
- 1激光雷达与自动驾驶详解_地平线j2+rh850
- 2Transformer的位置编码笔记(positional encoding)_transformer位置编码为啥用sin和cos
- 3全开源短剧app源码搭建带uniapp一键打包app
- 4matlab生成任意波形发生器(AWG)所需波形文件程序_任意波形发生器设置任意波形
- 5python nmap模块详解_python 使用nmap 模块
- 6explode与lateral view使用详解(spark及hive环境对比)_lateral view explode
- 7HBase的安装和配置_hbase安装与配置
- 82022年《北上广深杭》有哪些值得加入的软件测试大厂公司呢?花了三天三夜整理出各大互联网公司_硬件跟谁学
- 9php如何上传照片到数据库并回显_php实现图片上传路径到数据库
- 10C++ | Leetcode C++题解之第119题杨辉三角II
MySQL表增删改查(进阶)
赞
踩
一、前言
本篇文章是MySQL表里增删改查的进一步应用,相较之前简单的增删改查会难上一些。本篇主要围绕数据库约束、表的设计、新增、查询来学习。
提示:以下是本篇文章正文内容
二、数据库约束
数据库约束,就是创建表的时候,给这个表指定一些规则,后续插入/修改/删除都要保证数据是能够遵守这些规则的。而引入规则,是为了进行更强的数据检查或校验。当然,约束能够引入更多的检查操作,但是同时,也会带来额外的系统开销。所以,数据库约束是牺牲了执行效率,换来了开发效率。
| 类型 | 说明 |
|---|---|
| NOT NULL | 指示某列不能存储NULL值 |
| UNIQUE | 保证某列的每行必须有唯一的值 |
| DEFAULT | 规定没有给列赋值时的默认值 |
| PRIMARY KEY | NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录 |
| FOREIGN KEY | 保证一个表中的数据匹配另一个表中的值的参照完整性 |
| CHECK | 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句 |
说明:PRIMARY KEY 是主键。这是数据库中最重要的约束,表示一个记录的身份标识(如身份证,学号)。 FOREIGN KEY 是外键,描述两个表之间的关联关系。 CHECK 是指定一个具体的条件,在MySQL中并不支持。
下面通过代码来了解数据库约束。
- NOT NULL
create table student (id int, name varchar(20));
- 1
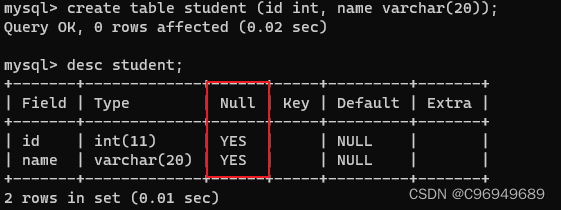
create table student2 (id int not null, name varchar(20));
- 1
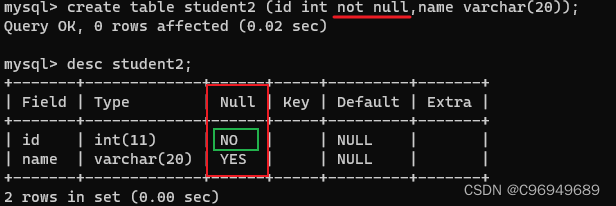
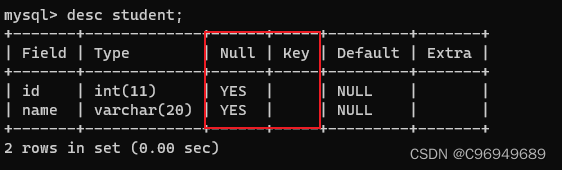
可以看到,在查看表结构时,原本id在Null一列经过not null修饰从YES变成了NO,说明id不再允许为Null。

当插入id为null时,就会提示错误。
- DEFAULT
create table student (id int, name varchar(20));
- 1
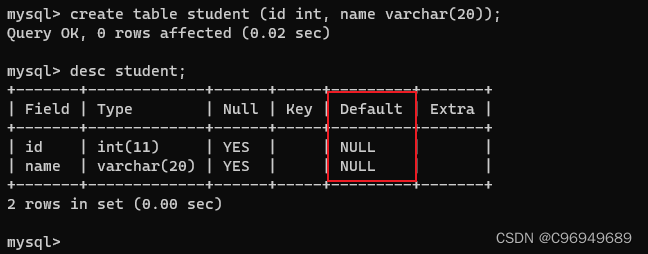
create table student (id int, name varchar(20) default '无名氏');
- 1
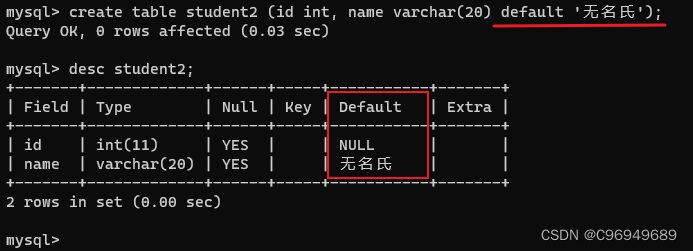
可以看到,查询表结构时,name的default这一列经过default修饰从NULL变成了无名氏。
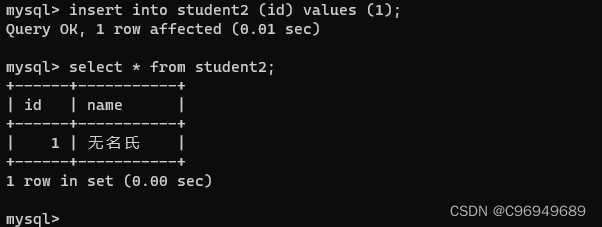
在只插入id时,name默认为无名氏。
- UNIQUE
create table student (id int, name varchar(20));
- 1
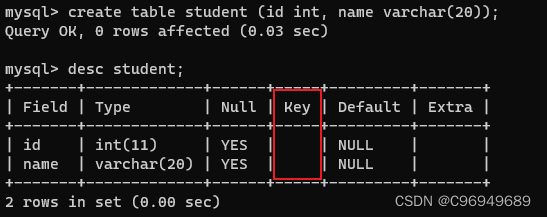
create table student (id int unique, name varchar(20));
- 1
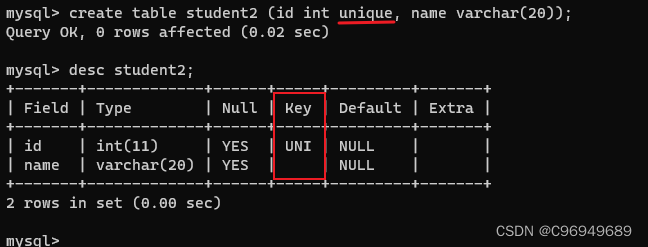
可以看到,id 在被unique修饰后,在查看表结构时,Key这一列变成了UNI,表示唯一。
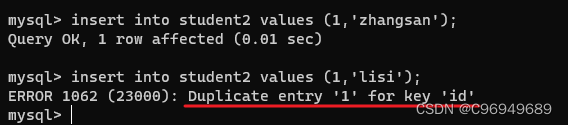
在插入id同为1的数据之后,MySQL就会报错,提示重复插入id为1。说明在加上unique约束之后,后续进行插入/修改的时候,都会先进行查询,看看当前这个值是否以及存在。
- PRIMARY KEY
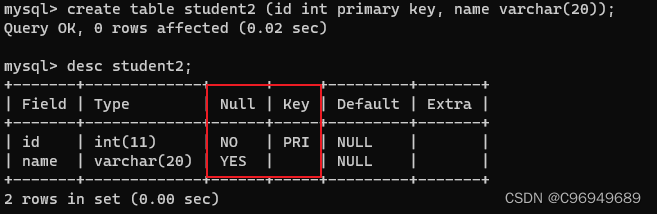
可以看到,id被primary key修饰后,Null变成了NO,Key变成了PRI。这表明primary key修饰的字段是非空且唯一的。
主键,是用来作为一个记录的身份标识。通常会使用一个xxx id 这样的列作为主键。一个表里面只能有一个主键。除了基础的使用之外,还有一种情况,就是联合主键,这个主键是由多个列联合构成的(暂不讨论)。

上面我们说到,主键是不可以重复的。那么如何保证它不重复?MySQL自身给我们提供了一种机制 “自增主键”。
create table student (id int primary key auto_increment, name varchar(20) );
- 1
通过自增主键,当前的id就不需要用户自己指定了,数据库会自行分配,按照“自增”的方式来分配。当然也可以手动插入id,但是要确保插入的结果是不重复的。
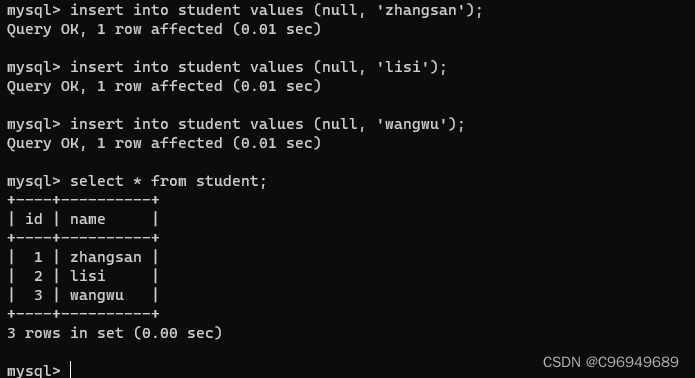
每次使用null的方式插入自增主键的时候,数据库会根据当前这一列的最大值,在这个基础上,继续进行递增。而且这里的递增是不会重复利用之前的值的,也就是说若最大id为20,即使删除了id为20的这一行,自增还是会从id为21开始。
上述自增主键,只能在单个数据库下生效。如果数据库是由多个MySQL服务器构成的”集群“,此时,自增主键就无法生效了。
MySQL服务器构成的集群:当表里的数据特别多,一台机器存不下,就需要使用多个机器,把表里的数据一分为二,每台机器存一半。此时,这两个机器的主键,就是各自自增各自的了。这就可能导致,第一个机器中的数据的id和第二个机器的数据的id重复了。实际上在业务中引入的”主键“是希望不会重复的。这其实就是所谓”分布式“。
确保一个分布式系统中,能够存在唯一的id。业界也有一些分布式系统生产唯一id的算法,但是都大同小异。有点儿类似于身份证号:位置信息+时间信息+其它编号。其算法主要由三部分构成(时间戳+主机编号+随机因子)。
首先把主键,设置成字符串类型。
1. 时间戳
时间戳,确保不同时刻生成的数据的id是不同的。
2. 主机编号
同一时刻生成的多个数据只要这几个数据是在不同主机上,仍然是可以通过主机编号确保不重复的。
3. 随机因子
同一时刻,同一个主机上生成了多个数据(随机数),这多个数据id 再通过随机因子进行区分。
当然,这套方案也不能够100%确保,生成的id一定是唯一的。关键在于,同一时刻,同一个主机上,连续两次随机因子恰好相同,这是当然有可能的,只是概率很低。
- FOREIGN KEY

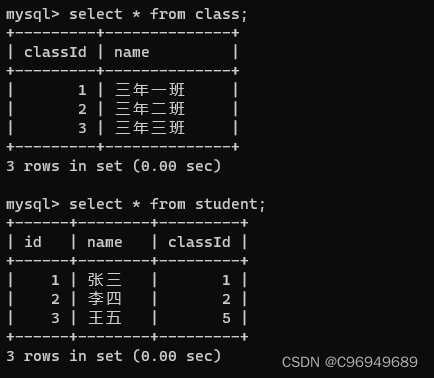
上面分别创建了一个班级表和学生表。可以看到,class表的classId为1,2,3。而学生却出现了classId为5的情况,然而并没有classId为5的班级,显然这样的数字是不合理的。所以,为了解决这样的问题,引入了外键约束。这样学生表中的classId都要在班级表中存在,就可以用外键约束来进行校验了。
create table class (classId int primary key, name varchar(20));
- 1
create table student (id int primary key, name varchar(20), classId int, foreign key (classId) references class (classId));
- 1

此时就要求,本表中的这个列的数据必须在引用的外面的表的对应列中存在。注意这里的约束与前面有所不同,外键约束,是要写到最后面的,而前面的列都定义好了之后,在最后面通过foreign key 创建外键约束。
这个情况下,也可以认为,班级表约束了学生表。
把班级表这种约束别的表的表,称为”父表“(parent table)
把学生表这种被别的表约束的表,称为”子表“(child table)
当父表中不存在子表需要插入的数据:

在插入时会先检查父表中是否存在数据,若不存在则插入失败。
子表存在父表关联的信息时,父表信息不能修改:

其实,外键约束是双向的。说是,父亲约束儿子,其实儿子也在约束父亲。子表对于父表也是有约束的。
想要删除父表的记录,就必须先删除子表对应的数据,确保子表中没有数据引用父表的记录,才能真正执行删除。尝试删除/修改父表中的记录,也会先查询子表,看看当前这个结果是否在子表中被引用,如果被引用了,就会删除失败。
使用外键约束的时候,操作子表时要查询父表,而操作父表时也要查询子表,这就伴随了很多的查询操作。如果表的数据很多,查询操作就会非常低效。为了让上述查询更高效一些,往往就需要要求子表中的列和父表中被引用的列,都要带有”索引“。

上述表为何创建失败?其实就是因为表里未添加主键,也就没有索引。所谓索引也可以理解成目录。

关于外键,还有一个经典的问题。如果做一个电商网站,有商品表和订单表两个表。
商品表(goodsId,name,price…)
订单表(orderId,goodsId,time…)
此处商品表和订单表就可以使用外键约束了,那么当商品要下架,如何完成这里的操作呢?其实我们只需在商品表的字段中添加isOnline(1表示商品在线,0表示商品下线),这样即使商品下架,只需要将商品上架信息标注为0,而无需考虑删除表中数据或者无法删除的因素。且历史订单数据是会是始终存在的,所以即使商品没了,订单也不能没。这种删除方式就是所谓的”逻辑删除“。
其实不仅仅是数据库,很多场景也会用到逻辑删除的思路。如电脑上的文件,你进行删除,也是逻辑删除,不是真正的删除。你把文件删除掉,其实也就是在系统中,把硬盘上的对应的盘块数据标记成无效了(也不是真正的删除)。删除文件+清空回收站 都是没用的,理论上都是可以恢复的。如果后面电脑不能用了,需要针对硬盘进行更彻底的删除(物理删除),也就是把硬盘砸了(0.0)。
所以,其实drop database在计算机硬盘上,也是逻辑删除,数据也是有很大概率能够恢复回来的。但是,不能保证数据100%恢复,所以还是尽量不要随便drop database。
- CHECK
MySQL使用时并不会报错,但是同时也忽略该约束(不支持)。
三、表的设计
设计,往往是和”经验“有一定关联的,谈到”数据库设计“就是根据需求,来把你需要的表给创建出来(有几个表,表里有啥…)
表的设计主要有两个步骤:
1. 先根据需求,找到实体
一些关键性质的对象,梳理清楚需求,提取出关键的名字。一般来说,每个实体,都得安排一个表。
2. 梳理清楚实体之间的关系
多个实体之间,需要理清楚关系。不同的关系下,有不同的设计表的方式。
而表的设计主要有三种关系
- 一对一
教务系统,需要表示的一个概念,学生(实体),需要一个学生表来描述这个实体。还有一个概念,账户(实体),需要一个账户表来描述这个实体。
学生表:学号、姓名、班级、联系方式、入学时间…
账户表:账户名、密码、注册时间、上次登录时间、登录地点…
一个学生,只能有一个账户。(学生不能有多号)
一个账户,也只能给一个学生使用。(一个账户不能给多个学生使用)
于是,在一对一的关系下,表结构就有一下两种设计方案:
方案一:创建一个大表,把两个表的信息合并起来。
学生账户表(accountId,accountName,password,…studentName,…)
如果这两个表都很简单(列很少)可以考虑合并,如果这两个表都很复杂(列很多)不建议合并。
方案二:分两个表,使用 id 来引用过来,建立联系。
student(studentId,studentName…)
account(accountId,userName,password…,studentId)
可以使用studentId建立两表之间的联系。
-
一对多
教务系统中,有一个实体学生,还有一个实体班级。一个班级,可以包含多个学生。
一个学生,只能从属一个班级。针对一对多设计表,也存在两种方案。
方案一:

但由于MySQL的类型中,不支持”数组“类型,因此这个方案在MySQL中行不通。只有像Redis这样的数据库才支持数组类型(List),就可以使用类似的方式来表示。
方案二:
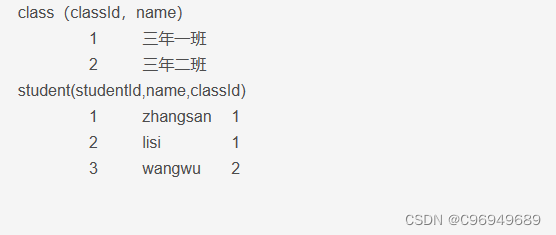
-
多对多
和刚才差不多,通过造句,把实体之间的关系,往固定句式里套。教务系统,学生是一个实体,课程也是一个实体。
一个学生,可以选择多门课程。
一个课程,也可以被多个学生选择。
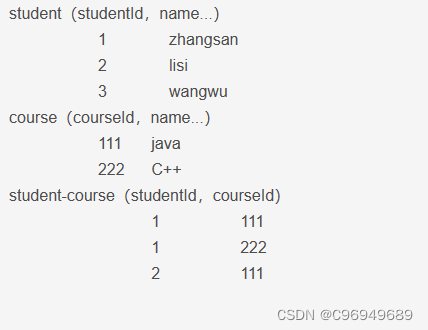
所以,确认实体的关系,就需要我们造句,往里套,这类似一个定式,按照固定套路来。

四、新增
insert into table_name [(column [,column...])] select...
- 1
这是一个组合技,把插入语句和查询语句结合到一起。以查询结果,来作为插入的值。把查询到的”临时数据“转换成”永久数据“。

当然也可以指定表中的列进行插入,但是查询出来的结果集合,列数/类型 要和 插入表的结构匹配。
SQL中经常有这种”套娃“操作。
五、多表查询
1.聚合查询
select name,chinese+math+english from...
- 1
上面这串代码是拿三个列来进行计算的。
聚合查询,就是在进行“行和行”之间的运算。通过”聚合函数“来进行操作,这是SQL提供的库函数。
| 函数 | 说明 |
|---|---|
| COUNT( [DISTINCT] expr ) | 返回查询到的数据的 数量 |
| SUM( [DISTINCT] expr ) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG( [DISTINCT] expr ) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX( [DISTINCT] expr ) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN( [DISTINCT] expr ) | 返回查询到的数据的 最小值,不是数字没有意义 |

虽然这个地方不是通过聚合函数获取到的,但是这个数据只是在客户端里方便看到,如果是编程的话,还是通过聚合函数进行比较好,使用聚合函数还可以进行一些条件判断。
下列举例说明:
例子1:
数据表:
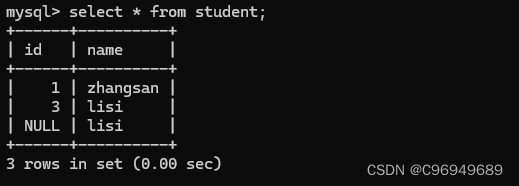
操作:
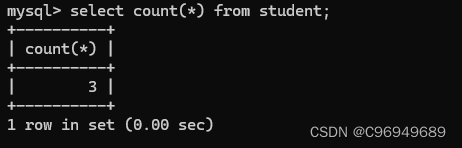
这个操作相当于先执行selct * from student,
再使用 count 来计算结果的行数。
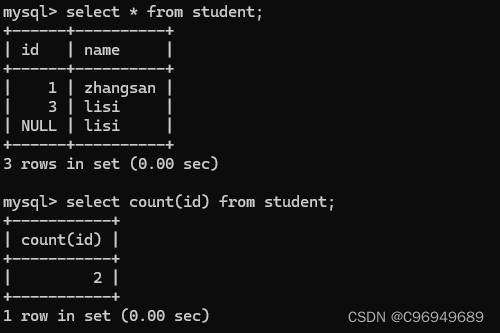
如果查询的列带有NULL,则NULL不计入行数。但如果使用count(*)的时候,即使是全是NULL的行,也会被记录。
例子2:
数据表:
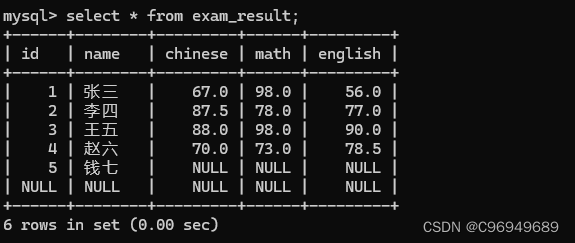
操作:
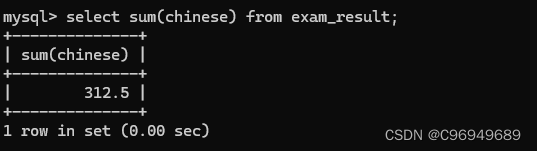
sum函数会把数字类型都相加起来,但是含义NULL的行会忽略掉,在SQL中NULL和其它数字进行运算,结果一般都是NUL。
剩下的AVG、MAX、MIN都是类似的。

若要查询数学成绩最低的同学:
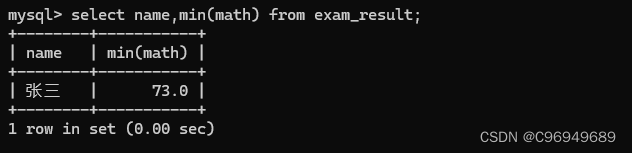
由数据表可知,数学成绩最低的同学并不是张三。由此可见,在使用聚合函数的时候,列和列之间的顺序以及被“打散”了。正常来说,一行数据的每个列都是对应的(共同构成同一条记录),如果查询中包含聚合函数和非聚合的列,则列各自是各自的。大部分情况下,聚合的列和非聚合的列,不能在一起配合使用,除非语句中带有group by的情况。

那么查询数学成绩最低的同学,可以使用order by加上limit。
前面的聚合,是把表的所有行都聚合在一起。但是有时候,我们可以把所有行分成若干组,每一组再分别进行聚合。
group by 的效果就是把指定的列,值相同的记录,划分到一组,针对这些组就可以分别进行聚合查询了。
数据表:
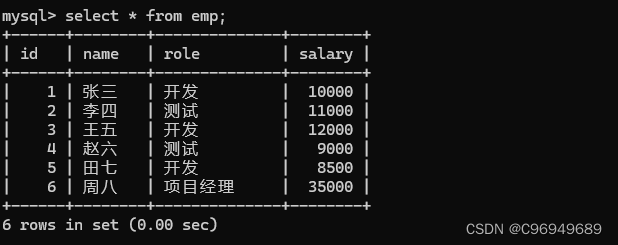
查询每个岗位的平均薪资:
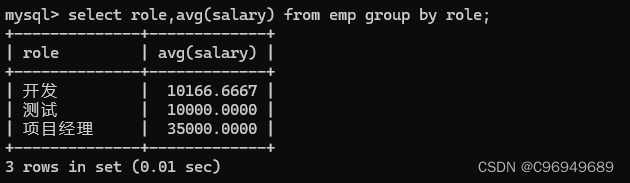
这里是按照role来group by的。
针对分组查询,也是可以使用条件的,可以对查询结果进行筛选。
分组之前的条件,使用where来表示。
分组之后的条件,使用having来表示。
例子1:
统计每个岗位的平均薪资,但是除去“张三”。
所以在分组之前,先把“张三”除去。
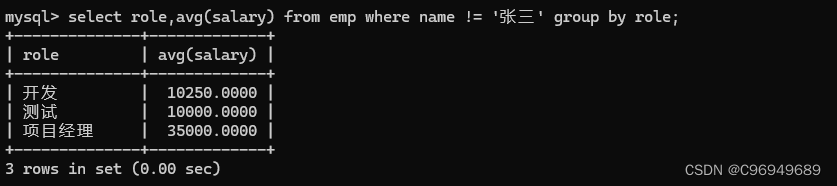
例子2:
统计每个岗位的平均薪资,除去平均薪资大于15000的情况。
平均薪资,需要在分组之后,才能计算。

所以,分组操作往往是和聚合一起使用的。
2.联合查询
前面的查询,都是针对一张表进行查询。而多表查询要比单表查询更加复杂。
2.1 内连接
内连接语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
- 1
- 2
提示:内连接的inner可以省略
在学习联合查询之前,我们需要先学习“笛卡尔积”。

那么在SQL中,笛卡尔积是怎么样的?其实,就是表之间进行简单的“排列组合”,将表1的所有列挨个加上表2的所有列。
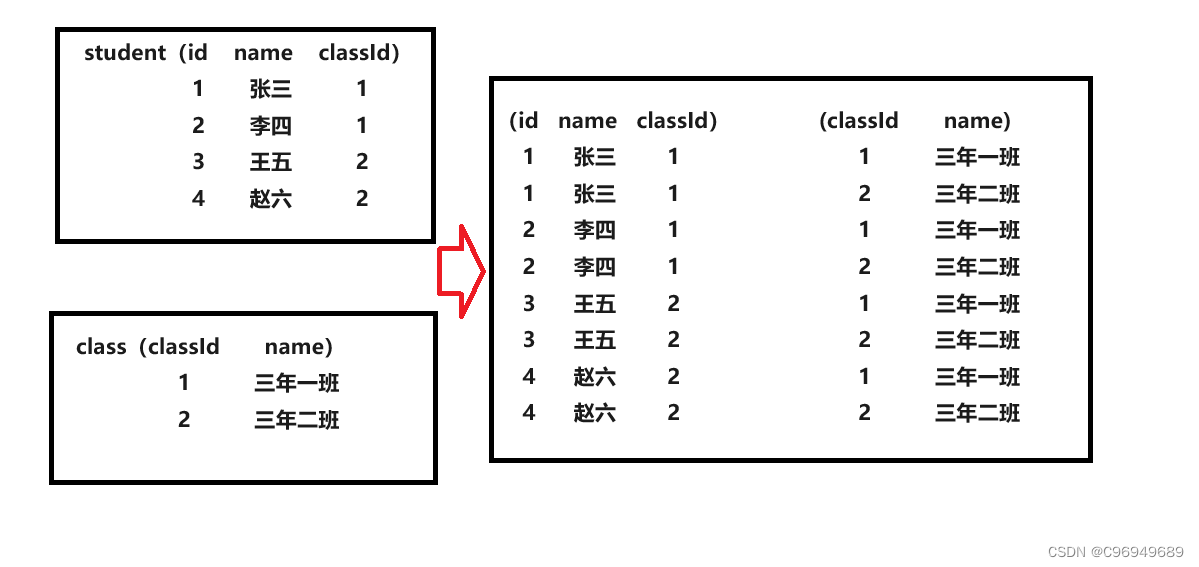
同时我们发现进行笛卡尔积之后,有些行的数据出现了不相符的情况,那么这些数据就是笛卡尔积之后无效的数据。
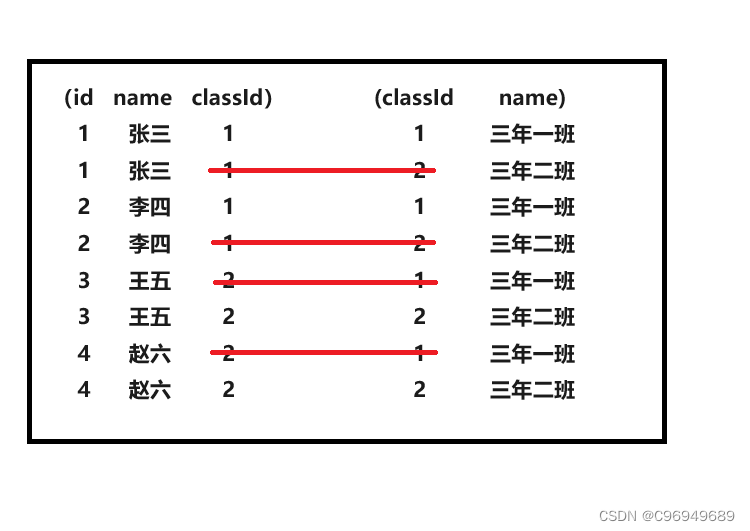
所谓的“多表联合查询”,核心操作就是进行笛卡尔积。比如使用两个表进行联合查询,就是先把两个表进行笛卡尔积,然后再指定一些条件,来实现需求中的一些查询。
再实际开发中,笛卡尔积(多表查询)一定要慎重使用,使用之前一定要评估好笛卡尔积的规模。如果基于两个很大的表进行笛卡尔积,这也是一个危险操作,会产生大量的运算和IO,可能会把数据库搞挂。
联合查询的四个要领:
1. 笛卡尔积
2. 指定连接条件
3. 指定其它条件
4. 针对列进行精简/表达式运算/聚合查询
提示:关联查询可以对关联表起别名
在进行联合操作前,先插入数据:
insert into classes(name, `desc`) values ('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'), ('中文系2019级3班','学习了中国传统文学'), ('自动化2019级5班','学习了机械自动化'); insert into student(sn, name, qq_mail, classes_id) values ('09982','黑旋风李逵','xuanfeng@qq.com',1), ('00835','菩提老祖',null,1), ('00391','白素贞',null,1), ('00031','许仙','xuxian@qq.com',1), ('00054','不想毕业',null,1), ('51234','好好说话','say@qq.com',2), ('83223','tellme',null,2), ('09527','老外学中文','foreigner@qq.com',2); insert into course(name) values ('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文'); insert into score(score, student_id, course_id) values -- 黑旋风李逵 (70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6), -- 菩提老祖 (60, 2, 1),(59.5, 2, 5), -- 白素贞 (33, 3, 1),(68, 3, 3),(99, 3, 5), -- 许仙 (67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6), -- 不想毕业 (81, 5, 1),(37, 5, 5), -- 好好说话 (56, 6, 2),(43, 6, 4),(79, 6, 6), -- tellme (80, 7, 2),(92, 7, 6);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
接下来,举几个例子来演示。
例子1:
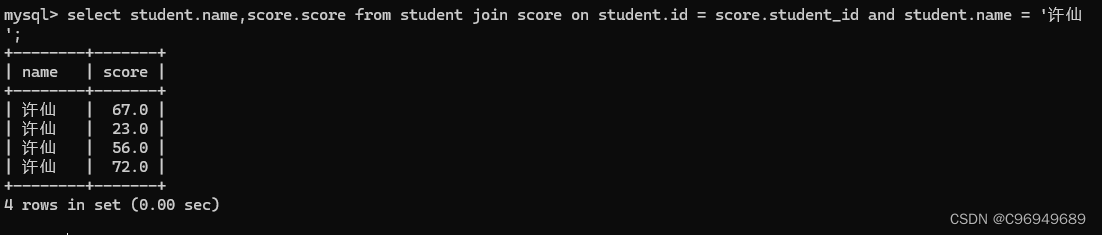
查询“许仙”同学的成绩
“许仙”这个名字是在学生表里面的,而成绩是在分数表里面的,所以需要用到联合查询。
第一步:进行笛卡尔积
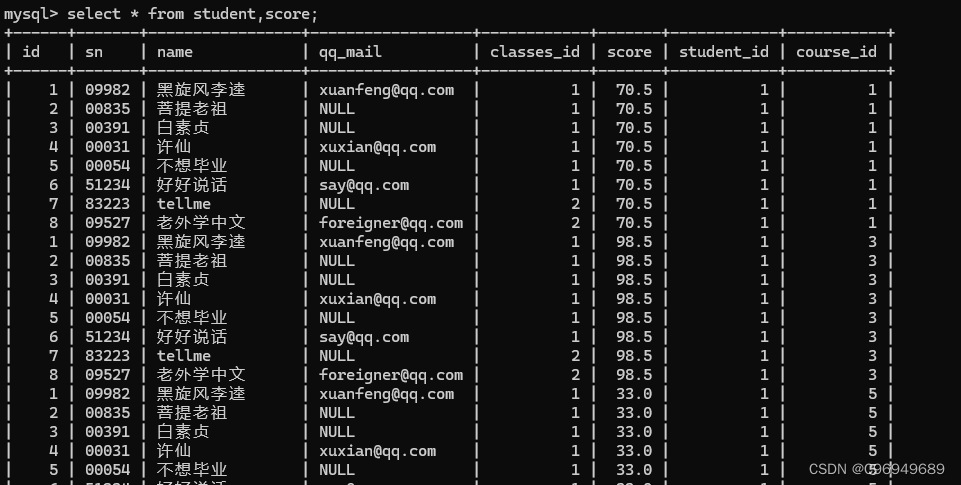
第二步:指定连接条件
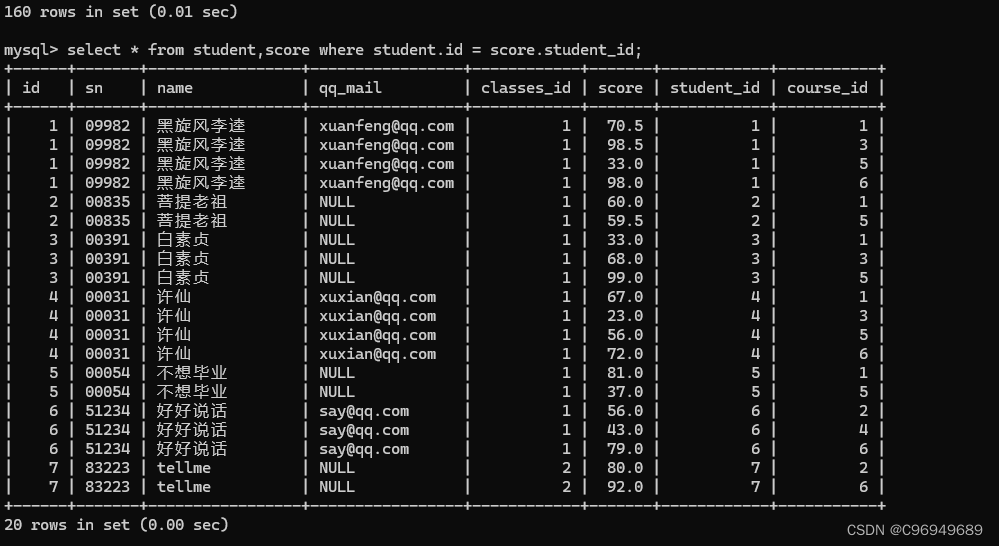
第三步:根据其它需求,补充其它条件
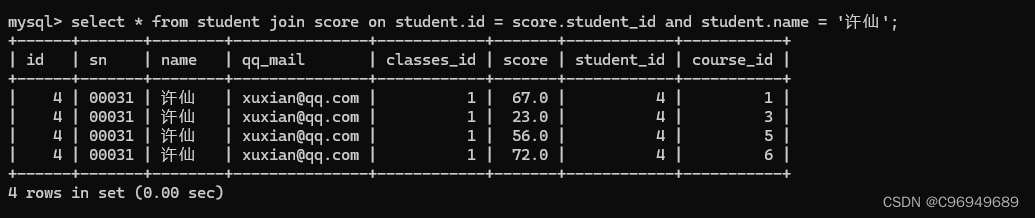
条件:找“许仙”同学的成绩
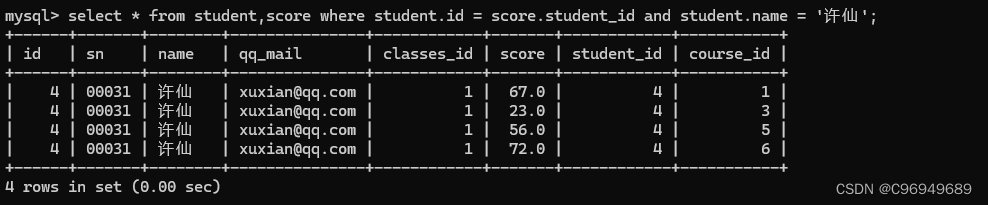
第四步:针对上面的列,进行精简
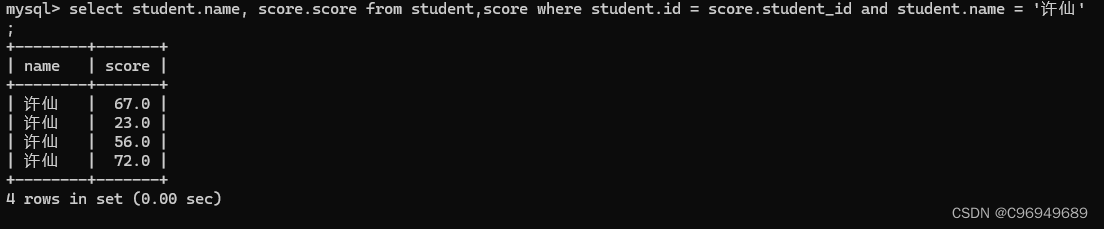
其实,多表查询还有另外一种写法:
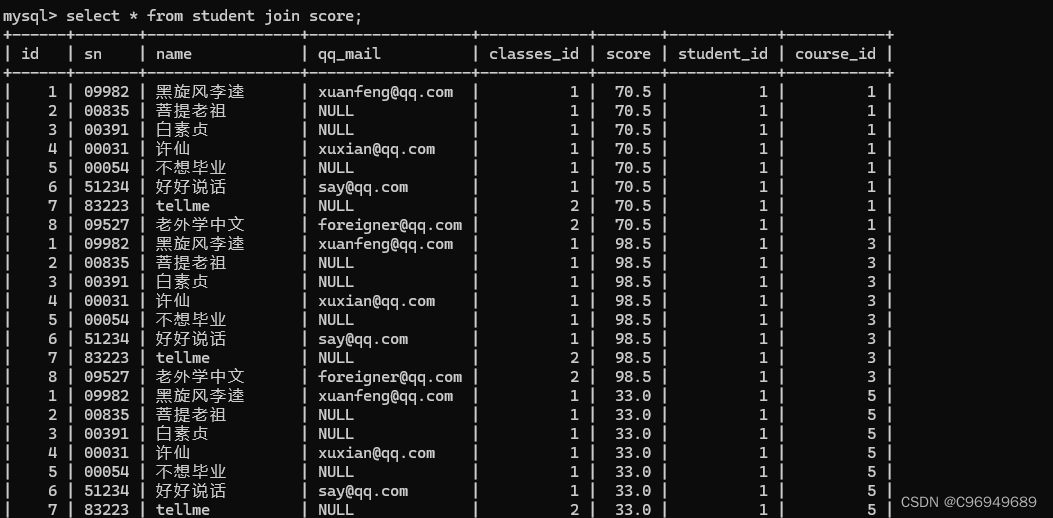
步骤一:进行笛卡尔积
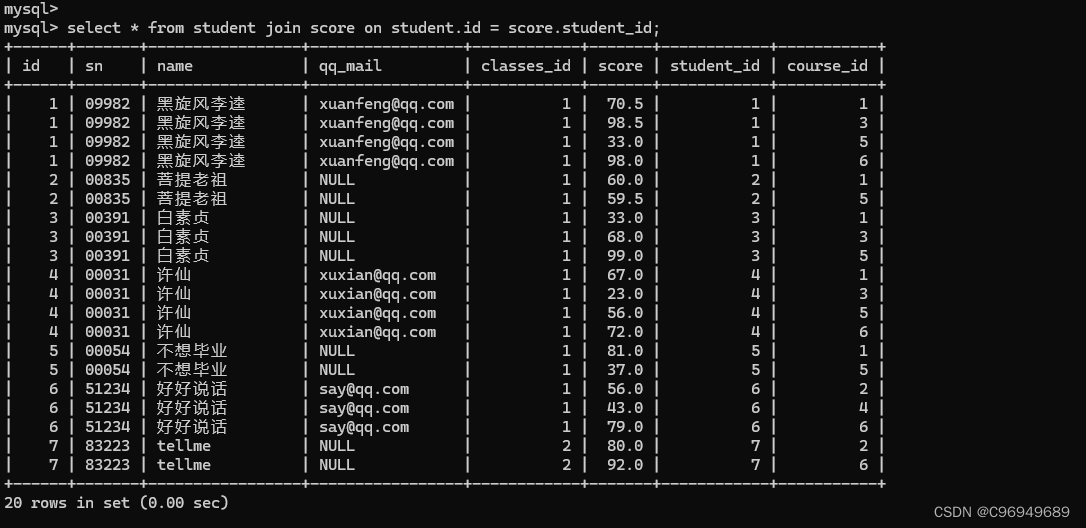
步骤二:指定连接条件
步骤三:指定其它条件
步骤四:针对列进行精简
例子2:
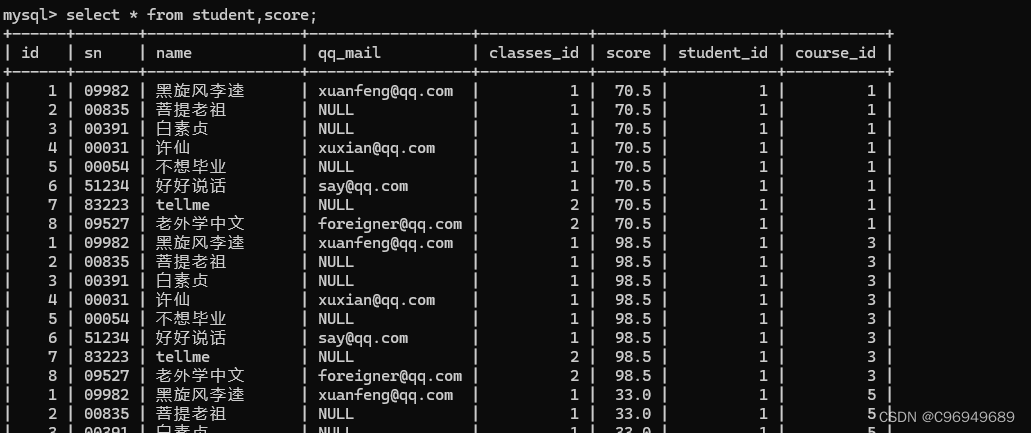
查询所有同学的总成绩,及同学的个人信息。
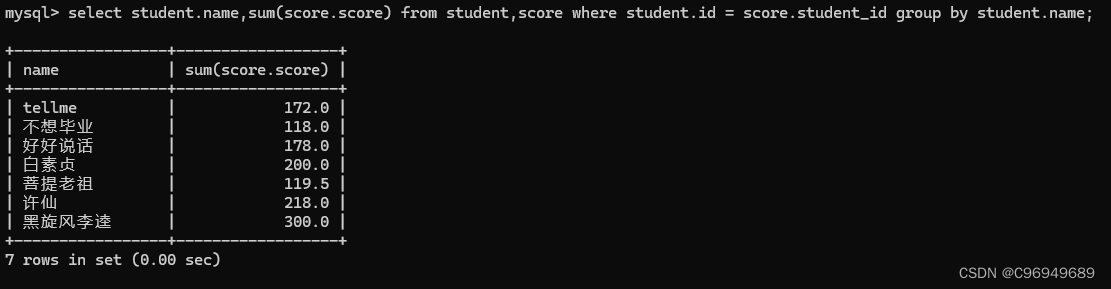
此处所求是每个同学的总成绩,所以应按照同学的名字/id进行group by。
步骤一:进行笛卡尔积
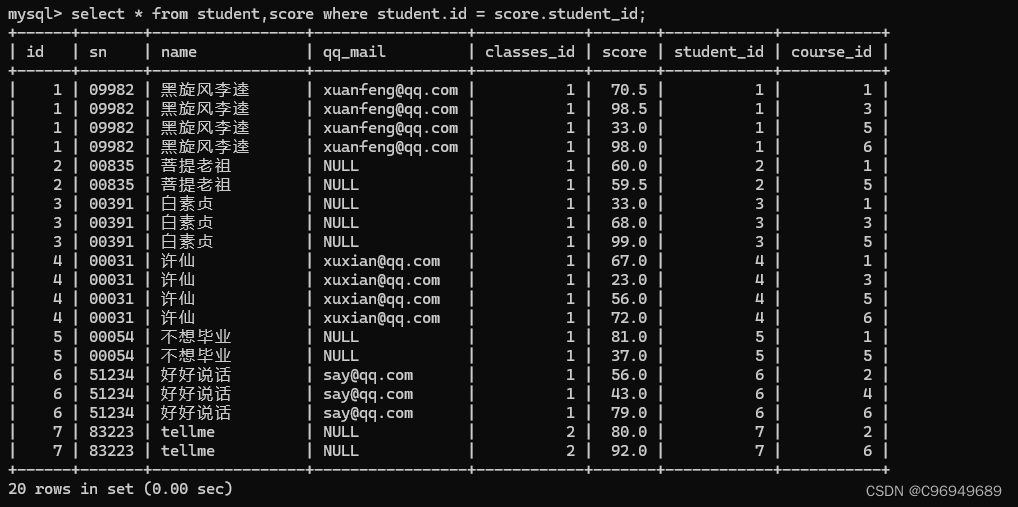
步骤二:指定连接条件
步骤三:补充其它条件
由于此处是需要知道所有同学的成绩,因此不用对同学进行进一步筛选。
步骤四:针对列进行精简 / 表达式 / 聚合查询
也可以使用第二种语法表示:
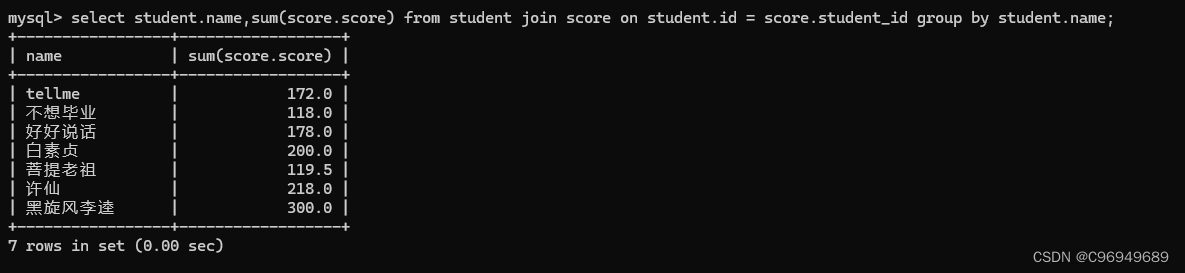
建议初学者学习联合查询这种复杂SQL时,最好一步一步写,避免出错时难以发现。
例子3:
查询所有同学的成绩,及同学的个人信息。
这里,同学的名字在学生表里,课程名字在课程表里,分数在分数表里。
步骤一:进行笛卡尔积
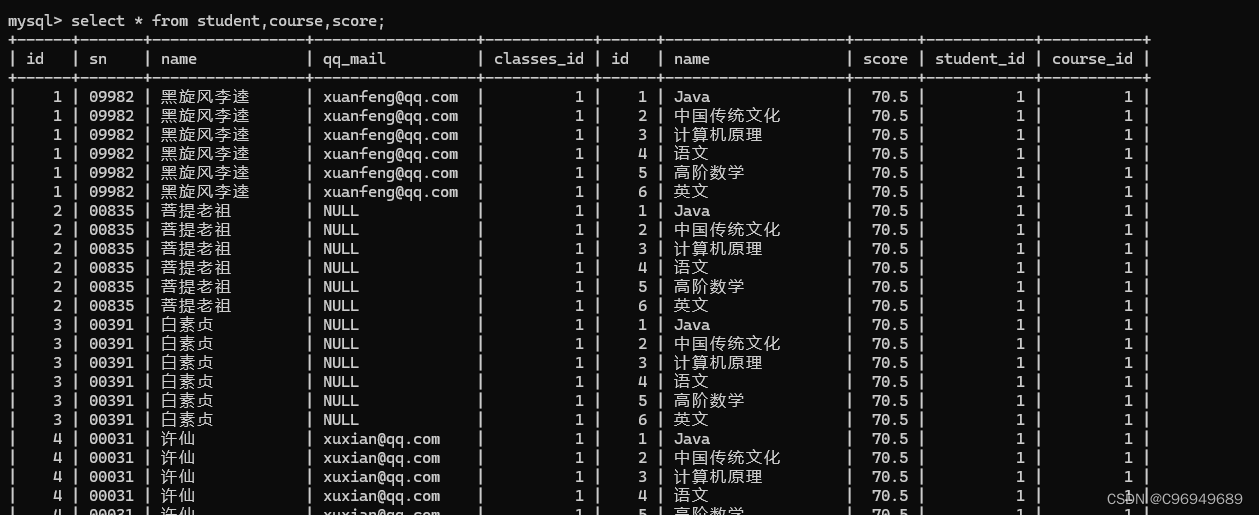
步骤二:指定连接条件
三张表进行笛卡尔积,相当于表A和表B先进行笛卡尔积(第一个连接条件),而表A和表B进行笛卡尔积的结果再和表C进行笛卡尔积(第二个连接条件),最终得到的就是三张表的笛卡尔积。

而student表和course表里没有“有关联的列”,所以无法直接算笛卡尔积。所以连接条件只能从student表与score表,score表与course表下手。
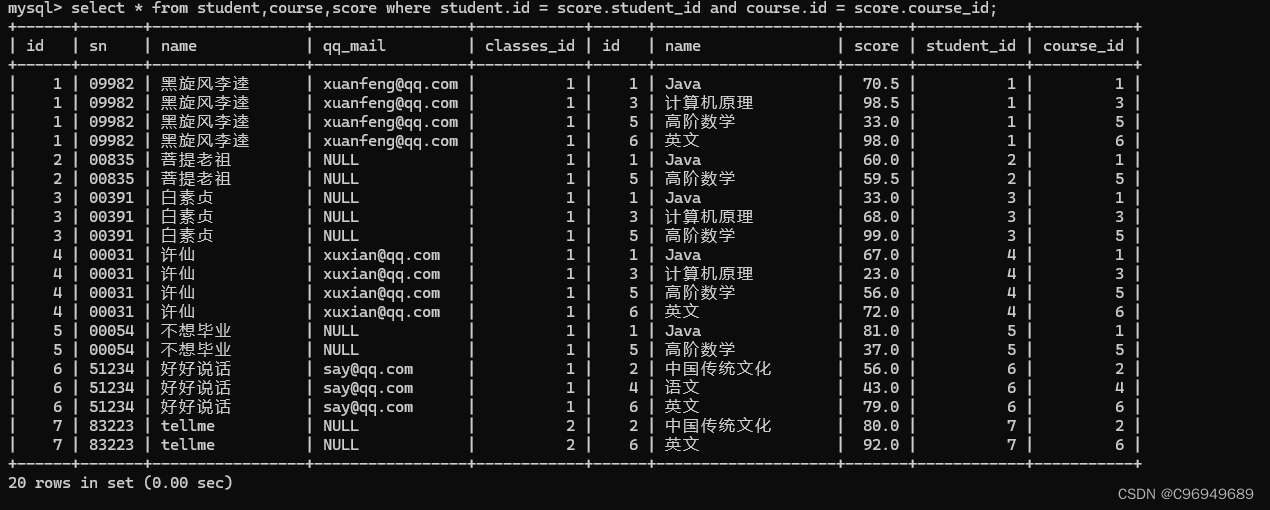
步骤三:指定其它条件
此处和例子2一样,也是不需要指定条件的。
步骤四:针对列进行 精简 / 表达式 / 聚合
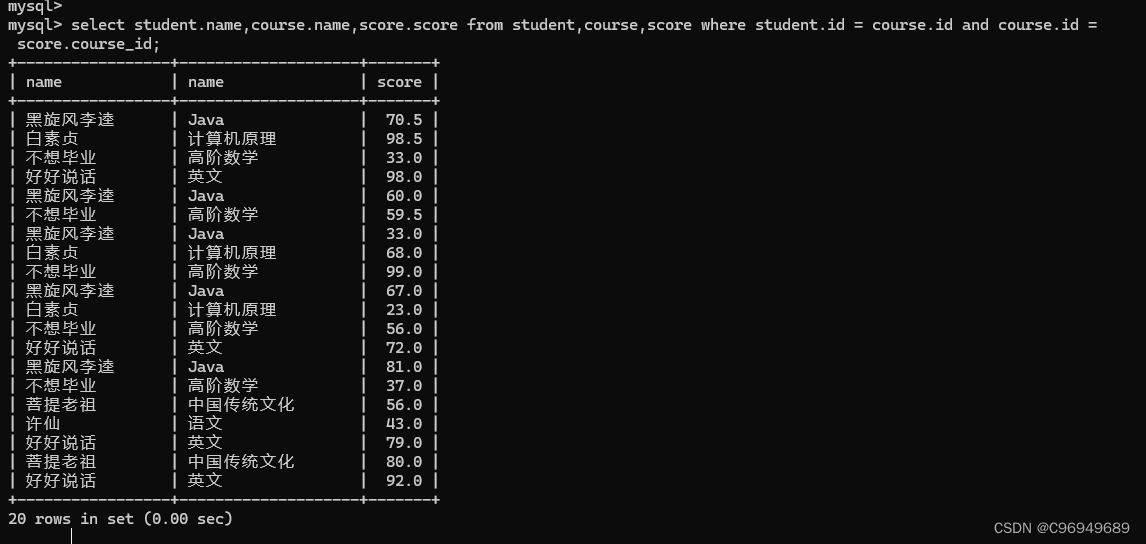
也可以用第二种方式写:
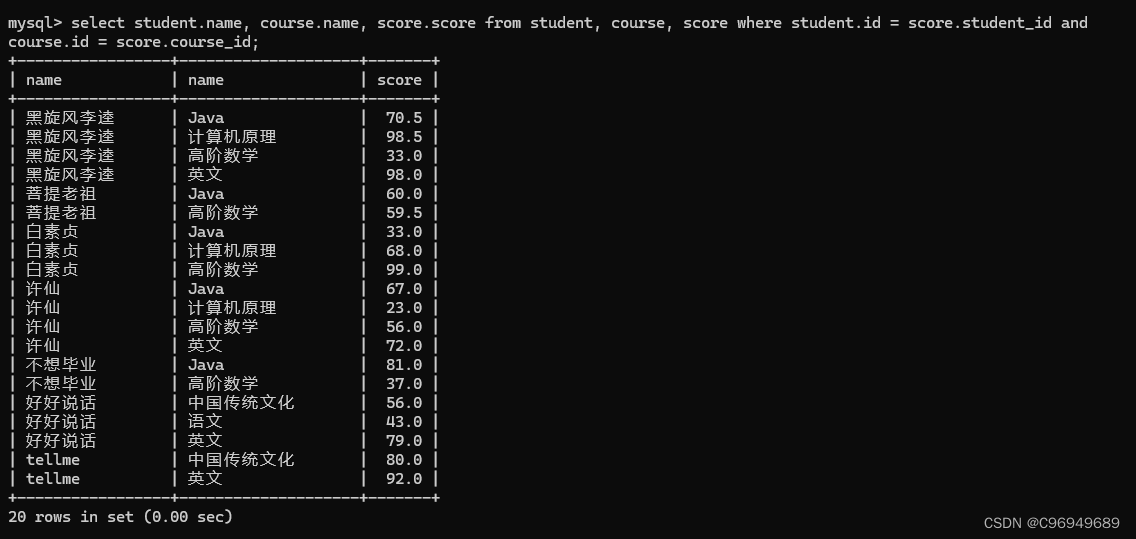
提示:在多表查询中,前面涉及到的去重、排序、limit 也是同样适用的
2.2 外连接
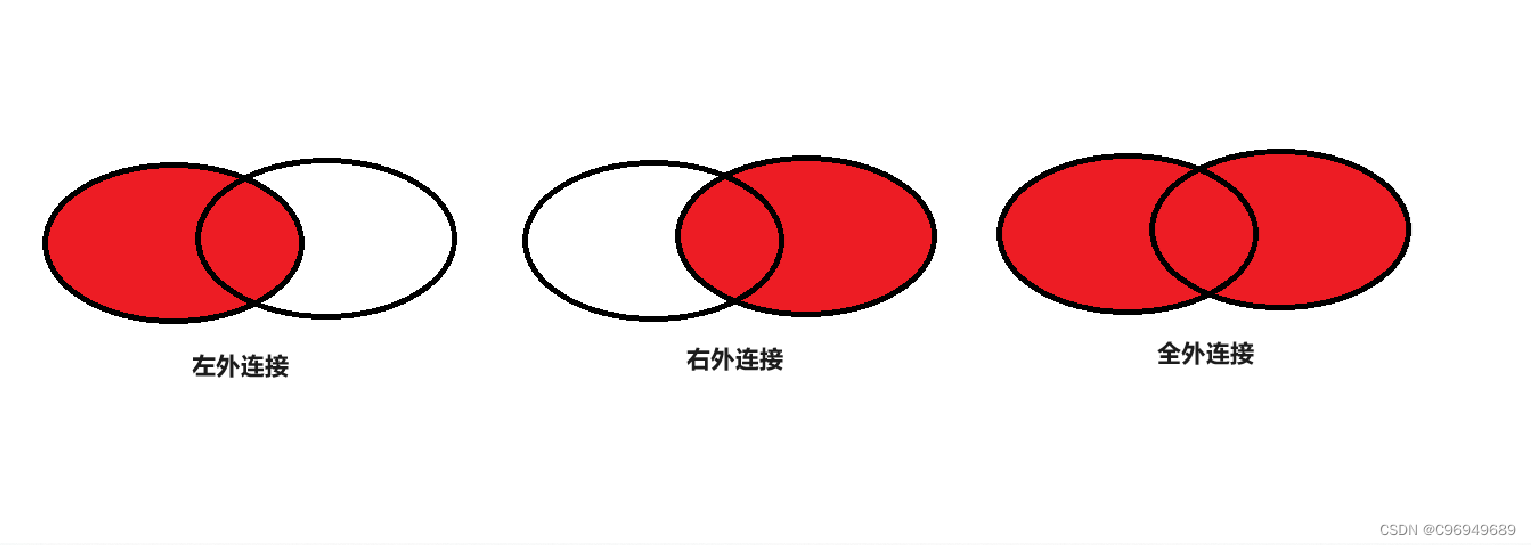
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
外连接语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
-- 全外连接,表1,表2完全显示
select 字段 from 表名1 outer join 表名2 on 连接条件;
- 1
- 2
- 3
- 4
- 5
- 6
外连接也是多表查询的一种体现形式。上面所学的写法叫做内连接。
给出以下数据表:
内连接:
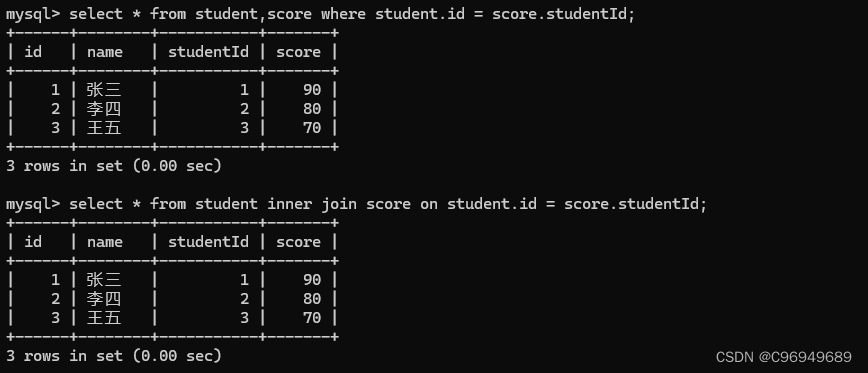
左外连接:
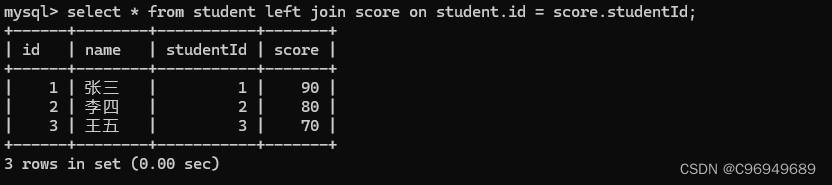
右外连接:
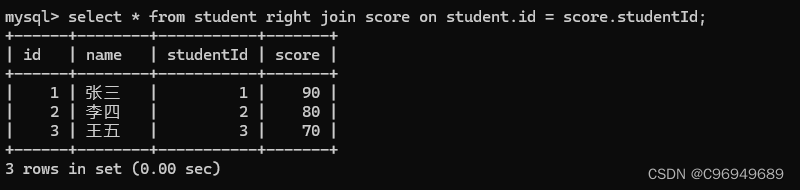
由于这两个表的数据都是一 一对应的,学生表中的任何一个记录都能在分数表中体现,当然,分数表中的每个记录也能在学生表中体现出来。所以,此时的内连接和外连接,结果是一样的。
给出数据表:
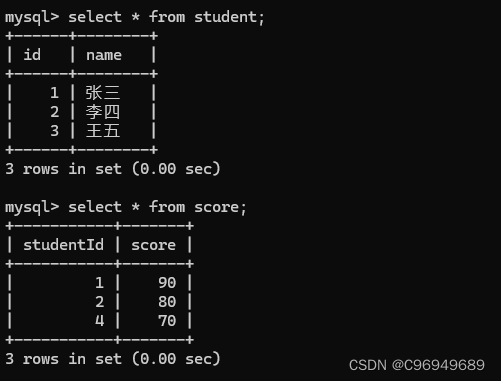
此时的数据,就不是一 一对应了。
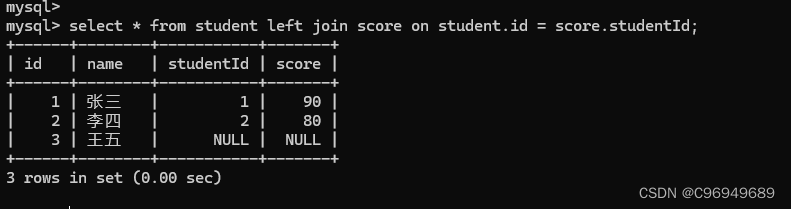
进行左外连接:
进行右外连接:
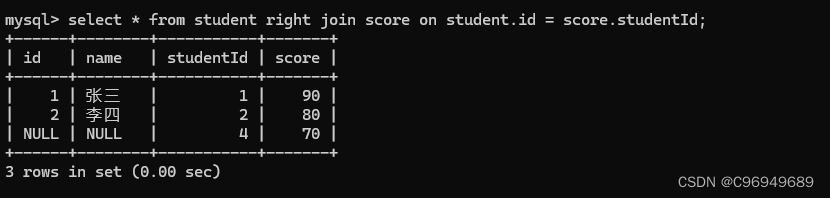
进行全外连接:

可以看到,MySQL是不支持全外连接的。但是,在Oracle是支持全外连接的。
2.3 自连接
自连接是指在同一张表连接自身进行查询
自连接用的很少,这算是一种奇淫技巧了。自连接需要在同一张表,自己和自己进行笛卡尔积。有的时候,想要进行条件查询,条件一定是列和列之间,而不能是行和行之间指定条件。所以,想要针对行之间指定条件,就可以通过自连接,把行关系转成列关系。
当然,这个操作的代价也是很高的,所以需要慎重。如果实际开发中遇到某个地方,必须用到内连接才能解决,那么就需要考虑一下,是不是表的结构设计的不科学。
例子:
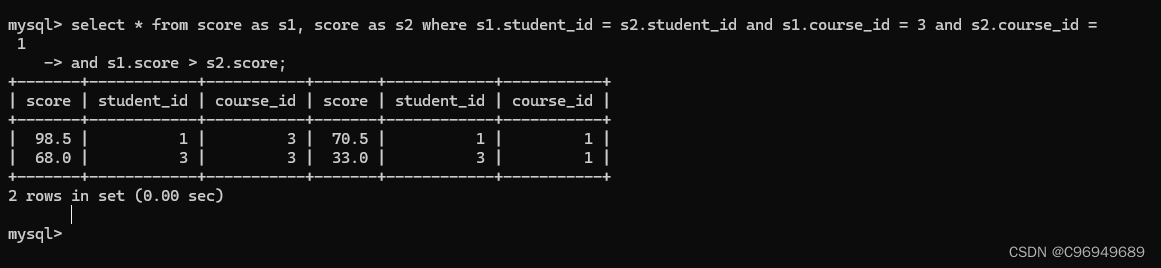
若要查询“计算机原理”比“Java”成绩高的成绩信息
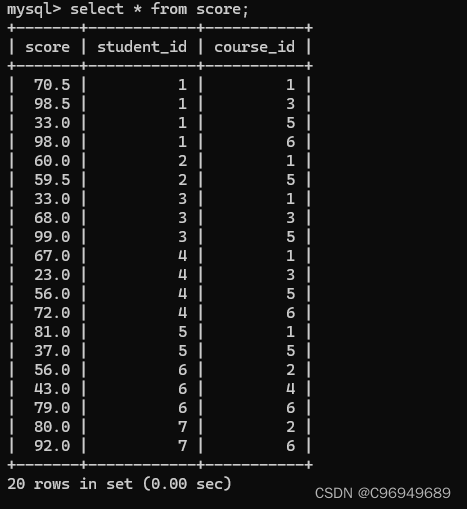
在这个例子中,想要完成不同科目的比较,就需要比较行之间的大小,而SQL无法直接做到,就只能把行转成列,用到自连接。
提示:进行自连接时,表名需要指定别名,否则两个表名相同会报错!
指定连接条件:
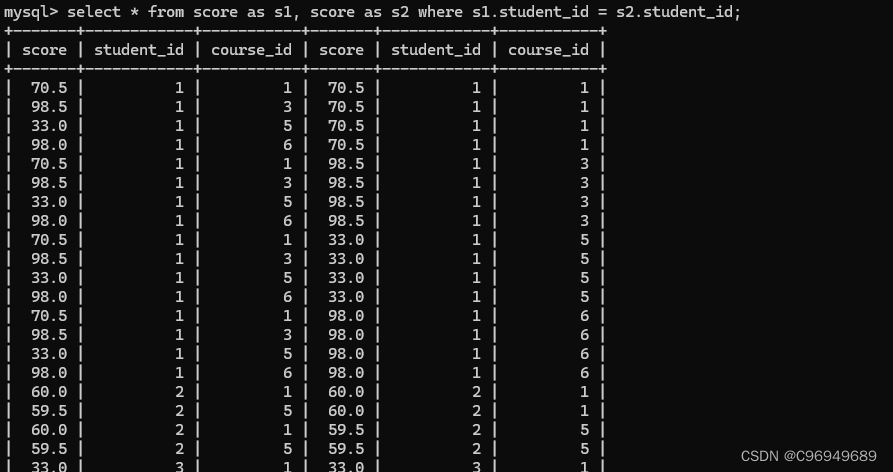
根据条件筛选:
筛选出左表course_id为3,右表course_id为1的记录(或者左为1,右为3),且course_id为3的成绩大于course_id为1的成绩。
3.子查询
子查询是指嵌入在其它SQL语句的select语句,也叫嵌套查询
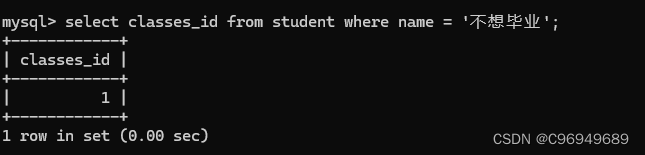
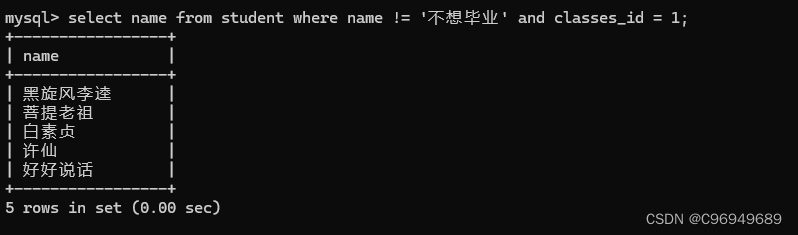
例子:查询“不想毕业”同学的同班同学
如果按照正常的步骤:
首先确认“不想毕业”同学所在的班级:
然后再查询班级里不叫“不想毕业”的同学:
用子查询来完成:
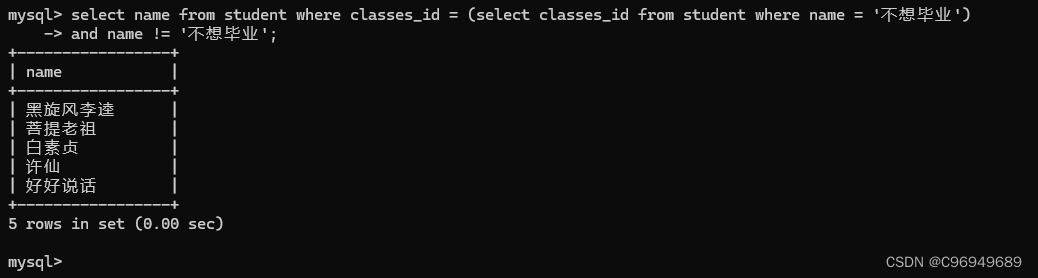
当然,这种把语句更加复杂化的操作,是不利于我们人脑的,所以日常开发中并不推荐使用子查询。
4.合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
合并查询,就是把两个查询的结果合集,合并成一个集合。使用union关键字完成。即select 1 union select 2,但是要求两个select查询的结果集,列数和类型要匹配,列名不影响,最终的列名就是第一个select的列名。
-
union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。 -
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
例子:查询名字带有英文的记录表以及id 小于3的记录表
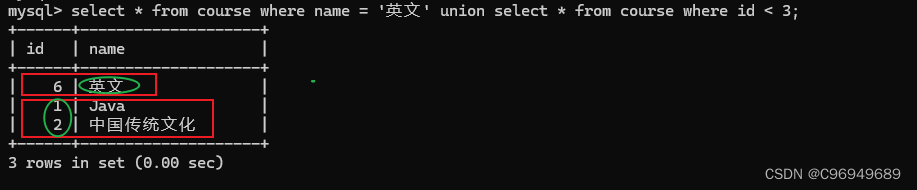
当然,使用or也可以完成上述查询。但是,union可以不局限于同一张表,可以针对不同表操作。
六、总结
本篇学习了 约束、表的设计、新增、查询,其中查询包括聚合查询以及联合查询。其中,有很多内核知识,是需要我们掌握的。 在实际开发中,其实更常用的SQL语句,是最基础的增删改查。但是在面试的时候,面试官会喜欢考察联合查询的知识。所以,也需我们耐下心来学习以上知识。

