
- 1AIGC文生图核心技术:StableDiffusion原理详细介绍_ai文生图的原理
- 2好工具推荐系列:国内外git开源仓库gitee和codechina_giteecode
- 3Android RadioButton控件
- 4Android 微信主页面_#22292c
- 5Redis过期回调_error org.springframework.data.redis.listener.redi
- 6MongoDB~俩大特点管道聚合和数据压缩(snappy)
- 7微信小程序发送请求
- 8AS移动开发--类微信界面的实现_微信app界面的设计与实现
- 9如何准备阿里社招面试,顺谈 Java 程序员学习中各阶段的建议
- 10Llama模型家族之RLAIF 基于 AI 反馈的强化学习(三) RLAIF 的工作原理
一文详解BERT模型实现NER命名实体抽取-王文广_实体抽取模型应用
赞
踩

在自然语言处理和知识图谱中,实体抽取、NER是一个基本任务,也是产业化应用NLP 和知识图谱的关键技术之一。BERT是一个大规模预训练模型,它通过精心设计的掩码语言模型(Masked Language Model,MLM)来模拟人类对语言的认知,并对数十亿个词所组成的语料进行预训练而形成强大的基础语义,形成了效果卓绝的模型。通过 BERT来进行实体抽取、NER的方法是当前在NLP和知识图谱的产业化应用中最常用的方法,是效果与成本权衡下的最佳选择。本文详细讲解使用BERT来进行实体抽取,看完本文就会用当前工业界最佳的模型了。
什么是实体抽取?
实体是一个常见的名词,《知识图谱:认知智能理论与实战》一书将其定义为:
实体(Entity):是指一种独立的、拥有清晰特征的、能够区别于其他事物的事物。在信息抽取、自然语言处理和知识图谱等领域,用来描述这些事物的信息即实体。实体可以是抽象的或者具体的。
在实体抽取中,实体也成为命名实体(Named Entity),是指在实体之上会将其分门别类,用实体类型来框定不同的实体。图1是一些常见的“实体”的例子,比如“城市”类型的实体“上海”,“ 公司”类型的实体“达观数据”等。

图1 实体示例
实体抽取(Entity Extraction,EE)的目标就是识别一段文本中所包含的实体,在其他语境中,也被称之为“实体识别(Entity Recognition,ER)”、“命名实体识别(Named Entity Recognition,NER)”,这些不同的名词在大多数情况下所指代的意思是一样的。
举例来说,有一段文本:
达观数据与同济大学联合共建的“知识图谱与语义计算联合实验室”正式揭牌成立
识别出其中的蓝色部分,并标记为“机构”类型的实体,就是实体抽取。实体抽取的过程通常可以分为是两个阶段:
-
识别出所有表示实体的词汇
-
将这些词汇分类到不同实体类型中
在传统的命名实体识别任务中,通常有人物、机构、地点等。而在知识图谱中,实体类型可以有数十种,甚至数百种。对于知识图谱来说,将各种文本中的实体抽取出来是最基本的任务,有许多方法都致力于解决这个问题。
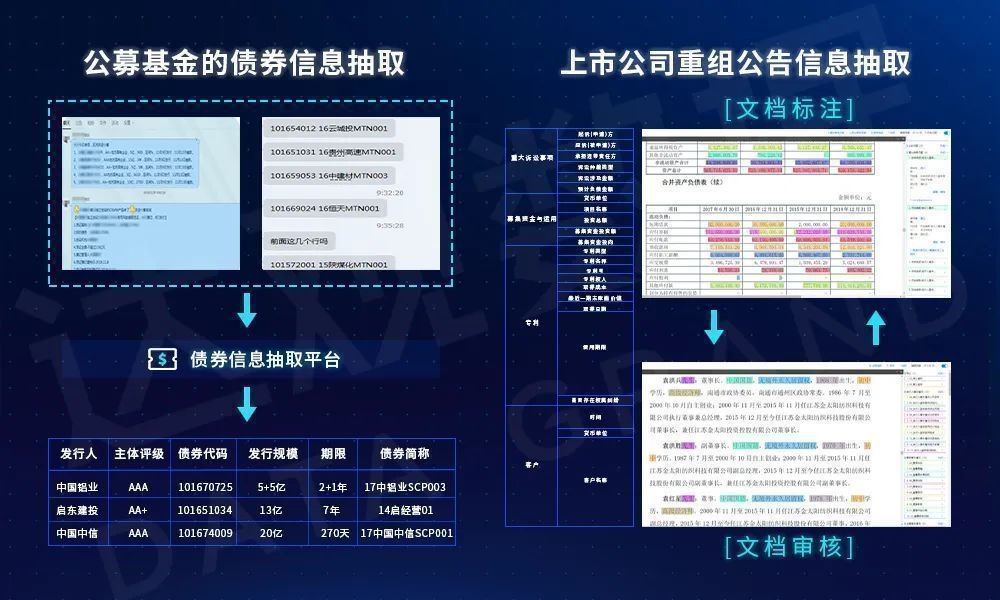
图2 实体抽取案例
众所周知,实体抽取的复杂程度十分之高,这不仅仅有上图中的这样复杂的文档的原因,语言本身的理解也存在重重困难,有些场景下即使是人类也会出现不解之处。比如语言中隐含着专业的背景知识,隐形或显性的上下文语境,同样的文本表达着完全不同的概念,而相同的概念又有多变的语言表达方法等等。这些综合的原因使得理解语言成为了人工智能皇冠上的明珠,而从文本中抽取实体则不可避免地要理解语言,实体抽取的效果则依赖于对语言理解的程度。

图3 语言理解困难重重<

