
- 1信息系统项目管理师第一章_左人右龟上鹰
- 2一个完整的购物商城系统是一个庞大且复杂的任务,涉及到前端、后端、数据库等多个方面。
- 3docker 安装与使用日记_docker slim
- 4Unity优化大全(八)之 GPU-Ligh和其他_unity gpu opaque
- 5MySQL长时间事务_MySQL-长事务详解
- 6sql 前100条_在100,900之前的sql
- 7this beta version of Typora is expired, please download and install a newer version.Typora的保姆级最新解决方法_无法下载this beta version of typora is expired
- 8循环顺序队列_c语言请设计void clearqueue(seqqueue *q)函数。 该函数清除循环顺序队列q
- 9一文掌握大模型数据准备、模型微调、部署使用全流程_如何给大模型的数据
- 10OWASP固件安全性测试指南_fstm
MySQL 使用 limit 分页会导致数据丢失、重复和索引失效_mysql limit影响索引
赞
踩
项目场景:
作为程序员,经常写 SQL 语句是正常不过了,在项目中我们都会使用【limit】进行查询,但在最近几个项目中都出现异常。
问题一:遗漏数据
在XXX项目中,进行歌手分页查询使用limit进行分页拉取,但在结果统计数据中出现了数据缺失
数据查询sql:
SELECT count(*) FROM `xx` where is_china in (4,6)
- 1
SELECT id FROM `xx` WHERE is_china IN ( 4, 6 ) LIMIT #{start},#{pageSize}
- 1
数据总量:2661025,拉取结果: 2340358,缺失了 30万+的数据量。
1.解决方案:
排序中加上唯一值,比如主键id
SELECT id FROM `xx` WHERE is_china IN ( 4, 6 ) order by id LIMIT #{start},#{pageSize}
- 1
2.原因分析:
MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。
在学习其他文档了解到,在5.5版本中没有这个问题。产生这个现象的原因就是5.6针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,使用的是堆排序算法。
如上述的例子 limit 0,2 需要采用大小为2的大顶堆;limit 2,4需要采用大小为4的大顶堆。
堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。而解决这个问题的有效方法就是可以在排序中加上唯一值,比如主键id。
3.问题衍生
在上述解决中包含了个关键点:唯一值进行排序,但在我们某些项目中没有使用【唯一值】进行排序的时候,果然也出现了这个问题
1.在官方文档中有这么一段话,在我们使用order by + limit 进行排序时:
官方文档是这样描述的:
If multiple rows have identical values in the ORDER BY columns, the server is free to return those rows in any order, and may do so differently depending on the overall execution plan. In other words, the sort order of those rows is nondeterministic with respect to the nonordered columns.
One factor that affects the execution plan is LIMIT, so an ORDER BY query with and without LIMIT may return rows in different orders
- 如果在使用order by列中的多个行具有相同的值,则服务器可以按任何顺序自由返回这些行,并且可能根据整体执行计划的不同而不同。换句话说,这些行的排序顺序相对于无序列是不确定的。
- 影响执行计划的一个因素是 LIMIT,因此ORDER BY 使用和不使用查询LIMIT可能会返回不同顺序的行。如果确保使用和不使用相同的行顺序很重要,请LIMIT在ORDER BY子句中包含其他列以使记录具有确定性,比如使用主键。
该部分引用自缺陷的背后(一)—MYQL之LIMIT M,N 分页查找
mysql官方文档:https://dev.mysql.com/doc/refman/5.7/en/limit-optimization.html
问题二: order by limit 造成优化器选择索引错误
1.不使用limit分页,直接进行查询

2.在limit进行数据分页时:
- 在limit 0,1000到limit 10000,1000使用的是主键进行查询
- 在limit 10000,1000以后,使用的是唯一索引进行查询
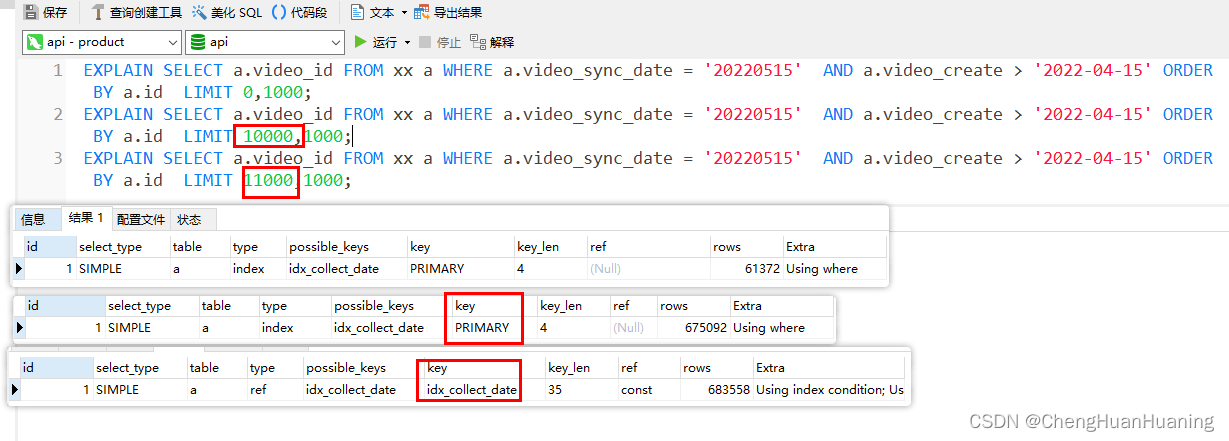
通过现象可以看到:
MySQL在order by id 和 limit 结合使用时,会根据limit值的大小来改变执行计划,可能选择不同的索引进行查询
# 相关建表语句
CREATE TABLE `xx` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`video_id` varchar(50) NOT NULL COMMENT '视频id',
`video_create` datetime DEFAULT NULL COMMENT '视频创建时间',
`video_sync_date` varchar(8) DEFAULT NULL COMMENT '视频同步时间'
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `idx_video_id` (`video_id`,`video_sync_date`) USING BTREE,
KEY `idx_collect_date` (`video_sync_date`,`create_date`,`comment_update`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=43653223 DEFAULT CHARSET=utf8mb4;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1.解决方案:
在排序中使用的索引字段与查询字段保持统一,都使用唯一索引进行查询和排序。
2.原因分析:
个人理解:mysql优化器认为如果不走【主键】索引,在查询出结果后还需要排序,而走【主键】索引只需要顺序扫描,且扫到满足limit就行了,效率比选取其他索引高,所以选择了【主键】索引而不是理想的【idx_collect_date】索引
bug 触发条件如下:
1.优化器先选择了 where 条件中字段的索引,该索引过滤性较好;
2.SQL 中必须有 order by limit 从而引导优化器尝试使用 order by 字段上的索引进行优化,最终因代价问题没有成功
相关文章:
MySQL · 捉虫动态 · order by limit 造成优化器选择索引错误
MySQL ORDER BY主键id加LIMIT限制走错索引
3. 小结
1.在order by id的情况下,MySQL由于自身的优化器选择,为了避免某些排序的消耗,可能会走非预期的PRIMARY主键索引;
2.order by 和 limit 结合使用,如果where 字段,order by字段都是索引,那么有limit索引可能会使用order by字段所在的索引,没有limit则会使用where 条件的索引;
3.对于数据量比较大,而且执行量很高的分页sql,尽可能将所有的查询字段包括在索引中,同时使用索引来消除排序;

