更新缓存的方式。
一般在数据一致性要求比较低的场景下可以使用内存淘汰机制,比如商城首页的分类信息,这些东西基本上是不会变化的。如果一致性要求比较高,我们可以采用主动更新+超时剔除兜底的方式来处理。

