
- 1RandLA-Net 训练自定义数据集
- 2Android源码环境搭建(aosp Ubuntu 16.04)_千里马csdn
- 3MacOS M1 使用 Homebrew 安装 Mysql_mac系统m1 brew安装指定版本mysql
- 4Mongodb正则表达式$regex操作符_mongodb $regex
- 50053-基于单片机的晾衣架仿真设计_单片机自动晾衣架光敏电阻
- 6各类总线协议_txrs
- 7【STM32自学笔记-ADC】_stm32战舰ad转换器引脚
- 8LINUX下编译安装PROTOBUF_error while loading shared libraries: libprotobuf.
- 9python对字符串的处理_Python对字符串的读出、处理及写入
- 10docker-compose部署Kafka_kafka docker-compose (kafka.server.kafkaconfig)
Transformer模型-Positional Encoding位置编码的简明介绍_transformer中的positional encoding使用了一种特殊的编码方式
赞
踩
今天介绍transformer模型的positional encoding 位置编码

背景
位置编码用于为序列中的每个标记或单词提供一个相对位置。在阅读句子时,每个单词都依赖于其周围的单词。例如,有些单词在不同的上下文中具有不同的含义,因此模型应该能够理解这些变化以及每个单词所依赖的上下文。一个例子是单词“trunk”。在一种情况下,它可以用来指大象用鼻子喝水;在另一种情况下,它可能指的是被闪电击中的树干。
由于模型使用长度为d_model的嵌入向量来表示每个单词,因此任何位置编码都必须与之兼容。使用整数来表示位置似乎很自然,比如第一个标记为0,第二个标记为1,以此类推。然而,这个数字很快就会增长,并且不容易添加到嵌入矩阵中。相反,我们为每个位置创建一个位置编码向量,这意味着可以创建一个位置编码矩阵来表示单词可能占据的所有位置。
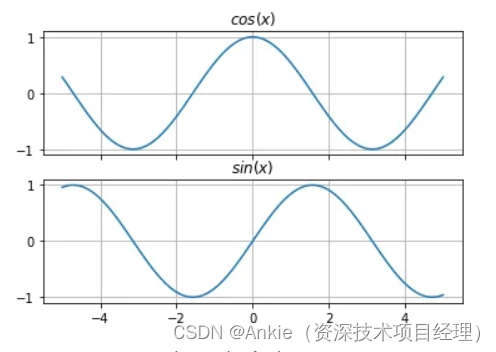
在“Attention Is All You Need”这篇论文中,为了捕捉这种位置信息,作者提出了一种特殊的位置编码方法,利用正弦和余弦函数为序列中的每个位置生成唯一的向量。这种方法不仅避免了整数位置编码可能导致的问题(如快速增长的数值和难以整合到嵌入矩阵中),而且还为每个位置提供了标准化的、无需额外训练的独特表示。通过这种方式,模型可以更好地理解序列中单词的顺序和相互依赖关系,从而提高其处理自然语言任务的能力。
公式:

举例:

pos 代表位置,i 代表维度。
对于每个位置编码向量,每两个元素为一组,将偶数位置的元素设置为PE(pos, 2i),将奇数位置的元素设置为PE(pos, 2i+1)。然后重复这个过程,直到向量中有d_model个元素为止。
我们选择这个函数是因为我们假设它能让模型更容易地学习到按相对位置进行关注。对于任何固定的偏移量 k,PE_{pos+k} 都可以表示为 PE_{pos} 的线性函数。这意味着模型可以通过学习不同位置编码之间的线性关系来理解序列中单词的相对位置。这种方法的好处是,无论序列有多长,模型都可以有效地利用位置信息,因为位置编码是通过正弦和余弦函数连续生成的,而不是依赖于离散的、有限的位置标记。
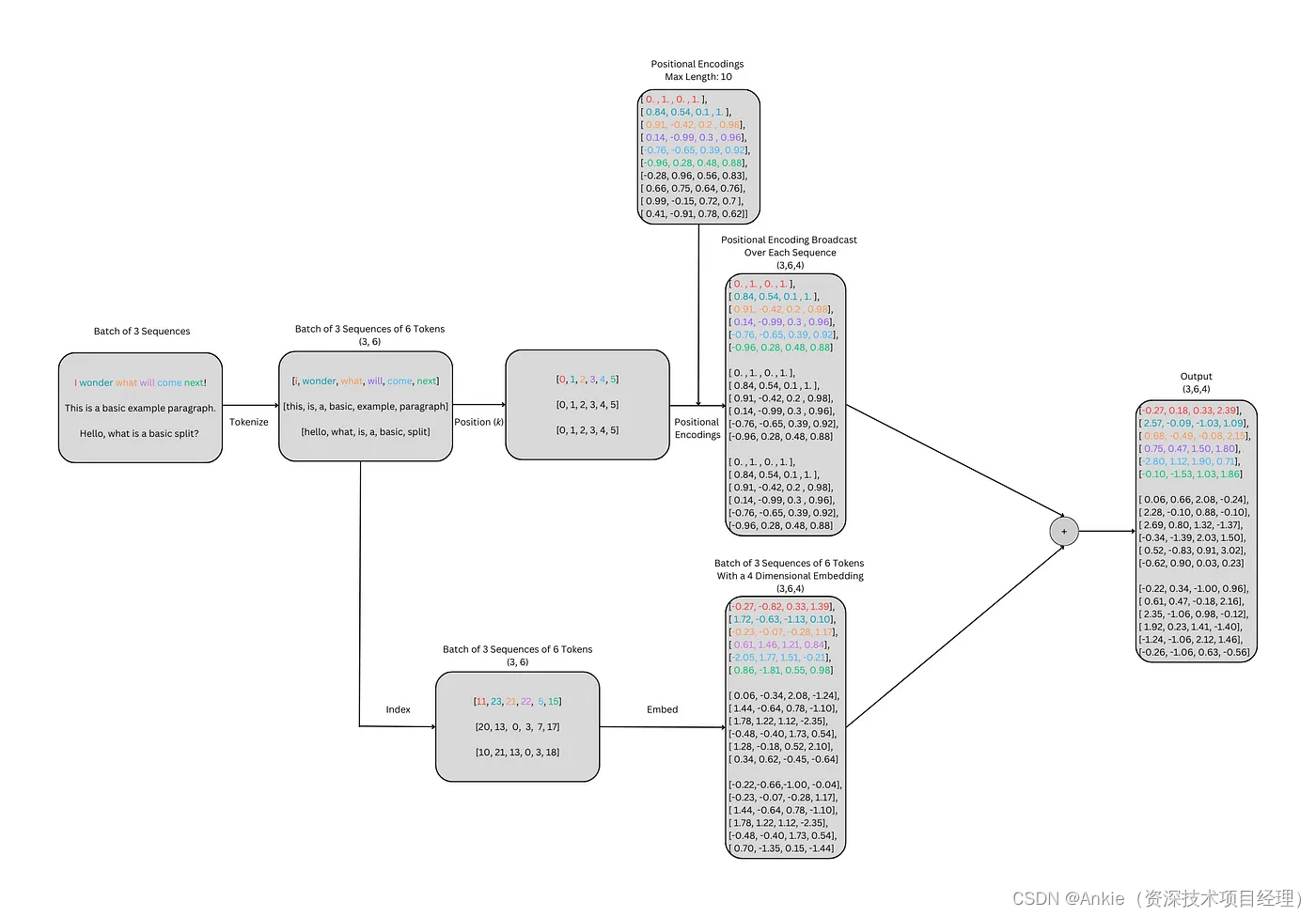
最后,把位置编码被添加到嵌入向量。

完整的流程如下:
原文链接:
https://medium.com/@hunter-j-phillips/positional-encoding-7a93db4109e6

