
热门标签
热门文章
- 155.跳跃游戏_给定一个整数数组,表示位于直线上的障碍物的坐标。 假设您从坐标为 0的点向右跳。
- 2【onlyoffice 服务器本地化部署】onlyoffice解决社区版文件编辑大小限制的方法。_onlyoffice社区版有哪些限制
- 323年hadoop单机版+hive_hadoop3.3.6 单机版
- 4如何在win7同样支持Webview2 在 WPF 中使用本地 Webview2 ,如何不依赖系统 Runtime_win7 webview2
- 5顺利上岸字节电商后端,但也真的很不顺利
- 62023各大厂面试遇到的91道软件测试面试题+答案纯干货_2023下半年软件测评师考题
- 7MySQL高级篇——性能分析工具_mysqldumpslow
- 8Kafka系列——Kafka数据通道指南,总结遇到的以及需要考虑的问题因素_通道数据传输 kafka格式
- 9git在macOS环境下的安装与配置(小白版)_apple git 设置_git for mac
- 10最新软件测试面试题 —— 整理与解析(3)_机票购买测试场景面试(1),0基础学软件测试开发
当前位置: article > 正文
Java8 Stream流常用api总结 --工作起来真的很方便_i->i.getage()
作者:花生_TL007 | 2024-06-02 10:25:42
赞
踩
i->i.getage()
目录
5.可以设置流的最大长度,超出的部分将被抛弃。(limit)
9.归约实现对集合求和、求乘积和求最值操作。(reduce)

stream流的特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
stream流的常用api:
Stream 流的中间方法,即中间操作方法,也称为非终结方法。常用的 API 如下:
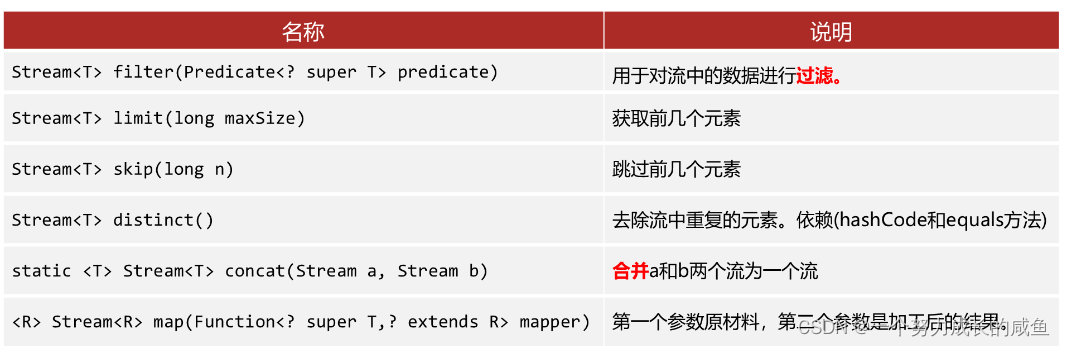
Stream 流的终结方法,即终结操作方法。常用的 API 如下:

stream流的综合应用
1.分组的常用用法(collectors.gropingBy(i->i.getName))
- //按照职员部分分组: List<Employee> list
- Map<String, List<Employee>> collect = list.stream().collect(Collectors.groupingBy(i -> i.getUnitName()));
-
- //多条件分组
- Map<String, Map<String,List<Employee>>> collect =list.stream().collect(Collectors.groupingBy(i -> i.getUnitName(),Collectors.groupingBy(i -> i.getWorkType())));
-
- //按年龄分组,年龄相同的是一组
- Map<Integer, List<Person>> 分组 = list.stream().collect(Collectors.groupingBy(Person::getAge));
-
- //按年龄分组后按工资分组,多级分组
- Map<Integer, Map<String, List<Person>>> 多级分组 = list.stream().collect(Collectors.groupingBy(Person::getAge, Collectors.groupingBy(x -> {
- return x.getSalary() > 3000 ? "高" : "低";
- })));
2、过滤.(filter方法)
- //根据指定sn,过滤出符合的数据: List<Map<String, Object>> list
- List<Map<String, Object>> newList = list.stream().filter(map -> map.get("sn").toString().equals(sn)).collect(Collectors.toList());
-
- //筛选出工资大于10000的职员
- List<Employee> newList = list.stream().filter(item -> {
- return item.getSalary().compareTo(new BigDecimal(10000)) > 0
- && !item.getWorkType().equals("项目经理");
- }).collect(Collectors.toList());
3.去重.(distinct)
- //打印所有作家的姓名,并且要求其中不能有重复元素。
-
- List<Author> authors = getAuthors();
- authors.stream()
- .distinct()
- .forEach(author -> System.out.println(author.getName()));
注意:distinct方法是依赖Object的equals方法来判断是否是相同对象的。所以需要注意重写equals方法
4.排序.(sorted)
- 对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素。
-
- List<Author> authors = getAuthors();
- // 对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素。
- authors.stream()
- .distinct()
- .sorted()
- .forEach(author -> System.out.println(author.getAge()));
-
- List<Author> authors = getAuthors();
- // 对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素。
- authors.stream()
- .distinct()
- .sorted((o1, o2) -> o2.getAge()-o1.getAge())
- .forEach(author -> System.out.println(author.getAge()));
- //按照时间排序 1升 -1降
- Collections.sort(listFast, (p1, p2) -> {
- return String.valueOf(p1.get("time")).compareTo(p2.get("time") + "");
- });
-
- // s1-s2 升序 s2-s1降序
- Collections.sort(list,(s1,s2) -> s1.getSalary().compareTo(s2.getSalary()));
-
- //多条件排序: List<Employee> list, s1-s2 升序 s2-s1降序
- list.sort(Comparator.comparing(Employee::getSalary).reversed().thenComparing(Employee::getId).reversed());
5.可以设置流的最大长度,超出的部分将被抛弃。(limit)
- 对流中的元素按照年龄进行降序排序,并且要求不能有重复的元素,然后打印其中年龄最大的两个作家的姓名。
-
- List<Author> authors = getAuthors();
- authors.stream()
- .distinct()
- .sorted()
- .limit(2)
- .forEach(author -> System.out.println(author.getName()));
6.跳过流中的前n个元素,返回剩下的元素(skip)
- 打印除了年龄最大的作家外的其他作家,要求不能有重复元素,并且按照年龄降序排序。
-
- // 打印除了年龄最大的作家外的其他作家,要求不能有重复元素,并且按照年龄降序排序。
- List<Author> authors = getAuthors();
- authors.stream()
- .distinct()
- .sorted()
- .skip(1)
- .forEach(author -> System.out.println(author.getName()));
7.可以用来获取当前流中元素的个数(count)
- 打印这些作家的所出书籍的数目,注意删除重复元素。
-
- // 打印这些作家的所出书籍的数目,注意删除重复元素。
- List<Author> authors = getAuthors();
-
- long count = authors.stream()
- .flatMap(author -> author.getBooks().stream())
- .distinct()
- .count();
- System.out.println(count);
8.统计:和、数量、最大值、最小值、平均值:
- //统计:和、数量、最大值、最小值、平均值: List<Employee> list
- IntSummaryStatistics collect = list.stream().collect(Collectors.summarizingInt(Employee::getId));
- System.out.println("和:" + collect.getSum());
- System.out.println("数量:" + collect.getCount());
- System.out.println("最大值:" + collect.getMax());
- System.out.println("最小值:" + collect.getMin());
- System.out.println("平均值:" + collect.getAverage());
9.归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。(reduce)
- public class StreamTest {
- public static void main(String[] args) {
- List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);
- // 求和方式1
- Optional<Integer> sum = list.stream().reduce((x, y) -> x + y);
- // 求和方式2
- Optional<Integer> sum2 = list.stream().reduce(Integer::sum);
- // 求和方式3
- Integer sum3 = list.stream().reduce(0, Integer::sum);
- // 求乘积
- Optional<Integer> product = list.stream().reduce((x, y) -> x * y);
-
- // 求最大值方式1
- Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y);
- // 求最大值写法2
- Integer max2 = list.stream().reduce(1, Integer::max);
-
- System.out.println("list求和:" + sum.get() + "," + sum2.get() + "," + sum3);
- System.out.println("list求积:" + product.get());
- System.out.println("list求最大值:" + max.get() + "," + max2);
- }
- }

10.map和list互转
- //将map的value转list
- List<User> userList = userMap.entrySet().stream().map(e ->e.getValue()).collect(Collectors.toList());
-
- //list转map
- //value是某一属性的值,例如,key是id,value是name:
- Map<String, String> userMap = userList.stream().
- collect(Collectors.toMap(User::getId, User::getName));
-
-
-
注意事项:
- 惰性求值(如果没有终结操作,没有中间操作是不会得到执行的)
- 流是一次性的(一旦一个流对象经过一个终结操作后。这个流就不能再被使用)
- 不会影响原数据(我们在流中可以多数据做很多处理。但是正常情况下是不会影响原来集合中的元素的。这往往也是我们期望的
好,以上就是全部内容,能坚持看到这里,你一定很有收获,那么动一动拿offer的小手,点个赞再走吧,听说这么做的人2023年都交了好运!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/662342
推荐阅读
相关标签

