
- 1C#中Winform使用OpenFileDialog选择文件打开并获取文件路径_通过openfiledialog选择文件路径
- 2react项目内存溢出,加大内存的方式之一 Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap_vscode的react项目内存溢出
- 3Redis实现分布式锁的原理:常见问题解析及解决方案、源码解析Redisson的使用_分布式事务redis解决方案
- 42024永久免费版CrossOver软件下载及使用方法详细的步骤_crossover安装包
- 5guitar pro 8许可证忘记了怎么办 guitar pro8谱数字可以改吗
- 6基于微信学生新生报到小程序系统设计与实现
- 7ROS Motion Planning运动规划库安装方法及进阶使用方法详细介绍
- 8pom可视化idea_GitHub - haizlin-idea/rsbi-pom: 睿思BI-数据仪表盘,开源商业智能,数据可视化系统...
- 9在CDH集群安装Flink
- 10单片机学习笔记---独立按键控制LED亮灭_单片机按键控制led灯亮灭
RT-DETR论文阅读笔记(包括YOLO版本训练和官方版本训练)_rtdert
赞
踩

论文地址:RT-DETR论文地址
代码地址:RT-DETR官方下载地址

大家如果想看更详细训练、推理、部署、验证等教程可以看我的另一篇博客里面有更详细的介绍
目录
一、介绍
目标检测是一项基础的视觉任务,涉及识别和定位图像中的对象。现代目标检测器有两种典型架构:基于CNN和基于Transformer。在过去几年中,基于CNN的目标检测器进行了广泛的研究。这些检测器的架构已从最初的两阶段发展到单阶段,并出现了基于锚点和无锚点两种检测范式。这些研究在检测速度和精度方面都取得了显著进展。自从提出以来,基于Transformer的目标检测器(DETRs)因其消除了各种手工制作的组件(例如非最大抑制NMS)而受到学术界的广泛关注。这种架构极大地简化了目标检测流程,并实现了端到端的目标检测。
实时目标检测是一个重要的研究领域,具有广泛的应用范围,例如对象跟踪、视频监控、自动驾驶等。现有的实时检测器通常采用基于CNN的架构,在检测速度和精度之间取得了合理的折中。然而,这些实时检测器通常需要NMS进行后处理,这通常难以优化且不够稳健,导致检测器的推理速度延迟。最近,由于研究人员在加速训练收敛和减少优化难度方面的努力,基于Transformer的检测器取得了显著的性能。然而,DETRs的高计算成本问题尚未得到有效解决,这限制了DETRs的实际应用,并导致无法充分利用其优势。这意味着尽管目标检测流程简化了,但由于模型本身的高计算成本,难以实现实时目标检测。上述问题自然地激发了我们的思考,我们是否可以将DETR扩展到实时场景中,充分利用端到端检测器的优势,避免NMS在实时检测器上造成的延迟。
为了实现上述目标,我们重新思考了DETR,并对其关键组件进行了详细的分析和实验,以减少不必要的计算冗余。具体来说,我们发现尽管引入多尺度特征有助于加速训练收敛和提高性能,但这也导致了输入编码器的序列长度显著增加。结果,由于高计算成本,变换器编码器成为模型的计算瓶颈。为了实现实时目标检测,我们设计了一个高效的混合编码器来替代原始的变换器编码器。通过解耦多尺度特征的内部尺度交互和跨尺度融合,编码器可以有效地处理不同尺度的特征。此外,以前的工作表明,解码器的对象查询初始化方案对检测性能至关重要。为了进一步提高性能,我们提出了IoU感知查询选择,在训练期间通过提供IoU约束来向解码器提供更高质量的初始对象查询。此外,我们提出的检测器支持使用不同的解码器层灵活调整推理速度,而不需要重新训练,这得益于DETR架构中解码器的设计,并促进了实时检测

二、相关工作
这一章节回顾了实时目标检测器和端到端目标检测器的相关研究以及多尺度特征在目标检测中的应用。
下面是根据DETR的发展历程总结了一个表格可能不全但是应该涵盖了绝大多数的版本->

2.1、实时目标检测器的发展
这一小节讨论了实时目标检测器的发展,尤其是以YOLO系列为代表的模型。这些模型可以分为基于锚点和无锚点两大类。尽管这些检测器的性能表明锚点不再是限制YOLO发展的主要因素,但是它们会产生大量冗余的边界框,需要在后处理阶段使用非最大抑制(NMS)来过滤。不幸的是,这导致了性能瓶颈,NMS的超参数对检测器的准确性和速度有显著影响,这与实时目标检测器的设计哲学不符。
2.2、端到端目标检测器的流程
Carion等人首次提出了基于Transformer的端到端目标检测器DETR,它因其独特的特性而引起了重大关注。特别是,DETR消除了传统检测流程中手工设计的锚点和NMS组件,转而采用二分匹配直接预测一对一的对象集合。这种策略简化了检测流程并缓解了NMS造成的性能瓶颈。尽管DETR具有明显的优势,但它也存在两个主要问题:训练收敛慢和难以优化的查询。为了解决这些问题,提出了许多DETR变体。例如,Deformable-DETR通过增强注意力机制的效率和多尺度特征加速训练收敛,Conditional DETR和Anchor DETR减少了查询的优化难度。尽管我们持续改进DETR的组件,但我们的目标不仅仅是进一步提高性能,而且是创建一个实时的端到端目标检测器。
2.3、强调多尺度特征在改进目标检测性能
这一小节强调多尺度特征在改进目标检测性能,特别是对小对象的重要性。FPN提出了一个特征金字塔网络,融合了来自相邻尺度的特征。后续的研究扩展并增强了这一结构,它们在实时目标检测器中被广泛采用。Zhu等人首次将多尺度特征引入到DETR中,提高了性能和收敛速度,但这也导致了DETR的计算成本显著增加。尽管变形注意力机制在一定程度上缓解了计算成本,多尺度特征的引入仍然导致了高计算负担。为了解决这个问题,一些研究试图设计计算效率高的DETR。Efficient DETR通过用密集先验初始化对象查询来减少编码器和解码器层的数量。Sparse DETR选择性地更新预计会被解码器引用的编码器令牌,从而减少了计算开销。Lite DETR通过交错减少低级特征的更新频率来增强编码器的效率。尽管这些研究降低了DETR的计算成本,但这些工作的目标并不是将DETR推广为实时检测器。
三、端到端检测器的速度
这一章文章分析了目标检测中NMS(非最大抑制)后处理步骤的影响,并建立了一个端到端速度测试基准来公平比较不同实时检测器的推理速度。
3.1、分析NMS
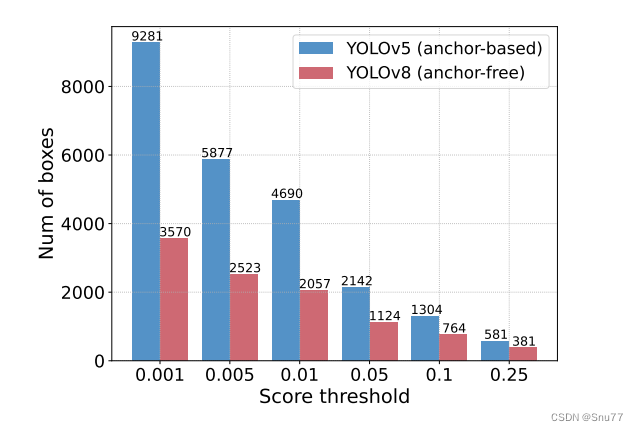
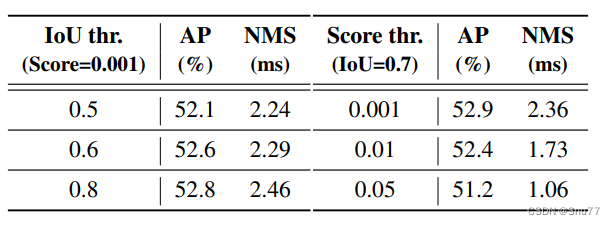
NMS它是在目标检测中广泛采用的后处理算法,用于消除检测器输出的重叠预测框。NMS需要两个超参数:分数阈值和IoU阈值。具体来说,分数低于分数阈值的预测框会被直接过滤掉,当两个预测框的IoU超过IoU阈值时,分数较低的框会被丢弃。这个过程将迭代执行,直到每个类别的所有框都被处理。因此,NMS的执行时间主要取决于输入预测框的数量和两个超参数。
为了验证这一观点,作者使用YOLOv5(基于锚点)和YOLOv8(无锚点)进行实验。他们首先计算不同分数阈值下保留的预测框数量,并绘制成直方图,直观地反映了NMS对其超参数的敏感性。


3.2、建立一个端到端速度测试基准
建立了一个端到端速度测试基准,以便公平比较各种实时检测器的推理速度。考虑到NMS的执行时间可能受输入图像的影响,选择一个基准数据集并计算多个图像的平均执行时间是必要的。这个基准使用COCO val2017数据集作为默认数据集,并为需要后处理的实时检测器附加TensorRT的NMS后处理插件。具体来说,根据基准数据集上对应精度的超参数,测试检测器的平均推理时间,并排除IO和内存复制操作。
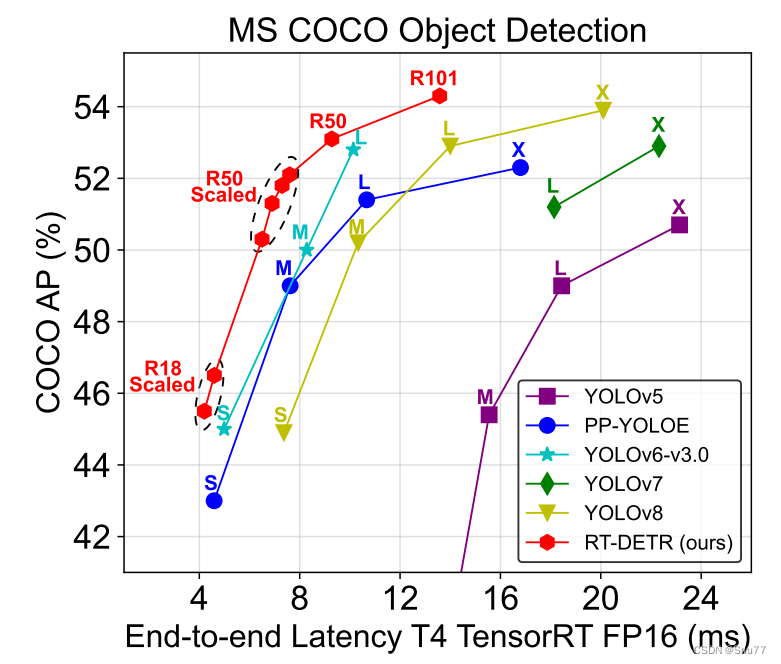
利用这个基准测试了基于锚点的检测器YOLOv5和YOLOv7,以及无锚点的检测器PP-YOLOE、YOLOv6和YOLOv8在T4 GPU上的端到端速度。根据结果,作者得出结论,对于需要NMS后处理的实时检测器来说,无锚点检测器因为后处理时间明显少于基于锚点的检测器而表现得更好,这一点在以前的工作中被忽略了。这种现象的原因是,基于锚点的检测器产生的预测框比无锚点的检测器多(在测试的检测器中多三倍)。
四、实时的DETR模型
4.1、模型概览
我们提出的RT-DETR包括一个主干网络(backbone)、一个混合编码器(hybrid encoder)和一个带有辅助预测头的变换器解码器(transformer decoder)。模型架构的概览如下面的图片3所示。

具体来说,我们利用主干网络的最后三个阶段的输出特征 {S3, S4, S5} 作为编码器的输入。混合编码器通过内尺度交互(intra-scale interaction)和跨尺度融合(cross-scale fusion)将多尺度特征转换成一系列图像特征(详见第4.2节)。随后,采用IoU感知查询选择(IoU-aware query selection)从编码器输出序列中选择一定数量的图像特征,作为解码器的初始对象查询(详见第4.3节)。最后,带有辅助预测头的解码器迭代优化对象查询,生成边框和置信度分数。

4.2、 高效混合编码器
计算瓶颈分析。为了加速训练收敛和提高性能,Zhu等人提出引入多尺度特征,并提出变形注意力机制来减少计算量。然而,尽管注意力机制的改进减少了计算开销,但输入序列长度的显著增加仍使编码器成为计算瓶颈,阻碍了DETR的实时实现。如[21]所报告,编码器占了49%的GFLOPs,但在Deformable-DETR中仅贡献了11%的AP。为了克服这一障碍,我们分析了多尺度变换器编码器中存在的计算冗余,并设计了一系列变体来证明内尺度和跨尺度特征的同时交互在计算上是低效的。
高级特征是从包含图像中对象丰富语义信息的低级特征中提取出来的。直觉上,在连接的多尺度特征上执行特征交互是多余的。为了验证这一观点,我们重新思考了编码器结构,并设计了一系列具有不同编码器的变体,如下图所示。

这一系列变体通过将多尺度特征交互分解为内尺度交互和跨尺度融合的两步操作,逐渐提高了模型精度,同时显著降低了计算成本(详细指标参见下表3)。
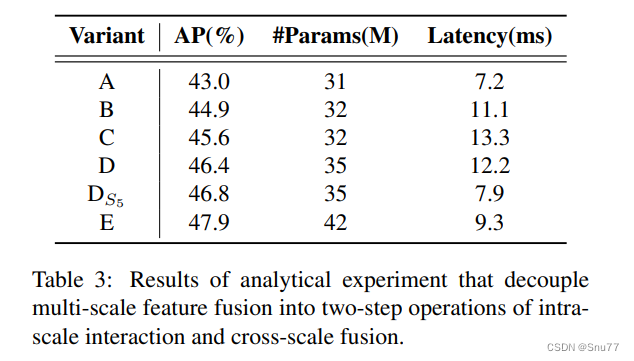
我们首先移除DINO-R50中的多尺度变换器编码器作为基线A。接下来,插入不同形式的编码器,基于基线A生成一系列变体,具体如下:
- A → B:变体B插入了一个单尺度变换器编码器,它使用一个变换器块层。每个尺度的特征共享编码器进行内尺度特征交互,然后连接输出的多尺度特征。
- B → C:变体C基于B引入了跨尺度特征融合,并将连接的多尺度特征送入编码器进行特征交互。
- C → D:变体D将内尺度交互和跨尺度融合的多尺度特征解耦。首先使用单尺度变换器编码器进行内尺度交互,然后使用类似PANet的结构进行跨尺度融合。
- D → E:变体E在D的基础上进一步优化
了内尺度交互和跨尺度融合的多尺度特征,采用了我们设计的高效混合编码器(详见下文)。
混合设计。基于上述分析,我们重新思考了编码器的结构,并提出了一种新型的高效混合编码器。如图3所示,所提出的编码器由两个模块组成,即基于注意力的内尺度特征交互模块(AIFI)和基于CNN的跨尺度特征融合模块(CCFM)。AIFI基于变体D进一步减少了计算冗余,它只在S5上执行内尺度交互。我们认为,将自注意力操作应用于具有更丰富语义概念的高级特征,可以捕捉图像中概念实体之间的联系,这有助于后续模块检测和识别图像中的对象。同时,由于缺乏语义概念,低级特征的内尺度交互是不必要的,存在与高级特征交互重复和混淆的风险。为了验证这一观点,我们仅在变体D中对S5执行内尺度交互,实验结果报告在表3中,见DS5行。与原始变体D相比,DS5显著降低了延迟(快35%),但提高了准确度(AP高0.4%)。这一结论对于实时检测器的设计至关重要。CCFM也是基于变体D优化的,将由卷积层组成的几个融合块插入到融合路径中。融合块的作用是将相邻特征融合成新的特征,其结构如图4所示。融合块包含N个RepBlocks,两个路径的输出通过逐元素加法融合。我们可以将此过程表示如下:
式中,Attn代表多头自注意力,Reshape代表将特征的形状恢复为与S5相同,这是Flatten的逆操作。

4.3、IoU感知查询选择
DETR中的对象查询是一组可学习的嵌入,由解码器优化并由预测头映射到分类分数和边界框。然而,这些对象查询难以解释和优化,因为它们没有明确的物理含义。后续工作改进了对象查询的初始化,并将其扩展到内容查询和位置查询(锚点)。其中,提出了查询选择方案,它们共同的特点是利用分类分数从编码器中选择排名靠前的K个特征来初始化对象查询(或仅位置查询)。然而,由于分类分数和位置置信度的分布不一致,一些预测框虽有高分类分数,但与真实框(GT)不接近,这导致选择了分类分数高但IoU分数低的框,而丢弃了分类分数低但IoU分数高的框。这降低了检测器的性能。为了解决这个问题,我们提出了IoU感知查询选择,通过在训练期间对模型施加约束,使其对IoU分数高的特征产生高分类分数,对IoU分数低的特征产生低分类分数。因此,模型根据分类分数选择的排名靠前的K个编码
器特征的预测框,既有高分类分数又有高IoU分数。我们重新制定了检测器的优化目标如下:
其中,和
分别代表预测和真实值,
和
,
和
分别代表类别和边界框。我们将IoU分数引入分类分支的目标函数中(类似于VFL),以实现对正样本分类和定位的一致性约束。
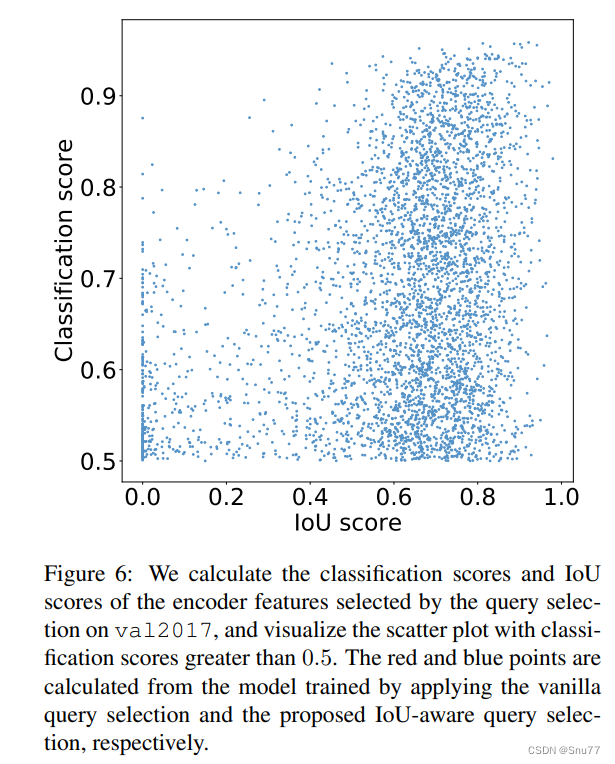
效果分析。为了分析所提出的IoU感知查询选择的有效性,我们可视化了在val2017数据集上,由查询选择选出的编码器特征的分类分数和IoU分数,如图6所示。具体来说,我们首先根据分类分数选择排名靠前的K(实验中K=300)个编码器特征,然后可视化分类分数大于0.5的散点图。红点和蓝点分别计算自应用传统查询选择和IoU感知查询选择的模型。点越接近图的右上方,相应特征的质量越高,即分类标签和边界框更有可能描述图像中的真实对象。根据可视化结果,我们发现最显著的特点是大量蓝点集中在图的右上方,而红点集中在右下方。这表明,经IoU感知查询选择训练的模型可以产生更多高质量的编码器特征。
此外,我们对两种类型点的分布特征进行了定量分析。图中蓝点比红点多138%,即更多的红点的分类分数小于或等于0.5,可以被认为是低质量特征。然后,我们分析了分类分数大于0.5的特征的IoU分数,发现有120%的蓝点比红点的IoU分数大于0.5。定量结果进一步证明,IoU感知查询选择可以为对象查询提供更多具有准确分类(高分类分数)和精确位置(高IoU分数)的编码器特征,从而提高检测器的准确度。详细的定量结果展示在第5.4节。
4.4、 可扩展的RT-DETR
为了提供可扩展的RT-DETR版本,我们用HGNetv2替换了ResNet主干网络。我们使用深度乘数和宽度乘数一起缩放主干网络和混合编码器。因此,我们得到了两个版本的RT-DETR,具有不同的参数数量和FPS。对于我们的混合编码器,我们通过调整CCFM中RepBlocks的数量和编码器的嵌入维度来控制深度乘数和宽度乘数。值得注意的是,我们提出的不同规模的RT-DETR保持了同质的解码器,这便于使用高精度大型DETR模型进行轻量化检测器的蒸馏。这将是一个可探索的未来方向。

五、实验
5.1、 实验设置
数据集。我们在Microsoft COCO数据集上进行实验。在COCO train2017上训练,在COCO val2017上验证。我们使用标准的COCO AP评价指标,并且输入的图像是单一尺寸的。
实现细节。我们使用在ImageNet上预训练的ResNet和HGNetv2系列作为主干网络,并采用PaddleClas提供的SSLD。AIFI由1层变换器层组成,CCMF中的融合块默认由3个RepBlocks构成。在IoU感知查询选择中,我们选择前300个编码器特征来初始化解码器的对象查询。解码器的训练策略和超参数几乎遵循DINO。我们使用AdamW优化器训练检测器,基础学习率为0.0001,权重衰减为0.0001,全局梯度裁剪范围为0.1,线性预热步骤为2000。主干网络的学习率设置遵循文献[5]。我们还使用指数移动平均(EMA)策略,EMA衰减率为0.9999。1×配置意味着总共训练12个周期,如果没有特别说明,所有消融实验都使用1×配置。报告的最终结果使用6×配置。数据增强包括随机的{色彩扭曲、扩展、裁剪、翻转、调整大小}操作。
5.2、与SOTA的比较
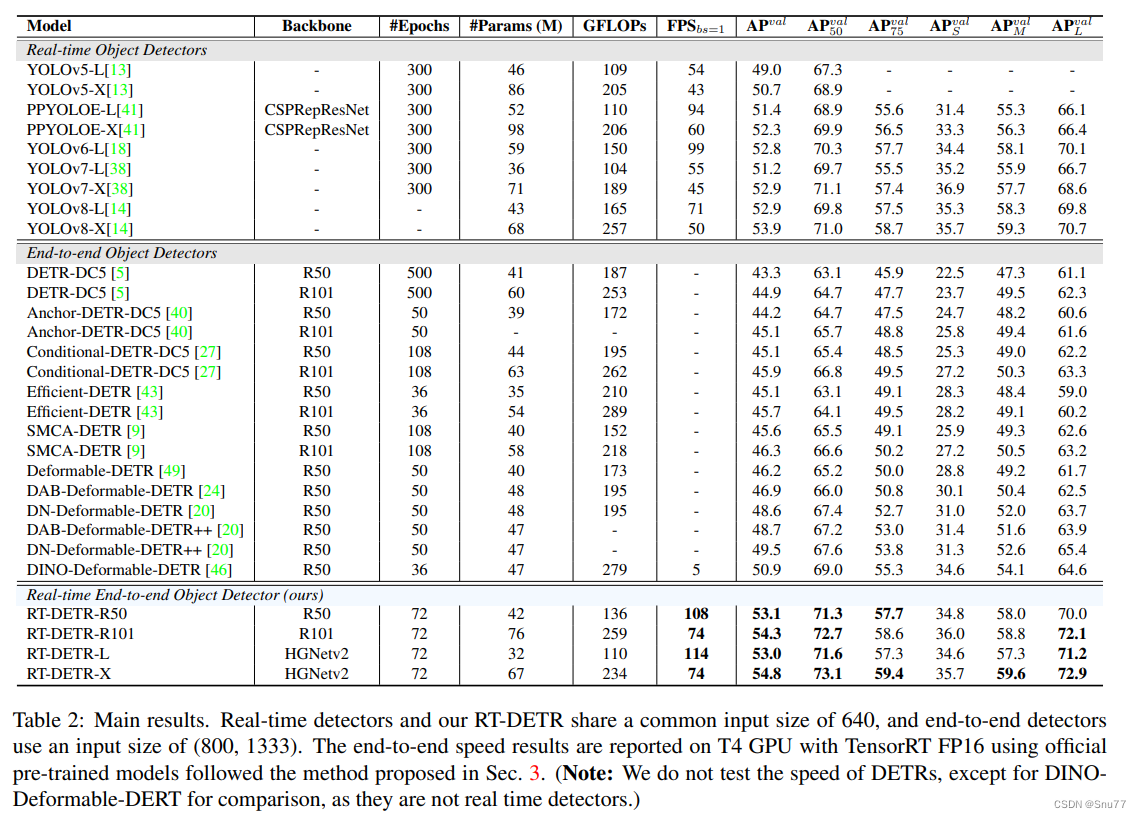
表2比较了我们提出的RT-DETR与其他实时和端到端目标检测器。我们提出的RT-DETR-L在COCO val2017数据集上达到了53.0%的AP和114FPS,而RT-DETR-X达到了54.8%的AP和74FPS,在速度和准确性上均优于同等规模的当前最先进的YOLO检测器。此外,我们提出的RT-DETR-R50达到了53.1%的AP和108FPS,而RT-DETR-R101达到了54.3%的AP和74FPS,在速度和准确性上均优于具有相同主干网络的最先进的端到端检测器。
与实时检测器相比。为了公平比较,我们将缩放后的RT-DETR与当前的实时检测器在端到端设置中进行了比较(速度测试方法参见3.2节)。我们在表2中将缩放后的RT-DETR与YOLOv5、PP-YOLOE、YOLOv6、YOLOv7和YOLOv8进行了比较。与YOLOv5-L / PP-YOLOE-L / YOLOv7-L相比,RT-DETR-L在AP上显著提高了4.0% / 1.6% / 1.8%,FPS提高了111.1% / 21.3% / 107.3%,参数数量减少了30.4% / 38.5% / 11.1%。与YOLOv5-X / PP-YOLOE-X / YOLOv7-X相比,RT-DETR-X在AP上提高了4.1% / 2.5% / 1.9%,FPS提高了72.1% / 23.3% / 64.4%,参数数量减少了22.1% / 31.6% / 5.6%。与YOLOv6-L / YOLOv8-L相比,RT-DETR-L在AP上提高了0.2% / 0.1%,在FPS上提高了15.2% / 60.6%,参数数量减少了45.8% / 25.6%。与YOLOv8-X相比,RT-DETR-X在AP上提高了0.9%,在FPS上提高了48.0%,在参数数量上减少了1.5%。
与端到端检测器相比。为了公平比较,我们只与使用相同主干网络的基于变换器的端到端检测器进行比较。考虑到当前的端到端检测器不是实时的,我们没有在T4 GPU上测试它们的速度,除了用于比较的DINO-Deformable-DERT。我们根据val2017上相应精度的设置测试了检测器的速度,即DINO-Deformable-DETR是用TensorRT FP16测试的,输入尺寸为(800, 1333)。表2显示,RT-DETR在性能上优于具有相同主干网络的最先进的端到端检测器。与DINO-Deformable-DETR-R50相比,RT-DETR-R50在AP上显著提高了2.2%(53.1%对比50.9%),在速度上提高了21倍(108FPS对比5FPS),并且在参数数量上减少了10.6%。与SMCA-DETR-R101相比,RT-DETR-R101在AP上显著提高了8.0%。
5.3、关于混合编码器的消融研究
为了验证我们对编码器分析的正确性,我们评估了在4.2节设计的一系列变体的指标,包括AP、参数数量和延迟。实验结果显示在表3中。变体B在AP上提高了1.9%,延迟增加了54%。这证明了内尺度特征交互的重要性,但传统的变换器编码器在计算上是昂贵的。变体C在B的基础上在AP上提高了0.7%,延迟增加了20%。这表明跨尺度特征融合也是必要的。变体D在C的基础上在AP上提高了0.8%,但延迟减少了8%。这表明解耦内尺度交互和跨尺度融合可以在提高准确性的同时减少计算量。与变体D相比,DS5在延迟上减少了35%,但在AP上提高了0.4%。这表明低级特征的内尺度交互不是必需的。最后,装备了我们提出的混合编码器的变体E在D的基础上在AP上提高了1.5%。尽管参数数量增加了20%,但延迟减少了24%,使编码器更高效。
5.4、 关于IoU感知查询选择的消融研究
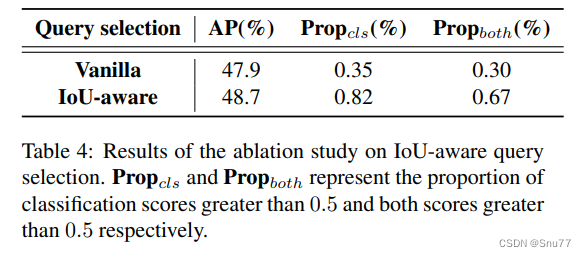
我们对IoU感知查询选择进行了消融研究,定量实验结果显示在表4中。我们采用的查询选择根据分类分数选择前300个编码器特征作为内容查询,这些被选择的特征对应的边界框被用作初始位置查询。我们比较了在val2017上由两种查询选择选出的编码器特征,并计算了分类分数大于0.5和两者分数都大于0.5的比例,分别对应于“Propcls”和“Propboth”列。结果显示,IoU感知查询选择选出的编码器特征不仅增加了高分类分数的比例(0.82%对比0.35%),而且提供了更多同时具有高分类分数和高IoU分数的特征(0.67%对比0.30%)。我们还评估了在val2017上用两种查询选择训练的检测器的准确性,其中IoU感知查询选择在AP上实现了0.8%的提升(48.7%对比47.9%)。
5.5、 关于解码器的消融研究
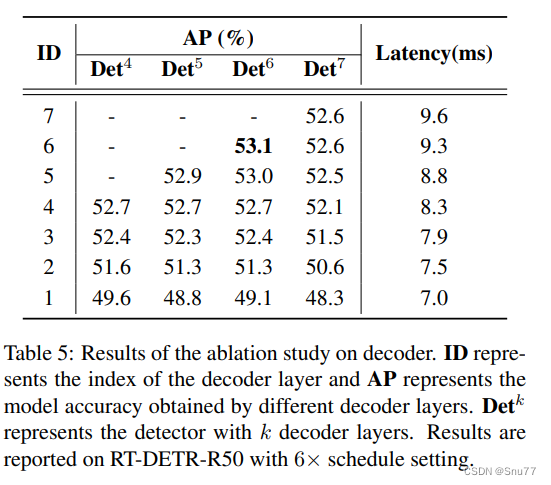
表5显示了RT-DETR在不同解码器层数下的准确性和速度。当解码器层数为6时,检测器达到了最佳的53.1%AP。我们还分析了每个解码器层对推理速度的影响,并得出结论,每个解码器层大约消耗0.5毫秒。此外,我们发现解码器相邻层之间的准确性差异随着解码器层索引的增加而逐渐减小。以6层解码器为例,使用5层进行推理只在准确性上损失0.1%AP(53.1%对比53.0%),同时将延迟减少了0.5毫秒(9.3毫秒对比8.8毫秒)。因此,RT-DETR支持在不需要为推理重新训练的情况下,通过使用不同的解码器层灵活调整推理速度,这有助于实时检测器的实际应用。
六、总结
在本文中,我们提出了RT-DETR,据我们所知,这是第一款实时的端到端检测器。我们首先对NMS进行了详细分析,并建立了一个端到端速度基准测试,以验证当前实时检测器的推理速度被NMS延迟的事实。我们还从NMS的分析中得出结论,无锚点检测器在相同精度下表现优于基于锚点的检测器。为了避免NMS造成的延迟,我们设计了一个包括两个关键改进组件的实时端到端检测器:一种可以高效处理多尺度特征的混合编码器,以及一种改进了对象查询初始化的IoU感知查询选择。广泛的实验表明,与类似规模的其他实时检测器和端到端检测器相比,RT-DETR在速度和精度方面都达到了最先进的性能。此外,我们提出的检测器支持使用不同的解码器层灵活调整推理速度,无需重新训练,这便于实时目标检测器的实际应用。我们希望这项工作能够被投入实践,并为研究人员提供灵感。
六、RT-DERT的官方版本训练方法
官方版本的训练方式又分两种,下面图片中使用两种不同的框架下实现的RT-DETR,我会拿PyTorch版本来进行举例另一种操作相同。
(前面提到过RT-DETR的Pytorch版本只支持COCO的数据集训练所以开始之前大家需要有一个COCO的数据集)
6.1 步骤一
我们找到如下文件“rtdetr_pytorch/configs/dataset/coco_detection.yml”,内容如下->
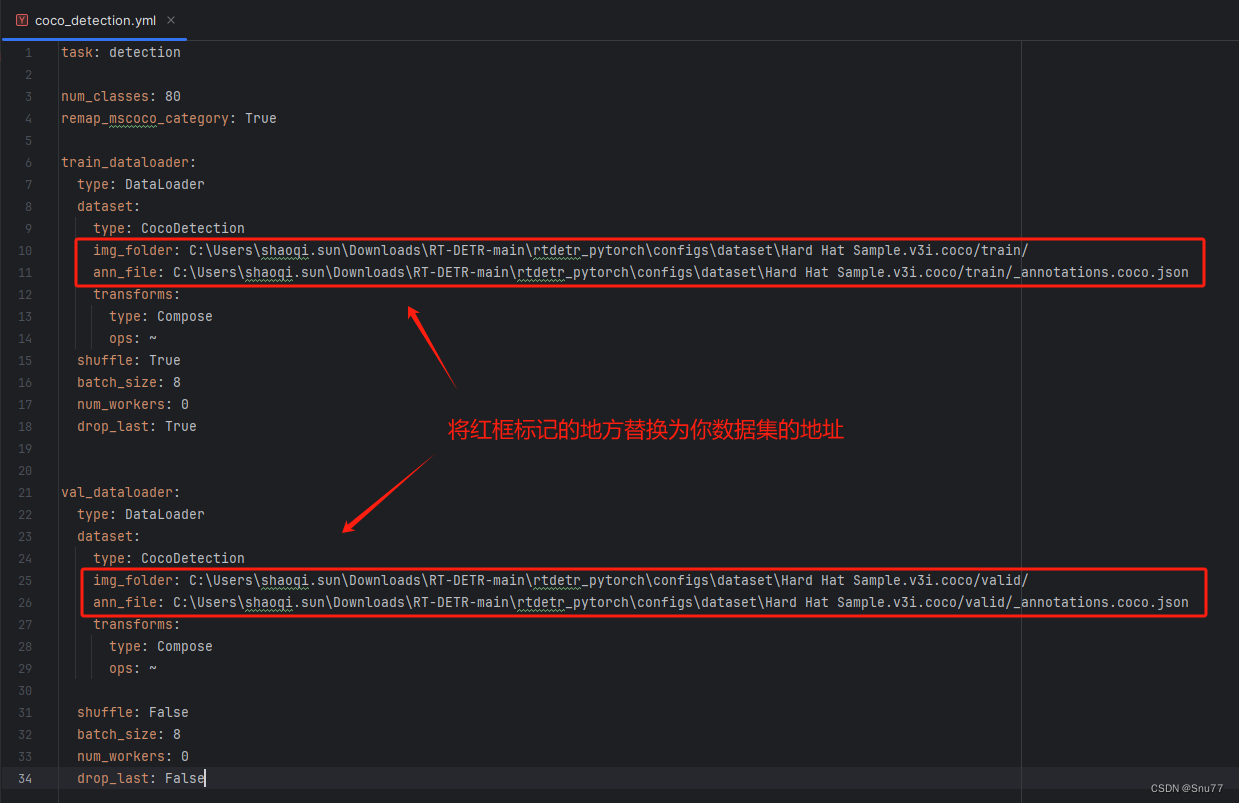
6.2 步骤二
我们找到下面的这个文件"RT-DETR-main/rtdetr_pytorch/tools/train.py"
"RT-DETR-main/rtdetr_pytorch/tools/train.py" 文件得末尾如下图的右面所示我们找到左边的配置文件填写到右边 的config参数下。

之后我们运行整个文件即可开始训练
PS:首次训练需要下载权重

训练过程如下->
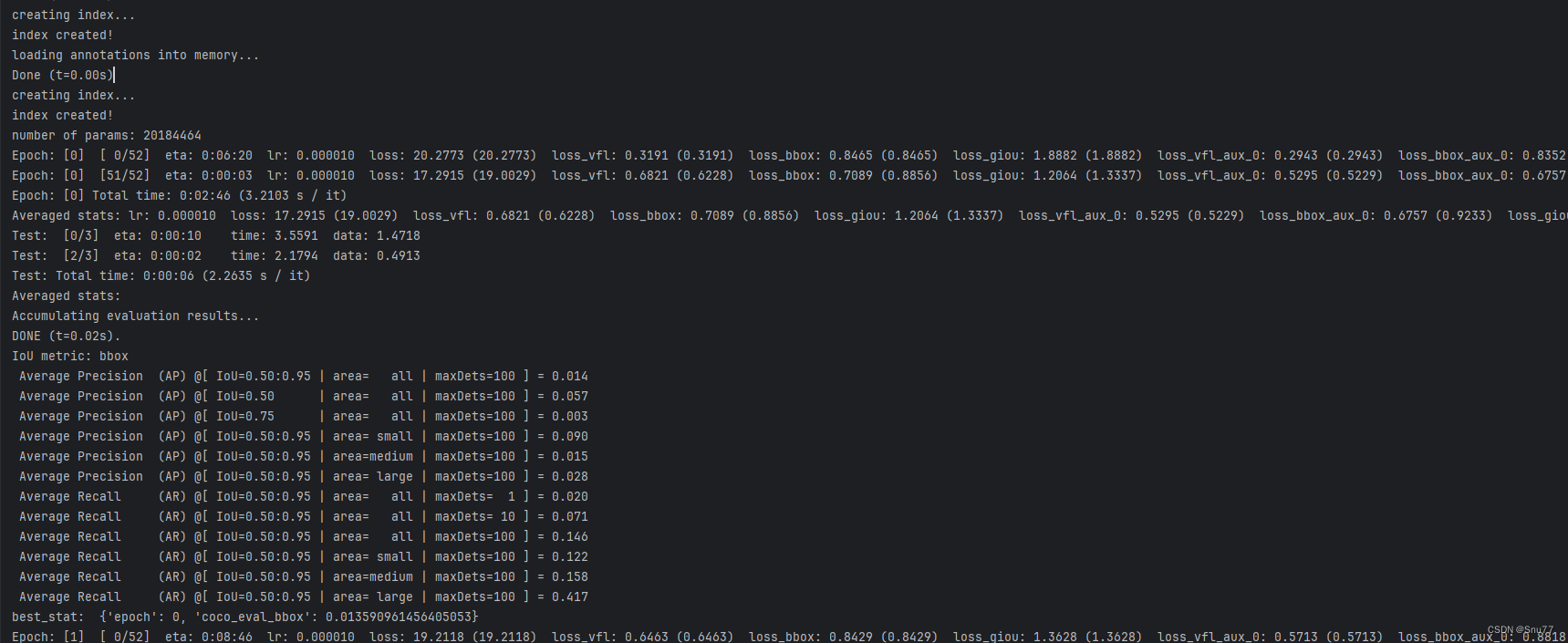
训练结果会保存在以下的文件的地址(后面我们导出需要这个文件)->
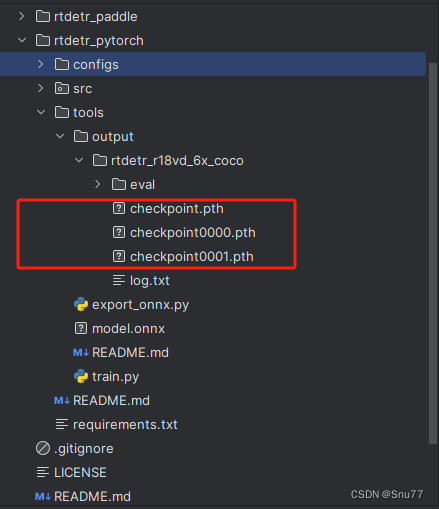
PS:这里只讲了Pytorch版本的训练方式, Paddle版本的训练方式一样就不重复了。
七、RT-DERT的YOLO版本训练方法
这里讲的是YOLO版本的RT-DETR训练方法,一种方法是通过命令行另一种方法是通过创建文件来训练,共有参数如下->
7.1 方式一
我们可以通过命令直接进行训练在其中指定参数,但是这样的方式,我们每个参数都要在其中打出来。命令如下:
yolo task=detect mode=train model=ResNet18_vd_pretrained_from_paddle.pth data=data.yaml batch=16 epochs=100 imgsz=640 workers=0 device=0
需要注意的是如果你是Windows系统的电脑其中的Workers最好设置成0否则容易报线程的错误。
7.2 方式二(推荐)
通过指定cfg直接进行训练,我们配置好ultralytics/cfg/default.yaml这个文件之后,可以直接执行这个文件进行训练,这样就不用在命令行输入其它的参数了。
yolo cfg=ultralytics/cfg/default.yaml7.3 方式三
我们可以通过创建py文件来进行训练,这样的好处就是不用在终端上打命令,这也能省去一些工作量,我们在根目录下创建一个名字为run.py的文件,在其中输入代码
- from ultralytics import RTDETR
-
- # Load a model
- model = RTDETR("ultralytics/cfg/models/rt-detr/rtdetr-l.yaml") # build a new model from scratch
-
- # Use the model
- model.train(data="fire.v1i.yolov8/data.yaml", cfg="ultralytics/cfg/default.yaml", epochs=100) # train the model
训练截图如下->
八、RT-DERT的官方版本训练方法
官方版本的训练方式又分两种,下面图片中使用两种不同的框架下实现的RT-DETR,我会拿PyTorch版本来进行举例另一种操作相同。
(前面提到过RT-DETR的Pytorch版本只支持COCO的数据集训练所以开始之前大家需要有一个COCO的数据集)
8.1 步骤一
我们找到如下文件“rtdetr_pytorch/configs/dataset/coco_detection.yml”,内容如下->
8.2 步骤二
我们找到下面的这个文件"RT-DETR-main/rtdetr_pytorch/tools/train.py"
"RT-DETR-main/rtdetr_pytorch/tools/train.py" 文件得末尾如下图的右面所示我们找到左边的配置文件填写到右边 的config参数下。
之后我们运行整个文件即可开始训练
PS:首次训练需要下载权重
训练过程如下->
训练结果会保存在以下的文件的地址(后面我们导出需要这个文件)->
PS:这里只讲了Pytorch版本的训练方式, Paddle版本的训练方式一样就不重复了。
九、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的RT-DETR改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~


