- 1Kotlin——高级篇(五):集合之常用操作符汇总_kt list 操作符
- 2完全指南:在MacOS M1上安装Stable Diffusion WebUI,零基础也能上手。_stable diffusion webui macos
- 3java c json时间转换_JSONObject转换JSON--将Date转换为指定格式
- 4python 将数据输出为文件,然后保存在本地磁盘
- 5Android adb常用命令_adb reboot -p
- 6mysql函数str_to_date字符串转日期_mysql to date
- 72024 直冲「云」霄训练营火热报名中,免费学课助力拿下云认证!
- 8Oracle关于时间/日期的操作
- 9夜神模拟器adb连接电脑_使用adb devices命令查看模拟器是否连接成功
- 10git 常用操作与遇到的问题_git safecrlf true不好用
Wav2Lip:嘴型同步模型的技术深度解析
赞
踩
一、简介
在2020年,一支由来自印度海德拉巴大学和英国巴斯大学的学者组成的团队,在ACM MM2020会议上发表了一篇题为《A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild》的论文。这篇论文中,他们向世界介绍了一种名为Wav2Lip的AI模型。这个模型拥有令人惊叹的能力,只需要一段人物的视频片段和一段目标语音,它就能够将这两者完美地结合在一起。具体来说,音频信息被Wav2Lip模型转化为与视频中人物嘴型完全匹配的动画。这无疑为语音识别、虚拟现实、增强现实等领域带来了革命性的突破。在2020年,一支由来自印度海德拉巴大学和英国巴斯大学的学者组成的团队,在ACM MM2020会议上发表了一篇题为《A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild》的论文。这篇论文中,他们向世界介绍了一种名为Wav2Lip的AI模型。这个模型拥有令人惊叹的能力,只需要一段人物的视频片段和一段目标语音,它就能够将这两者完美地结合在一起。具体来说,音频信息被Wav2Lip模型转化为与视频中人物嘴型完全匹配的动画。这无疑为语音识别、虚拟现实、增强现实等领域带来了革命性的突破。
Wav2Lip,一个嘴型同步模型,是一个能够将语音波形转换为面部动画的深度学习模型。它在语音交互、虚拟现实、增强现实等领域具有广泛的应用前景。本文将详细介绍Wav2Lip模型的搭建原理、搭建流程(搭建流程;shuziren06)以及应用场景,并以代码的形式提供详细的搭建方案。
二、Wav2Lip模型搭建原理
Wav2Lip模型的搭建基于生成对抗网络(GAN)的原理。GAN由两个主要部分组成:生成器和判别器。生成器的任务是根据输入的音频波形生成逼真的面部动画,而判别器的目标是区分生成的动画与真实的面部动画。在训练过程中,生成器和判别器进行对抗性训练,以逐渐学习音频信号与面部动画之间的映射关系。
为了实现嘴型同步,Wav2Lip模型在GAN的基础上增加了条件约束,使得生成的面部动画与给定的语音信号在嘴型上保持一致。具体而言,模型将音频信号作为条件输入,与面部特征一起传递给生成器和判别器。在生成器中,音频信号经过一个编码器,将其转换为与面部特征具有相同维度的条件向量。然后,这个条件向量被用于指导生成器生成与输入音频对应的面部动画。判别器则同时接收生成的面部动画和真实的面部动画,并根据音频信号对它们进行区分。
三、Wav2Lip模型搭建流程
以下是使用代码实现Wav2Lip模型的搭建流程:
- 数据准备:首先需要准备一个大规模的标注数据集,其中包含音频波形和对应的面部动画。可以使用现有的数据集或自己制作的数据集。确保数据集中的音频波形和面部动画具有相同的长度和采样率。
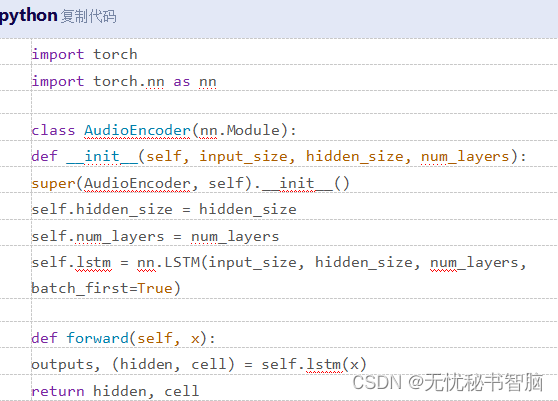
- 构建音频编码器:为了将音频信号转换为与面部特征具有相同维度的条件向量,需要构建一个音频编码器。可以使用深度学习框架(如TensorFlow或PyTorch)来实现这个编码器。以下是一个使用PyTorch实现音频编码器的示例代码:
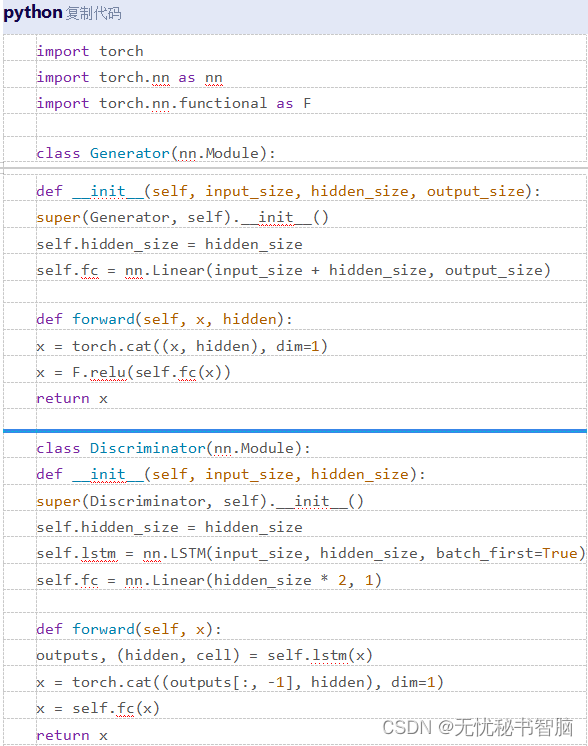
 构建生成器和判别器:生成器和判别器的具体架构可以根据实际需求进行调整。以下是一个使用PyTorch实现生成器和判别器的示例代码:
构建生成器和判别器:生成器和判别器的具体架构可以根据实际需求进行调整。以下是一个使用PyTorch实现生成器和判别器的示例代码: