为了方便采用了Cygwin模拟linux环境的方法
一、安装JDK以及下载hadoop
hadoop官网下载hadoop http://hadoop.apache.org/releases.html 。
二、安装Cygwin
1、http://www.cygwin.com/ 根据操作系统的需要下载32位或64的安装文件。
2、双击下载好的安装文件进入安装引导页,选择从网络安装
3、选择安装路径
4、选择internet连接方式
5、选择合适的安装源
6、选择需要安装的软件包
net下的openssh和openssl
Base下的sed
Editors下的vim
7、等待安装完成
8、配置环境变量
9、安装sshd服务
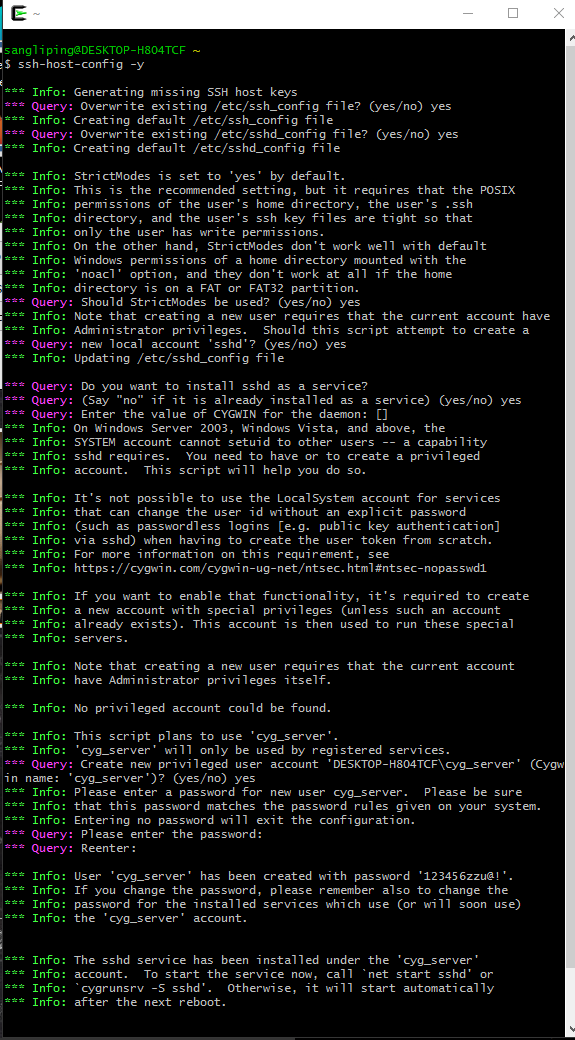
启动Cygwin执行ssh-host-config - y
出现下述文字表示安装成功
10、启动sshd服务
net start sshd

三、安装hadoop
1、下载hadoop并解压
http://hadoop.apache.org/releases.html
2、单机模式配置
单机模式不需要进行配置,这种方式下,Hadoop被认为是一个单独的Java进程,经常用来进行调试。
3、伪分布模式
伪分布模式可以看做是只有一个节点的集群,在这个集群中,这个节点既是Master也是Slave,既是NameNode也是DataNode,既是JobTracket也是TaskTranker.
伪分布式需要修改配置文件hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml
<!--core-site--> <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9999</value> </property> <property> <name>mapred.child.tmp</name> <value>/cygdrive/d/hadoop/hadoop-2.8.0/tmp</value> </property> </configuration>
<!--hdfs-site--> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration><!--mapred-site.xml--> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9998</value> </property> <property> <name>mapred.child.tmp</name> <value>/cygdrive/d/hadoop/hadoop-2.8.0/tmp</value> </property> </configuration>4、启动hadoop
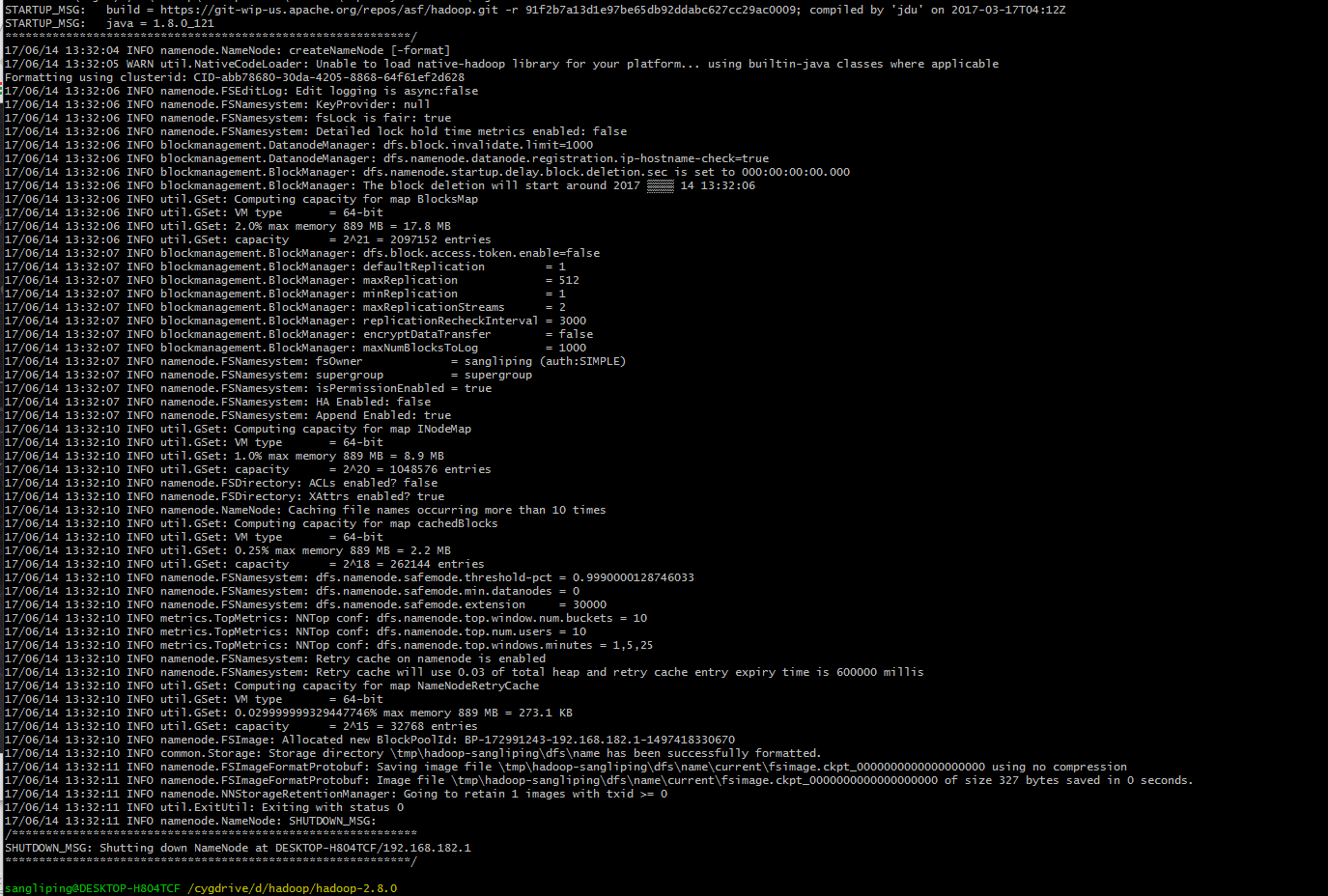
打开cygwin窗口,进入hadoop文件夹,启动hadoop之前需要先格式化Hadoop的文件系统HDFS,执行命令 bin/hadoop namenoce -format