
- 1Python基础之综合练习一_头歌平台 python 练习一
- 2从事Java开发3年,技术和工资遇到瓶颈,怎么突破?_java工作三年发现什么都不会
- 3图解快速排序
- 4文盘Rust -- 给程序加个日志_log4rs 实际工程
- 5信息安全加解密各种算法(比较全)_信息安全算法
- 6VMware 安装 Centos7 后,没有ipv4的地址,或者地址显示127.0.0.1_vmvare 安装centos7 无ipv4
- 7Source Tree 图形化工具的使用
- 8平衡二叉树实现(Java)_java平衡二叉树
- 9Python程序设计实例 | 条形码图片识别_识别图片中的条形码
- 10Kali渗透测试:社会工程学工具_kali社会工程学
python实现OCR:pytesseract和pyddleocr(附代码)_python ocr 识别
赞
踩
背景
OCR是光学字符识别(Optical Character Recognition)的缩写,通过扫描等光学输入方式和文字识别将图片中的文字提取出来,非常适用于提取网络截图或扫描pdf等文件里的文本。
目前市面上的OCR工具很多,今天笔者对常用的两种方式分享:
1、pytesseract:pytesseract是google的tesseract的一个python版本的接口库。
2、paddleocr:在国内的工具中,百度AI提供的OCR接口服务算是其中的佼佼者。除了在线接口OCR服务之外,最近百度还开源了飞桨文字识别套件PaddleOCR,可以基于该工具开展本地化的文字识别。
pytesseract
pytesseract是google的tesseract的一个python版本的接口库,想要真正使用,首先需要安装tesseract。下载网址:tesseract,按默认安装就可以,记得勾选中文包,记住自己的安装路径,配置环境变量(配置到tesseract.exe所在那一级):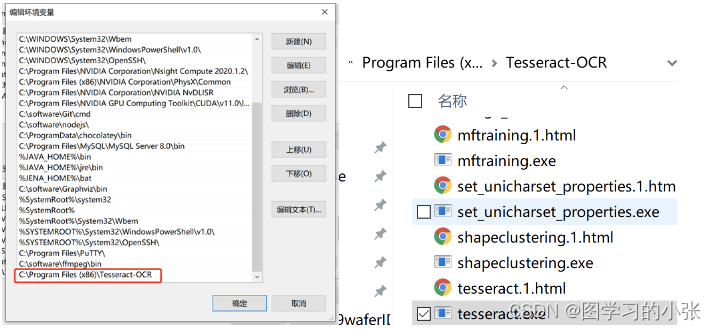 测试是否安装成功,在命令行输入tesseract --help查看是否会返回一些提示信息:
测试是否安装成功,在命令行输入tesseract --help查看是否会返回一些提示信息: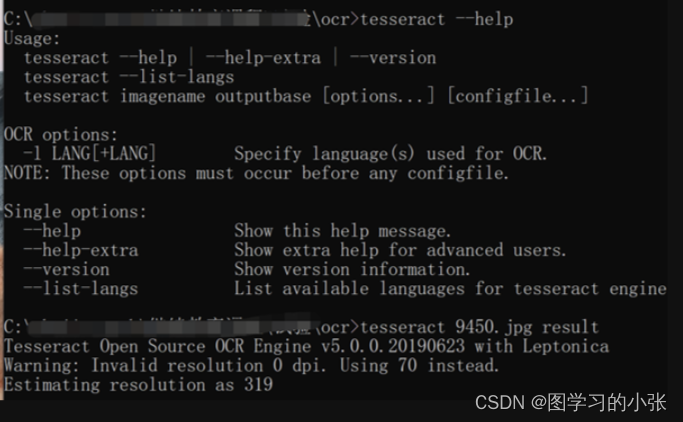
然后安装pytessract库:
pip install pytesseract
- 1
简单使用:
def get_OCR(img_path):
img_cv = cv2.imread(img_path)
txt = pytesseract.image_to_string(img_cv ,lang="chi_sim")
return txt
- 1
- 2
- 3
- 4
paddleocr
百度api提供的OCR服务算是其中的佼佼者,paddleocr是百度还搞的飞桨文字识别套件,可以基于该工具开展本地化的文字识别。我们分别介绍百度api和paddleocr的使用方法。
百度api
注册百度智能云账号,创建一个应用,在创建新应用页面中,需要填写使用应用的相关信息,并选择文字识别中的通用文字识别服务,全部填写完毕即可成功创建应用,会生成每个应用唯一的AppID、API Key、Secret Key等秘钥信息,这几个值是后续调用api接口的关键参数: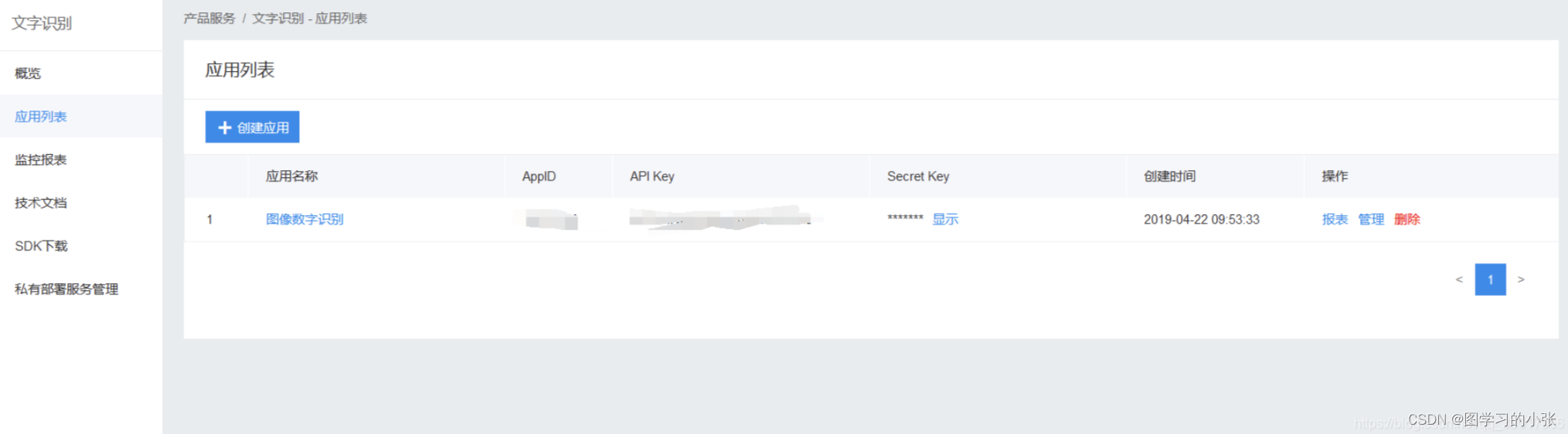
使用代码示例:
'''
构建请求url,获取Access Token,必须参数如下:
grant_type: 必须参数,固定为client_credentials;
client_id: 必须参数,应用的API Key;
client_secret: 必须参数,应用的Secret Key;
'''
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + '替换为自己的API Key' + '&client_secret=' + '替换为自己的Secret Key'
headers = {
'Content-Type': 'application/json;charset=UTF-8'
}
# 获取token
res = requests.get(url=host, headers=headers).json()
url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic'
data = {}
data['access_token'] = res['access_token']
'''
基于之前获取的token值,再次向请求url发送post请求,完成文字识别
'''
# 读取图片
image = "D:\临时\图片1.png"
file = open(image, 'rb')
image = file.read()
file.close()
data['image'] = base64.b64encode(image)
#发送post请求,传入图片信息参数,获取文字识别结果
headers = {"Content-Type": "application/x-www-form-urlencoded"}
res = requests.post(url=url, headers=headers, data=data)
result = res.json()
text = result['words_result'][0]['words']
#输出文本结果,保存为txt
f=open("D:\临时\图片1.txt",'a+')
for i in range(0,len(result['words_result'])):
f.write(result['words_result'][i]['words']+"\n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
但是,使用api有诸多限制,一天只有几百次免费次数,还会收到网速的影响。
paddleocr
PaddleOCR可以自行离线部署,并且没有使用频率限制,同时文字识别精度还是比较高的(比pytesseract强多了)。
在安装使用paddleocr之前,首先需要安装paddlepaddle和shapely:
pip install paddlepaddle
- 1
shapely如果直接使用pip安装可能会出现一些问题,我这里是在conda命令行安装,后续使用上没有出现问题:
conda install shapely
- 1
安装好前面两个库以后,就可以安装PaddleOCR了:
pip install paddleocr
- 1
给出我使用PaddleOCR的方法示例:
def get_paddle_ocr(ocr,image_path):
result = ocr.ocr(image_path, cls=True)[0]
txt = ''
if result == None:
return txt,False
for line in result:
txt = txt + line[1][0]
if txt == '':
return txt,False
return txt,True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

