
- 1openlayers学习——14、openlayers结合echarts图表和地图_openlayers echarts
- 2Hugging Face 下载加速器:提升模型获取速度的新利器
- 3【人工智能算法图解】之“人工智能初印象”_人工智能算法图解pdf下载
- 4HCL华三模拟器静态路由实验_h3c三层设备静态路由实验
- 5[论文总结] 智慧农业论文摘要阅读概览_oasis 文章摘要
- 6使用pycharm创建Django项目
- 7低代码开发之vue.draggable的使用(进阶:组件化拖拽生成功能页面)_vuedraggable
- 8【LeetCode算法学习笔记】股票买卖问题_股票涨跌,其中u(up),d(down),b(balance),输入一连串字符串,仅包括u,d,b,
- 9git之idea分支操作_common local branches
- 10读Muduo源码笔记---7(Protobuf)_mudo protobuffer
oracle 学习之 unpivot/pivot函数及hive实现该功能
赞
踩
pivot行转列函数
unpivot列转行函数
总结:
pivot函数:行转列函数:
语法:pivot(任一聚合函数 for 需专列的值所在列名 in (需转为列名的值));
unpivot函数:列转行函数:
语法:unpivot(新增值所在列的列名 for 新增列转为行后所在列的列名 in (需转为行的列名));
执行原理:将pivot函数或unpivot函数接在查询结果集的后面。相当于对结果集进行处理。
在学习之前,我个人觉得很多时候行转列 列转行,一行转多行,一列变多列,这些概念都不是很清楚
先看看网上说法 行转列、列转行 - 知乎
所谓行转列,即将一行数据转成多行显示,或者说将多列数据转成一列显示。通常将转化后的列名为某一行中某一列的值,来识别原先对应的数据
所谓列转行,即将多行转为一行显示,或者说将一列转为多列显示。通常转化后将某一列distinct后的值作为列名,将此值对应的多行数据显示成一行
又有人评论说上面的说法反了
行转列:
即将多行一列数据转为一行多列显示。通常转化后将某一列分类后的值作为新的列名,将此值对应的多行数据显示成一行。
列转行:
即将一行多列数据转成多行一列显示。通常将转化后的列名为某一行中某一列的值,来识别原先对应的数据。
搞得我也迷惑了。再次搜索MySQL的行转列与列转行_什么是 列转行、行转列_¥程序猿¥的博客-CSDN博客


这里有句话说的好,
行转列 就是行数少了列数多了。
列转行 就是列数少了行数多了。
一列转多列 就是行数不变,列数多了
一行转多行 就是列数不变,行数多了
所以这才是真正的概念,因为a转b 肯定是a转化为b,一个少一个多。
——————————————————————————————————————————
pivot语法个人总结为
select * from table pivot( --注意这里啊 pivot函数是对 table 进行行转列 table pivot是一个整体
聚合函数(column1) --column1你要聚合的字段
for column2 in ( --column2 是你要转成列的字段。比如下面的 COL_X 我要转列
value1 as newcolumn1 , -- value1 value2 必须是column2的值
value2 as newcolumn2
)
)
数据准备
create table test.test_pivot(name varchar2(10),subject varchar2(10),score int);
INSERT INTO test.test_pivot
SELECT * FROM (
select 'cc1','语文',12 from dual union all
select 'cc1','数学',24 from dual union all
select 'cc1','英语',44 from dual union all
select 'cc2','语文',12 from dual union all
select 'cc2','数学',24 from dual union all
select 'cc2','英语',44 from dual union all
select 'cc3','语文',12 from dual union all
select 'cc3','数学',24 from dual union all
select 'cc3','英语',44 from dual union all
select 'cc4','语文',12 from dual union all
select 'cc4','数学',24 from dual union all
select 'cc4','英语',44 from dual union all
select 'cc5','语文',12 from dual union all
select 'cc5','数学',24 from dual union all
select 'cc5','英语',44 from dual union all
select 'cc6','语文',12 from dual union all
select 'cc6','数学',24 from dual union all
select 'cc6','英语',44 from dual union all
select 'cc7','语文',12 from dual union all
select 'cc7','数学',24 from dual union all
select 'cc7','英语',44 from dual union all
select 'cc8','语文',12 from dual union all
select 'cc8','数学',24 from dual union all
select 'cc8','英语',44 from dual union all
select 'cc9','语文',12 from dual union all
select 'cc9','数学',24 from dual union all
select 'cc9','英语',44 from dual union all
select 'cc10','语文',12 from dual union all
select 'cc10','数学',24 from dual union all
select 'cc10','英语',44 from dual
)--如果oracle执行失败因为是csdn复制的时候多了空格。。自己处理
开始实战。
SELECT * FROM test.test_pivot

----这里我先说下 为什么要行转列??什么情况下需要行转列,各位考虑过没有?
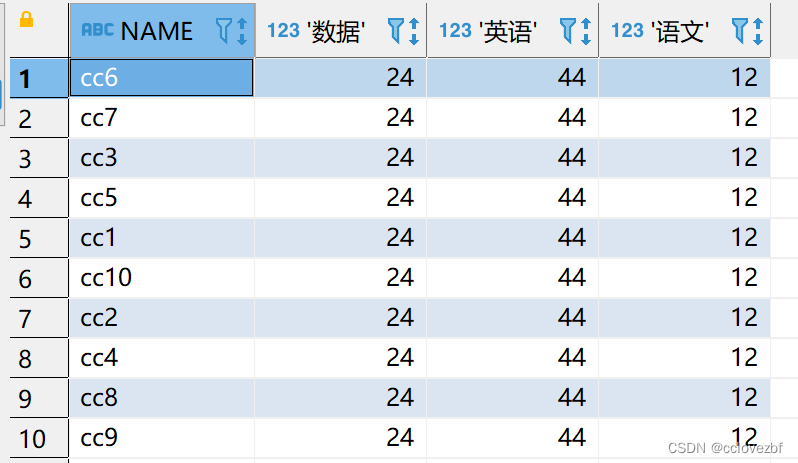
这张图和上面那张图 都能够看到学生的各科成绩,但是下面的图看起来更加直观一点,是不是更好呢? 我觉得不一定,因为每个人看待问题得角度不一样。
其实要是吹牛逼的话 还可以说下,存储的数据大小不一样,
最上面的是3*10 主要存的是 cc1 英语 12
下面的是4*10 主要寸的是cc1 24 12 44
上面的英语两个汉字占的空间可比下面占的多点。
好了直接实战。
1.显示每个学生的各科成绩
SELECT * FROM test.test_pivot pivot(
sum(score)
FOR subject IN ('数据','英语','语文')
)
--这里还是注意 这个函数pivot 和table还是一起的,说明是对整张表去列转行
--这个sum 啥用没有 你换成 avg min max 都一样
如何用hive表示呢?hive没有这类函数 直接group by 来处理
hive版本
SELECT NAME,
sum(CASE SUBJECT WHEN '语文' THEN SCORE ELSE 0 END ) AS yuwen,
sum(CASE SUBJECT WHEN '数学' THEN SCORE ELSE 0 END )AS shuxue,
sum(CASE SUBJECT WHEN '英语' THEN SCORE ELSE 0 END ) AS yingyu
FROM test.test_pivot
GROUP BY NAME--这也没啥好说的,就是注意一个问题 这里也用了sum 其实换做avg max也行 min就算了。
select*FROM test.test_pivot pivot
(
sum(score)
FOR name IN(
'cc1','cc2','cc3','cc4','cc5','cc6','cc7','cc8','cc9','cc10'
)
)
这种类似上面的。
SELECT subject,
sum(CASE name WHEN 'cc1' THEN SCORE ELSE 0 END) AS cc1,
sum(CASE name WHEN 'cc2' THEN SCORE ELSE 0 END) AS cc2,
sum(CASE name WHEN 'cc3' THEN SCORE ELSE 0 END) AS cc3,
sum(CASE name WHEN 'cc4' THEN SCORE ELSE 0 END) AS cc4,
sum(CASE name WHEN 'cc5' THEN SCORE ELSE 0 END) AS cc5,
sum(CASE name WHEN 'cc6' THEN SCORE ELSE 0 END) AS cc6,
sum(CASE name WHEN 'cc7' THEN SCORE ELSE 0 END) AS cc7,
sum(CASE name WHEN 'cc8' THEN SCORE ELSE 0 END) AS cc8,
sum(CASE name WHEN 'cc9' THEN SCORE ELSE 0 END) AS cc9,
sum(CASE name WHEN 'cc10' THEN SCORE ELSE 0 END) AS cc110
FROM test.test_pivot
group by subject--反正就是group by

2.显示每个学生的总成绩
select*FROM
(SELECT name,score from test.test_pivot) pivot
(
sum(score)
FOR name IN(
'cc1','cc2','cc3','cc4','cc5','cc6','cc7','cc8','cc9','cc10'
)
)

hive 如何实现呢?
第一步 先求sum总分
SELECT name,sum(score) from test.test_pivot
GROUP BY name
WITH tmp AS (SELECT name ,sum(score ) score FROM test.test_pivot GROUP BY name)
SELECT
sum(CASE name WHEN 'cc1' THEN SCORE ELSE 0 END) AS cc1,
sum(CASE name WHEN 'cc2' THEN SCORE ELSE 0 END) AS cc2,
sum(CASE name WHEN 'cc3' THEN SCORE ELSE 0 END) AS cc3,
sum(CASE name WHEN 'cc4' THEN SCORE ELSE 0 END) AS cc4,
sum(CASE name WHEN 'cc5' THEN SCORE ELSE 0 END) AS cc5,
sum(CASE name WHEN 'cc6' THEN SCORE ELSE 0 END) AS cc6,
sum(CASE name WHEN 'cc7' THEN SCORE ELSE 0 END) AS cc7,
sum(CASE name WHEN 'cc8' THEN SCORE ELSE 0 END) AS cc8,
sum(CASE name WHEN 'cc9' THEN SCORE ELSE 0 END) AS cc9
FROM tmp
GROUP BY 1反正就是这么个语法 我的不一定最好,只是一个思路。

unpivot
语法
select * from table pivot( --注意这里啊 pivot函数是对 table 进行行转列 table pivot是一个整体
聚合函数(column1) --column1你要聚合的字段
for column2 in ( --column2 是你要转成列的字段。比如下面的 COL_X 我要转列
value1 as newcolumn1 , -- value1 value2 必须是column2的值
value2 as newcolumn2
)
)
数据准备
直接将pivot的数据转化下久iu是unpivot的了 这两个函数本身就是相互转化的。
CREATE TABLE test.test_unpivot AS
SELECT * FROM test.test_pivot pivot(sum(score)FOR subject IN ('数学' AS 数学,'英语' AS 英语,'语文' AS 语文 ))
--这里注意有个坑,一般来说汉字 我们都要打引号的,oracle这里不需要。 如果你不 加as别名,你最后的字段名就是'数学'而不是 数学
--里面的分数我自己随便改了点 不影响。


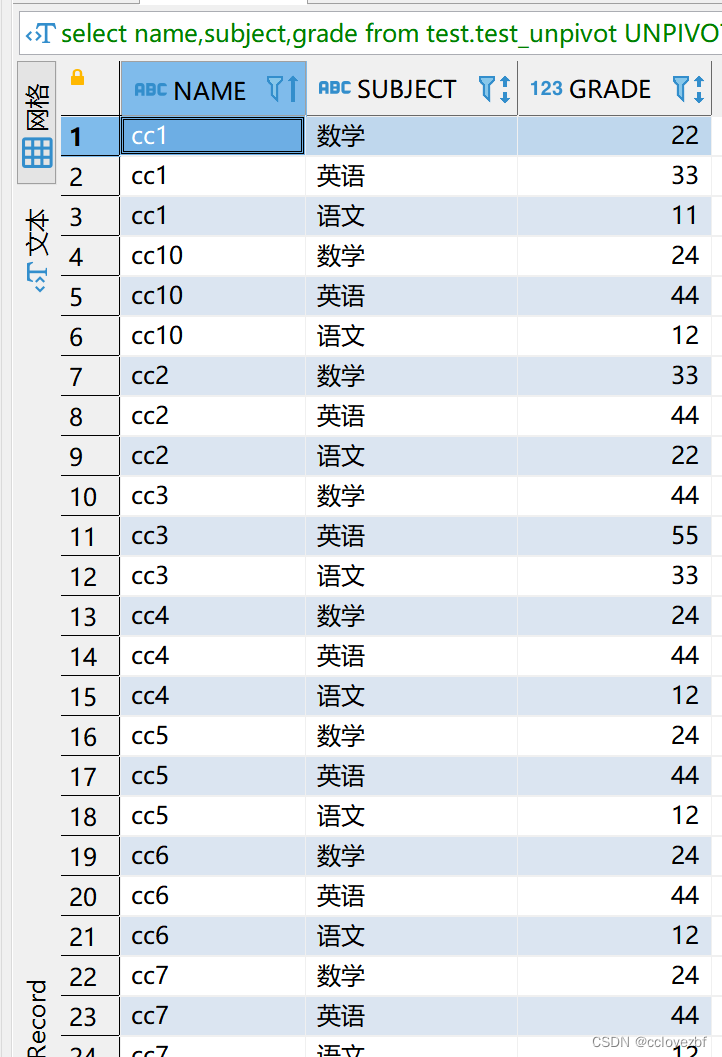
unpivot简单使用 行转列之一行转多列
select name,subject,grade from test.test_unpivot UNPIVOT(
grade for subject in(数学,英语,语文))
如何用hive语法,其实说mysql语法也行。实现如上功能呢?
上面行转列pivot 我们都是采用group by
那么列转行unpiovt 一般都是采用 union all。
SELECT *
FROM (
SELECT name ,'数学',数学 FROM test.test_unpivot UNION ALL
SELECT name ,'语文',语文 FROM test.test_unpivot UNION ALL
SELECT name ,'英语',英语 FROM test.test_unpivot
) ORDER BY name
就这样吧
总结下
pivot 我们在hive就用 case when +group by 来实现
unpivot我们在hive就用 union all来实现

